RegEx Split |
「RegEx Split」プロセッサでは、正規表現を使用して分割が発生する場所を定義し、属性のデータを配列に分割する手段を提供します。
正規表現は、パターンを表現し、文字列を操作するための標準の手法であり、一度習得すると非常に強力です。
正規表現に関するチュートリアルおよび参照資料は、インターネット上で次のサイトから入手できます。
次の書籍もあります。
また、正規表現の習得に役立つソフトウェア・パッケージ(RegExBuddyなど)、および有益な正規表現のオンライン・ライブラリ(RegExLibなど)も利用できます。
デリミタを使用する方法より高度なデータの分割方法が必要な場合は、「RegEx Split」を使用してデータを分割します。たとえば、一連の文字のいずれかが発生した場合または一連の可変長の文字が発生した場合にデータを分割できます。
単一の文字列属性。
|
オプション |
タイプ |
目的 |
デフォルト値 |
|
Regular expression |
正規表現 |
データを分割するデリミタとして使用する正規表現 |
なし |
|
データ属性 |
タイプ |
目的 |
値 |
|
RegExSplit |
導出 |
「RegEx Split」の結果が設定された新しい配列属性 |
「RegEx Split」の結果。正規表現自体にマッチしたデータはデリミタとして機能し、配列には存在しないことに注意してください。 |
|
フラグ属性 |
目的 |
可能性のある値 |
|
RegExSplitSuccess |
「RegEx Split」が正常に実行されたかどうかを示します。 |
Y/N |
|
実行モード |
サポート |
|
バッチ |
Yes |
|
リアルタイム・モニタリング |
Yes |
|
リアルタイム応答 |
Yes |
「RegEx Split」プロセッサでは、結果のサマリー・ビューが作成され、次の統計が表示されます。
|
統計 |
意味 |
|
Success |
正規表現を使用して分割されたレコードの数。 |
|
Failure |
正規表現を使用して分割されなかったレコードの数。 |
「RegEx Split」プロセッサからは、次の出力フィルタが使用可能です。
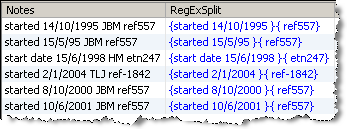
この例では、「RegEx Split」を使用して、従業員表の「Notes」属性から個人のイニシャル(一連の中で検出された2または3文字の大文字)の左右どちら側でもデータを分割します。
Regular expression: ([A-Z]{2,3})
結果(成功した分割):
Oracle (R) Enterprise Data Qualityオンライン・ヘルプ バージョン8.1
Copyright (C) 2006,2011 Oracle and/or its affiliates.All rights reserved.