| Oracle® Database Net Services管理者ガイド 11gリリース2 (11.2) B56288-05 |
|



 前 |
 次 |
この章では、データベースの識別方法とクライアントのデータベースへのアクセス方法を説明します。この章の内容は、次のとおりです。
データベースには1つ以上のインスタンスがあります。インスタンスは、システム・グローバル領域(SGA)と呼ばれるメモリー領域とOracleバックグラウンド・プロセスからなります。インスタンスのメモリーとプロセスは、関連データベースのデータを効率的に管理し、データベース・ユーザーにサービスを提供します。
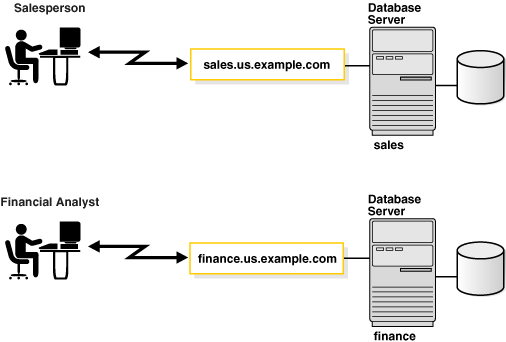
図2-1では、salesとfinanceの2つのデータベース・インスタンスを示します。各インスタンスは、それぞれデータベースとサービス名に対応付けられています。
インスタンスはインスタンス名で識別されます。この例では、salesおよびfinanceです。インスタンス名は、INSTANCE_NAME初期化パラメータで指定されます。インスタンス名のデフォルトは、データベース・インスタンスのOracleシステム識別子(SID)です。
一部のハードウェア・アーキテクチャでは、複数のコンピュータがデータ、ソフトウェアまたは周辺装置へのアクセスを共有できます。Oracle Real Application Clusters(Oracle RAC)では、単一の物理データベースを共有する異なるコンピュータ上で複数のインスタンスを実行することで、このようなアーキテクチャを活用できます。
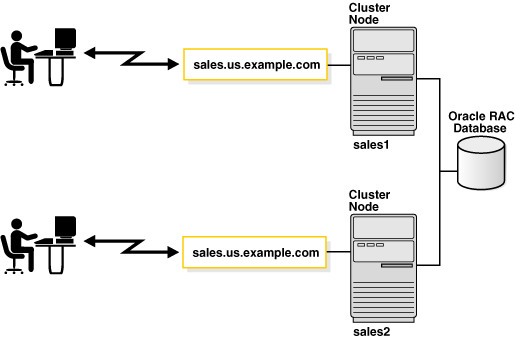
図2-2は、Oracle RAC構成を示しています。この例では、2つのインスタンス、sales1とsales2が1つのデータベース・サービス、sales.us.example.comに対応付けられています。
Oracle Databaseは、クライアントに対してはサービスとして表示されます。データベースには、1つ以上のサービスを対応付けることができます。
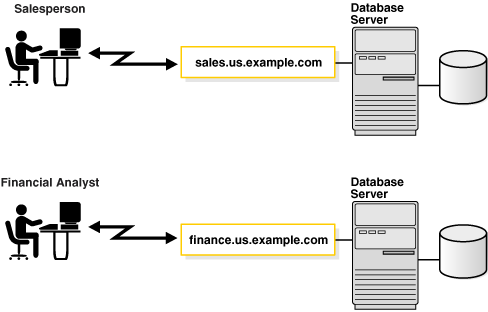
図2-3は、2つのデータベースを示しています。各データベースがそれぞれクライアントにデータベース・サービスを提供しています。一方のサービスsales.us.example.comでは、販売担当者が販売データベースにアクセスできます。もう一方のサービスfinance.us.example.comでは、財務アナリストが財務データベースにアクセスできます。
販売データベースと財務データベースは、サービス名、sales.us.example.comおよびfinance.us.example.comによってそれぞれ識別されます。サービス名はデータベースの論理表現です。インスタンスを起動すると、インスタンスはそれ自体を1つ以上のサービス名を使用してリスナーに登録します。クライアント・プログラムまたはデータベースがリスナーに接続すると、これらはサービスへの接続を要求します。
サービス名は複数のデータベース・インスタンスを識別することができ、インスタンスは複数のサービスに属することができます。このため、リスナーはクライアントとインスタンスとの間の仲介役を果し、接続要求を適切なインスタンスに渡します。サービスに接続するクライアントは、必要なインスタンスを指定する必要がありません。
サービス名は、サーバー・パラメータ・ファイルのSERVICE_NAMES初期化パラメータで指定します。サーバー・パラメータ・ファイルを使用すると、ALTER SYSTEMコマンドを使用して初期化パラメータを変更でき、変更内容は停止して起動した後も維持されます。DBMS_SERVICEパッケージを使用して、サービスを作成することもできます。サービス名のデフォルトはグローバル・データベース名で、データベース名(DB_NAME初期化パラメータ )およびドメイン名(DB_DOMAIN初期化パラメータ)から構成されています。sales.us.example.comの場合、データベース名はsalesで、ドメイン名はus.example.comです。
