 Data Sources
Data Sources
This section provides an overview of data sources and discusses:
Required data source types
Database structures
System data source connections
System table caching
Storing object librarian and central objects
Data Sources
The data sources define where the database tables reside and where the software runs logic objects for the enterprise. Data sources can point to:
A database in a specific location (for example, a local database, such as E1Local located in \E900\data, or an iSeries data library, such as PRODDATA)
A specific machine in the enterprise that processes logic
Data source definitions are stored in the Data Source Master table (F98611). Workstations use a Common table F98611, which generally resides in the system data source on the enterprise server. Oracle's JD Edwards EnterpriseOne servers that process logic and request data require their own unique definitions for data sources; therefore, they have their own table F98611 in the server map data source.
A least two sets of table F98611 exist. They reside in a centralized system data source normally kept on an enterprise server which is accessed by workstations, and in a server map data source, which each logic server requires.
 Data Source Types
Data Source Types
Data sources are the building blocks that you use to set up an enterprise configuration. Data sources define all the databases and logic machines required by the Oracle JD Edwards EnterpriseOne configuration. Each database and machine in the enterprise must be defined as a data source for JD Edwards EnterpriseOne to recognize it.
There are two types of data sources:
|
A database is a grouping of tables in a database management system. You must identify databases to the applications that access them. You can distribute databases across a network and involve various servers and database management systems. A database data source identifies the database information that the software needs to connect to a database. |
|
|
A logic machine is the machine on which batch applications and master business functions run. You must identify logic machines using a data source definition. The data source definition must include the network information about the machine, such as a server name - HP9000, for example. When mapping logic objects for distributed processing, the software uses the machine data source (distributed processing data source) as the target location for processing logic objects. |
Data Source Names
Data source names that you define are names used to identify the data source. You should use a meaningful name for the data sources. For example, to indicate that you are storing business data for production users, the data source name could be Business Data - Prod.
JD Edwards EnterpriseOne provides demonstration data source names at installation; you can use these for your own data sources.
See JD Edwards EnterpriseOne Applications Release 9.0 Upgrade Guide (for your database and platform)
Data Source Definitions
The data source definition must contain information about the database and the server in which it is located. Different database management systems identify the databases in different ways. For example, you must identify Oracle databases by the Oracle SQL*Net V.2 connect string. You must identify databases that you access through ODBC by the ODBC data source name.
Network Machine/Server Names
Database management systems reside on a machine/server. You must identify this machine/server to the network so that other computers can access its resources. You must provide to JD Edwards EnterpriseOne (in the data source definition) the machine/server name for the machine/server that hosts the database management system in which the database resides.
Required Data Source Types
You must set up a minimum number of data sources for JD Edwards EnterpriseOne to run. Two of the required data sources define machines that process logic in the enterprise. The other data sources define various databases used in the enterprise.
The installation software provides samples of these required data sources to build your system configuration:
Database Structures
All supported database platforms have a similar configuration of tables and data sources.
This diagram illustrates owners and databases for four different platforms:
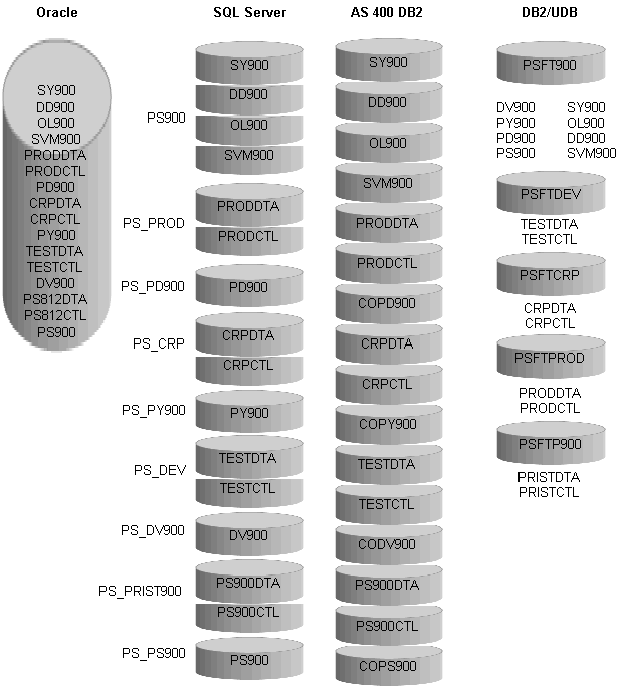
Example of owners and databases structure
Oracle Structure and JD Edwards EnterpriseOne
The basic architecture of an Oracle database includes many different logical and physical storage structures.
