The BEA TUXEDO System/T Development Environment
The purpose of the remainder of this chapter is to describe the environment in which you will be writing code for a BEA TUXEDO System/T application.
In addition to the C code that expresses the logic of your application, you will be using the Application-Transaction Monitor Interface (ATMI), which refers to the interface between the BEA TUXEDO System/T transaction monitor and your application. The ATMI primitives are C language functions that resemble UNIX system calls, but they have the specific purpose of implementing the communication among application modules running under the control of the BEA TUXEDO System/T transaction monitor, including all the associated resources you need.
As you might remember from the BEA TUXEDO Product Overview the BEA
TUXEDO System uses an enhanced client-server architecture.
Chapters 2 through 7 of this book describe how the ATMI
primitives are used in writing and debugging clients and
services. This chapter provides some of the context within which
you will be doing that work.
Client Processes
A client process takes user input and sends it as a service
request to a server process that offers the requested service.
Basic Client Operation
A client process uses one ATMI primitive to join an application, allocates a message buffer by using another ATMI primitive, and uses still others to send the buffer to a server and receive the reply.
The operation of a basic client process can be summarized by the pseudo-code shown in Figure 1.
Fig. 1: Pseudo-code for a Client
main()
{
allocate a TPINIT buffer
place initial client identification in buffer
enroll as a client of the System/T application
allocate buffer
do while true {
place user input in buffer
send service request
receive reply
pass reply to the user
}
leave application
}
Most of the statements in Figure 1 are implemented with ATMI primitives. Placing user input in a buffer and passing the reply to the user are implemented with C language functions.
When client programs are ready to test, you use the buildclient(1)
command to compile and link edit them.
Client Sending Repeated Service Requests
A client may send and receive any number of service requests
before leaving the application. These can be sent as a series of
request/response calls or, if it is important to carry state
information from one call to the next, a connection to a
conversational server can be set up. The logic within the client
program is about the same, but different ATMI primitives are
used.
Server Processes and Service Subroutines
Servers are processes that provide one or more services. They
continually check their message queue for service requests and
dispatch them to the appropriate service subroutines.
Basic Server Operation
Applications combine their service subroutines with the main() that System/T provides in order to build server processes. This system supplied main() is a set of predefined functions. It performs server initialization and termination and allocates buffers to receive and dispatch incoming requests to service routines. All of this processing is transparent to the application.
Server and a service subroutine interaction can be summarized by the pseudo-code shown in Figure 2.
Fig. 2: Pseudo-code for a Request/Response Server and a Service Subroutine
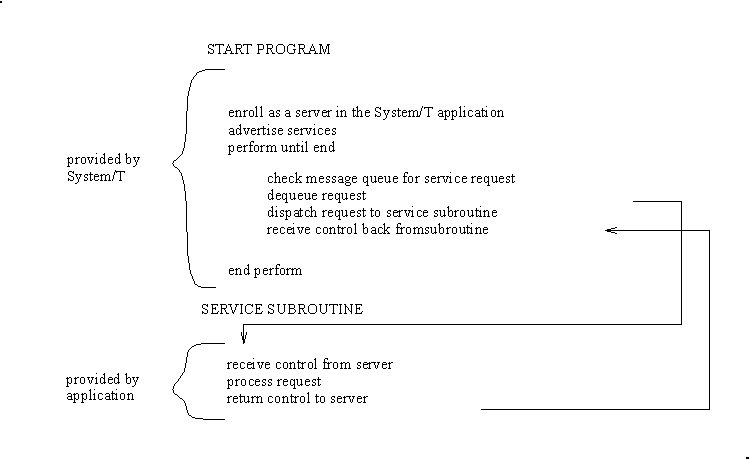
After some initialization a server allocates a buffer, waits until a request message is put on its message queue, dequeues the request, and dispatches it to a service subroutine for processing. If a reply is needed, the reply is considered part of request processing.