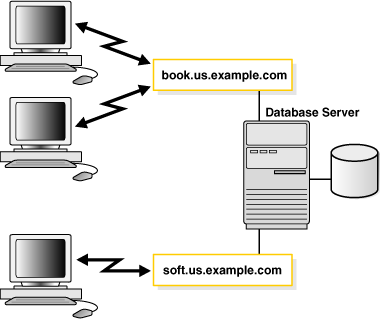
図2-4では、1つのデータベースに対応する複数のサービスに接続しているクライアントを示します。
1つのデータベースに複数サービスを対応付けると、次のような機能が得られます。
単一のデータベースを、異なる方法であらゆるクライアントが識別できます。
データベース管理者は、システム・リソースを制限したり、確保できます。このレベルの制御では、これらのサービスの1つを要求するクライアントに、より適切にリソースを割り当てることが可能です。
|
関連項目:
|
データベース・サービスに接続するために、クライアントは、データベースの場所とデータベース・サービスの名前を示す接続記述子を使用します。次の例は、sales.us.example.comというデータベース・サービス、およびホストsales-serverに接続する簡易接続記述子を示しています(デフォルトではポートは1521です)。
sales-server/sales.us.example.com
次の例は、前述の簡易接続記述子およびデータベース・サービスのtnsnames.oraエントリを示しています。
(DESCRIPTION= (ADDRESS=(PROTOCOL=tcp)(HOST=sales-server)(PORT=1521)) (CONNECT_DATA= (SERVICE_NAME=sales.us.example.com)))
この項で説明する項目は、次のとおりです。
接続記述子は、tnsnames.oraファイルに記述されている、リスナーの1つまたは複数のプロトコル・アドレスおよび宛先サービスの接続情報により構成されます。例2-1は、salesデータベースにマップされた接続記述子を示しています。
例2-1 接続記述子
sales= (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=sales-server)(PORT=1521))(CONNECT_DATA= (SID=sales) (SERVICE_NAME=sales.us.example.com) (INSTANCE_NAME=sales)))
例2-1に示すように、接続記述子には次のパラメータが含まれています。
ADDRESSセクションには次のパラメータがあります。
PROTOCOLパラメータは、リスナー・プロトコル・アドレスを識別します。プロトコルは、TCP/IPの場合tcpです。
HOSTパラメータは、ホスト名を識別します。ホストはsales-serverです。
PORTパラメータは、ポートを識別します。ポートは、デフォルトのポート番号1521です。
CONNECT_DATAセクションには次のパラメータがあります。
SERVICE_NAMEパラメータはサービスを識別します。宛先サービス名は、sales.us.example.comという名前のデータベース・サービスです。
この接続記述子の値は、初期化パラメータ・ファイルのSERVICE_NAMES初期化パラメータ(SERVICE_NAMESでは末尾にSが使用されます)から取得されます。一般的にSERVICE_NAMES初期化パラメータは、データベース名とドメイン名が含まれるグローバル・データベース名です。例では、sales.us.example.comには、salesのデータベース名とus.example.comのドメインがあります。
INSTANCE_NAMEパラメータはデータベース・インスタンスを識別します。インスタンス名はオプションです。
初期化パラメータ・ファイルのINSTANCE_NAMEパラメータは、インストール中またはデータベース作成中に入力されたSIDが、デフォルトで設定されます。
ホストは、IP version 4 (IPv4)およびIP version 6 (IPv6)インタフェースを使用できます。IPv6アドレスとIPv6アドレスに解決されるホスト名は、TNS接続アドレスのHOSTパラメータで使用すると便利です。このTNS接続アドレスは、表2-1にリストされているサポート対象のNetネーミング・メソッドから取得できます。
