| Oracle Data Mining概要 11g リリース2(11.2) E48231-01 |
|


 前 |
 次 |
この章では、Oracle Data Miningでサポートされている分類アルゴリズムの1つであるディシジョン・ツリーについて説明します。
この章には、次の項が含まれます。
Naive Bayes同様、ディシジョン・ツリー・アルゴリズムは条件付き確率に基づきます。ただし、ディシジョン・ツリーでは、Naive Bayesとは異なり、ルールが生成されます。ルールは、ユーザーが容易に理解でき、レコード・セットを識別するためにデータベース内で簡単に使用できる条件文です。
データ・マイニングの一部のアプリケーションでは、モデルの品質全体を評価する際に、ある結果または別の結果を予測する理由は、重要ではない場合があります。別の用途では、決定の理由を説明できることが不可欠となる場合があります。たとえば、マーケティングの専門家は、マーケティング・キャンペーンを成功させるために、顧客の各セグメントに関する説明をすべて必要とします。ディシジョン・ツリー・アルゴリズムはこのような用途に適しています。
Oracle Data Miningでは、ルールを提供するアルゴリズムがいくつかサポートされています。ディシジョン・ツリーの他にも、クラスタリング・アルゴリズム(第7章を参照)では、クラスタのメンバーによって共有される条件を記述するルールが提供され、相関ルール(第8章を参照)では、属性間の相関を記述するルールが提供されます。
ルールではモデルの透明性が提供され、モデルの内部機構について知ることができます。ルールは、モデルの予測の根拠を示します。Oracle Data Miningではモデルの透明性が高いレベルで確保されています。ルールが提供されるのは一部のアルゴリズムですが、モデルの詳細はすべてのアルゴリズムで提供されます。モデルの詳細を調べて、アルゴリズムによる属性の内部的な処理方法(変換や逆変換など)を決定できます。透明性については、第19章のデータ準備の説明や『Oracle Data Miningアプリケーション開発者ガイド』内のモデル作成の説明を参照してください。
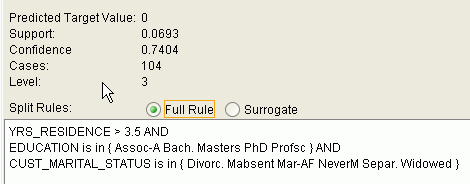
図11-1に、ディシジョン・ツリー・モデルによって生成されるルールを示します。このルールは、ポイント・カードが与えられている場合に顧客が消費を増やす確率を予測するディシジョン・ツリーから生成されています。ターゲット値の0は消費を増やす可能性がないことを、1は増やす可能性があることを意味しています。
図11-1のルールは、次の条件文を表しています。
IF
(current residence > 3.5 and has college degree and is single)
THEN
predicted target value = 0
このルールは完全なルールです。サロゲート・ルールは適用時に使用できる関連属性で、分割に必要な属性がない場合に使用されます。
信頼度と支持度はルールのプロパティです。これらの統計上の測度は、ルールおよび予測のランク付けに使用できます。
支持度: ルールを満たすトレーニング・データセット内のレコード数
信頼度: ルールが満たされている場合に、予測結果が発生する可能性
たとえば、1000人の顧客のケース(1000ケース)について考えてみます。すべての顧客のうち、100人が指定した条件を満たします。100人のうち、75人が消費を増やす可能性があり、消費を増やす可能性がありません。ルールの支持度は100/1000 (10%)です。ルールを満たすケースの予測の信頼度(消費を増やす可能性)は、75/100 (75%)です。
ディシジョン・ツリー・アルゴリズムは、ユーザーによる操作をあまり必要とせずに、正確かつ解釈可能なモデルを作成できます。このアルゴリズムは、2項および多クラスのどちらの分類問題にも使用できます。
アルゴリズムは、作成時および適用時ともに高速です。ディシジョン・ツリーの作成プロセスは並列処理されます。(スコアリングはアルゴリズムに関係なく並列処理されます。)
ディシジョン・ツリーのスコアリングは特に高速です。モデル作成時に作成されるツリー構造は、一連(通常、2から7)の単純なテストに使用されます。各テストは、単一の予測子に基づきます。これは、値のリストにIN(含まれる)かNOT IN(含まれない)か(質的予測子)、または、一定の値に対してLESS THAN(未満)かEQUAL TO(等しい)か(量的予測子)のメンバーシップに関するテストです。
ユーザーは、ディシジョン・ツリー・モデルを表すXMLを生成できます。生成されるXMLは、Data Mining GroupのPredictive Model Markup Language (PMML)バージョン2.1の仕様に示されている定義に準拠します。この仕様は、http://www.dmg.orgで入手できます。