The conversational paradigm is somewhat different. Pseudo-code is shown in Figure 3.
Fig. 3: Pseudo-code for a Conversational Service Subroutine
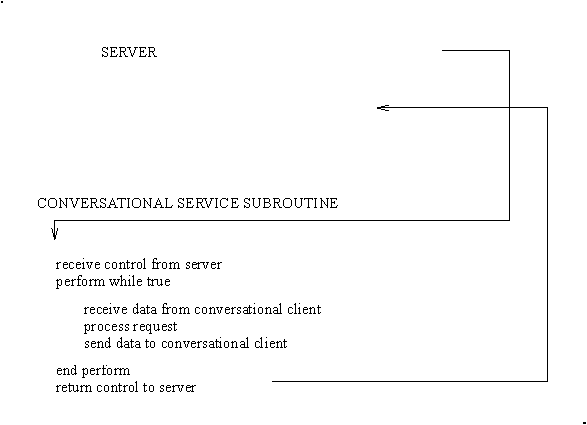
The BEA TUXEDO System/T-supplied main() contains the code
needed to enroll as a server, advertise services, allocate
buffers, and dequeue request messages. The ATMI primitives are
used in service subroutines that process requests. When they are
ready to compile and test, service subroutines are link edited
with the server main() by means of the buildserver(1)
command to form an executable server.
Servers As Requesters
The serially reusable architecture of servers is particularly significant if the operation requested by the user is logically divisible into several services, or several iterations of the same service. Such operations can be overlapped by having a server assume the role of a client and hand off part of the task to another server as part of fulfilling the original client's request. In such a capacity the server becomes a requester. Both clients and servers can be requesters. In fact, a client can only be a requester. The coding model for such a system is easily accomplished with the routines that are provided by ATMI.
A request/response server can also forward a request to
another server. This is different from becoming a requester. In
this case, the server does not assume the role of client since no
reply is expected by the server that forwards a request. The
reply is expected by the original client.
The ATMI Primitives
The Application-Transaction Monitor Interface is a reasonably compact set of primitives used to open and close resources, begin and end transactions, allocate and free buffers, and provide the communication between clients and servers. Table 1 summarizes them. Each routine is documented on its own page in the BEA TUXEDO Reference Manual: Section 3c
Table 1: ATMI Primitives
| Group | Name | Operation |
|---|---|---|
| Application Interface | tpinit() | join an application |
| tpterm() | leave an application | |
| Buffer Management Interface | tpalloc() | allocate a buffer |
| tprealloc() | re-size a buffer | |
| tpfree() | free a buffer | |
| tptypes() | get buffer type | |
| Request/Response Communication Interface | tpcall() | send a request, wait for answer |
| tpacall() | send request asynchronously | |
| tpgetrply() | get reply after asynchronous call outstanding reply | |
| tpcancel() | cancel communications handle for | |
| tpgprio() | get priority of last request | |
| tpsprio() | set priority of next request | |
| Conversational Interface | tpconnect() | begin a conversation |
| tpdiscon | end a conversation | |
| tpsend() | send data in conversation | |
| tprecv() | receive data in conversation | |
| Unsolicited Notification Interface | tpnotify() | notify by client id |
| tpbroadcast() | notify by name | |
| tpsetunsol() | set unsolicited message handling routine | |
| tpgetunsol() | get unsolicited message | |
| tpchkunsol() | check for unsolicited messages | |
| Transaction Management Interface | tpbegin() | begin a transaction |
| tpcommit() | commit the current transaction | |
| tpabort() | abort the current transaction | |
| tpgetlev() | check if in transaction mode | |
| Service Routine Template | tpservice() | start a service |
| tpreturn() | end service routine | |
| tpforward() | forward request and end service routine | |
| Dynamic Adv Interface | tpadvertise() | advertise a service name |
| tpunadvertise() | unadvertise a service name | |
| Resource Mgr Interface | tpopen() | open a resource manager |
| tpclose() | close a resource manager | |
| Event Broker/Event Monitor Interface | tppost() | post an event |
| tpsubscribe() | subscribe to an event | |
| tpunsubscribe() | unsubscribe to an event |
An Overview of X/Open's TX Interface
In addition to ATMI's transaction management verbs, System/T also supports X/Open's TX Interface for defining and managing transactions. Because X/Open used ATMI's transaction demarcation verbs as the base for the TX Interface, the syntax and semantics of the TX Interface are quite similar to ATMI.