Oracle Database 11gでIPv6を使用してエンドツーエンド接続を確立するには、次の構成が必要です。
クライアントTNS接続アドレスは、IPv6エンドポイント上のOracle Net Listenerに接続する必要があります。
Oracle Net Listenerに対して構成されているデータベース・インスタンスは、IPv6エンドポイント上の接続要求をリスニングする必要があります。
ホスト名が指定されている場合、正常な接続が確立されるか、すべてのアドレスが試行されるまで、Oracle Netはドメイン・ネーム・システム(DNS)の名前解決によって戻されるすべてのIPアドレスへの接続を試行します。例2-1で、sales-serverホストはクライアント接続を受け入れるIPv4専用ホストであるとします。DNSはsales-serverを次のIPアドレスにマップします。
IPv6アドレス2001:0DB8:0:0::200C:417A
IPv4アドレス192.168.2.213
この場合、IPv6アドレスがDNSリストの先頭にあるため、Oracle Netはまずこのアドレスで接続を試行します。この例では、sales-serverはIPv6接続をサポートしていないため、この試行は失敗します。Oracle NetはIPv4アドレスへの接続に進み、この試行は成功します。
接続記述子のアドレスの一部はリスナーのプロトコル・アドレスです。データベース・サービスに接続するには、クライアントは、まず、データベース・サーバーに常駐しているリスナー・プロセスに接続します。リスナーはクライアントからの着信接続要求を受信し、これらの要求をデータベース・サーバーに送信します。接続が確立された後、クライアントとデータベース・サーバーは直接通信します。
リスナーはクライアントからの要求を受け入れるようにプロトコル・アドレスで設定できます。このアドレスはリスナーがリスニングを実行するプロトコルと、プロトコル固有のその他の情報を定義します。たとえば、リスナーを次のプロトコル・アドレスでリスニングを実行するように設定できます。
(DESCRIPTION= (ADDRESS=(PROTOCOL=tcp)(HOST=sales-server)(PORT=1521)))
前の例では、リスナーのホストとポート番号を指定するTCP/IPプロトコル・アドレスを示しています。これと同じプロトコル・アドレスで構成されたクライアント接続記述子は、このリスナーに接続要求を送信できます。
接続記述子ではデータベース・サービス名を指定し、これを使用してクライアントは接続の確立を試みます。リスナーは接続要求を処理できるサービスを認識しています。これは、Oracle Databaseがこの情報をリスナーに動的に登録しているためです。この登録プロセスは、サービス登録と呼ばれます。登録によって、データベース・インスタンス、および各インスタンスで利用可能なサービス・ハンドラに関する情報がリスナーに提供されます。ディスパッチャまたは専用サーバーがあります。
データベースの特定のインスタンスへの接続が必要な場合、クライアントは特定インスタンスのINSTANCE_NAMEを接続記述子で指定できます。この機能は、Oracle Real Application Clusters構成を使用する場合に役立ちます。たとえば、次の接続記述子は、sales.us.example.comに対応付けられているsales1のインスタンス名を指定しています。
(DESCRIPTION=
(ADDRESS=(PROTOCOL=tcp)(HOST=sales-server)(PORT=1521))
(CONNECT_DATA=
(SERVICE_NAME=sales.us.example.com)
(INSTANCE_NAME=sales1)))
特定のタイプのサービス・ハンドラを常に使用するクライアントは、そのサービス・ハンドラのタイプを指定する接続記述子を使用できます。次の例の接続記述子は、(SERVER=shared)で示すように、共有サーバー構成のディスパッチャを使用するように構成されています。
(DESCRIPTION=
