| Oracle® Database Real Application Testingユーザーズ・ガイド 11gリリース2(11.2) B56321-06 |
|



 前 |
 次 |
この章では、Oracleデータ・マスキングを構成するコンポーネントの概念と、マスキング・フォーマットやマスキング定義の作成など、タスク順序を実行する手順について説明します。内容は次のとおりです。
この章の手順は、Oracle Enterprise Manager 12.1以上のCloud Controlのみに適用されます。データ・マスキング機能を使用するには、Oracle Data Masking and Subsetting Packライセンスが必要です。
|
注意: Database Plug-in 12.1.0.3以上を使用する11.2.0.3データベースでマスキングを実行するには、マスキングの正常の実行のためにデータベース・パッチ# 16922826の適用が必要です。 |
企業は、アプリケーション開発、テストまたはデータ分析のために本番データを非本番環境にコピーする際に、機密情報が漏えいするリスクにさらされます。Oracleデータ・マスキングを使用すると、元の機密データを架空のデータに不可逆的に置き換え、本番データを非本番ユーザーと安全に共有できるようにすることで、このようなリスクを低減できます。Oracleデータ・マスキングはOracle Enterprise Managerからアクセス可能で、エンドツーエンドの安全な自動化により、本番データを元に規制に準拠したテスト・データベースを提供します。
データ・マスキング(データ・スクランブルやデータの匿名化とも呼ばれる)は、本番データベースから非本番テスト・データベースにコピーされる機密情報を、外見は本物であるもののマスキング・ルールに基づいて修正されたデータに置き換えるプロセスのことです。データ・マスキングは、機密データまたは規制対象のデータを非本番ユーザーと共有する必要があるほぼすべての状況において最適です。そのようなユーザーには、アプリケーション開発者などの内部ユーザーや、海外のテスト企業、サプライヤ、カスタマなどの外部のビジネス・パートナなどが含まれます。このような非本番ユーザーは、すべての表のあらゆる列を参照する必要はありませんが、元のデータの一部にはアクセスする必要があります(特に情報が政府の規制によって保護されている場合)。
データ・マスキングを使用すると、組織ではオリジナル・データに類似した特性を持つ、外見は本物で完全に機能するデータを生成し、機密情報のかわりに使用することができます。これと対照的な暗号化や仮想プライベート・データベースの場合は、データが単に隠されるだけであり、適切なアクセス権やキーがあればオリジナル・データを取得できます。データ・マスキングの場合は、元の機密データを取得することも、元の機密データにアクセスすることもできません。
情報コンテンツを不適切な開示から保護すべきデータの例としては、名前、住所、電話番号、クレジット・カードの詳細情報などがあります。本物の本番稼働データベース環境には、貴重な機密データが含まれており、そのような情報へのアクセスは厳重に規制されます。ただし、各本稼働システムには通常、開発用のコピー・データがあり、そのようなテスト環境に対する規制はさほど厳しくありません。これにより、データが不適切に使用されるリスクが非常に高くなります。データ・マスキングでは、データベースの機密レコードを変更し、利用可能ではあるものの機密情報も個人情報も含まれないようなデータにすることができます。マスクされたテスト・データは、アプリケーションの整合性を確保するために、外見はオリジナル・データに類似しています。
テスト情報をマスキングするとデータが誤って漏れるのを防止できるため、データのマスキングはビジネス・セキュリティの観点から見て賢明な予防策です。多くの場合、データのマスキングは法律上の義務です。Enterprise Manager Data Masking Packを使用すると、組織では法律上の義務を満たし、サーベンス・オクスリー法、カリフォルニア州データベース機密保護違反通知法(CA上院法案1386)、欧州連合データ保護指令のようなグローバルな規制基準に応じることができます。
法的必要条件は国によって異なりますが、個人的な消費者情報の機密性および整合性を保護するためのなんらかの形態の規制が現在ではほとんどの国に存在しています。たとえば、米国の場合、財務プライバシ権法(1978年)により財務レコードに対する第4修正条項の法的保護が策定され、これを必要とする州法は多数あります。同様に、米国における医療保険の相互運用性と説明責任に関する法令(US Health Insurance Portability and Accountability Act: HIPAA)では、個人医療情報の保護が策定されています。
データ・マスキング以外に、Oracleでは次のセキュリティ製品を提供しています。
仮想プライベート・データベース または Oracle Label Security : ユーザーのアクセス権限に基づいて、行およびデータを隠します。
透過的データ暗号化 : ディスクに格納されている情報を暗号化を使用して隠します。暗号化されていない情報は、クライアントに表示されます。
DBMS_CRYPTO: ユーザー・データを暗号化できるサーバー・パッケージが得られます。
Database Vault : データに対するアクセス制御を強化できます。
データ・マスキングは、Oracle Database 9i 以上のリリースをサポートしています。11.1より前のバージョンを保有している場合、次の回避策を実行することで、そのバージョンを使用できます。
次のファイルを置き換えます。
AGENT_HOME/sysman/admin/scripts/db/reorg/reorganize.pl
... 次のファイルと置き換えます。
OMS_HOME/sysman/admin/scripts/db/reorg/reorganize.pl
サポートされているデータ型のリストは、リリースによって異なります。
Grid Control 10gリリース5 (10.2.0.5)、Database 11gリリース2 (11.2)およびCloud Control 12cリリース1 (10.2.0.1)
数値型
次の数値型では、「配列リスト」、「削除」、「固定数値」、「NULL値」、「後処理関数」、「元のデータの保持」、「ランダム小数」、「ランダム数値」、「シャッフル」、「SQL式」、「置換」、「表の列」、「切捨て」、「暗号化」、「ユーザー定義関数」フォーマットを使用できます。
NUMBER
FLOAT
RAW
BINARY_FLOAT
BINARY_DOUBLE
文字列型
次の文字列型では、「配列リスト」、「削除」、「固定数値」、「固定文字列」、「NULL値」、「後処理関数」、「元のデータの保持」、「ランダム小数」、「ランダム桁数」、「ランダム数値」、「ランダム文字列」、「シャッフル」、「SQL式」、「置換」、「部分文字列」、「表の列」、「切捨て」、「暗号化」、「ユーザー定義関数」フォーマットを使用できます。
CHAR
NCHAR
VARCHAR2
NVARCHAR2
日付型
次の日付型では、「配列リスト」、「削除」、「NULL値」、「後処理関数」、「元のデータの保持」、「ランダム日付」、「シャッフル」、「SQL式」、「置換」、「表の列」、「切捨て」、「暗号化」、「ユーザー定義関数」フォーマットを使用できます。
DATE
TIMESTAMP
Grid Control 11gリリース1 (11.1)およびCloud Control 12cリリース1 (10.2.0.1)
ラージ・オブジェクト(LOB)・データ型
次のデータ型では、「固定数値」、「固定文字列」、「NULL値」フォーマットを使用できます。
BLOB
CLOB
NCLOB
データのマスキングを対象として、Data Masking Packでは次の2つの主要な機能を提供しています。
すぐに利用可能な一連のマスキング・フォーマットが入ったフォーマット・ライブラリです。このライブラリは、マスキングに利用可能な一連のフォーマット・ルーチンから構成されています。マスキング・フォーマットには、ユーザーが作成したものか、Oracle付属のデフォルト・マスキング・フォーマットのリストから取得したものを使用できます。
組織では、一般的に規制の対象になるすべての情報に対してマスキング・フォーマットを作成し、機密データが属するデータベースとは無関係に機密データにフォーマットを適用できるようにすることをお薦めします。そうしておけば、組織全体にわたり、全機密データに対するマスキングを首尾一貫して行うことができます。