Table 2 introduces the routines in the TX Interface and highlights the main differences with their corresponding ATMI routines. For maximum portability, the TX routines can be used in place of the ATMI routines shown in Table 2.
Table 2: TX Verbs
| TX Verbs | Corresponding ATMI Verbs | Main Differences |
|---|---|---|
| tx_begin | tpbegin | Timeout value not passed as argument to tx_begin. See tx_set_transaction_timeout. |
| tx_close | tpclose | None |
| tx_commit | tpcommit | tx_commit can optionally start a new transaction before it returns. This is known as a "chained" transaction. |
| tx_info | tpgetlev | tx_info returns the settings of transaction characteristics set via the three tx_set_* routines. |
| tx_open | tpopen | None |
| tx_rollback | tpabort | tx_rollback supports chained transactions. |
| tx_set_commit_return | tpscmt | None |
| tx_set_transaction_control | None | Defines whether the application is using chained or unchained transactions. |
| tx_set_transaction_timeout | tpbegin | Transaction timeout parameter separated from tx_begin. |
The TX interface requires that tx_open() be called before using any other TX verbs. Thus, even if a client or a server is not accessing an XA-compliant resource manager, it must call tx_open() before it can use tx_begin(), tx_commit(), and tx_rollback() to define transactions.
Figure 4 contains an example of how the TX Interface can be used to support chained transactions. Note that tx_begin() must be used to start the first of a series of chained transactions. Also, note that before calling tx_close(), the application must switch to unchained transactions so that the last tx_commit() or tx_rollback() does not start a new transaction.
Fig. 4: Chained Transactions Using TX Verbs
tx_open();
tx_set_transaction_control(TX_CHAINED);
tx_set_transaction_timeout(120);
tx_begin();
do_forever {
do work as part of transaction;
if (no more work exists)
tx_set_transaction_control(TX_UNCHAINED);
if (work done was successful)
tx_commit();
else
tx_rollback();
if (no more work exists)
break;
}
tx_close();
Typed Buffers
Messages are passed to servers in typed buffers. Why ``typed?'' Well, different types of data require different software to initialize the buffer, send and receive the data and perhaps encode and decode it, if the buffer is passed between heterogeneous machines. Buffers are designated as being of a specific type so the routines appropriate to the buffer and its contents can be invoked. These issues are typically not of concern to application developers, but more details can be found in buffer(3), tuxtypes(5), and typesw(5).
System/T provides nine buffer types for messages: STRING, CARRAY, VIEW, VIEW32, FML, FML32, X_OCTET, X_COMMON, and X_C_TYPE. Applications can define additional types as needed. Consult the manual pages referred to above and the BEA TUXEDO Administrator's Guide.
The STRING buffer type is used when the data is an array of characters that terminates with the null character.
The data in a CARRAY buffer is an undefined array of characters, any of which can be null. The CARRAY is not self-describing and the length must always be provided when transmitting this buffer type. The X_OCTET buffer type is equivalent to CARRAY.
The VIEW type is a C structure that the application defines and for which there has to be a view description file. Buffers of the VIEW type must have subtypes, which designate individual data structures. The X_C_TYPE buffer type is equivalent to VIEW. The X_COMMON buffer type is similar to VIEW but is used for both COBOL and C programs so field types should be limited to short, long, and string. The VIEW32 buffer type is similar to VIEW but allows for larger character fields, more fields, and larger overall buffers.
