| All of the Data Grid capabilities described below are features of Coherence Enterprise Edition and higher. |
| All of the Data Grid capabilities described below are features of Coherence Enterprise Edition and higher. |
Coherence provides a data grid by dynamically, transparently and automatically partitioning the data set across all storage enabled nodes in a cluster. We have been doing some scale out testing on our new Dual 2.3GHz PowerPC G5 Xserve cluster and here is one of the tests that we have performed using the Data Grid Aggregation feature.
The new InvocableMap tightly binds the concepts of a data grid (i.e. partitioned cache) and the processing of the data stored in the grid. When you take the InvocableMap and combine it with the linear scalability of Coherence itself you get an extremely powerful solution. The following tests show that you can take an application that Coherence provides you (the developer, the engineer, the architect, etc.) the ability to build an application once that can scale out to handle any SLA requirement, any increase in throughput requirements. For example, the following test demonstrate Coherence's ability to linearly increase the number of trades aggregated per second as you increase hardware. I.e. if one machine can aggregate X trades per second, if you add a second machine to the data grid you will be able to aggregate 2X trades per second, if you add a third machine to the data grid you will be able to aggregate 3X trades per second and so on...
First, we need some data to aggregate. In this case we used a Trade object with a three properties Id, Price and Symbol.
package com.tangosol.examples.coherence.data; import com.tangosol.util.Base; import com.tangosol.util.ExternalizableHelper; import com.tangosol.io.ExternalizableLite; import java.io.IOException; import java.io.NotActiveException; import java.io.DataInput; import java.io.DataOutput; /** * Example Trade class * * @author erm 2005.12.27 */ public class Trade extends Base implements ExternalizableLite { /** * Default Constructor */ public Trade() { } public Trade(int iId, double dPrice, String sSymbol) { setId(iId); setPrice(dPrice); setSymbol(sSymbol); } public int getId() { return m_iId; } public void setId(int iId) { m_iId = iId; } public double getPrice() { return m_dPrice; } public void setPrice(double dPrice) { m_dPrice = dPrice; } public String getSymbol() { return m_sSymbol; } public void setSymbol(String sSymbol) { m_sSymbol = sSymbol; } /** * Restore the contents of this object by loading the object's state from the * passed DataInput object. * * @param in the DataInput stream to read data from in order to restore the * state of this object * * @throws IOException if an I/O exception occurs * @throws NotActiveException if the object is not in its initial state, and * therefore cannot be deserialized into */ public void readExternal(DataInput in) throws IOException { m_iId = ExternalizableHelper.readInt(in); m_dPrice = in.readDouble(); m_sSymbol = ExternalizableHelper.readSafeUTF(in); } /** * Save the contents of this object by storing the object's state into the * passed DataOutput object. * * @param out the DataOutput stream to write the state of this object to * * @throws IOException if an I/O exception occurs */ public void writeExternal(DataOutput out) throws IOException { ExternalizableHelper.writeInt(out, m_iId); out.writeDouble(m_dPrice); ExternalizableHelper.writeSafeUTF(out, m_sSymbol); } private int m_iId; private double m_dPrice; private String m_sSymbol; }
The cache configuration is easy through the XML Cache Configuration Elements. Here I define one wildcard cache-mapping that maps to one caching-scheme which has unlimited capacity:
<?xml version="1.0"?> <!DOCTYPE cache-config SYSTEM "cache-config.dtd"> <cache-config> <caching-scheme-mapping> <cache-mapping> <cache-name>*</cache-name> <scheme-name>example-distributed</scheme-name> </cache-mapping> </caching-scheme-mapping> <caching-schemes> <!-- Distributed caching scheme. --> <distributed-scheme> <scheme-name>example-distributed</scheme-name> <service-name>DistributedCache</service-name> <backing-map-scheme> <class-scheme> <scheme-ref>unlimited-backing-map</scheme-ref> </class-scheme> </backing-map-scheme> <autostart>true</autostart> </distributed-scheme> <!-- Backing map scheme definition used by all the caches that do not require any eviction policies --> <class-scheme> <scheme-name>unlimited-backing-map</scheme-name> <class-name>com.tangosol.util.SafeHashMap</class-name> <init-params></init-params> </class-scheme> </caching-schemes> </cache-config>
ReflectionExtractor extPrice = new ReflectionExtractor("getPrice"); m_cache.addIndex(extPrice, true, null);
Adding an index to this property increases performance by allowing Coherence to access the values directly rather than having to deserialize each item to accomplish the calculation. In our tests the aggregation speed was increased by more than 2x after an index was applied.