マスキング定義では、1つのデータベース内の1つまたは複数の表に実装されるデータ・マスキング操作を定義します。マスキング定義では、データのマスキングに使用する表の列とフォーマットを関連付けます。また、データベース内で正式に宣言されない列間の関係も、関連列を使用して維持されます。
マスキング操作には、新しいマスキング定義を作成することもできますし、既存の定義を使用することもできます。マスキング定義を作成するには、データがマスキングの対象となる表の列とマスク・データのフォーマットを指定します。マスク対象の列が一意な主キー制約または外部キー制約に関与している場合は、データ・マスキングにより、それらの制約に違反しないような値が生成されます。マスキングでは、10進演算を使用して文字ごとの一意性が確保されます。たとえば、5文字の文字列では最大で99999個の一意な値のみが生成されます。同様に、1文字の文字列では最大で9個の一意な値のみが生成されます。
通常は、マスキング定義をファイルにエクスポートした後、他のシステムにインポートします。テスト・サイトと本番サイトが、別々のOracle Management Systemにある場合や、まったく別のサイトにある場合には、これが重要です。
|
関連項目:
|
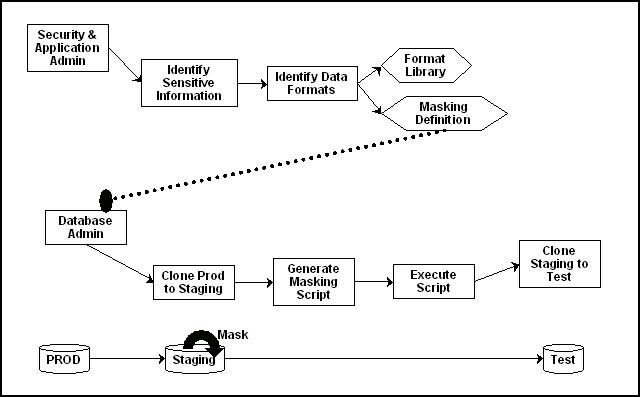
図16-1は、本番データベースをステージング・リージョンにクローニングし、そこでマスキングする過程を示しています。マスキングのプロセスでは、ステージング領域およびテスト領域は本番サイトのように厳重に規制されます。
データ・マスキングは、セキュリティ管理者によって処理され、データベース管理者によって実装される、反復され改良される処理です。データ・マスキングを最初に構成する場合は、テスト・システムでマスキング定義を十分に試してから、マスキング定義に追加する列の数を増やし、マスキング定義が適切に機能し、かつアプリケーションの制約に違反しないことをテストします。この過程において、実データに対するすべての埋込み参照を削除する際に、参照整合性を維持するように注意する必要があります。
データ・マスキングを納得いくまで構成したら、クローニング後に既存の定義を使用して繰り返しマスキングを行うことができます。ただし、新しいスキーマの変更によって新しいデータおよび列のマスキングが必要になったら、マスキング定義を修正する必要があります。
マスキング・プロセスが終わると、データベースは広く利用可能な状態にすることができます。データベースを別のサード・パーティ・サイトに移送する場合は、データ・ポンプ・エクスポート・ユーティリティを使用してリモート・サイトにダンプ・ファイルを移送する必要があります。ただし、マスキングされたデータを社内に保持する場合は、「データ・マスキング・タスクの順序」を参照してください。
この項のタスク順序では、データ・マスキングのワークフローを具体的に示すと同時に、一部のタスク順序では追加情報を紹介します。この順序を確認する前に、このプロセスを完了するためのオプションが2つあることに注意してください。
別のデータベースへのエクスポートおよびインポート
本番データベースをステージング領域にクローニングしてマスキングし、別のデータベースにエクスポートおよびインポートしてから、社内テスト実行者または外部のカスタマに提供できます。これは最も安全な方法です。
テスト・リージョンとしてのステージング領域の使用
本番データベースをマスキングされたステージング領域にクローニングし、そのステージング領域を新しいテスト・リージョンにします。この場合は、SYSDBAアクセスや、データベース・ファイルへのアクセス権をテスト実行者に付与しないでください。付与するとセキュリティが低下します。マスキングされたデータベースでは、未使用ブロックと空きリストに元のデータが含まれます。この情報は、データを別のデータベースにエクスポート/インポートすることでのみパージできます。
次の基本的な手順は、データ・マスキング・プロセスを、追加情報が記載されている他のセクションの参照箇所とともに示します。
アプリケーション・データベースを見直し、機密情報のソースを特定します。
機密データのマスキング・フォーマットを定義します。マスキング・フォーマットがシンプルであるか複雑であるかは、組織の情報セキュリティに対するニーズによって異なります。
詳細は、「新規マスキング・フォーマットの作成」および「Oracle付属の事前定義済のマスキング・フォーマットの使用」を参照してください。
それらのマスキング・フォーマットに表の列を関連付けるマスキング定義を作成します。データ・マスキングにより、データベースの外部キー関係が決定され、外部キー列がマスクに追加されます。
詳細は、「アプリケーション・データ・モデルおよびワークロードによるマスキング」を参照してください。
マスキング定義を保存してマスキング・スクリプトを生成します。
マスキングされたデータが情報セキュリティ要件を満たしているかどうかを確認します。満たしていない場合は、マスキング定義を調整し、変更した表をリストアした後、マスキング定義の最適なセットが得られるまでマスキング定義の適用を繰り返します。
本番データベースをステージング領域にクローニングし、クローニング後に使用するマスキング定義を選択します。Enterprise Managerを使用してクローニングを実行すると、Enterprise Managerのクローニング・ワークフローにマスキングを追加できます。一方、Enterprise Managerを使用せずにクローニングを実行する場合、クローニングの完了後にEnterprise Managerからマスキングを開始する必要があります。クローニングされたデータベースは、本番環境用の機密データがまだ含まれているので、本稼働システムと同じ権限で制御する必要があります。
クローニングが終わったら、パスワードを変更するだけでなく、データベース・リンク、ストリーム、または外部データ・ソースへの参照の更新または無効化も必ず実行してください。クローニングされたデータベース、または少なくともマスキングされたデータが含まれる表をバックアップします。そうしておけば、マスキング定義をさらに調整する必要がある場合に、オリジナル・データをリストアできます。
詳細は、「本番データベースのクローニング」を参照してください。
マスキングが終わったら、アプリケーション、レポートおよびビジネス・プロセスをすべてテストし、それらが機能していることを確認します。すべて正常に機能している場合は、マスキング定義をエクスポートし、バックアップとして保存することができます。
ステージング・サイトのマスキング後、テスト・リージョンにクローニングする前に、MGMT_DM_TTという表をすべて削除します。これらの一時表は、元の機密列値とマスク値間のマッピングを含んでいるため、機密データとして扱う必要があります。
これらの一時表は、デフォルトの「マスキング中に作成した一時表の削除」オプションにより、マスキング中に自動的に削除されます。ただし、このオプションの選択を解除することで、これらの一時表を維持できます。この場合、テスト・リージョンにクローニングする前にユーザーの責任で一時表を削除します。
マスキングが完了したら、置換列フォーマットまたは表の列フォーマットによって使用するためにロードされたすべての表が削除されることを確認します。これらの表には、表の列フォーマットまたは置換フォーマットによって使用されるマスク値が含まれています。セキュリティ上の理由から、この情報をパージすることをお薦めします。
詳細は、「置換フォーマットを使用した決定論的マスキング」を参照してください。
データベースをテスト・リージョンにクローニングするか、データベースを新しいテスト・リージョンとして使用します。データベースを外部サイトまたは安全でないサイトにクローニングする場合、エクスポートまたはインポートを使用することをお薦めします。データベース・ファイル自体ではなく、データベースのみにデータを指定します。
テスト用のクローニングされた本番環境の一部として、マスキング定義をアプリケーション・データベース管理者に提供し、データベースをマスキングできるようにします。
マスキング定義では、そのマスキング定義に含まれる列に対する1つ以上のマスキング・フォーマットが必要です。マスキング定義に列を追加する場合、マスキング・フォーマットを手動で作成するか、フォーマット・ライブラリからインポートすることができます。多くの場合、フォーマット・ライブラリのマスキング・フォーマットを使用して作業する方が効率的です。
この項では、Enterprise Managerを使用して新規マスキング・フォーマットを作成する方法について説明します。
フォーマット・ライブラリにマスキング・フォーマットを作成するには、次の手順を実行します。