(ADDRESS=(PROTOCOL=tcp)(HOST=sales-server)(PORT=1521))
(CONNECT_DATA=
(SERVICE_NAME=sales.us.example.com)
(SERVER=shared)))
リスナーはクライアントの要求を受け取ると、登録されているサービス・ハンドラの1つを選択します。選択したハンドラのタイプ、使用する通信プロトコル、データベース・サーバーのオペレーティング・システムに基づいて、リスナーは次の処理のいずれかを実行します。
接続要求を直接ディスパッチャに渡します。
ディスパッチャまたは専用サーバー・プロセスの位置情報が記録されたリダイレクト・メッセージをクライアントに戻します。続いてクライアントが、ディスパッチャまたは専用サーバー・プロセスに直接接続します。
専用サーバー・プロセスを生成して、クライアント接続を専用サーバー・プロセスに渡します。
リスナーがクライアントとの接続処理を完了すると、クライアントはリスナーを介さずにOracle Databaseと直接通信します。リスナーは、着信ネットワーク・セッションのリスニングを再開します。
サービス・ハンドラを指定するときは、次の点を考慮する必要があります。
クライアントに専用サーバーを使用する場合は、(SERVER=dedicated)を指定します。SERVERパラメータが設定されていない場合、共有サーバー構成として判断されます。しかし、利用できるディスパッチャがない場合、クライアントは専用サーバーを使用します。
データベース常駐接続プーリングがサーバーで有効になっている場合、(SERVER=pooled)を指定してプールから接続を取得します。データベース常駐接続プーリングがサーバーで有効になっていない場合、クライアント要求は拒否され、ユーザーはエラー・メッセージを受け取ります。
|
関連項目:
|
サービス・ハンドラは、Oracle Databaseへの接続ポイントとして機能します。サービス・ハンドラには、共有サーバー・プロセスまたは専用サーバー・プロセス、またはプールがあります。
この項で説明する項目は、次のとおりです。
共有サーバー・アーキテクチャはディスパッチャ・プロセスを使用して、クライアント接続を共通の要求キューに渡します。サーバー・プロセスの共有プールの中のアイドル状態の共有サーバー・プロセスは、共通キューから要求を取り出します。このアプローチでは、小さいサーバー・プロセス・プールで大量のクライアントを処理することが可能です。専用サーバー・モデルと比較した共有サーバー・モデルの大きな利点は、システム・リソースが少なくて済むため、ユーザー数の増加に対応できることです。
リスナーはサービス・ハンドラのタイプとしてディスパッチャを使用しますが、これにクライアント要求を渡すことができます。クライアント要求を受け取ると、リスナーは次のいずれかの処理を実行します。
ディスパッチャのプロトコル・アドレスを含むリダイレクト・メッセージをリスナーに発行します。次に、クライアントは、リスナーに要求したネットワーク・セッションを終了し、リダイレクト・メッセージで提供されたネットワーク・アドレスを使用して、ディスパッチャとのネットワーク・セッションを確立します。
リスナーは可能な場合は必ずダイレクト・ハンドオフを使用します。リダイレクト・メッセージは、たとえばディスパッチャがリスナーに対してリモートである場合に使用します。
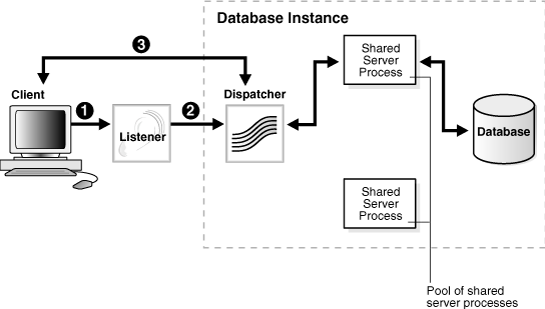
図2-5では、リスナーが接続要求をディスパッチャに直接渡す様子を示します。
リスナーがクライアント接続要求を受け取ります。
リスナーは、接続要求をディスパッチャに直接渡します。
クライアントは、ここでディスパッチャに直接接続します。
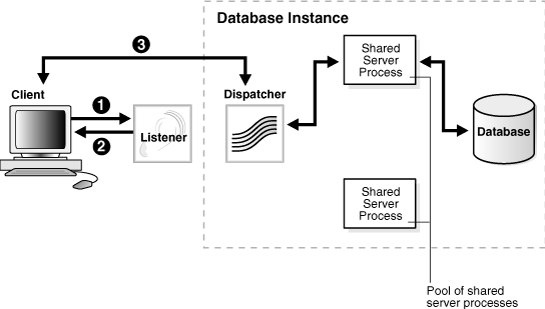
図2-6では、リダイレクト接続におけるディスパッチャの役割を示します。
リスナーがクライアント接続要求を受け取ります。
リスナーは、ディスパッチャの位置をリダイレクト・メッセージでクライアントに通知します。
クライアントがディスパッチャに直接接続します。
