Managing an Object Model
Overview
This document describes best practices for managing an object model whose state is managed in a collection of Coherence named caches. Given a set of entity classes, and a set of entity relationships, what is the best means of expressing and managing the object model across a set of Coherence named caches?
Cache Usage Paradigms
The value of a clustered caching solution depends on how it is used. Is it simply caching database data in the application tier, keeping it ready for instant access? Is it taking the next step to move transactional control into the application tier? Or does it go a step further by aggressively optimizing transactional control?
Simple Data Caching
Simple data caches are common, especially in situations where concurrency control is not required (e.g. content caching) or in situations where transactional control is still managed by the database (e.g. plug-in caches for Hibernate and JDO products). This approach has minimal impact on application design, and is often implemented transparently by the Object/Relational Mapping (ORM) layer or the application server (EJB container, Spring, etc). However, it still does not completely solve the issue of overloading the database server; in particular, while non-transactional reads are handled in the application tier, all transactional data management still requires interaction with the database.
It is important to note that caching is not an orthogonal concern once data access requirements go beyond simple access by primary key. In other words, to truly benefit from caching, applications must be designed with caching in mind.
Transactional Caching
Applications that need to scale and operate independently of the database must start to take greater responsibility for data management. This includes using Coherence features for read access (read-through caching, cache queries, aggregations), features for minimizing database transactions (write-behind), and features for managing concurrency (locking, cache transactions).
Transaction Optimization
Applications that need to combine fault-tolerance, low latency and high scalability will generally need to optimize transactions even further. Using traditional transaction control, an application might need to specify SERIALIZABLE isolation when managing an Order object. In a distributed environment, this can be a very expensive operation. Even in non-distributed environments, most databases and caching products will often use a table lock to achieve this. This places a hard limit on scalability regardless of available hardware resources; in practice, this may limit transaction rate to hundreds of transactions per second, even with exotic hardware. However, locking "by convention" can help – for example, requiring that all acessors lock only the "parent" Order object. Doing this can reduce the scope of the lock from table-level to order-level, enabling far higher scalability. (Of course, some applications already achieve similar results by partitioning event processing across multiple JMS queues to avoid the need for explicit concurrency control.) Further optimizations include using an EntryProcessor to avoid the need for clustered coordination, which can dramatically increase the transaction rate for a given cache entry.
Managing the Object Model
Overview
The term "relationships" refers to how objects are related to each other. For example, an Order object may contain (exclusively) a set of LineItem objects. It may also refer to a Customer object that is associated with the Order object.
The data access layer can generally be broken down into two key components, Data Access Objects (DAOs) and Data Transfer Objects (DTOs) (in other words, behavior and state). DAOs control the behavior of data access, and generally will contain the logic that manages the database or cache. DTOs contain data for use with DAOs, for example, an Order record. Also, note that a single object may (in some applications) act as both a DTO and DAO. These terms describe patterns of usage; these patterns will vary between applications, but the core principles will be applicable. For simplicity, the examples in this document follow a "Combined DAO/DTO" approach (behaviorally-rich Object Model).
Managing entity relationships can be a challenging task, especially when scalability and transactionality are required. The core challenge is that the ideal solution must be capable of managing the complexity of these inter-entity relationships with a minimum of developer involvement. Conceptually, the problem is one of taking the relationship model (which could be represented in any of a number of forms, including XML or Java source) and providing runtime behavior which adheres to that description.
Present solutions can be categorized into a few groups:
- Code generation (.java or .class files)
- Runtime byte-code instrumentation (ClassLoader interception)
- Predefined DAO methods
Code Generation
Code generation is a popular option, involving the generation of .java or .class files. This approach is commonly used with a number of Management and Monitoring, AOP and ORM tools (AspectJ, Hibernate). The primary challenges with this approach are the generation of artifacts, which may need to be managed in a software configuration management (SCM) system.
Byte-code instrumentation
This approach uses ClassLoader interception to instrument classes as they are loaded into the JVM. This approach is commonly used with AOP tools (AspectJ, JBossCacheAop, TerraCotta) and some ORM tools (very common with JDO implementations). Due to the risks (perceived or actual) associated with run-time modification of code (including a tendency to break the hot-deploy options on application servers), this option isn't viable for many organizations and as such is a non-starter.