「エンタープライズ」メニューから「クオリティ管理」を選択し、次に「データ・マスキングのフォーマット」を選択します。あるいは、「データベース」ホーム・ページにいる場合は、「スキーマ」メニューから「データ・マスキングのフォーマット・ライブラリ」を選択します。
Oracle Enterprise Managerに付属する事前定義済のフォーマットが含まれたフォーマット・ライブラリが表示されます。
「作成」をクリックします。
マスキング・フォーマットを定義できる「フォーマットの作成」ページが表示されます。
|
ヒント: ページのユーザー・コントロールの詳細は、「フォーマット」ページのオンライン・ヘルプを参照してください。 |
新規フォーマットに必要な名前を指定し、「追加」リストからフォーマット・エントリ・タイプを選択して、「実行」をクリックします。
選択したフォーマット・エントリにデータを入力できるページが表示されます。たとえば、「配列リスト」を選択した場合、後続のページでは、New York、New Jersey、New Hampshireなどの値のリストを入力できます。
必要に応じて続けて別のフォーマット・エントリを追加します。
終了したら、オプションでユーザー定義関数または後処理関数を指定し(「ユーザー定義関数および後処理関数の指定」を参照)、「OK」をクリックしてマスキング・フォーマットを保存します。
「フォーマット・ライブラリ」ページが再表示され、新しく作成したフォーマットが「フォーマット・ライブラリ」表に表示されます。後でこのフォーマットを使用して、同じ機密タイプの列をマスキングできます。
|
ヒント: ページのユーザー・コントロールの詳細は、「フォーマット・ライブラリ」および「フォーマットの作成」ページのオンライン・ヘルプを参照してください。 |
必要に応じて、「フォーマットの作成」ページでユーザー定義関数および後処理関数を指定できます。ユーザー定義の選択肢は「追加」リスト内、後処理関数フィールドはページ下部にあります。
ユーザー定義関数を指定するには、「追加」リストから「ユーザー定義関数」を選択し、「実行」をクリックして、入力フィールドにアクセスします。
ユーザー定義関数は、元の値を入力として受け取り、マスク値を戻します。出力値のデータ型と一意性は、元の出力値と互換性がある必要があります。それ以外の場合、ジョブの実行に失敗します。また、ユーザー定義関数は、SELECT文で起動できるPL/SQLファンクションです。シグネチャは、次のように戻されます。
Function udf_func (rowid varchar2, column_name varchar2, original_value varchar2) returns varchar2;
rowidは、第3引数のoriginal_valueの値を含む行の最小値(rowid)になります。
column_nameはマスキングされる列の名前です。
original_valueはマスキングされる値です。
つまり、それは、元の値を入力文字列として受け取り、マスク値を戻します。
入力値と出力値は、両方ともVARCHAR2です。たとえば、数値をマスキングするユーザー定義関数は、入力として100を受け取り(数値100の文字列表現)、99を戻します(数値99の文字列表現)。値は、表への挿入時に適切にキャストされます。値をキャストできない場合、マスキングは失敗します。
後処理関数を指定するには、「後処理関数」フィールドに関数を入力します。
後処理関数は、ユーザー定義関数と同じシグネチャを持ちますが、マスキング・エンジンが生成したマスク値を受け取り、マスキングに使用できるマスク値を戻します。次の例を参照してください。
Function post_proc_udf_func (rowid varchar2, column_name varchar2, mask_value varchar2) returns varchar2;
rowidは、mask_valueの値を含む行の最小値(ROWID)です。
column_nameはマスキングされる列の名前です。
mask_valueはマスキングされる値です。
1つ以上のフォーマットを作成したら、「フォーマットの作成」ページでテンプレートとしてフォーマット定義を使用し、新規フォーマットを最初から作成することなく、フォーマットの大部分を異なる名前で実装し、必要に応じてそのエントリを変更できます。
既存のフォーマットに似た新規フォーマットを作成するには、「フォーマット・ライブラリ」ページでフォーマットを選択し、「類似作成」をクリックします。マスキング・フォーマットには、以前に自分で定義したフォーマットか、即時利用可能なマスキング・フォーマットのリストから取得したフォーマットを選択できます。これらの汎用マスキング・フォーマット定義は、様々なアプリケーションに使用できます。
様々なOracle付属の事前定義済のマスキング・フォーマット定義と、要件に合せてそれらを変更する方法の詳細は、「Oracle付属の事前定義済のマスキング・フォーマットの使用」を参照してください。
Enterprise Managerには、即時利用可能ないくつかの事前定義済フォーマットが用意されています。.様々な事前定義済フォーマットと組込みフォーマットが用意されています。次の項では、様々なOracle付属のフォーマット定義と、要件に合せてそれらを変更する方法について説明します。
すべてのフォーマット定義は、次の一般的なパターンに準拠します。
ランダム数値またはランダム桁数を生成します。
生成された値に後処理が実行され、有効で現実的な値が最終的に生成されます。
たとえば、クレジット・カード番号が有効であるためには、Luhnチェックに合格する必要があります。つまり、クレジット・カード番号の最後の桁はチェックサム桁であり、この桁は常に計算されます。また、最初の数桁は、カード・タイプを示します(MasterCard、Amex、Visaなど)。したがって、クレジット・カードのフォーマット定義は、次のようになります。
ランダムで一意な10桁の数値を生成します。
後処理関数の使用により、既知のカード・タイプ接頭辞を追加して最後の桁を計算することで、前述の値を適切なクレジット・カード番号に変換します。
このフォーマットにより、100億個の異なるクレジット・カード番号を生成できます。
次の項では、これらの定義の異なるカテゴリについて説明します。
デフォルトでは、これらのマスキング・フォーマットは、ハイフン(-)形式などの異なるフォーマット・スタイルでも使用できます。フォーマット・スタイルは、必要に応じて変更できます。
デフォルトで、フォーマット・ライブラリには、クレジット・カード用の異なるフォーマットが多数用意されています。これらのフォーマットにより生成されたクレジット・カード番号は、アプリケーションによる標準的なクレジット・カード検証テストに合格するため、有効なクレジット・カード番号を装うことができます。
次のようなクレジット・カード・フォーマットを使用できます。
MasterCard番号
Visaカード番号
American Expressカード番号
Discover Card番号
任意のクレジット・カード番号(すべてのタイプのカードに属するクレジット・カード番号)
クレジット・カード番号を格納するために、次のような異なるスタイルを使用できます。
番号のみ
4桁ごとに空白を挿入
4桁ごとにハイフン(-)を挿入、など
マスキングされた値に特定のフォーマット・スタイルを適用するには、DM_FMTLIBパッケージのDM_CC_FORMAT変数を設定します。パッケージのインストール方法の詳細は、「DM_FMTLIBパッケージのインストール」を参照してください。
デフォルトで、有効な米国社会保障番号(SSN)を生成できます。これらのSSNは、有効なSSNを検証する通常のアプリケーション・テストに合格します。
DM_FMTLIBパッケージのDM_SSN_FORMAT変数を設定すると、フォーマット・スタイルを変更できます。たとえば、この変数を「-」に設定すると、一般的な社会保障番号は「123-45-6789」のように示されます。
フォーマット・ライブラリを使用して、10桁または13桁のISBN番号を生成できます。これらの番号は、標準的なISBN番号検証テストに合格します。これらのISBN番号は、事実上すべてランダムです。他のフォーマット定義と同様に、DM_ISBN_FORMATに値を設定することでISBNフォーマットのスタイルを調整できます。
フォーマット・ライブラリを使用して、有効なUPC番号を生成できます。これらの番号は、有効なUPC番号を検証する標準的なテストに合格します。DM_FMTLIBパッケージのDM_UPC_FORMAT値を設定すると、フォーマット・スタイルを変更できます。
フォーマット・ライブラリを使用して、有効なカナダ社会保険番号(SIN)を生成できます。これらの番号は、カナダSIN番号を検証する標準的なテストに合格します。フォーマット・スタイルを調整するには、DM_FMTLIBパッケージのDM_CN_SIN_FORMAT値を設定します。
事前定義済のマスキング・フォーマットは、DM_FMTLIBパッケージに定義されたファンクションを使用します。このパッケージは、Enterprise Managerリポジトリ・データベースのDBSNMPスキーマに自動的にインストールされます。(リポジトリ・データベースではなく)ターゲット・データベースで事前定義済のマスキング・フォーマットを使用するには、手動でそのデータベースにDM_FMTLIBパッケージをインストールする必要があります。
DM_FMTLIBパッケージをインストールするには、次の手順を実行します。
Enterprise Managerのインストール環境で次のスクリプトを検索します。
$PLUGIN_HOME/sql/db/latest/masking/dm_fmtlib_pkgdef.sql $PLUGIN_HOME/sql/db/latest/masking/dm_fmtlib_pkgbody.sql
PLUGIN_HOMEは、SYSMANとして実行される次のSQL SELECT文によって返される場所のいずれかです。
select PLUGIN_HOME from gc_current_deployed_plugin where plugin_id='oracle.sysman.db' and destination_type='OMS';
これらのスクリプトをターゲット・データベースのインストール環境にあるディレクトリにコピーし、DBSNMPスキーマにパッケージを作成できるユーザーとしてSQL*Plusに接続してから、これらのスクリプトを実行します。
これで、マスキング定義で事前定義済のマスキング・フォーマットを使用できます。
列マスクの定義ページの「フォーマットのインポート」ボタンをクリックし、事前定義済のマスキング・フォーマットを選択してマスキング定義にインポートします。
マスキング定義を作成する場合(「アプリケーション・データ・モデルおよびワークロードによるマスキング」)、フォーマットをインポートするか、「列マスクの定義」ページで使用できるいずれかの種類を選択します。フォーマット・エントリ・オプションは次のとおりです。
配列リスト
リストの各値のデータ型が、マスクされた列のデータ型と互換性を持つ必要があります。必要に応じて一意性が保証されることが必要です。たとえば、一意キー列にすでに10の固有値がある場合、配列リストにも少なくとも10の固有値が必要です。
削除
指定された行を条件句に従って削除します。条件の削除フォーマットが列に含まれていると、外部キー制約または依存列は表を参照できなくなります。
暗号化
正規表現を使用して列データを暗号化します。すべての行の列値が正規表現に一致する必要があります。このフォーマットは、データベース全体でデータを一貫してマスクするために使用されます。つまり、特定の値に対して、マスクされた同じ値が常に生成されます。
たとえば、正規表現[(][1-9][0-9]{2}[)][_][0-9]{3}[-][0-9]{4}によって、米国の電話番号((123) 456-7890など)が生成されます。
このフォーマットでは、正規表現言語のサブセットがサポートされます。固定幅の文字列の暗号化がサポートされます。ただし、*や+といった正規表現の構文はサポートされません。
指定されたフォーマットに値が一致しない場合、暗号化された値で1対1のマッピングが生成されない場合があります。すべての非確認の値が1つの暗号化された値にマップされるため、多対1マッピングが生成されます。
固定数値
このエントリに適用可能な列のタイプはNUMBER列またはSTRING列です。たとえば、社会保障番号を持つ列をマスクした場合、エントリの1つが固定数値900になる可能性があります。このフォーマットは結合できます。
固定文字列
このエントリに適用可能な列のタイプはSTRING列です。たとえば、ライセンス・プレート番号を持つ列をマスクした場合、エントリの1つが固定文字列CAになる可能性があります。このフォーマットは結合できます。
NULL値
NULL値を使用して列をマスキングします。列にはNULL値が設定可能でなければなりません。
後処理関数
これは、マスキング・エンジンが生成するマスク値に適用可能な特殊関数です。入力としてマスク値を使用し、マスキングに使用する実際のマスク値を返します。
後処理関数は、マスク値の生成後に呼び出されます。これにより、カンマやドル記号を値に追加できます。たとえば、マスク値が12000のような数値の場合、後処理関数を使用すると、この値を$12,000に変更できます。また、生成されたマスク値にチェックサムや特殊なエンコーディングを追加できます。
文の例:
Function post_proc_udf_func (rowid varchar2, column_name varchar2, mask_value varchar2) returns varchar2;
rowidは、第3引数のmask_valueの値を含む行の最小値(rowid)です。
column_nameはマスキングされる列の名前です。
mask_valueはマスキングされる値です。
元のデータの保持
指定された条件句に一致する行の元の値を保持します。これは、条件を満たす行の中に、マスキングの必要がない行が含まれている場合に使用します。
ランダム日付
DATE列の一意性は、マスキング後は維持されません。このフォーマットは結合できます。
ランダム桁数
このフォーマットは、指定範囲内で一意の値を生成します。たとえば、長さが[5,5]で、[0, 99999]間の整数のランダム桁数は、長さおよび一意性の要件を満たすよう左側が0で埋められてランダムに生成されます。これは、0で埋められることがないランダム数値の補完型です。ランダム桁数を使用する場合、文字列内で適切な長さになるように0が埋められます。番号の列に使用する場合、0は埋められません。このフォーマットは結合できます。
データのマスキングにより生成された値は一意です。ただし、十分な桁数を指定していない場合、指定した範囲内で一意の値がなくなる場合があります。
ランダム数値
混合ランダム文字列の一部として使用される場合、一意の値の生成に対する使用は制限されます。このフォーマットは、指定範囲内で一意の値を生成します。たとえば、開始値が100で終了値が200の場合、100以上200以下の範囲の整数が生成されます。Oracle Enterprise Managerリリース10.2.0.4.0はFLOAT数値をサポートしません。このフォーマットは結合できます。
ランダム文字列
このフォーマットは、指定範囲内で一意の値を生成します。たとえば、開始の長さが2で終了の長さが6の場合、2文字から6文字の長さのランダム文字列が生成されます。このフォーマットは結合できます。
シャッフル
このフォーマットでは、元の列データがランダムにシャッフルされます。列が条件付きでマスキングされており、その値が一意でない場合を除いて、データ配分は維持されます。
詳細は、「シャッフル・フォーマットの使用」を参照してください。
置換
このフォーマットは、元の値に対してハッシュ・ベースの置換を行い、任意の入力値に対して常に同じマスク値を生成します。置換マスキング表および列を指定します。このフォーマットには次のプロパティがあります。
マスキングされたデータは元に戻せません。つまり、このフォーマットでは、元の値は置換され、マスク値から元の値を取り出すことはできないため、外部のセキュリティ違反に対して脆弱ではありません。
別々のデータベースにおいて1つのハッシュ置換を使用して複数回マスキングを行うことで、同じマスク値を生成します。この特性は、複数のデータベース、または2回の実行で同じ置換値が使用されていれば複数回の実行にまたがって有効です。つまり、置換表の実際の行と値は変化しません。たとえば、2つの値JoeとTomがHenryとPeterにマスキングされたと想定します。同じ置換表を使用して、別のデータベースで同じマスキングを繰り返したとき、BobとTomが存在する場合に、LouiseとPeterに置換されるというような状況が起こります。2回の実行では異なるデータが使用されていますが、Tomは常にPeterに置換されていることに注意してください。
このフォーマットでは、一意性は得られません。
部分文字列
部分文字列はデータベースのsubstr関数と同様の動作をします。開始位置には正の整数または負の整数を設定できます。たとえば元の文字列がabcdの場合、開始位置が2で長さが3の部分文字列は、マスクされた文字列bcdを生成します。開始位置が-2で長さが3の部分文字列は、マスクされた文字列cdを生成します。このフォーマットは結合できます。
表の列
表の列により、置換値またはその一部として選択された列から値を選択できます。データ・タイプおよび一意性には互換性がある必要があります。それ以外の場合、ジョブの実行に失敗します。このフォーマットは結合できます。
切捨て
表のすべての行で切捨てが実行されます。列の1つが切捨てとマークされていると、表全体で切捨てが実行されるため、他の列にマスキング・フォーマットは指定できません。表で切捨てが実行されると、外部キー制約または依存列による参照ができなくなります。
ユーザー定義関数
出力値のデータ型と一意性は、元の出力値と互換性がある必要があります。それ以外の場合、ジョブの実行に失敗します。
文の例:
Function udf_func (rowid varchar2, column_name varchar2, original_value varchar2) returns varchar2;
rowidは、第3引数のoriginal_valueの値を含む行の最小値(rowid)になります。
column_nameはマスキングされる列の名前です。
original_valueはマスキングされる値です。
状況によっては、複数の異なるデータベースを一貫してマスキングする必要があります。たとえば、3つの異なるデータベースで従業員IDの概念を持つHR、給与および手当てを管理する場合、従業員のIDを選択することで従業員のHR、給与または手当ての情報を取得できるという意味において、この概念はすべてのデータベースで一貫性を保持する可能性があります。この前提に基づくと、実際に社会保障番号を含むために従業員のIDをマスキングする必要がある場合、これら3つのデータベースすべてで一貫してマスキングを行う必要があります。
決定論的マスキングにより、この問題を解決できます。置換フォーマットを使用して、3つのデータベースすべての従業員ID列をマスキングできます。置換フォーマットでは、値の表を使用して元の値をマスク値と置換します。この値の表が変更されないかぎり、3つのデータベース全体で決定論的なマスクまたは一貫したマスクを使用できます。
マスキング定義を作成する前に、次の前提条件およびアドバイス情報を確認してください。
データ・マスキングの最小限の権限を持っていることを確認します。
Enterprise Manager Cloud ControlユーザーのEM_ALL_OPERATOR
データベース・ユーザーのSELECT_CATALOG_ROLE
データベース・ユーザーのSelect Any Dictionary権限
DBMS_CRYPTOパッケージの権限を実行します
選択したフォーマットが、チェック制約に違反していないことと、そのデータを使用するアプリケーションを中断させないことを確認してください。
トリガーおよびPL/SQLパッケージでは、データ・マスキングによりオブジェクトが再コンパイルされます。
パーティション表(特にパーティション・キー)をマスキングする場合、注意が必要です。この場合、行が別のパーティションに移動する可能性があります。
データ・マスキングでは、クラスタ表、オブジェクト表のマスキング情報、XML表および仮想列はサポートされません。リレーショナル表はマスキングでサポートされます。
オブジェクトが表の上層に位置する場合(ビュー、マテリアライズド・ビュー、PL/SQLパッケージなど)、それらのオブジェクトは有効になるように再コンパイルされます。
パフォーマンス評価の目的でテスト・システムをマスキングする場合、次を実行することをお薦めします。
マスキング前スクリプトを追加して一時表にSQLプロファイルおよび統計をエクスポートしてから、マスキングの完了後にリストアすることで、マスキング後に、本番統計およびSQLプロファイルの保持を試行します。
「SQLパフォーマンス・アナライザ」評価を実行し、パフォーマンスに対するマスキングの影響を理解します。評価レポートに示されたもの以外のパフォーマンスの変更は通常、マスキングされたデータベースのアプリケーション固有の変更に関連しています。
「エンタープライズ」メニューから「クオリティ管理」を選択し、次に「データ・マスキング定義」を選択します。
「データ・マスキング定義」ページが開き、このページで新規のマスキング定義を作成し、スケジューリングしたり、既存のマスキング定義を管理できます。
「作成」をクリックして「マスキング定義の作成」ページに移動します。
マスキング定義には、表の列と各列のフォーマットに関する情報が含まれます。マスキングする列とそのまま残す列を選択できます。
必須の「名前」、「アプリケーション・データ・モデル」および「参照データベース」を入力します。
「検索」アイコンをクリックし、リストから「アプリケーション・データ・モデル」(ADM)の名前を選択すると、自動的に値が「参照データベース」フィールドに移入されます。
オプション: 「取得ファイル」と「SQLチューニング・セット」をマスキングする場合は、「ワークロード・マスキングの互換性を確認」を選択します。
このチェック・ボックスを有効にすると、マスキング定義が評価され、SQL式のフォーマットまたは条件付きマスキングが使用されているかどうかが判断されます。「OK」をクリックする際にいずれかが使用されている場合は、オプションのチェックが解除され、このオプションを選択する前にこれらのアイテムの削除を求めるエラー・メッセージが表示されます。
「追加」をクリックして、マスクするADMの機密列を選択できる「列の追加」ページへ移動します。
検索基準を入力し、「検索」をクリックします。
次の表に、ADMに定義した機密列が表示されます。
1つ以上の列を選択し、「マスキング定義の作成」ページで後でフォーマットするか、(選択した列のデータ型が同一の場合)その場でフォーマットします。
オプション: 選択した複数の列をグループとしてマスキングする場合、「選択した列をグループとしてマスキング」を有効にします。グループとしてマスキングする列は、すべて同じ表の列である必要があります。
複数の列を別々ではなく一緒にマスキングする場合、このチェック・ボックスを有効化します。2つ以上の列を選択し、「グループ・マスクの定義」ページのフォーマットを定義すると、列が一緒に表示され、選択したフォーマットの種類または表のマスキングがすべての列にまとめて適用されます。
グループを定義してこのページに戻ると、グループのすべてのメンバーの「列グループ」列に同じ数字が表示されます。たとえば、4つの列を含む最初のグループを定義した場合、このページの4つのエントリの「列グループ」列には1が表示されます。別のグループを定義すると、この列には2が表示されます。これにより、どの列がどのグループに所属するのか簡単に識別できます。
「追加」をクリックしてマスキング定義に列を追加し、「マスキング定義の作成」ページに戻って後で列のフォーマットを定義するか、「フォーマットの定義と追加」をクリックしてその場で列のフォーマットを定義します。
「フォーマットの定義と追加」機能では、かなりの時間を節約できます。同じデータ型の複数の列を選択して追加する場合、「追加」をクリックするときのように列ごとにフォーマットを定義する必要はありません。たとえば社会保障番号(SSN)を検索し、これによって100のSSN列が生じた場合、これらをすべて選択し、「フォーマットの定義と追加」をクリックしてからすべての列に対するSSNフォーマットをインポートできます。
次のいずれかを実行します。
前の手順で「追加」をクリックした場合:
操作を進めるには、「マスキング定義の作成」ページで列のフォーマットを定義する必要があります。準備ができていれば、フォーマットする列の 「フォーマット」 列ページでアイコンをクリックします。選択した列をグループとしてマスキングすることを「列の追加」ページで指定したかどうかに応じて、「列マスクの定義」または「グループ・マスクの定義」が表示されます。どちらの場合も、詳細はこの手順の後続の内容を参照してください。
前の手順で「フォーマットの定義と追加」をクリックし、「選択した列をグループとしてマスキング」を選択していない場合:
「列マスクの定義」ページが表示され、このページで、「マスキング定義の作成」ページに列を追加する前に、列のフォーマットを定義できます。
必須のデフォルト条件のフォーマット・エントリを指定するため、リストからフォーマット・エントリを選択して「追加」をクリックするか、「フォーマットのインポート」をクリックして「フォーマットのインポート」ページで事前定義済のフォーマットを選択し、「インポート」をクリックします。