Double DResult; DResult = (Double) m_cache.aggregate((Filter) null, new DoubleSum("getPrice"));
| The aggregation is initiated and results received by a single client. I.e. a single "low-power" client is able to utilize the full processing power of the cluster/data grid in aggregate to perform this aggregation in parallel with just one line of code. |
| Client The test client itself is run on an Intel Core Duo iMac which is marked as Local Storage disabled. The command line used to start the client was: java ... -Dtangosol.coherence.distributed.localstorage=false -Xmx128m -Xms128m com.tangosol.examples.coherence.invocable.TradeTest |
| Server In this case a "JVM" refers to a cache server instance (i.e. a data grid node) that is a standalone JVM responsible for managing/storing the data. I used the DefaultCacheServer helper class to accomplish this. The command line used to start the server was: java ... -Xmx384m -Xms384m -server com.tangosol.net.DefaultCacheServer |
The JDK used on both the client and the servers was Java(TM) 2 Runtime Environment, Standard Edition (build 1.5.0_05-84)
| The lowest and highest times were not used in the calculations below resulting in a data set of eighteen results used to create an average. |
As you can see in the following graph the average aggregation time for the aggregations decreases linearly as more cache servers/machines are added to the data grid!

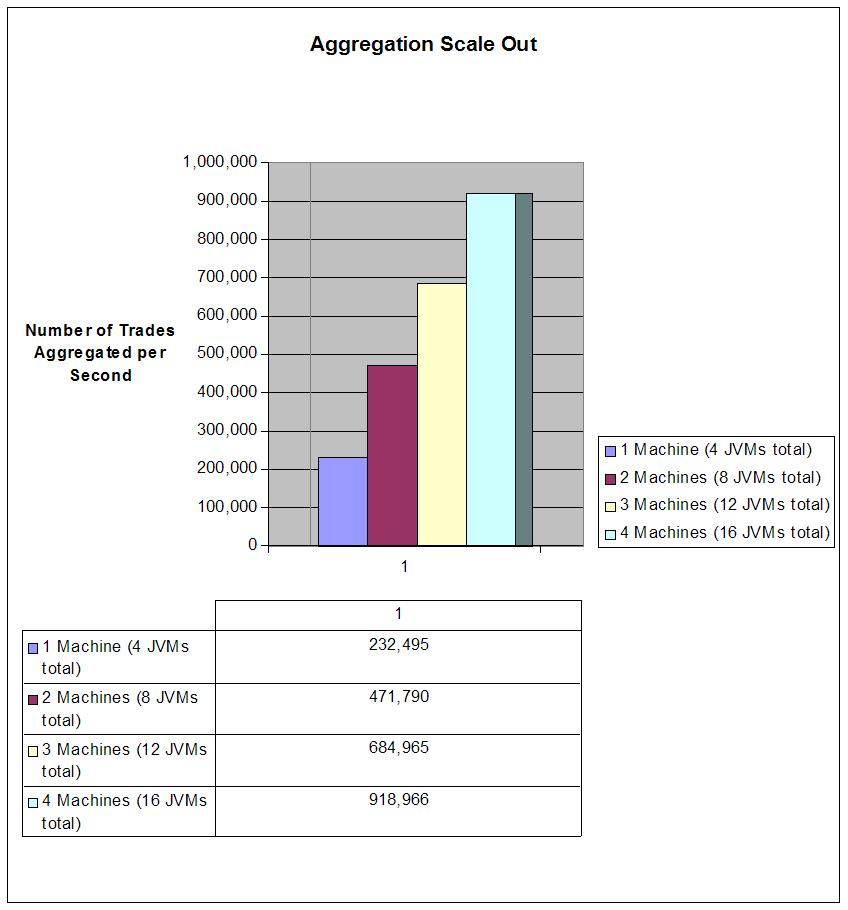
Similarly, the following graph illustrates how the aggregations per second scales linearly as you add more machines! When moving from 1 machine to 2 machines the trades aggregated per second double, when moving from 2 machines to 4 machines the trades aggregated per second double again.
| FAILOVER! The above aggregations will complete successfully and correctly even if one of the cache servers or and entire machine fails during the aggregation! |
Combining the Coherence data grid (i.e. partitioned cache) with the InvocableMap features enables: