| Oracle® Databaseアドバンスト・レプリケーション 11g リリース2 (11.2) B72089-02 |
|


 前 |
 次 |
レプリケーション環境によっては、複数サイト間でのデータ・レプリケーションによって発生する可能性のあるデータ競合を解消する競合解消方法を作成する必要があります。
この章には、次の項が含まれます。
レプリケーションの競合は、複数のサイトから同じデータを同時に更新できるレプリケーション環境で発生します。たとえば、別々のサイトから発生した2つのトランザクションによって、同じ行がほとんど同時に更新されたときに競合が発生します。レプリケーション環境を構成するときは、レプリケーションの競合が発生する可能性の有無を考慮する必要があります。システム設計に競合を発生させる可能性がある場合や、競合が発生した場合には、なんらかの方法で競合を解消しないかぎりシステム・データは収束しません。
一般的に、まず必要なのは競合が発生しないレプリケーション環境を設計することです。ほとんどのシステム設計では、いくつかのテクニックを使用することによって、レプリケートするデータの全体または大部分で競合を回避できます。しかし、多くのアプリケーションでは、データの一部を複数のサイトからいつでも更新できる必要があります。その場合、レプリケーションの競合の発生に対処できる必要があります。
次の各項で、競合解消に関する次の項目について説明します。
レプリケーションの競合を考慮してレプリケーション・システムを設計する方法
使用するレプリケーション環境で発生する可能性のある競合タイプの判別方法
レプリケーション環境の設計においてレプリケーションの競合を回避する方法
競合を回避できない設計でOracleが競合を検出および解消する方法
この項には、次の項目が含まれます。
どのようなタイプのデータベース・アプリケーションおよびサポート・データベースを設計する場合でも、データベースまたはアプリケーション自体を構築する前にアプリケーション要件を理解することは非常に重要です。たとえば、各アプリケーションは、機能境界や依存性(受注入力、出荷、請求など)が正しく定義され、モジュール化されている必要があります。さらに、サポート・データベースのデータを正規化して、アプリケーション・システムのモジュール間の隠れた依存性を軽減する必要があります。
レプリケーション環境で動作するデータベースを作成する場合は、基本的なデータベース設計のルールのみでなく、その他の要件も検討する必要があります。まず、レプリケート・データを扱うアプリケーションの一般的な要件を考慮します。たとえば、一部のアプリケーションは読取り専用マテリアライズド・ビューの使用でも十分に対応できるので、結果的にレプリケーションの競合の発生を完全に回避できます。これに対して、大部分のレプリケート・データが読取り専用で、一部のデータ(たとえば、1つまたは2つの表、あるいは特定の表内の1つまたは2つの列)をすべてのレプリケーション・サイトで更新可能にする必要があるアプリケーションもあります。この場合は、レプリケーションの競合が発生したときにレプリケート・データの整合性が完全に保たれるように、競合解消方法を決定する必要があります。
競合を考慮したレプリケート・データベースの設計方法をよく理解するために、競合の検出および解消が可能な場合と不可能な場合がある、次のような環境を考えてみます。
通常、同じ商品に対して複数の予約を受け付けることができない予約システムでは、競合を解消できません。たとえば、コンサートの特定の座席を予約するときには競合を解消する方法がないため、予約システムの異なるレプリカにアクセスする異なるエージェントが、複数の顧客のために同じ座席を予約できません。
顧客管理システムでは、通常、競合を解消できます。たとえば、複数の営業担当員がレプリケーション環境内の異なるデータベースの顧客住所情報をメンテナンスできます。競合が発生しても、レコードに最新の更新内容を適用することで、更新の競合を解消できます。
レプリケート・データベース環境で検出されるデータ競合のタイプは、次のとおりです。
レプリケーション環境で発生する可能性が最も高いのは更新の競合ですが、一意性競合および削除の競合にも対処できるように準備する必要があります。これらのタイプの競合を回避できるようにデータベースを設計することをお薦めします。
更新の競合は、ある行に対する更新のレプリケーションが同じ行に対する別の更新と競合したときに発生します。異なるサイトから発生した2つの異なるトランザクションによって、同じ行がほとんど同時に更新されたときに発生することがあります。
一意性競合は、行のレプリケーションによってエンティティの整合性(主キー制約や一意制約など)が失われるときに発生します。たとえば、2つの異なるサイトから発生した2つのトランザクションで、同じ主キー値を使用してそれぞれの表レプリカに行を挿入した場合について考えます。この場合、トランザクションのレプリケーションが原因で一意性競合が発生します。
順序競合は、マスター・サイトが3つ以上あるレプリケーション環境で発生します。なんらかの理由でマスター・サイトXへの伝播がブロックされた場合、レプリケート・データへの更新を他のマスター・サイト間で伝播できます。伝播を再開したときに、これらの更新がその他のマスターで発生した順序と異なる順序でサイトXに伝播されると、更新の競合が発生する可能性があります。デフォルトでは、発生した競合はエラー・ログに記録され、依存関係にあるトランザクションが伝播および適用された後で再実行できます。順序競合の例は、表5-1を参照してください。
マスター・サイトが3つ以上あるレプリケーション環境でデータ収束を保証するには、マスター・サイトがいくつあっても確実にデータ収束を行える競合解消方法(最も新しいタイムスタンプ、最小値、最大値、優先グループ、加算)を選択する必要があります。
最小値、最大値、優先グループおよび加算による競合解消方法は、一定の条件が存在するかぎり、マスター・サイトがいくつあってもデータ収束が保証されます。詳細は、「競合解消のアーキテクチャ」で説明している競合解消方法を参照してください。
レプリケートされたトランザクションが順不同で適用されると、データ競合を受信するのみでなく、データのサポートがリモート・サイトに正常に伝播されていないと、そのサイトで参照整合性の問題が発生する場合があります。新規の顧客が受注部門に連絡する場合の使用例を考えます。顧客記録が作成され、受注が行われます。受注データが顧客データより前にリモート・サイトに伝播されると、受注で参照されている顧客はリモート・サイトに存在しないため、参照整合性エラーが発生します。
参照整合性エラーが発生した場合は、サポート・データがリモート・サイトに伝播された後でエラーが発生したトランザクションを再度実行すると、簡単に解決できます。
レプリケーション・システムの各マスター・サイトは、レプリケーションの競合が発生するとそれを自動的に検出し、解消します。たとえば、あるマスター・サイトがシステム内の別のマスター・サイトに遅延トランザクション・キューをプッシュするときに、レプリケーションの競合があれば、その競合は呼び出された受信サイトのリモート・プロシージャによって自動的に検出されます。
マテリアライズド・ビュー・サイトが対応するマスター・サイトまたはマスター・マテリアライズド・ビュー・サイトに遅延トランザクションをプッシュすると、受信サイトで競合の検出および解消が行われます。マテリアライズド・ビュー・サイトでは、マテリアライズド・ビューのリフレッシュを実行することによってデータをリフレッシュします。このリフレッシュの仕組みによって、リフレッシュ完了後には、競合解消結果を含めたマテリアライズド・ビューのデータが、対応するマスター表またはマスター・マテリアライズド・ビューのデータと同一になります。したがって、マテリアライズド・ビュー・サイトでレプリケーションの競合の検出または解消を実行する必要はありません。
レプリケーション・システムでの受信側のマスター・サイトまたはマスター・マテリアライズド・ビュー・サイトでは、次のような更新の競合、一意性競合および削除の競合が検出されます。
レプリケート行の古い値(変更前の値)と受信サイトの同じ行の現在の値が異なる場合、受信サイトで更新の競合が検出されます。
レプリケート行のINSERTまたはUPDATEの実行中に一意制約違反が発生した場合、受信サイトで一意性競合が検出されます。
行の主キーが存在しないために受信サイトでUPDATE文またはDELETE文の対象の行が見つからない場合、受信サイトで削除の競合が検出されます。
|
注意:
|
競合が検出された場合は、競合を解消してすべてのサイトでデータ収束を実行します。Oracleには、更新の競合を解消するビルトインの競合解消方法が用意されており、通常は、この方法を使用することで、様々なレプリケーション環境のデータ収束を保証できます。また、一意性競合に対する競合解消方法もありますが、これはデータ収束を保証しません。
削除の競合または順序競合については、ビルトインの競合解消方法はありません。ただし、ビジネス・ルールに固有の競合解消方法を独自に作成できます。データ収束を保証しない競合解消方法(特に、一意性競合および削除の競合の解消方法)を作成する場合、通知機能を作成してデータベース管理者にデータ収束を手動で実現するように依頼する必要があります。
ビルトインの競合解消方法またはユーザー定義の競合解消方法のいずれを使用する場合も、競合が検出されると即時に適用されます。定義した競合解消方法で競合を解消できない場合は、その競合はエラー・キューにロギングされます。
競合解消が1つの時点で失敗するのを回避するために、別の競合解消方法を定義して、主要な競合解消方法の予備を作成できます。たとえば、タイムスタンプが同一であるため、最も新しいタイムスタンプによる競合解消方法では競合を解消できない場合(このような状況が発生することはほとんどありません)、サイト優先の競合解消方法を定義でき、これにより、タイムスタンプを使用せずにデータ競合を解消できます。