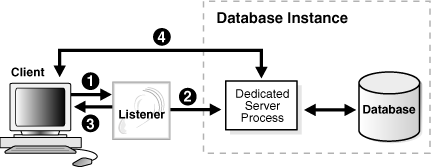
専用サーバー構成では、リスナーはクライアントの着信接続要求ごとに専用サーバー・プロセスを個別に起動します。このプロセスはクライアントへのサービス提供のみを行います。セッション完了後、専用サーバー・プロセスは終了します。専用サーバー・プロセスは接続ごとに起動する必要があるため、共有サーバー構成よりも多くのシステム・リソースが構成に必要になる場合があります。
専用サーバー・プロセスは、クライアント要求を受け取った時にリスナーが開始するサービス・ハンドラのタイプです。クライアント/サーバー接続を完了するには、次のいずれかの処理が発生します。
専用サーバーはリスナーから接続要求を継承します。
専用サーバーはリスナーにリスニング・プロトコル・アドレスを通知します。リスナーはリダイレクト・メッセージでプロトコル・アドレスをクライアントに渡し、接続を終了します。クライアントは、そのプロトコル・アドレスを使用して、専用サーバーに直接接続します。
前述の処理のどちらかが選択されるかは、オペレーティング・システムおよび使用中のトランスポート・プロトコルによって決まります。
クライアントとデータベースが同じコンピュータ上に存在する場合、クライアント接続は、リスナーを経由せずに専用サーバー・プロセスに直接渡すことができます。これは、bequeathプロトコルとして知られています。セッションを開始するアプリケーションは、接続要求に対する専用サーバー・プロセスを生成します。データベースの起動に使用されるアプリケーションがデータベースと同じコンピュータ上にある場合、この処理は自動的に実行されます。
|
注意: リモート・クライアントが専用サーバーに接続するためには、リスナーとデータベース・インスタンスを同じコンピュータ上で実行する必要があります。 |
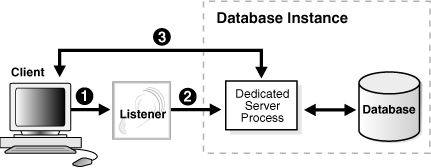
図2-7では、リスナーがクライアント接続要求を専用サーバー・プロセスに渡す様子を示します。
リスナーがクライアント接続要求を受け取ります。
リスナーは専用サーバー・プロセスを開始し、専用サーバーはリスナーから接続要求を継承します。
クライアントがここで専用サーバーに直接接続します。
図2-8では、リダイレクト接続における専用サーバーの役割を示します。
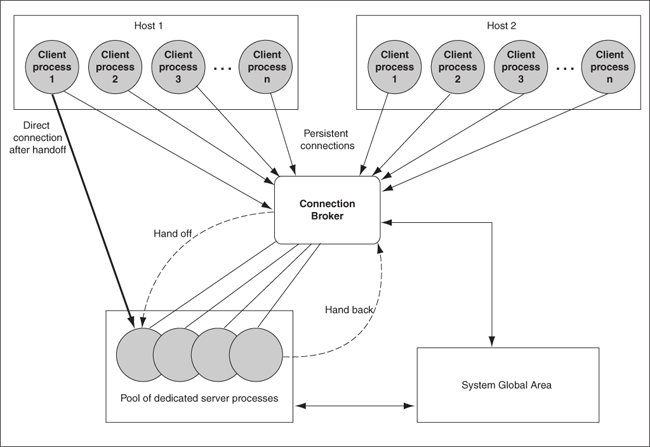
データベース常駐接続プーリングは、データベース接続を取得し、比較的短時間の処理を実行した後、データベース接続を解放するような一般的なWebアプリケーション使用シナリオに対して、データベース・サーバーの接続プールを提供します。データベース常駐接続プーリングは、専用サーバーをプールします。プール・サーバーは、サーバー・フォアグラウンド・プロセスとデータベース・セッションの組合せに相当します。
データベース常駐接続プーリングは、中間層プロセス内のスレッド間で接続を共有する中間層接続プールを補完します。また、これを使用すると、同じ中間層ホスト上の中間層プロセス間、および異なる中間層ホスト上の中間層プロセス間でもデータベース接続を共有できます。この結果、大量のクライアント接続をサポートするために必要となる基本データベース・リソースが大幅に減少するため、データベース層のメモリー・フットプリントが縮小し、中間層とデータベース層の両方のスケーラビリティが向上します。すぐに使用できるサーバーのプールを保持することで、クライアント接続の作成と切断のコストが削減されるという利点もあります。
データベース常駐接続プーリングは、クライアント・アプリケーションとプロセス全体に専用接続のプーリングを提供します。この機能は、データベースへの永続的な接続を維持してサーバー・リソース(メモリーなど)を最適化する必要があるアプリケーションに役立ちます。
データベース常駐接続プールから接続を取得するクライアントは、専用サーバーのかわりにバックグラウンド・プロセス(接続ブローカ)に永続的に接続されます。接続ブローカはプール機能を実装しており、クライアントから専用サーバーのプールへのセッションを使用したインバウンド接続の多重化を実行します。