Typically, an Oracle database is divided into one or more logical storage structures. The highest-level structures are table spaces and user schema. These structures provide two categories that data may be logically grouped. Data belonging to one table space may belong to different schema, and data for one schema may belong to different table spaces.
This diagram illustrates the Oracle structure with JD Edwards EnterpriseOne:
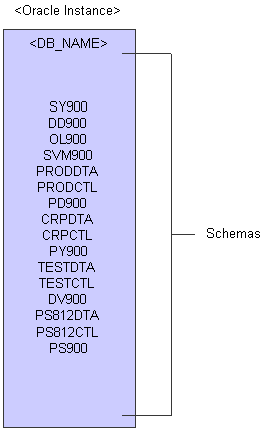
Oracle Structure and JD Edwards EnterpriseOne
SQL Server Structure and JD Edwards EnterpriseOne
SQL Server provides a comprehensive platform that makes it easy to design, build, manage, and use data warehousing solutions which enable your organization to make effective business decisions based on timely and accurate information. SQL Server delivers nine separate databases with JD Edwards EnterpriseOne during an installation.
This diagram illustrates the SQL structure with JD Edwards EnterpriseOne:
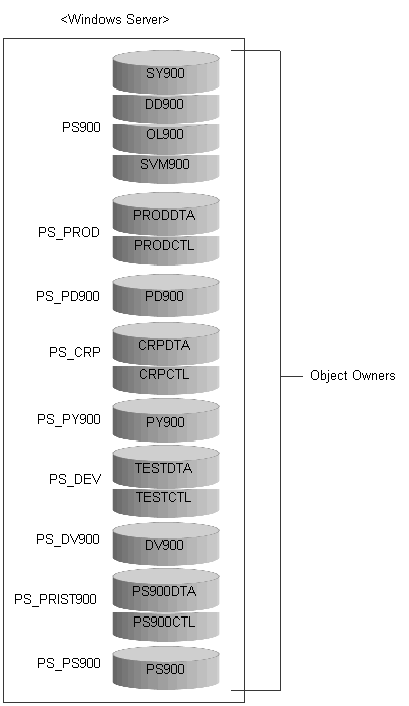
SQL structure with JD Edwards EnterpriseOne
AS400 DB/2 Server Structure and JD Edwards EnterpriseOne
AS/400 DB2 is the relational database manager that is fully integrated and provides numerous functions and features such as triggers, stored procedures, and dynamic bitmapped indexing that serve a wide variety of application types. These applications range from traditional host-based applications to client/server solutions to business intelligence applications.
In the AS/400 system, each file (also called a file object) has a description that describes the file characteristics and how the data associated with the file is organized into records and the fields in the records. The operating system uses this description whenever a file is processed.
AS400 DB/2 installations store all tables in their respective data sources in a single database.
