| Oracle Data Mining概要 11g リリース2(11.2) E48231-01 |
|


 前 |
 次 |
この章では、データ・マイニング技術に関する概要を説明します。
|
注意: データ・マイニングに関する情報は、幅広く提供されています。現在の知識に関係なく、データ・マイニングに関して役立つドキュメントや記事を見つけることができます。たとえば、http://en.wikipedia.org/wiki/Data_miningです。 |
この章には、次の項が含まれます。
データ・マイニングとは、大量に保管されているデータを自動的に検索して、単純な分析では得られないパターンや傾向を見つけることです。データ・マイニングでは高度な数学的アルゴリズムを使用して、データを分割し、将来のイベントの発生確率を判断します。データ・マイニングは、データからの知識発見(KDD)としても知られています。
データ・マイニングの主要な特性を次に示します。
パターンの自動検出
発生確率の高い結果の予測
実用的な情報の作成
大規模なデータセットおよびデータベースへの特化
データ・マイニングを行うと、単純な問合せや報告技術では解決できない問題を解決できます。
データ・マイニングは、モデルを作成することによって達成されます。モデルはアルゴリズムを使用してデータセットに作用します。自動検出という概念は、データ・マイニング・モデルの実行に相当します。
データ・マイニング・モデルは、そのモデル作成の基になったデータのマイニングに使用できますが、ほとんどのタイプのモデルは新しいデータに一般化することが可能です。新しいデータに対してモデルを適用するプロセスはスコアリングとも呼ばれます。
|
関連項目: Oracle Data Miningでのスコアリングおよび配置については、『Oracle Data Miningアプリケーション開発者ガイド』を参照してください。 |
データ・マイニングの多くの形式には予測の側面があります。たとえば、あるモデルは、教育レベルなどの人口統計要素に基づいて収入を予測します。予測には、確率(この予測が正しいことの確からしさ)が関連しています。予測確率は信頼度(この予測を信頼できる程度)とも呼ばれます。
予測データ・マイニングの一部の形式では、特定の結果を想定するルールが生成されますたとえば、ルールでは、特定の地区に住む学士号を持つ人は、地域の平均を超える収入を持つ可能性が高いことが示されます。ルールには、関連付けられた支持度(母集団の何割がルールを満たすか)があります。
データ・マイニングの他の形式として、データ内の自然なグループを識別するというものがあります。たとえば、モデルによって、母集団のうち、収入が特定の範囲内にある集団、良好な運転歴を持つ集団、年単位で新車をリースする集団を識別するような場合です。
データ・マイニングでは、大量のデータから実用的な情報を導き出すことができます。たとえば、都市設計家の場合、低所得者向け住宅を開発する際に、人口統計に基づいて収入を予測するモデルを使用することが可能です。自動車のリース会社では、付加価値の高い顧客を対象とする販促を計画するために、顧客の各セグメントを識別するモデルを使用できます。
データ・マイニングと統計はかなりの部分で重複しています。実際、データ・マイニングで使用される技術のほとんどは統計の範疇に収まります。しかし、データ・マイニング技術は従来の統計手法と同一ではありません。
従来の統計手法では一般的に、モデルの精度を検証するためにユーザーとの対話が相当量必要になります。そのため、統計手法の自動化は難しい場合があります。さらに、統計手法では通常、非常に大規模なデータセットに対しては適切な見積りがなされません。統計手法は、大規模な母集団内の小規模な代表サンプルに基づいた仮説の検定または相関の検出に依存しているためです。
データ・マイニング手法は大規模なデータセットに適していて、容易に自動化できます。実際、データ・マイニング・アルゴリズムでは多くの場合、良質なモデルを作成するために大規模なデータセットが必要とされます。
On-Line Analytical Processing(OLAP)は、共有されている多次元データの高速な分析であると定義できます。OLAPとデータ・マイニングは異なりますが、相互に補完的なアクティビティです。
OLAPでは、データ集約、コスト割当て、時系列分析およびwhat-if分析などのアクティビティがサポートされています。ただし、ほとんどのOLAPシステムには、時系列予測のサポートを超える帰納的推論の機能はありません。特定のサンプルから一般的な結論を導き出すプロセスである帰納的推論は、データ・マイニングの特性です。帰納的推論は、計算論的学習とも呼ばれます。
OLAPシステムではデータの多次元的ビューが提供され、階層が完全にサポートされます。このデータ・ビューは、企業や組織の分析に一般的に使用される様式です。一方、データ・マイニングには通常の場合、次元や階層の概念はありません。