クライアントがデータベースの作業を実行する必要がある場合、接続ブローカはプールから専用サーバーを選択し、クライアントに割り当てます。その後、クライアントは要求が処理されるまで専用サーバーに直接接続されます。サーバーがクライアント要求の処理を終了した後、サーバーはプールに戻され、クライアントからの接続は接続ブローカに戻されます。
図2-9は、プロセスを図で示しています。
ネーミング・メソッドとは、データベース・サービスに接続するときに、クライアント・アプリケーションが接続識別子を接続記述子に変換するために使用する解決メソッドです。ユーザーは接続文字列を指定して接続要求を開始します。接続文字列には、ユーザー名、パスワードおよび接続識別子が含まれます。接続識別子には、接続記述子または接続記述子に解決される名前を使用できます。接続記述子には次のものが含まれます。
プロトコル・アドレスによるリスナーの位置情報など、サービスへのネットワーク・ルート。
データベース・サービス名またはOracleシステム識別子(SID)。
次のCONNECTコマンドでは、ネット・サービス名のかわりに、接続識別子として完全な接続記述子を持つ接続文字列を使用しています。1つの行として、文字列を入力する必要があります。ページの幅のために2行で表示されます。
SQL> CONNECT hr@(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=sales-server1) (PORT=1521))(CONNECT_DATA=(SERVICE_NAME=sales.us.example.com)))
最も一般的な接続識別子の1つは、サービスの単純な名前であるネット・サービス名です。次のCONNECTコマンドでは、接続文字列に、接続識別子としてネット・サービス名salesを使用しています。
SQL> CONNECT hr@sales
Enter password: password
ネット・サービス名のsalesを使用すると、salesから接続記述子への最初のマッピングによって、接続処理が実行されます。このマップ情報にはネーミング・メソッドでアクセスします。次のネーミング・メソッドを利用できます。
ローカル・ネーミング
ディレクトリ・ネーミング
簡易接続ネーミング
外部ネーミング
接続記述子に名前をマッピングする適切なネーミング・メソッドの選択は組織の規模によって決まります。
データベースが少ない小規模な組織では、簡易接続ネーミングを使用してデータベース・サーバーのホスト名にTCP/IP接続するか、またはローカル・ネーミングを使用してクライアント上のtnsnames.oraファイルに名前を格納します。
データベースが多い大規模な組織では、ディレクトリ・ネーミングを使用して集中化されたディレクトリ・サーバーに名前を格納します。
インターネット・ネットワークではローカル・ネーミング・メソッドでデータベースに接続するために必要なアプリケーションWebサーバーを構成します。
表2-1では、各ネーミング・メソッドの相対的なメリットおよびデメリットをまとめ、ネットワーク内でそれらのネーミング・メソッドを使用するための推奨事項を示します。
表2-1 ネーミング・メソッド: メリットおよびデメリット
| ネーミング・メソッド | 説明 | メリット/デメリット | 推奨環境 |
|---|---|---|---|
|
ネット・サービス名とその接続記述子を、 |
メリット:
デメリット: すべてのネット・サービス名とアドレス変更をローカル側で構成する必要があります。 |
ほとんど変更がなくサービス数の少ない単純な分散ネットワーク |
|
|
接続識別子を集中化されたLDAP準拠のディレクトリ・サーバーに格納し、データベース・サービスにアクセスします。 |
メリット:
デメリット: ディレクトリ・サーバーにアクセスする必要があります。 |
頻繁に変更する大規模で複雑なネットワーク(20以上のデータベースを持つ) |
|
|
クライアントは、ホスト名およびオプションのポート名やサービス名から構成されるTCP/IP接続文字列を使用して、Oracle Databaseサーバーへ接続できるようになります。 |