「フォーマットのインポート」ページには、マスクされた列と同じ機密タイプでマークされたフォーマットが表示されます。
Oracle付属の事前定義済のマスキング・フォーマット定義の詳細は、「Oracle付属の事前定義済のマスキング・フォーマットの使用」を参照してください。
「フォーマット・エントリ」リストで使用できる選択肢の詳細は、「マスキング・フォーマットの指定による列の定義」を参照してください。
別の条件を追加するには、「条件の追加」をクリックして新しい条件行を追加し、前の手順に従って1つ以上のフォーマット・エントリを指定します。
列のフォーマット作業が終了したら、「OK」をクリックして「マスキング定義の作成」ページに戻ります。
前の手順で「フォーマットの定義と追加」をクリックし、「選択した列をグループとしてマスキング」を選択した場合:
「グループ・マスクの定義」ページが表示され、このページで、「マスキング定義の作成」ページに表示されるグループ列のフォーマット・エントリを追加できます。
使用可能ないずれかのフォーマット・タイプを選択します。フォーマット・タイプの詳細は、オンライン・ヘルプのグループ・マスキング・フォーマットの定義に関するトピックを参照してください。
「フォーマット・エントリ」リストで使用できる選択肢の詳細は、「マスキング・フォーマットの指定による列の定義」を参照してください。
オプションで、グループに列を追加します。
グループのフォーマット作業が終了したら、「OK」をクリックして「マスキング定義の作成」ページに戻ります。
「列」表に構成が表示されます。あらかじめ選択した機密列がこのページに表示されます。選択した列は主キーであり、外部キー列は下にリストされます。これらの列も同様にマスキングされます。
「拡張オプションの表示」を展開し、選択したデフォルト・データ・マスキングのオプションが十分であるかどうかを判断します。
詳細は、「データ・マスキング拡張オプションの選択」を参照してください。
「OK」をクリックして定義を保存し、「データ・マスキング定義」ページに戻ります。
この時点で、スーパー管理者は互いのマスキング定義を確認できます。
定義を選択して「スクリプトの生成」をクリックし、前に選択した列をマスキングするためのデータベース・コマンドのリストにスクリプトを表示します。
この処理では、操作で十分なディスク領域を使用できるかどうかを確認し、マスキング後に他の宛先オブジェクト(ユーザーなど)に影響があるかどうかも判断します。プロセスが完了すると「スクリプト生成結果」ページが表示され、次の操作が可能になります。
必要に応じて、PL/SQLスクリプト全体をデスクトップに保存します。
データベースのクローニング - データベースのクローニング・ウィザードを使用してデータベースをクローニングおよびマスキングします(これには、Database Lifecycle Management Packライセンスが必要です)。
クローニングせずにデータ・マスキング・ジョブをスケジューリングします。
影響レポートにエラーおよび警告を表示します(ある場合)。
次のいずれかを実行します。
本番データベースで作業している場合、「クローニングとマスキング」をクリックすると、現在作業しているデータベースがクローニングおよびマスキングされるため、本番データベースをマスキングする必要はありません。
「クローニングとマスキング」機能には、Database Lifecycle Management Packライセンスが必要です。
詳細は、「本番データベースのクローニング」を参照してください。
テスト・データベースですでに作業しており、そのデータベースのデータを直接マスキングする場合、「ジョブのスケジュール」をクリックします。
必須情報と必要なオプションを入力します。実行時のデータベースは任意のデータベースに指定できます。選択したデータベースは、ソース・データベースのクローンであるとみなされます。デフォルトでは、ADMからのソース・データベースが選択されます。
「発行」をクリックします。
データ・マスキング定義ページが表示されます。ジョブはEnterprise Managerに発行されており、マスキング・プロセスが表示されます。このページの「ステータス」列は、プロセスの現在のステージを示します。
|
ヒント: ページのユーザー・コントロールの詳細は、「データ・マスキング・ジョブのスケジュール」のオンライン・ヘルプを参照してください。 |
マスキング操作のための領域の要件の見積りのガイドラインを示します。これらの見積りは、予測される最大の表サイズが500GBであることに基づきます。マスキングの領域の見積もりでは、「最悪のシナリオ」を想定します。
インプレース・マスキングの場合:
マッピング表のために2 * 500GB (マッピング表には元の列およびマスクされた列の両方が格納されます。最悪の場合は、すべての列がマスクされます)。
元の表およびマスクされた表の両方のために2 * 500GB (マスキング・プロセス中のある時点でデータベース内に両方が存在します)。
一時表領域のために2 * 500GB (hash joins、sortsなどに必要です)。
最悪の場合の必要な合計領域は3TBです。
ソースでのマスキングの場合:
マッピング表のために2 * 500GB (インプレース・マスキングと同様)。
一時表領域のために2 * 500GB (インプレース・マスキングと同様)。
ダンプ・ファイルに対応する十分なファイル・システム領域。
最悪の場合の必要な合計領域は、2TBに必要なファイル・システム領域を加えたものです。
いずれの場合も、一時およびUNDO表領域を自動拡張に設定することをお薦めします。
スクリプトの生成中に、マッピング表用の表領域を指定できます。表領域を指定しない場合は、実行中のユーザーの表領域内に表が作成されます。シャッフル形式を使用しているときなど、状況によっては、マッピング表は必要ありません。そのような場合、インラインで元の表への更新が発生します。
依存列をアプリケーション・データ・モデルに追加することで、定義します。次の前提条件は、依存列として定義される列に適用されます。
マスキング用としてすでに含まれている列は、有効な依存列になりません。
外部キー列、または外部キー列に参照される列は、依存列に指定できません。
この列のデータは、親列のデータに準拠している必要があります。
列がこれらの基準を満たしていない場合、依存列を追加しようとすると、「無効な依存列」というメッセージが表示されます。
次の手順では、データ・ディクショナリに関係が定義されていないパッケージ・アプリケーションでの、列間でのデータのマスキング方法について説明します。
「データ検出およびモデリング」へ移動して、パッケージ・アプリケーション・スイートのメタデータ・コレクションを使用して、新しいアプリケーション・データ・モデル(ADM)を作成します。
メタデータ収集が完了してから、新しく作成されたADMを編集します。
「参照関係」タブから、「アクション」メニューを開き、「参照関係の追加」を選択します。
「参照関係の追加」ポップアップ・ウィンドウが表示されます。
必要な親キーおよび依存キー情報を選択します。
「列名」リストで、親キー列に関連付ける依存キー列を選択します。
「OK」をクリックして、参照関係をADMに追加します。
これで、新規依存列が参照関係リストに表示されます。
機密列の検出が完了したら、検索ジョブによって検出された列を確認し、必要に応じてそれらを機密または非機密としてマーク付けします。
機密としてマークされているとき、検出されたすべての機密列は、親と、親の他の子の列にも機密としてマーク付けします。このため、すべての関係を含むADMを最初に作成することをお薦めします。デフォルトでは、またはドライバの実行後、ADMが非正規化された関係を含むことはできません。これらは手動で追加する必要があります。
機密列の検出の詳細は、手順6を参照してください。
「データ・マスキング」へ移動して、新しいマスキング定義を作成します。
新しく作成したADMを選択して、「追加」をクリックしてから「検索」をクリックして、このADMの機密列を表示します。
検索結果に基づいて列を選択し、選択した列のフォーマットをインポートします。
Enterprise Managerで、プライバシ属性に準拠するフォーマットが表示されます。
フォーマットを選択し、スクリプトを生成します。
マスキング・スクリプトを実行します。
Enterprise Managerでは、生成されたスクリプトがターゲット・データベースで実行され、指定した列すべてがマスキングされます。
デフォルトでは、「マスキング定義」ページで次のオプションがすべて選択されているため、無効にしたいオプションは選択を解除してください。
マスキング中のREDOログ生成の無効化