An FML buffer is a proprietary BEA TUXEDO System type of self-defining buffer where each data field carries its own identifier, an occurrence number, and possibly a length indicator. This type provides great flexibility at the expense of some processing overhead in that all data manipulation is done via FML function calls rather than native C statements.
The FML32 data type is similar to FML but allows for larger
character fields, more fields, and larger overall buffers.
Using VIEW and FML Buffers
If you are using the VIEW or FML buffer
types, some preliminary work is required to create view
description files or field table files. In the case of VIEWs,
a description file must exist and must be available to client and
server processes that use a data structure described in the VIEW.
For FML buffers, a field table file containing
descriptions of all fields that may be in the buffer must be
available.
Relationship Between Some VIEW Buffers and FML
There are two kinds of VIEW buffers. One is based
on an FML buffer. The other VIEW buffer is
independent; it is simply a C structure. Both types are described
in view description files and compiled with viewc(1), the BEA
TUXEDO System view compiler. We're going to talk first about the
FML variety.
FML Views
BEA TUXEDO System FML is a family of functions, some of which convert an FML buffer into a C structure or vice versa. The C structure that is derived from the fielded buffer is referred to as an FML VIEW. The reason for converting FML buffers to C structures and back again is that while FML buffers provide data independence and convenience, they do involve processing overhead because they must be manipulated using FML function calls. C structures, while not providing flexibility, offer the performance required for lengthy manipulations on buffer data. If enough manipulation of the data is called for, you can improve the performance of your programs if you transfer fielded buffer data to C structures, operate on the data using normal C functions, and then put the data back into the FML buffer for storage or message transmission.
There are slight differences between a view description of an FML-based view and one that is independent of FML. Figure 5 shows a view description file with all of the available data types. The file is myview.v and the structure is based on an FML buffer. Note that the CARRAY1 field has a count of 2 occurrences and has the "C" count flag to indicate that an additional count element should be created in the structure so the application can indicate how many of the occurrences are actually being used. It also has the "L" length flag such that there is a length element (which occurs twice, once for each occurrence of the field) indicating how many of the characters the application has populated.
Fig. 5: View Description File for FML View
VIEW MYVIEW $ /* View structure */ #type cname fbname count flag size null float float1 FLOAT1 1 - - 0.0 double double1 DOUBLE1 1 - - 0.0 long long1 LONG1 1 - - 0 short short1 SHORT1 1 - - 0 int int1 INT1 1 - - 0 dec_t dec1 DEC1 1 - 9,16 0 char char1 CHAR1 1 - - '\0' string string1 STRING1 1 - 20 '\0' carray carray1 CARRAY1 2 CL 20 '\0' END
FML Field Table Files
Field table files are always required when using FML records, including the use of FML-dependent VIEWS. A field table file maps the logical name of a field in an FML buffer to a field identifier that uniquely identifies the field.
An example that could be used with the view shown in Figure 5 is shown in Figure 6.
Fig. 6: The myview.flds Field Table File
# name number type flags comments FLOAT1 110 float - - DOUBLE1 111 double - - LONG1 112 long - - SHORT1 113 short - - INT1 114 long - - DEC1 115 string - - CHAR1 116 char - - STRING1 117 string - - CARRAY1 118 carray - -
Independent VIEWs
Figure 7 shows the view description file, similar to the example in Figure 5, but for a VIEW independent from FML.
Fig. 7: View Description File for Independent Views
$ /* View data structure */ VIEW MYVIEW #type cname fbname count flag size null float float1 - 1 - - - double double1 - 1 - - - long long1 - 1 - - - short short1 - 1 - - - int int1 - 1 - - - dec_t dec1 - 1 - 9,16 - char char1 - 1 - - - string string1 - 1 - 20 - carray carray1 - 2 CL 20 - END
Note that in this view description, the format is similar to
the FML-dependent view, except that the columns fbname
and null in the file are ignored by the view compiler.