データ・マイニングとOLAPは、様々な方法で統合できます。たとえば、データ・マイニングを使用して、キューブ用のディメンションの選択、ディメンション用の新しい値の作成、キューブ用の新しいメジャーの作成などが可能です。OLAPを使用すると、データ・マイニングの結果を様々な粒度レベルで分析できます。
データ・マイニングを使用すると、より興味深い有益なキューブを作成できます。たとえば、予測データ・マイニングの結果をカスタム・メジャーとしてキューブに追加できます。このようなメジャーにより、各顧客について「債務を履行しない可能性が高い」または「購入する可能性が高い」などの情報を提供できます。OLAP処理を使用すれば、さらに確率を集計したり要約したりできます。
データは、フラット・ファイル、スプレッドシート、データベース表またはその他の格納形式で保存されている場合でもマイニングできます。データの重要な基準は格納形式ではなく、解決すべき問題への適用性にあります。
データ・マイニングでは、データの整備および準備を適切に行うことが非常に重要であり、これらのアクティビティはデータ・ウェアハウスで円滑に実行できます。ただし、問題の解決に必要なデータが含まれていないデータ・ウェアハウスは役に立ちません。
Oracle Data Miningでは、1つの例外に単一レコード・ケースのデータ表示が必要です。各レコード(ケース)のデータは、1つの行に指定する必要があります。例外は、相関ルールの計算を行うAprioriアルゴリズムによって受取るデータです。相関ルールのデータが、トランザクション(マーケット・バスケット・データ)として、各ケースのデータが複数の行に指定されて表示される場合があります。
|
関連項目: Oracle Data Miningでのデータ要件の詳細は、『Oracle Data Miningアプリケーション開発者ガイド』を参照してください。 |
データ・マイニングは、データ内のパターンや関係性の検出に役立つ強力なツールです。ただし、データ・マイニングは、単独では機能しません。データ・マイニングを実施しても、ユーザーによるビジネス、データおよび分析手法への理解が必要であることに変わりはありません。データ・マイニングによってデータに隠された情報が発見されても、その情報がユーザーの組織にとってどのような価値を持つかは提示できません。
ユーザーは、長期にわたってデータを処理してきた結果、重要なパターンについてはすでに認識している可能性があります。データ・マイニングでは、そうした経験的観測の追認や適切性の確認ができ、その上で、簡単な観測ではすぐには認識できない可能性のある新たなパターンを発見できます。
データ・マイニングで検出された予測の関係は、因果関係ではないことを理解しておいてください。たとえば、データ・マイニングによって、「収入が$50,000から$65,000で、特定の雑誌を購読する男性は、特定の製品を購入する傾向にある」と判断されたとします。ユーザーは、この情報をマーケティング戦略の開発に利用できますが、データ・マイニングで識別された母集団が、この母集団に属するという理由でその製品を購入すると想定するべきではありません。
データ・マイニングでは、ガイダンスがなければ自動的に情報は発見されません。データ・マイニングを通じて発見されるパターンは、ユーザーが問題をどのように設定するかによって大きく異なります。
意味のある結果を得るには、適切な設問のしかたを学ぶ必要があります。たとえば、ダイレクト・メールによるセールスへの反応を向上させる方法を知ろうとするよりは、過去にセールスに対して反応した顧客の特性を検出しようとする方が有用な場合があります。
意味のあるデータ・マイニング結果を得るには、データを理解する必要があります。データ・マイニング・アルゴリズムは、データの特定の特徴に敏感な場合が多くあります。たとえば、外れ値(データベース内の標準的な値とは大きく異なるデータ値)、無関係な列、同時に変化する列(年齢と生年月日など)、データ・コーディング、および含めるまたは除外すると選択したデータです。Oracle Data Miningでは、アルゴリズムで必要なデータ準備のほとんどが自動的に実行されます。ただし、データ準備の一部は、通常はドメインまたはデータ・マイニングの問題に固有となります。モデルの適用時に結果を正しく解釈するためには、モデルの作成に使用したデータについて理解しておく必要があります。
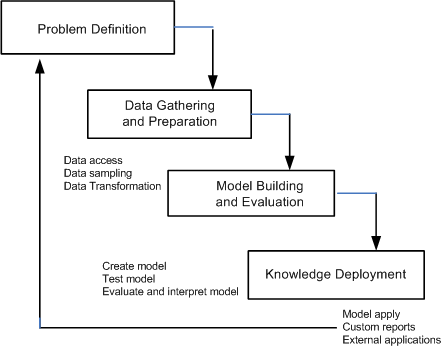
図1-1に、データ・マイニング・プロジェクトの各フェーズおよび反復的な性質を示します。このプロセス・フローでは、特定の解決が得られた後もデータ・マイニング・プロジェクトは停止しないことを示しています。データ・マイニングの結果からビジネス上の新たな問題が提起され、この問題を利用してさらに的確なモデルを開発できます。