ディシジョン・ツリーは、一連の質問を問うことによってターゲット値を予測します。各段階で問われる質問はそれぞれ、直前の質問に対する回答によって決まります。最終的に特定のターゲット値を一意に識別できるような質問を重ねていきます。図形的には、このプロセスがツリー構造を形成します。
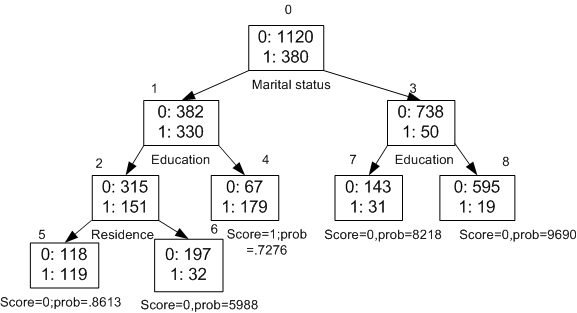
図11-2は、9個のノード(および対応する9個のルール)を持つディシジョン・ツリーです。ターゲット属性は2値で、顧客が消費を増やす場合は1、増やさない場合は0です。ツリーにおける最初の分岐は、CUST_MARITAL_STATUS属性に基づきます。このツリーのルート(ノード0)はノード1とノード3に分岐します。既婚者はノード1に、独身者はノード3に属します。
ノード1には、次のルールが関連付けられています。
Node 1 recordCount=712,0 Count=382, 1 Count=330 CUST_MARITAL_STATUS isIN "Married",surrogate:HOUSEHOLD_SIZE isIn "3""4-5"
ノード1には712個のレコード(ケース)が含まれています。この712ケースのすべてにおいて、CUST_MARITAL_STATUS属性は顧客が結婚していることを示しています。これらのケースのうち、消費を増やす可能性がないターゲット値0を382のケースがとり、消費を増やす可能性があるターゲット値1を330のケースがとります。
ディシジョン・ツリー・アルゴリズムは、トレーニング・プロセスにおいて、ケース(レコード)のセットを2つの子ノードに分割する最も効率的な方法を繰り返し見つける必要があります。Oracle Data Miningでは、この分岐の計算用に2つの同種メトリック(giniおよびentropy)を使用できます。デフォルトのメトリックはginiです。
同種メトリックでは、代替分岐条件の質を評価し、その結果、最も同質な子ノードを選択します。均質性は、純粋度とも呼ばれ、結果の子ノードが同じターゲット値のケースで構成される程度を示します。子ノードの純粋度を最大限に高めることを目的としています。たとえば、ターゲットが、はい、または、いいえ(消費を増やす可能性がある場合とない場合)のいずれかのとき、消費を増やすケースがほとんどのノードと、消費を増やさないケースがほとんどのノードを生成することが目的となります。
ディシジョン・ツリーを含むすべての分類アルゴリズムでは、適用時にコスト/利益マトリックスを使用できます。ディシジョン・ツリー・モデルの作成およびスコアリングに同じコスト・マトリックスを使用したり、スコアリングに異なるコスト/利益マトリックスを指定したりすることが可能です。
原理上は、ディシジョン・ツリー・アルゴリズムでは、トレーニング・サンプルを完全に分類するのに十分な深さまでツリーの各枝を増やすことができます。これは、場合によっては理にかなった方策ですが、実際には、データ内にノイズが存在する場合や、トレーニング・サンプルの数が少なすぎて真のターゲットの機能を代表するサンプルを生成できない場合に、扱いにくくなることがあります。どちらの場合でも、この単純なアルゴリズムでは、トレーニング・サンプルにオーバーフィットするツリーが生成される可能性があります。オーバーフィットとは、あるモデルで、そのモデルの作成に使用されたデータは正確に予測できるが、新たに提示されたデータに対しては満足に予測できない状態を指します。
オーバーフィットを回避するために、Oracle Data Miningでは自動のプルーニング(枝刈り)、およびツリーの拡大を制御する設定可能な制限条件をサポートしています。制限条件を使用すると、条件が満たされた場合に以降の分岐が回避されます。プルーニングによって、予測能力がほとんどない枝を取り除くことができます。
ディシジョン・ツリー・アルゴリズムには、分岐および終了基準に対して妥当なデフォルト値が実装されています。ただし、微調整のために複数の構築設定を使用できます。
ツリーの最適な分岐条件を見つけるための同種メトリックを指定できます。デフォルトのメトリックはginiです。entropyメトリックも使用できます。
ツリーの拡大を制御する設定も使用できます。ツリーの最大深度、子ノードで必要とされるケースの最小数、追加の分岐を可能にするためにノードで必要とされるケースの最小数、子ノードのケースの最小数、および追加の分岐を可能にするためにノードで必要とされるケースの最小数を指定できます。
|
関連項目: 詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。 |
ディシジョン・ツリー・アルゴリズムは、自身のデータ準備を内部的に管理します。データを事前処理する必要はありません。ディシジョン・ツリーは自動データ準備の影響を受けません。
ディシジョン・ツリーは、欠損値を、ランダムに欠損した値として解釈します。アルゴリズムでは、ネストした表はサポートされていないため、スパース・データもサポートされていません。