Often times the Coherence distributed caches will be evaluated with respect to pre-existing local caches. The local caches generally take the form of in-processes hash maps. While Coherence does include facilities for in-process non-clustered caches, direct performance comparison between local caches and a distributed cache not realistic. By the very nature of being out of process the distributed cache must perform serialization and network transfers. For this cost you gain cluster wide coherency of the cache data, as well as data and query scalability beyond what a single JVM or machine is capable of providing. This does not mean that you cannot achieve impressive performance using a distributed cache, but it must be evaluated in the correct context.
When evaluating performance you try to establish two things, latency, and throughput. A simple performance analysis test may simply try performing a series of timed cache accesses in a tight loop. While these tests may accurately measure latency, in order to measure maximum throughput on a distributed cache a test must make use of multiple threads concurrently accessing the cache, and potentially multiple test clients. In a single threaded test the client thread will naturally spend the majority of the time simply waiting on the network. By running multiple clients/threads, you can more efficiently make use of your available processing power by issuing a number of requests in parallel. The use of batching operations can also be used to increase the data density of each operation. As you add threads you should see that the throughput continues to increase until you've maxed out the CPU or network, while the overall latency remains constant for the same period.
To show true linear scalability as you increase cluster size, you need to be prepared to be add hardware, and not simply JVMs to the cluster. Adding JVMs to a single machine will scale only up to the point where the CPU or network are fully utilized.
Plan on testing with clusters with more then just two cache servers (storage enabled nodes). The jump from one to two cache servers will not show the same scalability as from two to four. The reason for this is because by default Coherence will maintain one backup copy of each piece of data written into the cache. The process of maintaining backups only begins once there are two storage enabled nodes in the cluster (there must have a place to put the backup). Thus when you move from a one to two, the amount of work involved in a mutating operation such as cache.put actually doubles, but beyond that the amount of work stays fixed, and will be evenly distributed across the nodes.
To get the most out of your cluster it is important that you've tuned of your environment and JVMs. Please take a look at our performance tuning guide, it is a good start to getting this most out of your environment. For instance Coherence includes a registry script for Windows (optimize.reg), which will adjust a few critical settings and allow Windows to achieve much higher data rates.
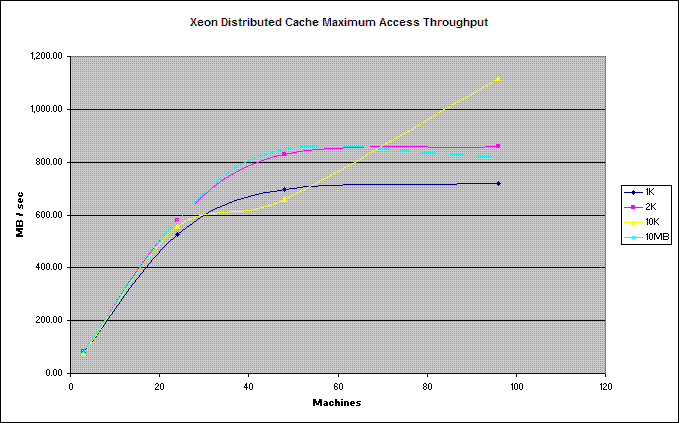
The following graphs show the results of scaling out a cluster in an environment of 100 machines. In this particular environment Coherence was able to scale to the limits of the networks switching infrastructure. Namely there were 8 sets of ~12 machines, each set having a 4Gbs link to a central switch. Thus for this test Coherence's network throughput scales up to ~32 machines at which point it has maxed out the available bandwidth, beyond that it continues to scale in total data capacity.
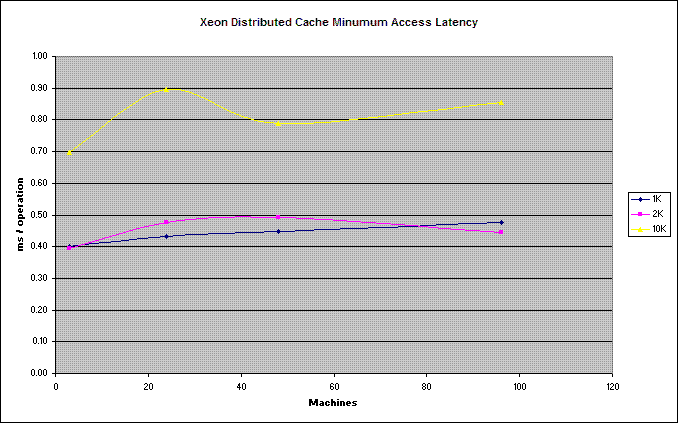
Latency for 10MB operations (~300ms) is not included in the graph for display reasons, as the payload is 1000x the next payload size. See the attached spreadsheet for raw data and additional graphs.
The attached zip file includes the Coherence based test tool used in the above tests. See the included readme.txt for details on test execution.