データ・マイニング・プロジェクトの最初のフェーズでは、プロジェクトの目的および要件の把握に取り組みます。ビジネスの観点からプロジェクトを特定した時点で、そのプロジェクトをデータ・マイニング問題として編成し、暫定的な実装計画として開発できるようになります。
たとえば、ビジネス上の問題が「顧客により多くの製品を購入してもらうには」という場合があります。これは「どの顧客が製品を購入する可能性が高いか」などの、データ・マイニングの問題として解釈できます。製品を購入する可能性が最も高い顧客を予測するモデルは、過去に製品を購入したことがある顧客を説明するデータに基づいて作成する必要があります。モデルを作成する前に、製品を購入したことがある顧客と購入したことがない顧客の関係を含む可能性が高いデータをアセンブルする必要があります。顧客の属性には、年齢、子供の数、居住年数、持ち家または賃貸などがあります。
データの把握フェーズでは、データの収集や調査を行います。データを詳細に調べるほど、そのデータによって当該のビジネス問題をどの程度解決できるかを判断できるようになります。一部のデータの削除や、他のデータの追加を行う場合もあります。また、このフェーズでは、データの質に関する問題の識別やデータ内のパターンのスキャンも行います。
データの準備フェーズでは、モデルの作成に使用するケース表の作成に必要なタスクをすべて実施します。データ準備のタスクは複数回にわたって実行される可能性が高く、所定の順序には従いません。こうしたタスクには、表、ケースおよび属性の選択に加え、データの整備や変換も含まれます。たとえば、DATE_OF_BIRTH列のAGEへの変換や、INCOME列がNULLのケースへの平均収入の挿入といったタスクが考えられます。
また、データの表面に近い情報を引き出すために、新しく計算された属性を追加できます。たとえば、購入額ではなく、「12か月間で購入額が500ドルを超えた回数」などの新しい属性を作成することができます。頻繁に高額の購入をする顧客は、オファーに反応する顧客としない顧客とも関連する可能性があります。
十分に考慮してデータを準備すると、データ・マイニングで発見できる情報の価値を大幅に高めることができます。
このフェーズでは、様々なモデリング手法を選択して適用し、パラメータを最適な値に調整します。アルゴリズムでデータ変換が必要な場合、実装するには、(第19章で説明されているとおり、Oracle自動データ準備を使用している場合を除き)前のフェーズに戻る必要があります。
最終的なケース表には何千、何万という数のケースが存在する可能性があるため、暫定的なモデルを作成するときは、多くの場合データセットの数を少なくして(ケース表の行数を減らして)作業する方が合理的です。
プロジェクトのこの段階では、モデルが、事前に示されたビジネス目標をどの程度満たしているか評価します(フェーズ1)。モデルが製品を購入する可能性が高い顧客を予測する場合、2つのクラスを十分に区別できているか。リフトが十分か。混同マトリックスに示したトレードオフは許容可能か。テキスト・データの追加によりモデルが向上するか。購入(マーケット・バスケット・データ)などのトランザクショナル・データを含める必要があるか。偽陽性または偽陰性に関連付けられているコストをモデルに組み込む必要があるか。(分類のテスト・メトリックおよびコストの詳細は、第5章を参照してください。トランザクショナル・データの詳細は、第8章を参照してください。)
知識の配置とは、ターゲット環境内でデータ・マイニングを利用することです。配置フェーズでは、本質的かつ実用的な情報をデータから導き出すことができます。
配置では、スコアリングの実行(新しいデータへのモデルの適用)、モデルの詳細(ディシジョン・ツリーのルールなど)の抽出の他、アプリケーション、データ・ウェアハウス・インフラストラクチャ、問合せツールやレポート・ツールなどへのデータ・マイニング・モデルの統合などを行います。
Oracle Data Miningによるモデルの作成および適用はOracle Database内で実行されるため、その結果はすぐに利用できます。データ・マイニングの結果は、BIレポート・ツールまたはダッシュボードで簡単に表示できます。さらに、Oracle Data Miningではリアルタイムのスコアリングもサポートしているので、データのマイニング結果が1回のデータベース・トランザクション内で戻されます。たとえば、販売担当者は、不正の可能性を予測するモデルをオンライン販売のトランザクションのコンテキスト内で実行できます。
|
関連項目: Oracle Data Miningでのスコアリングおよびデプロイメントの詳細は、『Oracle Data Miningアプリケーション開発者ガイド』を参照してください。 |