Record Duplication Profiler |
「Record Duplication Profiler」を使用すると、選択した属性に基づいて、相互に完全に重複しているレコードを検索できます。
「Record Duplication Profiler」は、データ・セット内で完全に重複しているレコード(たとえば、データ移行時のエラーのため)があるかどうかをチェックするために使用します。
重複チェックで使用する属性を選択できるため、レコード全体のサブセットに基づいて重複したレコードを検索することもできます。たとえば、氏名、住所および郵便番号に基づいて重複した顧客レコードを検索できます。
重複チェックで使用する属性。
|
オプション |
タイプ |
目的 |
デフォルト値 |
|
Consider no data values as duplicates? |
Yes/No |
すべての属性がNull値のレコードを相互に重複とみなすかどうかを決定します。 |
Yes |
|
Ignore case? |
Yes/No |
重複分析で大/小文字を無視するかどうかを決定します。 |
Yes |
|
注意: 一部(全部ではない)の属性がNull値で、他のレコードと完全にマッチするレコードは、常に重複とみなされます。 |
なし
|
フラグ属性 |
目的 |
可能性のある値 |
|
RecordDuplicate |
属性が他と重複しているかどうかを示します。 |
Y/N |
|
実行モード |
サポート |
|
バッチ |
Yes |
|
リアルタイム・モニタリング |
Yes |
|
リアルタイム応答 |
No |
「Record Duplication Profiler」では、レコードのバッチで重複を評価します。したがって、結果を使用するには完了まで実行される必要があり、リアルタイム応答が必要なプロセスには適していません。
リアルタイム・データ・ソースからのトランザクションのバッチに対して実行した場合、「Reader」プロセッサで構成されたコミット・ポイント(トランザクションまたは時間制限)に到達すると処理が終了します。返される統計は、トランザクションのバッチ内のみの重複数を示します。
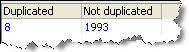
「Record Duplication Profiler」では、結果のサマリー・ビューが作成され、次の統計が表示されます。
|
統計 |
意味 |
|
Duplicated |
分析対象の属性間で重複しているレコードの数 |
|
Not duplicated |
分析対象の属性間で重複していないレコードの数 |
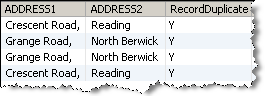
この例では、「Record Duplication Profiler」を使用して、「ADDRESS1」と「ADDRESS2」の2つの属性に基づき顧客表内の重複を検索します。
サマリー・ビュー
「Duplicated」値からのレコードのドリルダウン
Oracle (R) Enterprise Data Qualityオンライン・ヘルプ バージョン8.1
Copyright (C) 2006,2011 Oracle and/or its affiliates.All rights reserved.