![]()
|
|
Character Replace |
「Character Replace」プロセッサでは、個々の文字を置換します。これにより、参照データ・マップとマッチする文字を標準化または正規化できます。
アクセント付き文字や記号のバリアント(開始引用符と終了引用符など)のような一定でない文字を他の類似データでマスクできます。「Character Replace」プロセッサを使用して、参照データ・マップの文字のすべてのインスタンスを、その置換文字で置換します。
場合によっては、ある記述体系から別の記述体系に文字をマッピングすることで、「Character Replace」を文字から文字への単純な音訳に使用することもあります。
文字を置換する文字列または文字列配列型の属性。数値属性および日付属性は有効な入力ではありません。
配列属性を入力すると、変換はすべての配列要素に適用され、単一の配列属性が出力されます。
|
オプション |
タイプ |
目的 |
デフォルト値 |
|
Ignore Case |
Yes / No |
大文字と小文字の両方の文字(存在する場合)の置換を有効にします。 |
No |
|
Transform Map Reference Data |
参照データ |
文字をその置換文字にマップします。 |
*Standardize Accented Characters |
|
データ属性 |
タイプ |
目的 |
値 |
|
[Attribute Name].CharReplace |
導出 |
置換した文字が設定された新しい文字列または配列属性。 |
元の属性が文字置換された後の値 |
なし
なし
|
実行モード |
サポート |
|
バッチ |
Yes |
|
リアルタイム・モニタリング |
Yes |
|
リアルタイム応答 |
Yes |
「Character Replace」プロセッサでは、処理に関するサマリー統計は表示されません。
データ・ビューには、入力属性とともに、右側に文字を置換した後の文字列が格納された新しい属性が表示されます。
なし
この例では、「Character Replace」プロセッサを使用して、名(姓名の名)属性のアクセント付き文字を標準化します。
変換マップ参照データ:
|
参照 |
マップ |
コメント |
|
E |
E |
E acute |
|
E |
E |
E grave |
|
o |
o |
o circumflex |
Ignore case = Yes
結果:
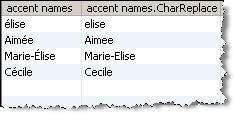
注意: 大文字のEがEに変換され、小文字のeがeに変換されます。
Oracle (R) Enterprise Data Qualityオンライン・ヘルプ バージョン8.1
Copyright (C) 2006,2011 Oracle and/or its affiliates.All rights reserved.