メリット:
デメリット: 推奨環境の欄に示すように使用できる環境に制限があります。 |
次に示す条件に合致する単純なTCP/IPネットワーク
|
|
|
Network Information Service(NIS)外部ネーミングなど、サポートされるサードパーティ・ネーミング・サービスにネット・サービス名を保存します。 |
メリット: 管理者は使用方法を熟知しているツールおよびユーティリティを使用してOracleネット・サービス名をサイト固有のネーム・サービスにロードできます。 デメリット: Oracle Net製品では管理できないサード・パーティのネーミング・サービスが必要です。 |
既存のネーム・サービスを持つネットワーク |
ネーミング・メソッドは、次の手順で構成します。
ネーミング・メソッドを選択します。
接続記述子を名前にマップします。
そのネーミング・メソッドを使用するクライアントを構成します。
ネーミング・メソッドを使用してクライアント・セッションを確立する代表的なプロセスは、次のとおりです。
クライアントは、接続識別子を指定して接続要求を開始します。
接続識別子は、ネーミング・メソッドによって接続記述子に解決されます。
クライアントは、接続記述子内に存在するアドレスに対して、接続要求を実行します。
リスナーは要求を受け取り、それを該当するデータベース・サーバーに送ります。
データベース・サーバーによって、接続が受け入れられます。
|
注意: 接続記述子の他にも、ネーミング・メソッドを使用して、接続名をプロトコル・アドレスやプロトコル・アドレス・リストにマッピングできます。 |
ネットワーク・コンポーネントを起動すると、ネットワーク経由の接続を確立できます。接続の確立方法は、ネーミング・メソッドと、接続に使用するツールによって異なります。
接続文字列は次のような形式になります。
CONNECTusername@connect_identifier
ほとんどのオペレーティング・システムで、デフォルトの接続識別子を定義できます。デフォルトを使用する場合、接続文字列で接続識別子を指定する必要がなくなります。デフォルトの接続識別子を定義するには、LinuxおよびUNIXプラットフォームの場合は環境変数TWO_TASKを、Microsoft Windowsの場合は環境変数LOCALまたはレジストリ・エントリを使用します。
たとえば、環境変数TWO_TASKがsalesに設定されている場合は、SQL*Plusから、CONNECT username@salesではなくCONNECT usernameを使用してデータベースに接続できます。Oracle NetはTWO_TASK変数を確認し、接続識別子として値salesを使用します。
|
関連項目: TWO_TASKおよびLOCALの設定方法については、Oracleオペレーティング・システム固有のマニュアルを参照してください。 |
接続文字列で使用される接続識別子には、一重引用符(')または二重引用符(")で囲む場合を除いて、空白を含めることはできません。次の例では、空白を含む接続識別子および接続記述子が一重引用符で囲まれています。
CONNECT scott@'(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=sales-server) (PORT=1521))(CONNECT_DATA=(SERVICE_NAME=sales.us.example.com)))' Enter password:passwordCONNECT scott@'cn=sales, cn=OracleContext, dc=us, dc=example, dc=com' Enter password:password
接続識別子の中で二重引用符(")が使用されている場合は、一重引用符(')で囲みます。たとえば、次のように指定します。
CONNECT scott@'sales@"good"example.com'
Enter password: password