These columns are not relevant when an FML buffer does
not stand behind the view, but it is necessary to place some
value (a dash, for example) in these columns to serve as a
placeholder.
Corresponding Data Type Definitions
The C float and double fields correspond to COBOL COMP-1 and COMP-2 respectively.
The field types long and short correspond to S9(9) COMP-5 and S9(4) COMP-5 respectively in COBOL. (The use of COMP-5 is for use with MicroFocus COBOL so that the COBOL integer fields match the data format of the corresponding C fields; the data type for VS COBOL II would simply be COMP.)
The dec_t type maps to a COBOL COMP-3 packed decimal field. Packed decimals exist in the COBOL environment as two decimal digits packed into each byte with the low-order half byte used to store the sign. The length of a packed decimal may be 1 to 9 bytes with storage available for 1 to 17 digits and a sign. The dec_t field type is supported within the VIEW definition for the conversion of packed decimals between the C and the COBOL environments. The dec_t field is defined in a VIEW with a size of two numbers separated by a comma. The number to the left of the comma is the total number of bytes that the decimal occupies in COBOL. The number to the right is the number of digits to the right of the decimal point in COBOL. The formula for conversion to the COBOL declaration is:
dec_t(m, n) <=> S9(2*m-(n+1),n)COMP-3
For example, say a size of 6,4 is specified in the VIEW. There are 4 digits to the right of the decimal point, 7 digits to the left, and the last half byte stores the sign. The COBOL application programmer would represent this as 9(7)V9(4), with the V representing the decimal point between the number of digits to each side. Note that there is no dec_t type supported in FML; if FML-dependent VIEWs are used, then the field must be mapped to a C type in the VIEW file (for instance, the packed decimal can be mapped to an FML string field and the mapping functions do the conversion between the formats).
A decimal field can be initialized and accessed in C using the
functions described in the decimal(3c) manual pages.
Creating Header Files from View Descriptions
View description files are source files. To use the view in a program, you need a header file that defines the structures in the view. You can create a header file from the myview.v view description file by invoking the view compiler, viewc(1). viewc creates two files. One is the header file and the other is the binary version of the source description file, myview.V. This binary file must be in the environment when a VIEW buffer is allocated. For an FML-dependent VIEW, the compiler is invoked as follows:
viewc myview.v
The header file it creates from the myview.v description file is shown in Figure 8.
Fig. 8: Header File Created for FML View
struct MYVIEW {
float float1;
double double1;
long long1;
short short1;
int int1;
dec_t dec1;
char char1;
char string1[20];
unsigned short L_carray1[2]; /* length array of carray1 */
short C_carray1; /* count of carray1 */
char carray1[2][20];
};
To compile a view description of an independent view, use the -n option on the command line as follows:
viewc -n myview.v
The header file created is the same with or without the -n option. Header files for views must be brought into client programs and service subroutines with #include statements.
For use with VIEW32, the viewc32 command
should be used.
Header Files from Field Tables
To create a field header file from the field table file, you use the mkfldhdr(1) command. For example:
mkfldhdr myview.flds
creates a file called myview.flds.h that can be #include'd in a service routine or client program so you can refer to fields by their symbolic names. The myview.flds.h header file produced by mkfldhdr from this field table file is shown in Figure 9.
Fig. 9: The myview.flds.h Header File
/* fname fldid */ /* ----- ----- */ #define FLOAT1 ((FLDID)24686) /* number: 110 type: float */ #define DOUBLE1 ((FLDID)32879) /* number: 111 type: double */ #define LONG1 ((FLDID)8304) /* number: 112 type: long */ #define SHORT1 ((FLDID)113) /* number: 113 type: short */ #define INT1 ((FLDID)8306) /* number: 114 type: long */ #define DEC1 ((FLDID)41075) /* number: 115 type: string */ #define CHAR1 ((FLDID)16500) /* number: 116 type: char */ #define STRING1 ((FLDID)41077) /* number: 117 type: string */ #define CARRAY1 ((FLDID)49270) /* number: 118 type: carray */
For use with FML32, the mkfldhdr32
command should be used.