|
関連項目: 変更をレプリケートせずに表を変更する方法の詳細は、『Oracle Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス』を参照してください。自動的に解消されない競合を手動で解消するときに、この方法が必要になることがあります。 |
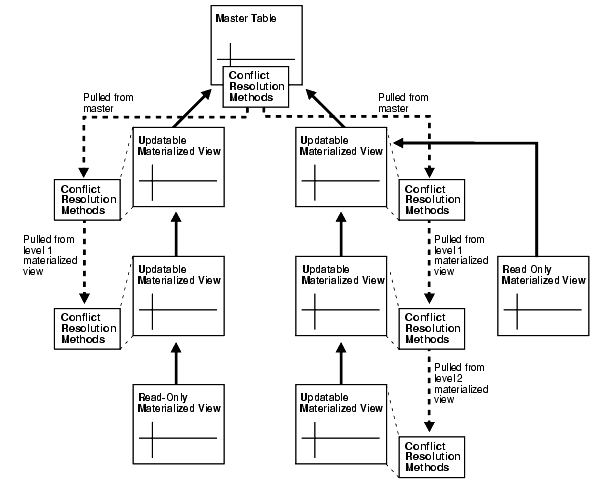
マスター表とこのマスター表に基づいた更新可能マテリアライズド・ビューがあった場合、マテリアライズド・ビューをリフレッシュすると変更がマスター・サイトにプッシュされ、プッシュによって競合が発生した場合には、マスター・サイトが構成済の競合解消方法を使用して競合を処理します。次に、マテリアライズド・ビューはリフレッシュ完了時にマスターの変更を取り出します。リフレッシュは、常にマテリアライズド・ビュー・サイトで開始されます。
同様に、更新可能マテリアライズド・ビューのマスター・マテリアライズド・ビューは、マスター表と同じ動作をします。ただし、マスター・マテリアライズド・ビューでは、マテリアライズド・ビューからのプッシュによって発生する競合を処理するときに、マスターからプルした競合解消方法を使用します。この場合、マスターはマスター・サイトのマスター表、あるいは別のマテリアライズド・ビュー・サイトのマスター・マテリアライズド・ビューのいずれかです。競合解消方法をマテリアライズド・ビューに直接構成することはできません。かわりに、更新可能マテリアライズド・ビューを作成したとき、およびマテリアライズド・ビューのレプリケーション・サポートを生成したときに、上位のマスターから競合解消方法が自動的にプルされます。読取り専用マテリアライズド・ビューは、マスターから競合解消方法をプルしません。
たとえば、レベル3のマテリアライズド・ビューがレベル2のマスター・マテリアライズド・ビューに変更をプッシュしたとします。このプッシュにより、レベル2のマテリアライズド・ビューで競合が発生したとします。レベル2のマテリアライズド・ビューでは、競合を処理するために、レベル1のマスター・マテリアライズド・ビューから以前にプルした競合解消方法を使用します。同様に、レベル1のマテリアライズド・ビューでは、マスター・サイトから以前にプルした競合解消方法を使用して競合を処理します。図5-1に、この構成を示します。
各更新可能マテリアライズド・ビューは、従属するマテリアライズド・ビューがない場合でも、マスターから競合解消方法をプルします。読取り専用マテリアライズド・ビューは、マスターから競合解消方法をプルしません。
多重化マテリアライズド・ビューが含まれる環境でマスター表の競合解消方法を変更する場合は、次の一般的な手順を実行します。
列グループまたはキー列のいずれかを変更する場合で、マスター表に基づいたどの更新可能マテリアライズド・ビューとも最小限の通信しか実行していない場合は、次のサブステップを実行します。
必要な場合は、マスター・グループを静止します。
マスター定義サイトで競合解消方法を変更します。
DBMS_REPCATパッケージのGENERATE_REPLICATION_SUPPORTプロシージャまたはOracle Enterprise Managerのアドバンスト・レプリケーション・インタフェースを使用して、マスター定義サイトで影響を受けるオブジェクトのレプリケーション・サポートを再生成します。
手順2でマスター・グループを静止した場合は、マスター・グループのレプリケーション・アクティビティを再開します。
レプリケーション・サポートがまだ再生成されていない、最上位のレベル番号のマテリアライズド・ビューのレプリケーション・サポートを再生成します。再生成中に、現在の競合解消方法が上位のマスターからプルされます。この手順を初めて実行した場合、これがレベル1のマテリアライズド・ビュー用で、2回目に実行した場合はレベル2のマテリアライズド・ビュー用、というようになります。DBMS_REPCATパッケージのGENERATE_MVIEW_SUPPORTプロシージャまたはOracle Enterprise Managerのアドバンスト・レプリケーション・インタフェースを使用して、マテリアライズド・ビューのレプリケーション・サポートを再生成します。
手順1でサブステップを実行した場合は、現在DML変更が禁止されている、最上位のレベル番号のマテリアライズド・ビューでDML変更を使用できるようにします。この手順を初めて実行した場合、これがレベル1のマテリアライズド・ビュー用で、2回目に実行した場合はレベル2のマテリアライズド・ビュー用、というようになります。
マスター表から最下位のマテリアライズド・ビューに手順6および手順7を実行するまで、各マテリアライズド・ビュー・レベルに対してこの2つの手順を繰り返します。たとえば、マテリアライズド・ビューが3レベルある場合は、最後の手順はレベル3のマテリアライズド・ビューに対して実行されます。
レプリケーション・サポートのこの再生成は、自動的には実行されません。複数のデータベース管理者がマスター・サイトとマテリアライズド・ビュー・サイトを管理する環境では、マスター・サイトのデータベース管理者は影響される全マテリアライズド・ビュー・サイトのデータベース管理者に対して、競合解消方法の変更を通知する必要があります。その後、すべてのデータベース管理者が協力して、前述の手順を適切に実行する必要があります。
列のサブセット化を使用すると、マテリアライズド・ビューの作成中にSELECT文で特定の列を指定することによって、マスター表の列をマテリアライズド・ビューから除外できます。更新可能マテリアライズド・ビューに列グループの列のサブセットのみが含まれる場合、競合解消方法が廃棄またはサイト優先順位のいずれかでない場合には、この列グループで競合解消方法を作成しないでください。競合解消方法がサイト優先順位の場合、列のサブセット化は、マスター・サイトがマテリアライズド・ビュー・サイトよりも高い優先番号を持つシングル・マスター・レプリケーション環境でのみ使用する必要があります。
前述の廃棄による解消方法およびサイト優先順位による解消方法以外の競合解消方法の場合、更新可能マテリアライズド・ビューは列グループ内のいくつかの列に関する変更情報を送信しますが、その他の列に関しては情報を送信しないため、競合解消方法が適用されるときにエラーが戻されます。廃棄による解消方法とサイト優先順位による解消方法は列情報に依存しないため、これらの競合解消方法は列のサブセット化とともに使用できます。
たとえば、employeesマスター表に列グループがあり、この列グループにはemployee_id列、manager_id列、department_id列およびtimestamp列が含まれているとします。最新のタイムスタンプによる競合解消方法をマスター・サイトの列グループに対して定義します。次に、employeesマスター表に基づいてemployees_mvという更新可能マテリアライズド・ビューを作成しますが、列のサブセット化を使用して、このマテリアライズド・ビューからdepartment_id列を除外します。マテリアライズド・ビューでemployee_id列またはmanager_id列が更新されると、次のリフレッシュ時にこの変更情報がマスター・サイトに送信されます。マスター・サイトでは、競合解消方法が適用されるときに、列グループの残りの列(department_id)に関する情報がないため、エラーが戻されます。
多重化マテリアライズド・ビューを使用する場合は、前述のことを考慮します。競合解消方法がマスター・サイトからマスター・マテリアライズド・ビュー・サイトに取り出されるため、マスター・マテリアライズド・ビュー・サイトとそれに基づいた更新可能マテリアライズド・ビューに対しても、これと同じ規則が適用されます。
各ネストした表の列に対して、表にNESTED_TABLE_ID列という非表示列が作成されます。また、ネストした表の要素を格納するために、記憶表という個別の表が作成されます。この記憶表には、各親表の行用のネストした表の各要素の行が格納されます。また、この記憶表には、親表のNESTED_TABLE_ID列に対応し、特定の親行用のネストした表の要素を特定するために使用されるNESTED_TABLE_ID列も含まれます。ネストした表の列では、アドバンスト・レプリケーションにおいて特別な考慮が必要です。基礎となる記憶表は、親表と同程度の競合解消に対する考慮が必要で、さらに考慮すべき問題があります。
アドバンスト・レプリケーションでは、ネストした表に対するデータ操作言語(DML)文を、親表および記憶表に対するDML文とは別に処理します。ネストした表の列に対してDML文が実行された場合、DML文のタイプにより実行されるアクションが異なります。DML文のタイプとそれぞれのタイプに対して実行されるアクションを、次の表に示します。
| INSERT文 | DELETE文 | UPDATE文 |
|---|---|---|
|
|
|
次の例は、ネストした表に対するDML文が、解消の困難な競合につながる可能性があることを示しています。コード例に続いて、競合を最小化する方法について説明しています。
各学部の情報をdepartment表に格納する大学があったとします。この表には、各学部の履修課程の情報を格納するネストした表が含まれています。
CREATE TYPE Course AS OBJECT (
course_no NUMBER(4),
title VARCHAR2(35),
credits NUMBER(1));
/
CREATE TYPE CourseList AS TABLE OF Course;
/
CREATE TABLE department (
name VARCHAR2(20) primary key,
director VARCHAR2(20),