Developer-implemented classes
The most flexible option is to have a runtime query engine. ORM products shift most of this processing off onto the database server. The alternative is to provide the query engine inside the application tier; but again, this leads toward the same complexity that limits the manageability and scalability of a full-fledged database server.
The recommended practice for Coherence is to map out DAO methods explicitly. This provides deterministic behavior (avoiding dynamically evaluated queries), with some added effort of development. This effort will be directly proportional to the complexity of the relationship model. For small- to mid-size models (up to ~50 entity types managed by Coherence), this will be fairly modest development effort. For larger models (or for those with particularly complicated relationships), this may be a substantial development effort.
As a best practice, all state, relationships and atomic transactions should be handled by the Object Model. For more advanced transactional control, there should be an additional Service Layer which coordinates concurrency (allowing for composable transactions).
 | Composable Transactions
The Java language does not directly support composable transactions (the ability to combine multiple transactions into a single transaction). The core Coherence API, based on standard JavaSE patterns, does not either. Locking and synchronization operations support only non-composable transactions.
To quote from the Microsoft Research Paper titled "Composable Memory Transactions (PDF)":
Perhaps the most fundamental objection, though, is that lock-based programs do not compose: correct fragments may fail when combined. For example, consider a hash table with thread-safe insert and delete operations. Now suppose that we want to delete one item A from table t1, and insert it into table t2; but the intermediate state (in which neither table contains the item) must not be visible to other threads. Unless the implementor of the hash table anticipates this need, there is simply no way to satisfy this requirement. [...] In short, operations that are individually correct (insert, delete) cannot be composed into larger correct operations.
—Tim Harris et al, "Composable Memory Transactions", Section 2
This is one reason that "transparent clustering" (or any form of clustering that relies on the basic Java language features) only works for non-composable transactions. Applications may use the (composable) TransactionMap to enable composite transactions. Alternatively, applications may use transactional algorithms such as ordered locking to more efficiently support desired levels of isolation and atomicity. The "Service Layer" section below will go into more detail on the latter. |
Domain Model
Basics
A NamedCache should contain one type of entity (in the same way that a database table contains one type of entity). The only common exception to this are directory-type caches, which often may contain arbitrary values.
Each additional NamedCache consumes only a few dozen bytes of memory per participating
cluster member. This will vary, based on the backing map. Caches configured
with the <read-write-backing-map-scheme>
for transparent database integration will consume additional resources if write-behind
caching is enabled, but this will not be a factor until there are hundreds of
named caches.
If possible, cache layouts should be designed so that business transactions map to a single cache entry update. This simplifies transactional control and can result in much greater throughput.
Most caches should use meaningful keys (as opposed to the "meaningless keys" commonly used in relational systems whose only purpose is to manage identity). The one drawback to this is limited query support (as Coherence queries at present apply only to the entry value, not the entry key); to query against key attributes, the value must duplicate the attributes.
Coherence Best Practices
DAO objects must implement the getter/setter/query methods in terms of NamedCache access. The NamedCache API makes this very simple for the most types of operations, especially primary key lookups and simple search queries.
public class Order
implements Serializable
{
public static Order getOrder(OrderId orderId)
{
return (Order)m_cacheOrders.get(orderId);
}
public Customer getCustomer()
{
return (Customer)m_cacheCustomers.get(m_customerId);
}
public Collection getLineItems()
{
return ((Map)m_cacheLineItems.getAll(m_lineItemIds)).values();
}
private CustomerId m_customerId;
private Collection lineItemIds;
private static final NamedCache m_cacheCustomers = CacheFactory.getCache("customers");
private static final NamedCache m_cacheOrders = CacheFactory.getCache("orders");
private static final NamedCache m_cacheLineItems = CacheFactory.getCache("orderlineitems");
}
Service Layer
Overview
Applications that require composite transactions should use a Service Layer. This accomplishes two things. First, it allows for proper composing of multiple entities into a single transaction without compromising ACID characteristics. Second, it provides a central point of concurrency control, allowing aggressively optimized transaction management.
Automatic Transaction Management
Basic transaction management consists of ensuring clean reads (based on the isolation level) and consistent, atomic updates (based on the concurrency strategy). The TransactionMap API (accessible either through the J2CA adapter or programmatically) will handle these issues automatically.
Explicit Transaction Management
Unfortunately, the transaction characteristics common with database transactions (described as a combination of isolation level and concurrency strategy for the entire transaction) provide very coarse-grained control. This coarse-grained control is often unsuitable for caches, which are generally subject to far greater transaction rates. By manually controlling transactions, applications can gain much greater control over concurrency and therefore dramatically increase efficiency.
The general pattern for pessimistic transactions is "lock -> read -> write -> unlock". For optimistic transactions, the sequence is "read -> lock & validate -> write -> unlock". When considering a two-phase commit, "locking" is the first phase, and "writing" is the second phase. Locking individual objects will ensure REPEATABLE_READ isolation semantics. Dropping the locks will be equivalent to READ_COMMITTED isolation.
By mixing isolation and concurrency strategies, applications can achieve higher transaction rates. For example, an overly pessimistic concurrency strategy will reduce concurrency, but an overly optimistic strategy may cause excessive transaction rollbacks. By intelligently deciding which entities will be managed pessimistically, and which optimistically, applications can balance the tradeoffs. Similarly, many transactions may require strong isolation for some entities, but much weaker isolation for other entities. Using only the necessary degree of isolation can minimize contention, and thus improve processing throughput.
Optimized Transaction Processing
There are a number of advanced transaction processing techniques that can best be applied in the Service Layer. Proper use of these techniques can dramatically improve throughput, latency and fault-tolerance, at the expense of some added effort.
The most common solution relates to minimizing the need for locking. Specifically, using an ordered locking algorithm can reduce the number of locks required, and also eliminate the possibility of deadlock. The most common example is to lock a parent object prior to locking child object. In some cases, the Service Layer can depend on locks against the parent object to protect the child objects. This effectively makes locks coarse-grained (slightly increasing contention) and substantially minimizes the lock count.
public class OrderService
{
public void executeOrderIfLiabilityAcceptable(Order order)
{
OrderId orderId = order.getId();
m_cacheOrders.lock(orderId, -1);
try
{
BigDecimal outstanding = new BigDecimal(0);
Collection lineItems = order.getLineItems();
for (Iterator iter = lineItems.iterator(); iter.hasNext(); )
{
LineItem item = (LineItem)iter.next();
outstanding = outstanding.add(item.getAmount());
}
Customer customer = order.getCustomer();
if (customer.isAcceptableOrderSize(outstanding))
{
order.setStatus(Order.REJECTED);
}
else
{
order.setStatus(Order.EXECUTED);
}
m_cacheOrders.put(order);
}
finally
{
m_cacheOrders.unlock(orderId);
}
}
}
Relationship Patterns
Managing Collections of Child Objects
Shared Child Objects
For shared child objects (e.g. two parent objects may both refer to the same child object), the best practice is to maintain a list of child object identifiers (aka foreign keys) in the parent object. Then use the NamedCache.get() or NamedCache.getAll() methods to access the child objects. In many cases, it may make sense to use a Near cache for the parent objects and a Replicated cache for the referenced objects (especially if they are read-mostly or read-only).
If the child objects are read-only (or stale data is acceptable), and the entire object graph is often required, then including the child objects in the parent object may be beneficial in reducing the number of cache requests. This is less likely to make sense if the referenced objects are already local, as in a Replicated, or in some cases, Near cache, as local cache requests are very efficient. Also, this makes less sense if the child objects are large. On the other hand, if fetching the child objects from another cache is likely to result in additional network operations, the reduced latency of fetching the entire object graph at once may outweigh the cost of inlining the child objects inside the parent object.
Owned Child Objects
If the objects are owned exclusively, then there are a few additional options. Specifically, it is possible to manage the object graph "top-down" (the normal approach), "bottom-up", or both. Generally, managing "top-down" is the simplest and most efficient approach.
If the child objects are inserted into the cache before the parent object is updated (an "ordered update" pattern), and deleted after the parent object's child list is updated, the application will never see missing child objects.
Similarly, if all Service Layer access to child objects locks the parent object first, SERIALIZABLE-style isolation can be provided very inexpensively (with respect to the child objects).