This diagram illustrates the AS400 DB/2 structure with JD Edwards EnterpriseOne:
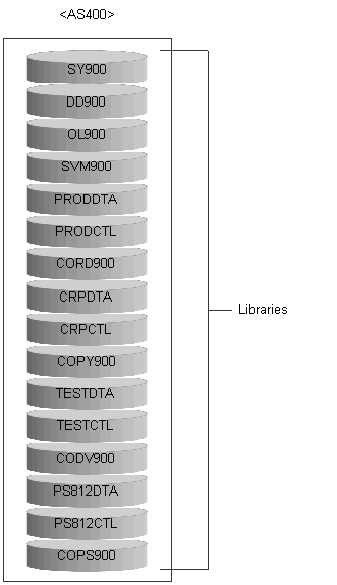
AS400 DB/2 structure with JD Edwards EnterpriseOne
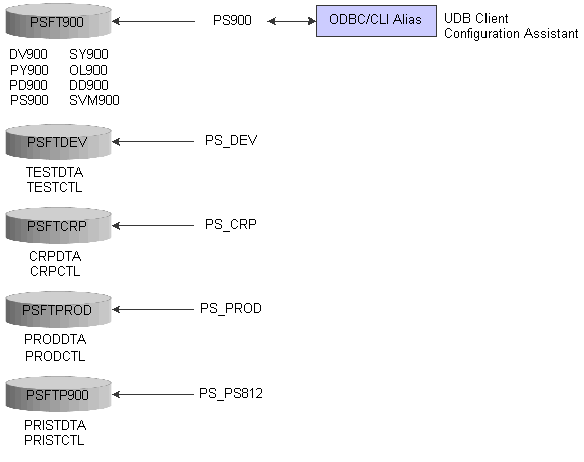
DB2/UDB 8.1.4 Structure for JD Edwards EnterpriseOne
Every data element in a database is stored in a column of a table, and each column is defined to have a data type. The data type places limits on the types of values you can put into the column and the operations you can perform on them. DB2 includes a set of built-in data types with defined characteristics and behaviors: character strings, numerics, datetime values, large objects, nulls, graphic strings, binary strings, and datalinks.
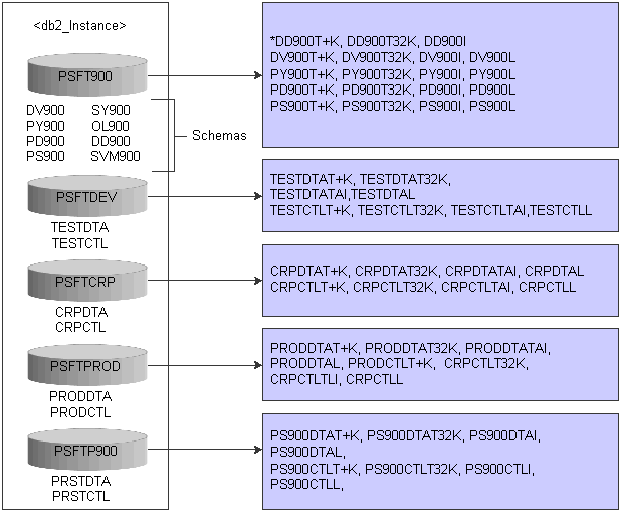
When organizing the data into tables, it is beneficial to group tables and other related objects together. This is done by defining a schema. Information about the schema is kept in the system catalog tables of the database to which you are connected. As other objects are created, they can be placed within this schema.
Each schema has a set of four dedicated tablespaces in which the data is physically stored. IBM recommends that each tablespace be stored on a separate disk drive.
This diagram illustrates the DB2/UDB 8.1.4 structure with JD Edwards EnterpriseOne:
Schemas and tablespaces for DB2/UDB 8.1.4
This diagram illustrates the schemas and associated tablespaces for DB2/UDB 8.1.4:
Schemas and tablespaces for DB2/UDB 8.1.4
System Data Source Connections
When JD Edwards EnterpriseOne starts on a workstation, the software attempts to connect to the base data source found in the workstation jde.ini file. If this data source is unavailable, the software attempts to connect to a secondary data source for system information. It is important to have processes for ensuring that the alternate system data source location contains current information. You can maintain an alternate data source's information using table conversion or data replication.
The jde.ini file should look like the example for the primary system data source connection:
[DB SYSTEM SETTINGS]
.
.
Default Env=DEMO900A
Default PathCode=DEMO
Base Datasource=System 900
Database=System 900
.
.
.
Secondary System Data Source connection
[DB SYSTEM SETTINGS - SECONDARY]
Base Datasource=Access32
Object Owner=
Server=
Database=Access32
During installation, the Release Master application relates the system data source to a release. Configuring the release updates the setup.inf file used during the workstation install to create the jde.ini file.
See Also
Major Technical Tables in the JD Edwards EnterpriseOne Guide 9.0 Installation Supplemental Reference
System Table Caching
When a user firsts logs on, the software uses the user ID and environment to retrieve information from the system tables for that user and environment. This information is cached in memory on the workstation. Any time a change is made to the central system tables, dynamic caching of the system information occurs for those workstations with an active JD Edwards EnterpriseOne session.