office VARCHAR2(20),
courses CourseList)
NESTED TABLE courses STORE AS courses_tab(
(PRIMARY KEY(nested_table_id,course_no)));
この大学はアメリカ全土にキャンパスがあり、マルチマスター・レプリケーションを使用して様々なキャンパスをサポートしています。各キャンパスではdepartment表を更新できます(この表はレプリケート表です)。マスター・サイトの1つであるuniv1.example.comで、Psychology学部に対して情報が挿入されます。
INSERT INTO department
VALUES('Psychology', 'Irene Friedman', 'Fulton Hall 133',
CourseList(Course(1000, 'General Psychology', 5),
Course(2100, 'Experimental Psychology', 4),
Course(2200, 'Psychological Tests', 3),
Course(2250, 'Behavior Modification', 4),
Course(3540, 'Groups and Organizations', 3),
Course(3552, 'Human Factors in Business', 4),
Course(4210, 'Theories of Learning', 4)));
アドバンスト・レプリケーションにより、この挿入が全マスターに伝播されます。
次に、Psychologyクラスに関する変更情報が届きます。つまり、クラスが1つ追加されます。この情報がuniv1.example.comで更新されます。
UPDATE department SET courses = CourseList(
Course(1000, 'General Psychology', 5),
Course(2100, 'Experimental Psychology', 4),
Course(2200, 'Psychological Tests', 3),
Course(2250, 'Behavior Modification', 4),
Course(3540, 'Groups and Organizations', 3),
Course(3552, 'Human Factors in Business', 4),
Course(4210, 'Theories of Learning', 4),
Course(4320, 'Cognitive Processes', 4))
WHERE name = 'Psychology';
univ1.example.comが更新をコミットした後、他のマスター・サイトに変更が伝播される前に、別のマスター・サイトuniv2.example.comが、4320および4410という2つのクラスが追加されたという情報を受け取ります。
UPDATE department SET courses = CourseList(
Course(1000, 'General Psychology', 5),
Course(2100, 'Experimental Psychology', 4),
Course(2200, 'Psychological Tests', 3),
Course(2250, 'Behavior Modification', 4),
Course(3540, 'Groups and Organizations', 3),
Course(3552, 'Human Factors in Business', 4),
Course(4210, 'Theories of Learning', 4),
Course(4320, 'Cognitive Processes', 4),
Course(4410, 'Abnormal Psychology', 4))
WHERE name = 'Psychology';
univ1.example.comでの更新とuniv2.example.comでの更新の両方がプッシュされます。
department表に更新競合がありそうです。更新を行ったユーザーは、それがINSERT文後の最初の更新であると思っています。しかし、実際にはローカルの更新が最初に行われているため、これらは親表での更新となるのでNESTED_TABLE_IDは変更されています。これはネストした表の列での更新(記憶表の行とNESTED_TABLE_IDを変更)のみで、問題が多くなります。親表での他の列の更新は問題はありません。
ローカルな表を最新状態にすることにより、この競合が解消されるとします。ローカルな更新によりすでに削除されている行を無視するように、記憶表に対して削除による競合解消方法が必要になります。記憶表に挿入された新規行は、リモート・サイトでの更新のため、親表に参照先がありません。記憶表のこの新規行も処理する必要があります。そうしない場合、これらの行が孤立してしまいます。記憶表には、department表からアクセスできないcourse行が増えてしまいます。
記憶表の行を操作しながら親表を更新するという競合解消は、マルチマスター・レプリケーション環境に2つのマスター・サイトがある場合は非常に困難で、マスター・サイトが増えた場合はほとんど不可能です。このような更新が必要な場合は、ネストした表に競合解消方法を定義せずに、競合は手動で解消するというのが最善の方法です。競合解消方法が正しくない場合、データの相違が発生する可能性があります。つまり、異なるマスター上の表が一致しなくなる危険性があります。
次に示した方法(推奨)により、前項で説明した更新の問題を回避できます。
ネストした表に対して、最初は遅延されている外部キー制約を使用します。この制約により、記憶表で参照先がない行が発生しません。このような外部キー制約の例を、次に示します。
ALTER TABLE courses_tab add CONSTRAINT courses_fk FOREIGN KEY(NESTED_TABLE_ID) REFERENCES department(courses) INITIALLY DEFERRED;
親表に対するすべての挿入で、空のネストした表が挿入されるようにします。ネストした表の値にNULLは使用しないでください。これにより、再利用可能なNESTED_TABLE_IDを作成できます。空のネストした表を含む挿入の例を、次に示します。
INSERT INTO department (name, director, office, courses)
VALUES('Psychology', 'Irene Friedman', 'Fulton Hall 133', CourseList());
すべての挿入、削除および更新は、DMLを介して親表に実行するのではなく、ネストした表に対して直接実行します。これにより、現在のNESTED_TABLE_ID値を再利用できます。
ネストした表から行を直接削除する例を、次に示します。
DELETE FROM TABLE (SELECT courses FROM department WHERE name = 'Psychology');
univ1.example.comのネストした表に次の行が直接挿入される例を考えてみます。
INSERT INTO TABLE (SELECT courses FROM department WHERE name = 'Psychology') VALUES (Course(5000, 'Social Psychology', 5)); INSERT INTO TABLE (SELECT courses FROM department WHERE name = 'Psychology') VALUES (Course(5100, 'Psychology of Personality', 4));
次に、univ1.example.comに対する前述の挿入がプッシュされる前に、次の行がuniv2.example.comのネストした表に直接挿入されます。
INSERT INTO TABLE (SELECT courses FROM department WHERE name = 'Psychology') VALUES (Course(5000, 'Social Psychology', 5)); INSERT INTO TABLE (SELECT courses FROM department WHERE name = 'Psychology') VALUES (Course(5100, 'Psychology of Personality', 4)); INSERT INTO TABLE (SELECT courses FROM department WHERE name = 'Psychology') VALUES (Course(5500, 'Cognitive Neuroscience', 5));
ここで、course 5000および5100に関して記憶表に挿入された行で主キー競合が発生しますが、1つのサイトからの挿入が失敗しても問題のない競合解消方法を記憶表に定義すると正しい結果が得られます。ただし、この場合、これらの挿入により「ネストした表の競合の例」で説明された複数の表が関与する複雑な問題は発生せず、NESTED_TABLE_IDの値も変更されないため、この値が失われることはありません。
ネストした表の列の操作を含む挿入および更新を回避するようなトリガーを、親表に対して使用することを考慮します。このようなトリガーの例を次に示します。
CREATE OR REPLACE TRIGGER depart_trig
AFTER INSERT OR UPDATE ON department
FOR EACH ROW
DECLARE
new_ntid raw(100);
old_ntid raw(100);
BEGIN
-- obtain the nested table ids
SELECT sys_op_tosetid(:new.courses) INTO new_ntid from dual;
SELECT sys_op_tosetid(:old.courses) INTO old_ntid from dual;
IF INSERTING THEN
-- raise error on insert of a null nested table column
IF :new.courses IS NULL THEN
raise_application_error(-20011, 'inserting null nested table ref');
END IF;
-- raise error if new rows are inserted in the storage table
-- this is not strictly necessary, but it does enforce DML access
-- semantics of separate DMLS on parent table and storage table
IF :new.courses.count != 0 THEN
raise_application_error(-20012,
'inserting rows into storage table while inserting parent table row');
END IF;
ELSE
-- raise error if update has caused the NESTED_TABLE_ID to change
IF new_ntid != old_ntid THEN
raise_application_error(-20013,
'updating storage table reference while updating parent table row');
END IF;
END IF;
END;
/
前述の推奨事項は、記憶表の行が別の記憶表の行の親になる複数レベルのネストにも適用されます。これらの推奨事項は、ネストの各レベルでの適切な競合対策になります。
Oracleではデータ競合を解消する強力な競合解消方法がありますが、レプリケート・データベースやフロントエンド・アプリケーションの設計時にまず優先する必要があるのは、データ競合を回避することです。以降の項では、レプリケーション競合の一部または全部を回避するためのテクニックを簡単に説明します。
列グループを使用すると、列グループに対して競合解消方法を適用しない場合でも、競合の回避に役立ちます。レプリケート表に複数列グループが含まれている場合、更新の競合が発生しているかどうかの分析は列グループごとに個別に行われます。
たとえば、列グループa_cgと列グループb_cgが含まれているレプリケート表を考えてみます。列グループa_cgには、a1、a2およびa3という列が含まれています。列グループb_cgには、b1、b2およびb3という列が含まれています。
レプリケーション・サイトのsf.example.comとla.example.comで次の更新が発生します。
ユーザーwsmithがsf.example.comの1つの行の列a1を更新します。
同一時刻に、ユーザーmrothがla.example.comの同一行の列b2を更新します。
この場合、Oracleでは列グループa_cgとb_cgでの更新は別々に分析されるため、競合は発生しません。ただし、列グループa_cgとb_cgがなかった場合は、表の全列が1つの列グループに入ることになり、競合が発生します。また、列グループが存在し、ユーザーmrothが列b2ではなくa3を更新した場合は、a1とa3が同じa_cg列グループにあるため、競合が発生します。
レプリケーションの競合の発生を回避する1つの方法として、システム内でレプリケート・データに同時更新アクセスできるサイトの数を制限する方法があります。プライマリ・サイト所有権と動的サイト所有権という、レプリケート・データの2つの所有権モデルにより、この方法がサポートされます。
プライマリ所有権は、読取り専用レプリケーション環境でサポートされるレプリケート・データ・モデルです。プライマリ所有権によって、一連のレプリケート・データに更新アクセスできるサーバーは1つに限定されるため、すべてのタイプのレプリケーションの競合が発生しません。
表レベルでデータの所有権を制御せずに、アプリケーションで行のサブセット化および列のサブセット化の機能を使用すると、データの静的所有権をより細かく設定できます。たとえば、サイト別の基準でレプリケート表の特定の列または行に更新アクセスできます。
動的所有権レプリケート・データ・モデルは、プライマリ・サイト所有権よりも制限の少ないモデルです。動的所有権の場合、データ・レプリカを更新する権利はサイトからサイトへ移動しますが、ある時点で特定のデータに更新アクセスできるサイトは1つしかありません。ワークフロー・システムに動的所有権の概念がわかりやすく示されています。たとえば、関連する部門のアプリケーションでは、注文を更新できる時期を判断するために、製品注文のステータス・コード(enterable、shippable、billableなど)を使用できます。
|
関連項目: 動的所有権データ・モデルの使用方法の詳細は、『Oracle Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス』を参照してください。 |
プライマリ・サイト所有権および動的所有権データ・モデルを使用するとアプリケーション要件に対して制限が多すぎる場合には、共有所有権データ・モデルを使用する必要があります。その場合でも、通常は、特定のタイプの競合を回避するためにいくつかの簡単な方法を使用する必要があります。
一意性競合が発生しないようにレプリケーション環境を構成するのは非常に簡単です。たとえば、順序が互いに排他的な一連の順序番号を生成するように、各サイトで順序を作成できます。ただし、この方法を使用する場合、サイト数またはレプリケート表内の項目数が増加するほど問題が多く発生します。
また、複合主キーの一部として一意のサイト識別子を追加する方法もあります。
さらに、SYS_GUIDファンクションを使用してグローバルに一意の値を選択できます。選択した値を主キー(または一意の)値として使用すると、一意性競合がグローバルに回避されます。
|
注意: 順序は、レプリケーションの有効なオブジェクト型ではありません。したがって、各サイトで順序を作成する必要があります。 |
削除の競合は、レプリケート・データ環境では常に回避する必要があります。一般的に、非同期の共有所有権データ・モデル環境で動作するアプリケーションでは、DELETE文を使用して行を削除しないでください。かわりに、アプリケーションで行に削除のマークを付けて、論理的に削除された行をプロシージャ・レプリケーションを使用して定期的にパージするようにシステムを構成できます。
|
関連項目: 削除の競合を防止するように表を準備し、マークされた行をパージするレプリケート・プロシージャを作成する方法は、『Oracle Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス』に記載された削除の競合防止方法の作成手順を参照してください。 |
レプリケーション・システムでは、一意性競合と削除の競合の発生を回避するように試みた後、さらに更新の競合の発生数を少なく抑える必要があります。ただし、共有所有権データ・モデルでは、更新の競合をすべて回避することはできません。更新の競合をすべて回避できない場合は、発生する可能性のあるレプリケーションの競合のタイプを正確に理解し、競合が発生したときに解消できるようにシステムを構成する必要があります。
順序競合はできるかぎり回避するか自動的に解消するようにします。たとえば、順序競合が発生する可能性のあるマルチマスター構成で収束を保証する競合解消方法を選択します。
表5-1の例は、3つのマスター・サイトでどのような場合に順序競合が発生するかを示しています。マスター・サイトAの優先順位は30、マスター・サイトBの優先順位は25、マスター・サイトCの優先順位は10で、xは、サイト優先順位による競合解消方法が割り当てられている列グループ内の特定の行の列です。優先順位の値が最も高いサイトに、最も高い優先順位が割り当てられています。優先順位値は任意のOracle番号で、連続する整数でなくてもかまいません。
表5-1 例: サイト優先順位による競合解消方法を使用した場合の順序競合
| 時間 | アクション | サイトA | サイトB | サイトC |
|---|---|---|---|---|
|
1 |
すべてのサイトが稼働していて、x = 2で一致します。 |
2 |
2 |
2 |
|
2 |
サイトAでx = 5に更新します。 |
5 |
2 |
2 |
|
3 |
サイトCが使用不可になります。 |
5 |
2 |
ダウン |
|
4 |
サイトAがサイトBに更新をプッシュします。サイトAとサイトBがx = 5で一致します。サイトCは使用不可のままです。更新トランザクションはサイトAのキューに残ります。 |
5 |
5 |
ダウン |
|
5 |
サイトCがx = 2で使用可能になります。サイトAとサイトBはx = 5で一致します。 |
5 |
5 |
2 |
|
6 |
サイトBでx = 5をx = 7に更新します。 |
5 |
7 |
2 |
|
7 |
サイトBがトランザクションをサイトAにプッシュします。サイトAとサイトBがx = 7で一致します。サイトCはx = 2のままです。 |
7 |
7 |
2 |
|
8 |
サイトBがトランザクションをサイトCにプッシュします。サイトCの古い値はx = 2で、サイトBの古い値はx = 5です。競合が検出され、サイトCの優先順位(10)より高い優先順位(25)を持つサイトBの更新を適用することで、競合が解消されます。すべてのサイトがx = 7で一致します。 |