Bottom-Up Management of Child Objects
To manage the child dependencies "bottom-up", tag each child with the parent identifier. Then use a query (semantically, "find children where parent = ?") to find the child objects (and then modify them if needed). Note that queries, while very fast, are slower than primary key access. The main advantage to this approach is that it reduces contention for the parent object (within the limitations of READ_COMMITTED isolation). Of course, efficient management of a parent-child hierarchy could also be achieved by combining the parent and child objects into a single composite object, and using a custom "Update Child" EntryProcessor, which would be capable of hundreds of updates per second against each composite object.
Bi-Directional Management of Child Objects
Another option is to manage parent-child relationships bi-directionally. An advantage to this is that each child "knows" about its parent, and the parent "knows" about the child objects, simplifying graph navigation (e.g. allowing a child object to find its sibling objects). The biggest drawback is that the relationship state is redundant; for a given parent-child relationship, there is data in both the parent and child objects. This complicates ensuring resilient, atomic updates of the relationship information and makes transaction management more difficult. It also complicates ordered locking/update optimizations.
Colocating Owned Objects
Denormalization
Exclusively owned objects may be managed as normal relationships (wrapping getters/setters around NamedCache methods), or the objects may be embedded directly (roughly analogous to "denormalizing" in database terms). Note that by denormalizing, data is not being stored redundantly, only in a less flexible format. However, since the cache schema is part of the application, and not a persistent component, the loss of flexibility is a non-issue as long as there is not a requirement for efficient ad hoc querying. Using an application-tier cache allows for the cache schema to be aggressively optimized for efficiency, while allowing the persistent (database) schema to be flexible and robust (typically at the expense of some efficiency).
The decision to inline child objects is dependent on the anticipated access patterns against the parent and child objects. If the bulk of cache accesses are against the entire object graph (or a substantial portion thereof), it may be optimal to embed the child objects (optimizing the "common path").
To optimize access against a portion of the object graph (e.g. retrieving a single child object, or updating an attribute of the parent object), use an EntryProcessor to move as much processing to the server as possible, sending only the required data across the network.
Affinity
Partition Affinity
can be used to optimize colocation of parent and child objects (ensuring that
the entire object graph is always located within a single JVM). This will minimize
the number of servers involved in processing a multiple-entity request (queries,
bulk operations, etc.). Affinity offers much of the benefit of denormalization
without having any impact on application design. However, denormalizing structures
can further streamline processing (e.g., turning graph traversal into a single
network operation).
Managing Shared Objects
Shared objects should be referenced via a typical "lazy getter" pattern. For read-only data, the returned object may be cached in a transient (non-serializable) field for subsequent access.
public class Order
{
public Customer getCustomer()
{
return (Customer)m_cacheCustomers.get(m_customerId);
}
}
As usual, multiple-entity updates (e.g. updating both the parent and a child object) should be managed by the service layer.
Refactoring Existing DAOs
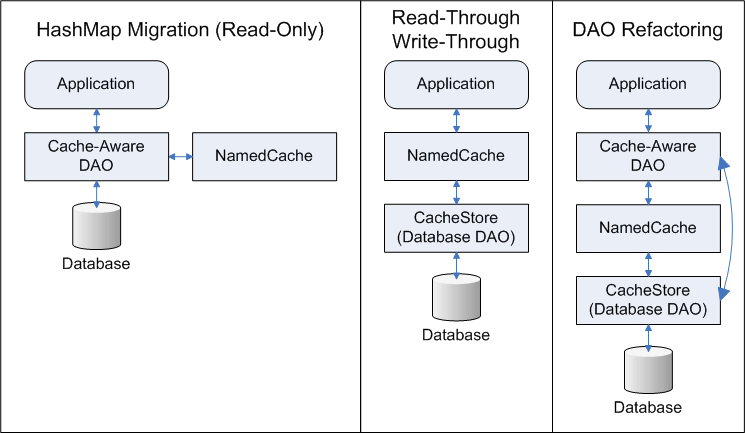
Generally, when refactoring existing DAOs, the pattern is to split the existing DAO into an interface and two implementations (the original database logic and the new cache-aware logic). The application will continue to use the (extracted) interface. The database logic will be moved into a CacheStore module. The cache-aware DAO will access the NamedCache (backed by the database DAO). All DAO operations that can't be mapped onto a NamedCache will be passed directly to the database DAO.
All trademarks and registered trademarks are the property of their respective owners.