Other Header Files
If you are using FML or VIEW typed buffers, #include the header files generated from their field table files or view description files as described above.
In addition, all System/T application programs must #include the atmi.h header file.
If you are using FML buffers, #include
the fml.h header file in your programs.
Environment Variables
Environment variables needed either for clients or service routines associated with a server can be set in ENVFILEs that are specified in the configuration file. The environment variables that might have to be set for field tables and view descriptions, for example, are summarized in Table 3.
Table 3: BEA TUXEDO System/T Environment Variables
| Variable | Contains | Used By |
|---|---|---|
| FIELDTBLS | comma-separated list of field table file names | client and server processes using FML buffers |
| FLDTBLDIR | colon-separated list of directories to be used to find field table files with relative file names | client and server processes using FML buffers |
| VIEWFILES | comma separated list of binary view description files | client and server processes using VIEW buffers |
| VIEWDIR | colon-separated list of directories to be used to find binary view description files | client and server processes using VIEW buffers |
For the FML32 and VIEW32 record types, the environment variables are suffixed with "32", that is, FLDTBLDIR32, FIELDTBLS32, VIEWFILES32, and VIEWDIR32.
The CC and CFLAGS environment variables are used by the buildclient(1) and buildserver(1) commands. You may want to set them in your environment to make compilation of clients and servers more convenient. Set CC to the command that invokes the C compiler. It defaults to cc. Set CFLAGS to the link edit flags you may want to use on the compile command line. Setting this variable is optional.
The location of the BEA TUXEDO System binary files must be
known to your application. It is the convention to install the
BEA TUXEDO System software under a root directory whose location
is specified in the TUXDIR environment variable. $TUXDIR/bin
must be included in your PATH in order for your
application to locate the executables for BEA TUXEDO System
commands.
Configuration File
The configuration file specifies the configuration of an application to System/T. For a BEA TUXEDO System/T application in production, it is the responsibility of the System/T administrator to set up a configuration file that defines the application. In the development environment, the responsibility may be delegated to application programmers to create their own.
If you are faced with the task of creating a configuration file, here are some suggestions:
- Borrow a file that already exists. For example, the file ubbshm that comes with the sample application is a good starting point.
- Keep it simple. For test purposes, set your application up as a shared memory, single processor system. Use regular UNIX files for your data.
- Make sure the IPCKEY parameter in the configuration file does not conflict with any others that may be in use at your installation. You should probably check this with your BEA TUXEDO System/T administrator.
- Set the UID and GID parameters so that you are the owner of the configuration.
- Read the documentation. The configuration file is
documented in the ubbconfig(5) page in Section 5 of the
BEA TUXEDO Reference Manual and in the BEA TUXEDO Administrator's Guide .
Making the Configuration Usable
The configuration file is an ASCII file. To make it usable,
you have to run tmloadcf(1)
to convert it to a binary file. The TUXCONFIG environment
variable must be set to the pathname for the binary file, and
exported.
The Bulletin Board
The bulletin board is the BEA TUXEDO System/T name for a group of data structures in a segment of shared memory that is allocated from information stored in TUXCONFIG when the application is booted. Both client and server processes attach to the bulletin board. Part of the bulletin board associates service names with the queue address of servers that advertise that service. Clients send their requests to the name of the service they want to invoke, rather than to a specific address.
All processes that are part of a System/T application share
this IPC resource.
Starting and Stopping an Application
Execute the tmboot(1) command to bring up an application. The command gets the IPC resources needed by the application, starts administrative processes and the application servers.
When it is time to bring the application down, execute the tmshutdown(1) command. tmshutdown stops the servers and releases the IPC resources used by the application, except any that might be used by the database resource manager.