7 |
7 |
7 |
|
9 |
サイトAがそのトランザクション(x = 5)を正常にサイトCにプッシュします。サイトCの現在の値(x = 7)がサイトAの古い値(x = 2)と一致しないため、競合が検出されます。サイトAはサイトC(10)より高い優先順位(30)を持ちます。サイトAの古い更新(x = 5)を適用することで、競合が解消されます。この競合処理の順序が原因で、サイトのデータは収束しません。 |
7 |
7 |
5 |
レプリケーション環境に競合解消方法を実装するときに、アーキテクチャ上のメカニズムやプロセスを意識することはほとんどありません。この項では、競合解消に関連するいくつかのサポート・メカニズムについて説明し、Oracleに組み込まれている競合解消方法を様々な観点から説明します。
この項には、次の項目が含まれます。
Oracleの競合解消に関連する最も重要なメカニズムは列グループであり、更新の競合の検出および解消はすべて、列グループに基づいて行われます。また、エラー・キューには、レプリケーション環境の競合検出アクティビティを監視するための重要な情報が記録されています。
Oracleでは、更新の競合を検出および解消するために列グループを使用します。列グループは、レプリケート表の1つ以上の列を論理的にグループ化したものです。レプリケート表の各列は、1つの列グループの一部になります。マスター定義サイトでレプリケート表を構成するときに、列グループを作成して、各グループに列および対応する競合解消方法を割り当てることができます。
列グループには次のような特性があります。
列が属するのは1つの列グループのみです。
列グループは、表の1つ以上の列で構成できます。
競合解消が適用されるのは、列グループ内の列のみです。
列グループを使用すると、データのタイプに応じて異なる競合解消方法を指定できます。たとえば、数値データの多くには算術的な解決メソッドが適しており、文字データの多くにはタイムスタンプによる解決メソッドが適しています。ただし、列グループの列を選択するときには、十分に考えた上で列をグループ化することが重要です。表内の複数の列で相互に整合性を保つ必要がある場合は、データ整合性を保証するためにそれらの列を同じ列グループに入れます。
たとえば、顧客表の郵便番号列で1つの解決メソッドを使用し、都市名列には別の解決メソッドを使用している場合、サイトは都市名に一致しない郵便番号に収束します。したがって、一般的には、競合解消方法が住所全体に対して適用されるように、1つの住所のすべての構成要素を1つの列グループに入れる必要があります。
デフォルトでは、各レプリケート表にシャドウ列グループがあります。表のシャドウ列グループには、特定の列グループ内にないすべての列が含まれます。表のシャドウ・グループには、競合解消方法を割り当てることはできません。したがって、列に競合解消方法を使用する必要がある場合は、列グループに必ずその列を入れてください。シャドウ列グループ内の列に関係する競合は検出されますが、このような競合を解消する競合解消方法は適用されません。
Oracleでは更新の競合の解消方法として8つのビルトインの方法を用意していますが、このうち最も一般的に実装されるのは、最新のタイムスタンプによる競合解消方法および上書きによる競合解消方法です。
この2つの競合解消方法は使いやすく、適切な環境ではデータ収束が保証されるため、最も一般的です。最新のタイムスタンプによる競合解消方法および上書きによる競合解消方法の詳細は、以降の2つの項で説明します。
|
注意: Oracleのビルトインの競合解消方法では、1つ以上のマテリアライズド・ビュー・サイトを持つシングル・マスター・サイト環境での収束を提供します。 |
最新のタイムスタンプによる方法を使用すると、更新発生時のタイムスタンプによって識別された最も新しい更新を原因とする競合を解消できます。
最新のタイムスタンプを使用した更新の競合解消方法の例を次に示します。
フェニックスの顧客が地元の営業担当員に電話をかけ、自分の住所情報を更新します。
電話を切った後で、営業担当員に伝えた郵便番号が間違っていたことに顧客が気付きます。
顧客は営業担当員に電話して正しい郵便番号を伝えようとしますが、担当者に電話がつながりません。
顧客はニューヨーク本社に電話します。フェニックス・サイトではなく、ニューヨーク・サイトで住所情報が正しく更新されます。
ニューヨーク本社とフェニックス営業所を接続するネットワークが一時的にダウンします。
ニューヨークとフェニックスを接続するネットワークが回復すると、同じ住所に対する2つの更新が認識され、各サイトでの競合が検出されます。
最新のタイムスタンプによる方法を使用して最新の更新内容が選択され、正しい郵便番号の住所が適用されます。
ターゲット環境 最新のタイムスタンプによる競合解消方法は、複数のマスター・サイトがあるレプリケーション環境でデータが収束するように機能します。タイムスタンプは常に増加しているので、この方法は複数のマスター・サイト間でのデータ収束を保証できる数少ない競合解消方法の1つです。また、任意の数のマテリアライズド・ビューがある環境でもうまく機能します。
サポート・メカニズム タイムスタンプによる方法を使用するには、レプリケート表内のDATE型の列を指定する必要があります。アプリケーションで列グループ内の列を更新するときは、ローカルSYSDATEで指定されたタイムスタンプ列の値も更新する必要があります。他のサイトから適用される変更については、タイムスタンプ値を発行元サイトのタイムスタンプ値に設定する必要があります。
タイムスタンプによる解消方法を使用する場合は、レプリケート・データを管理している異なるサイトの標準時間帯を慎重に考慮してください。たとえば、レプリケーション環境が複数の標準時間帯にわたっている場合、システムを使用するアプリケーションは、すべてのタイムスタンプをグリニッジ標準時(GMT)などの共通の標準時間帯に変換する必要があります。さらに、システム内の2つのサイトのシステム時計が正しく同期化されていない場合、タイムスタンプの比較が不正確になり、アプリケーション要件を満たすことができない可能性があります。
EARLIESTまたはLATESTタイムスタンプによる更新の競合の解消方法を使用する場合は、次の方法でタイムスタンプ列をメンテナンスできます。
各アプリケーションに、タイムスタンプを同期化する機能を組み込む方法
すべてのアプリケーションのタイムスタンプを自動的に同期化させる、レプリケート表のトリガーを作成する方法
クロックは、秒数を増加する値としてカウントします。タイムスタンプのメカニズムを正しく設計し、2つのサイトのタイムスタンプが同一である場合の予備の方法を作成した場合は、最新のタイムスタンプによる方法で収束が保証されます(最大値による方法と同様)。ただし、最も古いタイムスタンプによる方法では、複数のマスター・サイトの収束は保証されません。
最新のタイムスタンプによる方法の実装 Oracle Enterprise Managerのアドバンスト・レプリケーション・インタフェースを使用して最新のタイムスタンプによる競合解消方法を定義する方法については、アドバンスト・レプリケーション・インタフェースのオンライン・ヘルプを参照してください。
|
関連項目: レプリケーション・マネージメントAPIを使用してこのタイプの競合解消方法を定義する方法については、『Oracle Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス』を参照してください。 |
上書きによる方法では、接続先サイトの現在の値を、発行元サイトの新しい値で上書きするため、マスター・サイトが複数の場合のデータ収束は保証されません。この方法は、1つのマスター・サイトおよび複数のマテリアライズド・ビュー・サイトで使用するように設計されています。複数のマスター・サイトでこの方法を使用することもできますが、データ収束は保証されないので、なんらかのユーザー定義による通知機能とともに使用する必要があります。
たとえば、主に問合せに使用する1つのマスター・サイトがあり、すべての更新をそのマテリアライズド・ビュー・サイトで実行する場合は、廃棄による競合解消方法を選択できます。上書きによる方法は、次のような場合に役立ちます。
最大の目的がデータ収束である場合
マスター・サイトが1つしかない場合
更新の選択について、ビジネス・ルールが特にない場合
複数のマスター・サイトがある環境で、DEFERRORデータ・ディクショナリ・ビューでロギングした競合の解消をローカルのデータベース管理者にまかせる方法ではなく、データが正しく適用されるように確認する担当者への通知機能を使用する場合
ターゲット環境 上書きによる競合解消方法では、1つのマスター・サイトと任意の数のマテリアライズド・ビューから構成されるレプリケーション環境でのデータ収束が保証されます。この点を考慮すると、上書きによる競合解消方法は大規模デプロイメント環境で理想的な方法です。
競合が検出された場合、マテリアライズド・ビュー・サイトの値が使用されます。つまり、最後にリフレッシュが実行されたマテリアライズド・ビューに優先順位が与えられます。
サポート・メカニズム 上書きによる競合解消方法では、その他のサポート・メカニズムは必要ありません。
上書きによる方法の実装 Oracle Enterprise Managerのアドバンスト・レプリケーション・インタフェースを使用して上書きによる競合解消方法を定義する方法については、アドバンスト・レプリケーション・インタフェースのオンライン・ヘルプを参照してください。
|
関連項目: レプリケーション・マネージメントAPIを使用してこのタイプの競合解消方法を定義する方法については、『Oracle Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス』を参照してください。 |
最新のタイムスタンプまたは上書きによる競合解消方法を使用してもレプリケーション環境で発生した更新の競合を解消できない場合は、その他の6つのビルトインの競合解消方法を使用できます。
表5-3 更新の競合のその他の解消方法のデータ収束プロパティ
| 解消方法 | 複数のマスター・サイトでの収束 |
|---|---|
|
加算 |
収束します |
|
平均 |
収束しません |
|
廃棄 |
収束しません |
|
最も古いタイムスタンプ |
収束しません |
|
最大値 |
収束します(列値は常に増加する必要あり) |
|
最小値 |
収束します(列値は常に減少する必要あり) |
|
優先グループ |
収束します(順序付けられた更新値がある場合) |
|
サイト優先順位 |
収束しません |
加算による競合解消方法は、数値型の単一列のみで構成される列グループで機能します。競合が発生した場合、いずれか一方の値を選択するのではなく、2つの値の差が現在の値に加算されます。
加算による方法では、次の式に基づいて、発行元サイトの古い値と新しい値の差を、接続先サイトの現在の値に加算します。
current value = current value + (new value - old value)
この競合解消方法では、マスター・サイトやマテリアライズド・ビュー・サイトがいくつあっても値は収束します。
ターゲット環境 加算による競合解消方法では、最も適切なデータを選択するのではなくデータを収束するように設定されています。この方法は、預金の預入れや引出しが頻繁に行われてデータ競合が発生する可能性がある金融環境で便利であり、収支では、いずれか一方の値を選択するのではなく、データを収束させることが重要です。
サポート・メカニズム 加算による競合解消方法では、その他のサポート・メカニズムは必要ありません。
加算による方法の実装 Oracle Enterprise Managerのアドバンスト・レプリケーション・インタフェースを使用して加算による競合解消方法を定義する方法については、アドバンスト・レプリケーション・インタフェースのオンライン・ヘルプを参照してください。
|
関連項目: レプリケーション・マネージメントAPIを使用してこのタイプの競合解消方法を定義する方法については、『Oracle Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス』を参照してください。 |
平均による競合解消方法は、加算による方法の場合と同様に、数値型の単一列のみで構成される列グループで機能します。この方法では、現在の値に2つの値の差を追加するのではなく、現在の値と新しい値の平均を計算することで競合を解消します。
平均による競合解消方法では、発行元サイトの新しい列値と接続先サイトの現在の値の平均をとります。
current value = (current value + new value)/2
レプリケーション環境に複数のマスター・サイトが存在する場合、平均による方法では収束を保証できません。
ターゲット環境 平均による方法では、複数のマスター・サイトが存在するレプリケーション環境でのデータ収束を保証できないので、この方法は、1つのマスター・サイトと任意の数の更新可能マテリアライズド・ビューから構成される大規模デプロイメントの環境で実装するのが理想的です。
平均による方法は、いずれか一方の値を選択するのではなく、2つの値の平均をとる科学アプリケーションで使用すると便利です(たとえば、平均温度や平均体重を計算する場合などです)。
サポート・メカニズム 平均による競合解消方法では、その他のサポート・メカニズムは必要ありません。
平均による方法の実装 Oracle Enterprise Managerのアドバンスト・レプリケーション・インタフェースを使用して平均による競合解消方法を定義する方法については、アドバンスト・レプリケーション・インタフェースのオンライン・ヘルプを参照してください。
|
関連項目: レプリケーション・マネージメントAPIを使用してこのタイプの競合解消方法を定義する方法については、『Oracle Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス』を参照してください。 |
廃棄による競合解消方法では、発行元サイトの値は無視されるため、複数のマスター・サイトでのデータ収束が保証されることはありません。廃棄による方法では、発行元サイトからの新しい値を無視し、接続先サイトの現在の値を保持します。この方法は、1つのマスター・サイトと複数のマテリアライズド・ビュー・サイトの間で使用するか、なんらかのユーザー定義による通知機能とともに使用してください。
たとえば、1つのマスター・サイトとこのマスター・サイトに基づいた複数のマテリアライズド・ビューがあり、マテリアライズド・ビュー・サイトは主に問合せに使用され、更新はすべてマスター・サイトで実行される場合は、廃棄による競合解消方法を選択できます。廃棄による方法は、次のような場合に役立ちます。
最大の目的がデータ収束である場合
マスター・サイトが1つしかない場合
更新の選択について、ビジネス・ルールが特にない場合
複数のマスター・サイトがある環境で、DEFERRORビューでロギングした競合の解消をローカルのデータベース管理者にまかせる方法ではなく、データが正しく適用されるように確認する担当者への通知機能を使用する場合
ターゲット環境 廃棄による競合解消方法は、1つのマスター・サイトと任意の数のマテリアライズド・ビュー・サイトから構成される大規模デプロイメント・モデルに最も適しています。競合が検出された場合、マテリアライズド・ビュー・サイトの値は無視されます(つまり、最初にリフレッシュが実行されたマテリアライズド・ビューに優先順位が与えられます)。
サポート・メカニズム 廃棄による競合解消方法では、その他のサポート・メカニズムは必要ありません。
廃棄による方法の実装 Oracle Enterprise Managerのアドバンスト・レプリケーション・インタフェースを使用して廃棄による競合解消方法を定義する方法については、アドバンスト・レプリケーション・インタフェースのオンライン・ヘルプを参照してください。
|
関連項目: レプリケーション・マネージメントAPIを使用してこのタイプの競合解消方法を定義する方法については、『Oracle Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス』を参照してください。 |
最も古いタイムスタンプによる方法を使用すると、更新発生時のタイムスタンプによって識別された最も古い更新を原因とする競合を解消できます。
ターゲット環境 最も古いタイムスタンプによる競合解消方法は、1つのマスター・サイトと任意の数のマテリアライズド・ビューから構成されるレプリケーション環境でデータが収束するように機能します。タイムスタンプは常に増加しているので、最も古いタイムスタンプによる競合解消方法では、複数のマスター・サイトがあるレプリケーション環境のデータ収束は保証できません。この方法は、2つのトランザクションのタイムスタンプが同じである場合に備えて予備の競合解消方法を作成してある場合は、マテリアライズド・ビューの数にかかわらず機能します。
サポート・メカニズム タイムスタンプによる方法を使用するには、レプリケート表内のDATE型の列を指定する必要があります。アプリケーションで列グループ内の列を更新するときは、ローカルSYSDATEで指定されたタイムスタンプ列の値も更新する必要があります。他のサイトから適用される変更については、タイムスタンプ値を発行元サイトのタイムスタンプ値に設定する必要があります。「タイムスタンプの設定に関する問題」を確認してください。
最も古いタイムスタンプによる方法の実装 Oracle Enterprise Managerのアドバンスト・レプリケーション・インタフェースを使用して最も古いタイムスタンプによる競合解消方法を定義する方法については、アドバンスト・レプリケーション・インタフェースのオンライン・ヘルプを参照してください。
|
関連項目: レプリケーション・マネージメントAPIを使用してこのタイプの競合解消方法を定義する方法については、『Oracle Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス』を参照してください。 |
アドバンスト・レプリケーションによって列グループに競合が検出され、最大値による競合解消方法がコールされると、列グループ内の指定した列について、発行元サイトの新しい値と接続先サイトの現在の値が比較されます。最大値による競合解消方法を選択する場合は、列を指定する必要があります。
指定した列の新しい値が現在の値より大きい場合に、その行のその他のエラーがすべて解消されていると、発行元サイトの列グループの値が接続先サイトに適用されます。指定した列の新しい値が現在の値より小さい場合は、列グループの現在の値を変更しないかぎり競合は解消されます。
|
注意: 指定した列の2つの値が同じ場合(たとえば、指定した列が競合を発生させた列ではない場合)、競合は解消されず、列グループの列の値は変更されません。この場合は、予備の競合解消方法を指定してください。 |
列グループ内の列のデータ型に制約はありません。複数のマスター・サイトのデータ収束が保証されるのは、列の値が常に増加している場合のみです。
|
注意: 競合解消が制約によって妨げられる可能性があるため、CHECK制約を使用して常に増加する値を制限しないでください。 |
ターゲット環境 最大値による競合解消方法を定義済で、競合解消に使用するターゲット列の値がすべてのサイトで常に増加している場合は、マスター・サイトやマテリアライズド・ビュー・サイトの数にかかわらずデータ収束は保証されます。
サポート・メカニズム 最大値による競合解消方法では、その他のサポート・メカニズムは必要ありません。