接続識別子の中で一重引用符(')が使用されている場合は、二重引用符(")で囲みます。たとえば、次のように指定します。
CONNECT scott@"cn=sales, cn=OracleContext, ou=Mary's Dept, o=example"
Enter password: password
Oracle Real Application Clustersなどの一部の構成では、同じデータベース・サービスへのクライアント接続要求を処理するために、複数のノード上に複数のリスナーを構成できます。次の例では、sales.us.example.comはsales1-serverまたはsales2-serverでリスナーを使用して接続できます。
(DESCRIPTION= (ADDRESS_LIST= (ADDRESS=(PROTOCOL=tcp)(HOST=sales1-server)(PORT=1521)) (ADDRESS=(PROTOCOL=tcp)(HOST=sales2-server)(PORT=1521))) (CONNECT_DATA= (SERVICE_NAME=sales.us.example.com)))
複数のリスナー構成では、フェイルオーバーやロード・バランシング機能も、単独で、あるいはそれぞれを組み合せて有効的に活用できます。次の項では、次の機能について説明します。
接続時フェイルオーバー機能を使用すると、クライアントは、最初のリスナーへの接続に失敗した場合、別のリスナーに接続できます。接続を試行するリスナーの数は、リスナー・プロトコル・アドレスの数で決まります。接続時フェイルオーバーを実行しない場合、Oracle Netは、1つのリスナーへの接続のみ試行します。
透過的アプリケーション・フェイルオーバー(TAF)機能は、Oracle Real Application Clustersなどの高可用性環境のためのランタイム・フェイルオーバーです。TAFでは、アプリケーションとサービス間の接続のフェイルオーバーおよび再確立を行います。TAFにより、クライアント・アプリケーションは接続障害の発生時にデータベースに自動的に再接続でき、実行中だったSELECT文を再開することも可能です。この再接続は、Oracle Call Interface(OCI)ライブラリ内から自動的に実行されます。
クライアント・ロード・バランシング機能によって、クライアントは、複数のリスナー間で接続要求をランダム化できます。Oracle Netは、プロトコル・アドレスのリストを順不同に選択して、複数のリスナーに対する負荷を均衡化します。クライアント・ロード・バランシングを実行しない場合、Oracle Netは、接続が成功するまでプロトコル・アドレスを順番に試行します。
接続ロード・バランシング機能を利用すると、複数のディスパッチャ間のアクティブな接続数を均衡化することによって、接続時のパフォーマンスが向上します。シングル・インスタンス環境では、リスナーは最も負荷の少ないディスパッチャを選択して、クライアントの着信要求を処理できます。Oracle Real Application Clusters環境では、接続ロード・バランシングによって、複数のインスタンス間のアクティブな接続数を均衡化することも可能です。
サービス登録を動的に行うため、リスナーはすべてのインスタンスとディスパッチャをその場所に関係なく常に認識します。リスナーは、着信したクライアント要求の送信先となるインスタンスを、また共有サーバーが構成されている場合は送信先となるディスパッチャを、ロード情報に応じて判別します。
共有サーバー構成では、リスナーは次の順番でディスパッチャを選択します。
ロード量が最小のノード
ロード量が最小のインスタンス
そのインスタンスのロード量が最小のディスパッチャ
専用サーバー構成では、リスナーは次の順番でインスタンスを選択します。
ロード量が最小のノード
ロード量が最小のインスタンス
データベース・サービスが複数のノード上に複数のインスタンスを持つ場合、リスナーはロード量が最小のノード上にある、ロード量が最小のインスタンスを選択します。共有サーバーが構成されている場合、選択したインスタンスの中でロード量が最小のディスパッチャが選択されます。