マスキングを行うと、REDOロギングとフラッシュバック・ロギングが無効になり、元々マスキングされていないデータがログからパージされます。ただし、マスキングのテストのみを行い、変更をロールバックして複数のマスク列をテストする場合には、このチェック・ボックスの選択を解除し、マスキングを実行した後で、マスキングされていない古いデータをフラッシュバック・データベースから取得したほうが効率的です。Enterprise Managerでデータベースのフラッシュバックが可能です。
|
注意: このオプションを無効にすると、セキュリティが侵害される可能性があります。本番データベースのコピーに最終的なマスキングを実行する場合には、このオプションを有効にする必要がります。 |
マスキング後の統計のリフレッシュ
統計収集が有効になっているときに、ヒストグラムや異なるサンプリング率などの特殊オプションを統計収集で使用する場合には、このオプションをオフにしてデフォルトの統計収集を無効にし、独自の統計収集ジョブを実行します。
マスキング中に作成した一時表の削除
マスキングでは、元の重要なデータ値とマスク値を対応付けるため、一時表が作成されます。この情報を保持し、マスキングによるデータの変更を追跡する場合があります。ただし、これを行うと、セキュリティ侵害の危険性が高くなります。権限の低いユーザーにデータベースへのアクセスを許可する前に、これらの表は削除する必要があります。
暗号化列の複号化
このオプションでは、「暗号化」フォーマットを使用して以前にマスクされた列を復号します。以前に暗号化された列を復号化するには、シードの値が暗号化に使用した値と同じである必要があります。
暗号化に使用した元のフォーマットが元の値と一致する場合、復号化によって元の値のみがリカバリされます。元の暗号化された値が指定した正規表現に準拠していない場合、復号化すると、暗号化された値は元の値を再現できません。
可能な場合、パラレル実行を使用
Oracle Databaseでは、様々なSQL操作がパラレルで実行できるため、パフォーマンスが著しく向上します。このオプションを選択すると、この機能がデータ・マスキングで使用されます。Oracle Databaseに並列度を自動的に判別させることも、値を指定することもできます。パラレル実行と並行度の詳細は、『Oracle Databaseデータ・ウェアハウス・ガイド』を参照してください。
速度を優先
乱数の生成にDBMS_RANDOMパッケージが使用されます。
セキュリティを優先
乱数の生成にDBMS_CRYPTOパッケージが使用されます。また、「置換」フォーマットを使用する場合には、マスキング・ジョブまたはデータベース・クローニング・ジョブをスケジュールする際にシード値が必要です。
パフォーマンスの評価のためにテスト・システムをマスキングすると、マスキング後のオブジェクト統計保持に役立ちます。マスキング前スクリプトを追加して統計を一時表にエクスポートして、マスキングの終了後にマスキング後スクリプトを使用してリストアすることで、これを行います。
「マスク前スクリプト」テキスト・ボックスを使用して、マスキングの開始前に実行する必要のある任意のユーザー指定のSQLスクリプトを指定します。
「マスク後スクリプト」テキスト・ボックスを使用して、マスキング完了後に実行するSQLスクリプトを指定します。マスキングでデータが変更されるため、ブックをリバランスしたり、ロープアップ・モジュールや集計モジュールを呼び出して関連情報と集計情報の整合性を維持するなどのタスクも実行できます。
次に、統計を保持するためのマスク前およびマスク後スクリプトの例を示します。
例16-1 統計を保持するためのマスク前スクリプト
variable sts_task VARCHAR2(64); /*Step :1 Create the staging table for statistics*/ exec dbms_stats.create_stat_table(ownname=>'SCOTT',stattab=>'STATS'); /* Step 2: Export the table statistics into the staging table. Cascade results in all index and column statistics associated with the specified table being exported as well. */ exec dbms_stats.export_table_stats(ownname=>'SCOTT',tabname=>'EMP', partname=>NULL,stattab=>'STATS',statid=>NULL,cascade=>TRUE,statown=>'SCOTT'); exec dbms_stats.export_table_stats(ownname=>'SCOTT',tabname=>'DEPT', partname=>NULL,stattab=>'STATS',statid=>NULL,cascade=>TRUE,statown=>'SCOTT'); /* Step 3: Create analysis task */ 3. exec :sts_task := DBMS_SQLPA.create_analysis_task(sqlset_name=> 'scott_test_sts',task_name=>'SPA_TASK', sqlset_owner=>'SCOTT'); /*Step 4: Execute the analysis task before masking */ exec DBMS_SQLPA.execute_analysis_task(task_name => 'SPA_TASK', execution_type=> 'explain plan', execution_name => 'pre-mask_SPA_TASK');
例16-2 統計を保持するためのマスク後スクリプト
*Step 1: Import the statistics from the staging table to the dictionary tables*/ exec dbms_stats.import_table_stats(ownname=>'SCOTT',tabname=>'EMP', partname=>NULL,stattab=>'STATS',statid=>NULL,cascade=>TRUE,statown=>'SCOTT'); exec dbms_stats.import_table_stats(ownname=>'SCOTT',tabname=>'DEPT', partname=>NULL,stattab=>'STATS',statid=>NULL,cascade=>TRUE,statown=>'SCOTT'); /* Step 2: Drop the staging table */ exec dbms_stats.drop_stat_table(ownname=>'SCOTT',stattab=>'STATS'); /*Step 3: Execute the analysis task before masking */ exec DBMS_SQLPA.execute_analysis_task(task_name=>'SPA_TASK', execution_type=>'explain plan', execution_name=>'post-mask_SPA_TASK'); /*Step 4: Execute the comparison task */ exec DBMS_SQLPA.execute_analysis_task(task_name =>'SPA_TASK', execution_type=>'compare', execution_name=>'compare-mask_SPA_TASK');
データベースのクローニングおよびマスキングを行う場合、マスキング・スクリプトのコピーがEnterprise Managerリポジトリに保存され、クローニング・プロセスの完了後に取得されて実行されます。そのため、スキーマの変更後または本番データベースの変更後には、スクリプトを再生成することが重要です。
|
注意: 続行する前に、Database Lifecycle Management Packライセンスがあることを確認してください。データベースのクローニング機能には、このライセンスが必要です。 |
マスキング定義のターゲット・データベースをクローニングおよび(オプションで)マスキングするには、次の手順を実行します。
「データ・マスキング定義」ページで、クローニングするマスキング定義を選択し、「アクション」リストから「データベースのクローニング」を選択し、「実行」をクリックします。