最大値による方法の実装 Oracle Enterprise Managerのアドバンスト・レプリケーション・インタフェースを使用して最大値による競合解消方法を定義する方法については、アドバンスト・レプリケーション・インタフェースのオンライン・ヘルプを参照してください。
|
関連項目: レプリケーション・マネージメントAPIを使用してこのタイプの競合解消方法を定義する方法については、『Oracle Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス』を参照してください。 |
アドバンスト・レプリケーションによって列グループに競合が検出され、最小値による競合解消方法がコールされると、列グループ内の指定した列について、発行元サイトの新しい値と接続先サイトの現在の値が比較されます。最小値による競合解消方法を選択する場合は、列を指定する必要があります。
指定した列の新しい値が現在の値より小さい場合に、その行のその他のエラーがすべて解消されていると、発行元サイトの列グループの値が接続先サイトに適用されます。指定した列の新しい値が現在の値より大きい場合は、列グループの現在の値を変更しないかぎり競合は解消されます。
|
注意: 指定した列の2つの値が同じ場合(たとえば、指定した列が競合を発生させた列ではない場合)、競合は解消されず、列グループの列の値は変更されません。この場合は、予備の競合解消方法を指定してください。 |
列グループ内の列のデータ型に制約はありません。複数のマスター・サイトのデータ収束が保証されるのは、列の値が常に減少している場合のみです。
|
注意: 競合解消が制約によって妨げられる可能性があるため、CHECK制約を使用して常に減少する値を制限しないでください。 |
ターゲット環境 最小値による競合解消方法を定義済で、競合解消に使用するターゲット列の値がすべてのサイトで常に減少している場合は、マスター・サイトやマテリアライズド・ビュー・サイトの数にかかわらずデータ収束は保証されます。
サポート・メカニズム 最小値による競合解消方法では、その他のサポート・メカニズムは必要ありません。
最小値による方法の実装 Oracle Enterprise Managerのアドバンスト・レプリケーション・インタフェースを使用して最小値による競合解消方法を定義する方法については、アドバンスト・レプリケーション・インタフェースのオンライン・ヘルプを参照してください。
|
関連項目: レプリケーション・マネージメントAPIを使用して最小値による競合解消方法と最大値による競合解消方法を定義する方法については、『Oracle Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス』を参照してください。 |
優先グループを使用すると、特定の列に格納される可能性がある各値に優先順位レベルを割り当てることができます。競合が検出されると、「優先順位」列の値が低い表が、より高い優先順位値を持つ表のデータによって更新されます。したがって、値が大きいことは優先順位が高いことを意味します。
優先グループを使用しており、優先順位列の値が常に増加している場合は、複数のマスター・サイトでの収束が保証されます。つまり、優先順位列の値は、イベントの順序、たとえば、ordered(注文)、shipped(出荷)、billed(請求)に対応します。
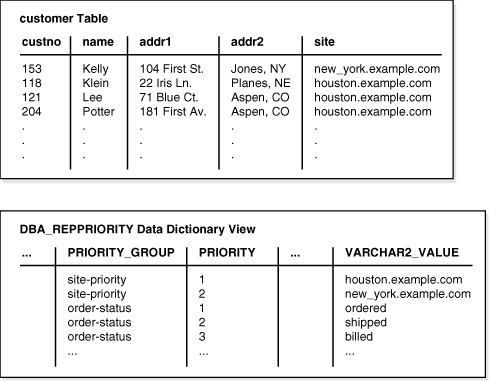
図5-2に示すように、各優先グループのメンバーに割り当てられている優先順位レベル(「優先順位」列に格納される値)はDBA_REPPRIORITYビューに表示されます。「優先順位」列に格納される可能性があるすべての値に対して、優先順位を指定する必要があります。
現行の位置で定義されたすべての優先グループの値は、DBA_REPPRIORITYビューに表示されます。図5-2の例では、site-priorityとorder-statusという2つの優先グループがあります。customer表は、site-priority優先グループを使用しています。この例のorder-status優先グループでは、billed(優先順位値=3)はshipped (優先順位値=2)よりも優先順位が高く、shippedはordered(優先順位値=1)よりも優先順位が高くなっています。
Oracle Enterprise Managerのアドバンスト・レプリケーション・インタフェースを使用して優先グループによる更新の競合解消方法を選択するには、その前に表内に優先順位列を指定する必要があります。
ターゲット環境 優先グループによる競合解消方法は、ワークフロー環境用に設定されたレプリケーション環境で役に立ちます。たとえば、order-statusがshipping状態になると、order entry部門による更新は常に上書きされます。
サポート・メカニズム ターゲット列に含まれる値の優先順位を定義する必要があります。この優先順位を定義するのは、指定された列値の優先順位に基づいて競合を解消するためです。優先順位の定義は、優先グループに格納されます。
優先グループによる方法の実装 Enterprise Managerのアドバンスト・レプリケーション・インタフェースを使用して優先グループによる競合解消方法を定義する方法については、アドバンスト・レプリケーション・インタフェースのオンライン・ヘルプを参照してください。
|
関連項目: レプリケーション・マネージメントAPIを使用してこのタイプの競合解消方法を定義する方法については、『Oracle Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス』を参照してください。 |
サイト優先順位は、特殊な種類の優先グループです。サイト優先順位を使用する場合、指定する優先順位列は、更新が発行されたサイトのグローバル・データベース名に自動的に更新されます。各データベース・サイトに割り当てられた優先順位レベルは、DBA_REPPRIORITYビューに表示されます。
あるサイトが最も正確な情報を持っている可能性が高いとみなされる場合、サイト優先順位が役に立つことがあります。たとえば、図5-2では、new_york.example.comサイト(優先順位値 = 2)は本社で、houston.example.comサイト(優先順位値 = 1)は営業所にある更新可能マテリアライズド・ビューです。したがって、本社オフィスは、各顧客のクレジット限度額に関する最も正確な情報を持っている可能性が営業所よりも高いと考えられます。
|
注意: DBA_REPPRIORITYビューの優先グループ列には、site-priority優先グループおよびorder-status優先グループの両方が表示されます。 |
サイト優先順位による方法のみを使用する場合は、複数のマスター・サイトでのデータ収束は保証されませんが、サイト優先順位はマルチマスター環境に適した予備の競合解消方法です。特に最新のタイムスタンプによる方法で2つのタイムスタンプがまったく同じである場合の予備の方法として役立ちます。
優先グループの場合と同様、Oracle Enterprise Managerのアドバンスト・レプリケーション・インタフェースを使用して列グループに対してサイト優先順位による競合解消方法を選択する前に、いくつかの準備を済ませておく必要があります。
ターゲット環境 優先グループと同様に、サイト優先順位による競合解消方法は、ワークフロー環境で実装されるのが一般的です。また、サイト優先順位による競合解消方法を大規模デプロイメントの環境(1つのマスター・サイトおよび任意の数のマテリアライズド・ビュー・サイトから構成される環境)で使用すると、データ収束を保証できます。
サイト優先順位による競合解消方法は、マルチマスター環境で主要な競合解消方法が失敗した場合の予備の方法としても適しています。
サポート・メカニズム 行が更新されたときにサイト情報を格納するための列を指定する必要があります。また、行が更新または挿入されたときにこのサイト列に更新中のサイトのグローバル名を移入するトリガーも作成する必要があります。このトリガーの例は、『Oracle Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス』を参照してください。
レプリケーション環境に関係する各サイトの優先順位も定義する必要があります。この優先順位を定義するのは、更新または挿入を実行したサイトの優先順位に基づいて競合を解消するためです。サイト優先順位の定義は、優先グループに格納されます。
サイト優先順位による方法の実装 Oracle Enterprise Managerのアドバンスト・レプリケーション・インタフェースを使用してサイト優先順位による競合解消方法を定義する方法については、アドバンスト・レプリケーション・インタフェースのオンライン・ヘルプを参照してください。
|
関連項目: レプリケーション・マネージメントAPIを使用してこのタイプの競合解消方法を定義する方法については、『Oracle Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス』を参照してください。 |
Oracleには、一意性競合を解消するビルトインの方法が3つ用意されています。
発行元サイトのグローバル・サイト名を、発行元サイトの列値に追加する方法
生成された順序番号を、発行元サイトの列値に追加する方法
発行元サイトの行値を廃棄する方法
次の項では、一意性競合解消方法について、詳しく説明します。
|
注意: Oracleのビルトインの一意性競合の解消方法では、実際にはレプリケーション環境のデータは収束しません(これらの方法は、制約違反を解決するテクニックのみを提供します)。Oracleの一意性競合の解消方法を使用する場合には、一意性競合の発生を知らせる通知メカニズムを同時に使用して、必要に応じて手動でレプリケート・データを収束する必要があります。 |