「クローン・データベース: ソース・タイプ」ページが表示されます。
テスト・システムを作成してマスキングを実行できる、データベースのクローニング・ウィザードが表示されます。また、「スクリプト生成結果」ページの「クローニングとマスキング」ボタンをクリックしてこのウィザードにアクセスすることもできます。
クローニング操作に使用するソース・データベース・バックアップのタイプを指定して、「続行」をクリックします。
通常のデータベースのクローニングと同じように、ウィザードのステップを進めます。詳細は、各ステップのオンライン・ヘルプを参照してください。
ウィザードの「データベース構成」手順で、マスキング定義を追加してから「SQLパフォーマンス・アナライザ」オプションおよびその他の任意のオプションを選択します。
クローン・ジョブをスケジュールして実行します。
現在のEnterprise ManagerリポジトリにXMLファイルとして保存されている、以前にエクスポートされたデータ・マスキング定義テンプレート(Fusion Applicationsのテンプレートを含む)をインポートして再利用できます。
次の補足情報に注意してください。
XMLファイル・フォーマットは、マスキング定義のXMLフォーマットと互換性があることが必要です。
インポートするマスキング定義の名前がリポジトリにすでに存在していないことを確認します。
ターゲット名が有効なEnterprise Managerターゲットを識別することを確認します。
「データ・マスキング定義」ページで、「インポート」をクリックします。
「マスキング定義のインポート」ページが表示されます。
テンプレートに関連付けられたADMを指定します。参照データベースが自動的に指定されます。
XMLファイルを参照するか、またはXMLファイルの名前を指定してから、「続行」をクリックします。
「データ・マスキング定義」ページが再表示され、インポートされた定義が以降の表示およびマスキング用の表リストに表示されます。
データ・マスキング定義を作成した後、テスト・システムでのマスキングによるパフォーマンスの影響の分析に使用する場合があります。次の各項の手順では、マスキングのみまたはクローニングとマスキングでのこのタスクのプロセスを説明しています。
マスキングのみを使用してパフォーマンスを評価するには:
「データ・マスキング定義」ページで、分析するマスキング定義を選択してから「ジョブのスケジュール」をクリックします。
「データ・マスキング・ジョブのスケジュール」ページが表示されます。
ページの上部に、必要な情報を指定します。
スクリプト・ファイルの場所は、マスキング・スクリプトに関係し、これには「マスク前およびマスク後スクリプト」で作成したマスキング前およびマスキング後スクリプトも含まれます。
「暗号化シード」セクションで、暗号化に使用するテキスト文字列を指定します。
このセクションは、「置換」または「暗号化」フォーマットを使用するマスキング定義にのみ表示されます。シードは、暗号化/ハッシュベースの置換APIによって使用される暗号化キーで、マスキングがランダムではなく、より決定的になります。
「ワークロード」セクションで次を実行します。
必要に応じて、「SQLチューニング・セットのマスク」オプションを選択します。
機密データを含むSQLチューニング・セットを使用してパフォーマンスを評価する場合、セキュリティ、データベースとデータの整合性および適切な評価結果の生成のために有効です。
必要に応じて、「取得ファイル」オプションを選択して、取得ディレクトリを選択します。
このオプションを選択すると、ディレクトリのコンテンツがマスキングされます。取得ファイルのマスキングは、データベースと一貫した状態で実行されます。
「マスキングによるSQL計画の変更の検出」セクションで、「SQLパフォーマンス・アナライザの実行」オプションを選択解除します。
作成したマスキング前およびマスキング後スクリプト(手順2参照)は、すでにアナライザを実行しているため、このオプションを有効にする必要はありません。
資格証明およびスケジュール情報を指定して、「発行」をクリックします。
「データ・マスキング定義」ページが再表示され、データ・マスキング・ジョブが正常に発行されたことを示すメッセージが表示されます。
データベースのマスキング中に、AWRバインド変数データが削除され、機密バインド変数のテスト・システムへの漏洩を防止します。
ジョブが正常に完了してから、「SQLパフォーマンス・アナライザのタスク」列のリンクをクリックして、実行された分析タスクおよび計画の変更、タイミングなどを示す試行比較レポートを表示します。
クローニングおよびマスキングの両方を使用したパフォーマンスの評価は、「データ・マスキング・ジョブのスケジュール」からではなく、「データベースのクローニング」ウィザードからオプションを指定するという点以外は、前述の項で説明した手順と非常に類似しています。
クローニングおよびマスキングの両方を使用してパフォーマンスを評価するには:
「本番データベースのクローニング」で説明されている手順に従います。
手順4では、データベース構成手順のフォーマットが、「マスキングのみを使用した評価」で説明した「データ・マスキング・ジョブのスケジュール」ページとは異なって表示されますが、「データ・マスキング・ジョブのスケジュール」ページと同じようにオプションを選択します。
ウィザードの手順を続行して、クローニングおよびマスキング・ジョブを完了および発行します。
レガシー(11.1 Grid Control)マスク定義を12.1 Cloud Controlにインポートすると、レガシー・マスク定義から機密列およびその依存列情報が移入されたシェルADMが作成されます。アプリケーション・データ・モデル(ADM)は(またデータ・マスキングも)ディクショナリ関係がないため、検証されていない状態のままになります。
ディクショナリ定義の関係では、ADMをクリックして、検証を実行して参照関係を取り込む必要があり、これで有効になります。このADMでのマスキングを継続できます。
複数のアップグレードしたADMを結合するには、ADMをエクスポートして別のADMに対して「コンテンツのインポート」を実行します。
アップグレードしたADMでは、レガシー・マスク定義をインポートしたのと同じセマンティクスを使用し(前述で説明)、その際、検証を実行する必要があります。
Oracleより出荷されたEBSマスキング・テンプレートに基づく11.1 Grid Control E-Business Suite (EBS)マスキング定義は、アップグレード後にはカスタム・アプリケーションとして扱われます。上記の2番目の項目で説明されているアプローチを使用して、すべてのメタデータを持つ、新規に作成された EBS ADMにいつでも移行できます。だし、これは必須ではありません。
列値が一意でない場合および条件付でマスキングされている場合、データ配分を保持しないシャッフル・フォーマットが使用できます。たとえば、EmpNameとSalaryの2つの列がある元の表(表16-1)があるとします。Salary列には10、90、20という3つの個別の値があります。
Salary列をこのフォーマットでマスキングすると、元の値はそれぞれ、このセットの値の1つに置き換えられます。シャッフル・フォーマットが10を20に、90を10に、20を90に置き換えたと仮定します(表16-2)。
この結果シャッフルされたSalary列がマスクされた表(表16-3)に表示されますが、データ配分は変更されています。値10は元の表のSalary列では3回発生しますが、マスクされた表では2回発生するだけです。
salaryの値が一意である場合、フォーマットによりデータ配分が保持されます。
データ・マスキング・スクリプトの生成が完了したら、影響レポートが表示されます。マスキング定義に、データ型LONGの列を持つ表がある場合、影響レポートに次の警告メッセージが表示されます。
The table <table_name> has a LONG column. Data Masking uses "in-place" UPDATE to mask tables with LONG columns. This will generate undo information and the original data will be available in the undo tablespaces during the undo retention period. You should purge undo information after masking the data. Any orphan rows in this table will not be masked.