|
注意: 列に対する一意性競合の解消方法を追加するには、その列に対する一意索引の名前が、一意制約または主キー制約の名前と同じである必要があります。 |
サイト名の追加による競合解消方法では、トランザクションの発生元サイトのグローバル・データベース名が、dup_val_on_index例外を生成しているレプリケートされた列値に追加されます。この方法を使用すると一意の整合性制約に違反せずに列を挿入または更新できますが、複数のマスター・サイト間での収束は提供されません。そのために発生した矛盾は手動で解決する必要があるため、この方法は、なんらかの通知機能とともに使用することを想定しています。
|
注意: サイト名の追加および順序の追加は、いずれもキャラクタ列のみに使用できます。 |
サイト名の追加による解消方法は、データの完全な正確さよりもデータの可用性の方が重要な場合に役立ちます。データがレプリケートされた後ですぐに使用可能な状態にするには、次のようにします。
サイト名の追加による方法を選択します。
競合をロギングするのではなく、通知スキームを使用して、適切な担当者に重複を解消するように警告します。
サイト名の追加による方法では、一意性競合が発生すると、トランザクションの発行元サイトのグローバル・データベース名が、レプリケートされた列値に追加されます。名前は最初のピリオド(.)までが追加されます。たとえば、houston.example.comはhoustonになります。
順序の追加による競合解消方法では、生成された順序番号が、dup_val_on_index例外を生成している列値に追加されます。この方法を使用すると一意の整合性制約に違反せずに列を挿入または更新できますが、複数のマスター・サイト間での収束は提供されません。そのために発生した矛盾は手動で解決する必要があるため、この方法は、なんらかの通知機能とともに使用することを想定しています。
|
注意: サイト名の追加および順序の追加は、いずれもキャラクタ列のみに使用できます。 |
サイト名の追加による解消方法は、データの完全な正確さよりもデータの可用性の方が重要な場合に役立ちます。データがレプリケートされた後ですぐに使用可能な状態にするには、次のようにします。
順序の追加による方法を選択します。
競合をロギングするのではなく、通知スキームを使用して、適切な担当者に重複を解消するように警告します。
順序の追加による方法では、生成された順序番号が列値に追加されます。列値は必要に応じて切り捨てられます。列値の生成された部分が列の長さを超えた場合、この競合解消方法ではエラーは解決されません。
Oracleでは、削除の競合を解消するビルトインの方法は提供していません。「削除の競合の回避」で説明されているように、データベースとフロントエンド・アプリケーションは削除の競合を回避するように設計する必要があります。これには、行に削除のマークを付け、プロシージャ・レプリケーションを使用して、論理的に削除された行を定期的にパージします。
|
関連項目:
|
行の更新の競合を検出および解消するには、伝播サイトから受信サイトに新旧の行に関するデータを送信する必要があります。環境によって、更新の競合の検出および解消をサポートするために伝播されるデータの量は異なります。
DBMS_REPCAT.SEND_OLD_VALUESプロシージャおよびDBMS_REPCAT.COMPARE_OLD_VALUESプロシージャを使用することによって、競合の検出および解消に必要な場合にかぎり、古い値が送信され、データ伝播を削減できる場合があります。たとえば、タイムスタンプ列が更新されると必ず列が更新されることが保証される場合、最新のタイムスタンプによる競合の検出および解消方法には、列グループ内の非キー列および非タイムスタンプ列の古い値は必要ありません。
|
提案: LOBデータ型をレプリケートしていて、これらの列で競合が発生しないと考えられる場合は、古い値の伝播をさらに最小化することが特に有効です。 |
|
注意: 予想される競合を検出および解消できるように、適切な古い値を伝播する必要があります。ユーザー指定の競合解消プロシージャでは、送信される古い列値NULLを適切に処理できる必要があります。データ伝播をさらに削減するためにSEND_OLD_VALUESプロシージャおよびCOMPARE_OLD_VALUESプロシージャを使用すると、予期しない競合に対する保護が低下します。 |
データ伝播をさらに削減するには、次のプロシージャを実行します。
DBMS_REPCAT.SEND_OLD_VALUES(
sname IN VARCHAR2,
oname IN VARCHAR2,
{ column_list IN VARCHAR2,
| column_table IN DBMS_UTILITY.VARCHAR2s | DBMS_UTILITY.LNAME_ARRAY,}
operation IN VARCHAR2 := 'UPDATE',
send IN BOOLEAN := TRUE );
DBMS_REPCAT.COMPARE_OLD_VALUES(
sname IN VARCHAR2,
oname IN VARCHAR2,
{ column_list IN VARCHAR2,
| column_table IN DBMS_UTILITY.VARCHAR2s | DBMS_UTILITY.LNAME_ARRAY,}
operation IN VARCHAR2 := 'UPDATE',
compare IN BOOLEAN := TRUE );
これらのプロシージャを実行した後で、変更を有効にするために、DBMS_REPCAT.GENERATE_REPLICATION_SUPPORTプロシージャでmin_communicationをTRUEに設定してレプリケーション・サポートを生成する必要があります。
|
注意: operationパラメータを使用すると、行が削除されたときまたは非キー列が更新されたとき(あるいはその両方)に、非キー列の古い値を送信するかどうかを決定できます。古い値を送信しない場合、古い値のかわりにNULLが送信され、更新または削除が適用されるときに古い値とターゲット・サイドの列の現在の値が等しいとみなされます。 |
古い列値に対して指定した動作は、DBA_REPCOLUMNデータ・ディクショナリ・ビューの2つの列、COMPARE_OLD_ON_DELETE(YまたはN)およびCOMPARE_OLD_ON_UPDATE(YまたはN)に公開されます。
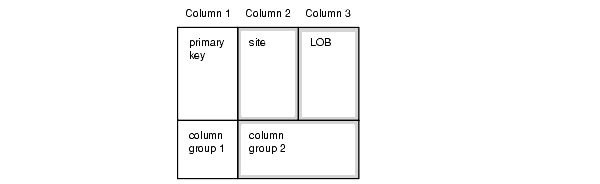
次の例では、これらのプロシージャを使用してデータ伝播をさらに削減する方法を示します。列が3つあるrsmith.reportsという表を考えてみます。列1は主キーであり、独自の列グループ(列グループ1)を構成します。列2および列3は、2番目の列グループ(列グループ2)に属します。
2番目の列グループの競合解消方針は、サイト優先順位です。列2は、サイト名を含むVARCHAR2型の列です。列3は、LOB列です。LOBを更新するときは必ず、更新が行われたサイトのグローバル名で列2も更新する必要があります。LOBに対するピース単位の更新にはトリガーがないため、LOBに対してピース単位の更新を行う場合は常に列2を明示的に更新する必要があります。
DBMS_REPCAT.GENERATE_REPLICATION_SUPPORTプロシージャでmin_communicationをTRUEに設定してrsmith.reportsのレプリケーション・サポートを生成し、次にUPDATE文を使用して列2(サイト名)と列3(LOB)を変更するとします。サイト名の新しい値とLOBの新しい値が更新されているので、遅延リモート・プロシージャ・コール(RPC)にはこれらの値が含まれます。遅延RPCには、主キー(列1)の古い値、サイト名(列2)の古い値およびLOB(列3)の古い値も含まれます。
|
注意: 競合の検出および解消には、LOBの古い値は必要ありません。競合の検出と解消に必要なのは、列C2(サイト名)のみです。LOBの古い値を送信すると、伝播時間が大幅に増加する可能性があります。 |
列C2または列C3が更新されたときにLOBの古い値を伝播しない場合は、次のコールを実行します。
BEGIN
DBMS_REPCAT.SEND_OLD_VALUES(
sname => 'rsmith',
oname => 'reports',
column_list => 'c3',
operation => 'UPDATE',
send => FALSE );
END;
/
BEGIN
DBMS_REPCAT.COMPARE_OLD_VALUES(
sname => 'rsmith',
oname => 'reports',
column_list => 'c3',
operation => 'UPDATE',
compare => FALSE);
END;
/
変更を有効にするには、DBMS_REPCAT.GENERATE_REPLICATION_SUPPORTプロシージャでmin_communicationをTRUEに設定してrsmith.reportsのレプリケーション・サポートを生成する必要があります。続いてUPDATE文を使用して列2(サイト名)と列3(LOB)を変更するとします。遅延RPCには、主キー(列1)の古い値、サイト名(列2)の古い値と新しい値、およびLOB(列3)の新しい値が含まれます。遅延RPCは、主キーの新しい値とLOBの古い値についてはNULLを含みます。
|
注意: Oracleの競合解消では、LOBのピース単位の更新はサポートしていません。 |
リーフ属性がレプリケーション・キー列でない場合は、古い値を送信および比較するときに、列オブジェクトのリーフ属性を指定できます。たとえば、次のcust_address_typオブジェクト型を作成するとします。
CREATE TYPE cust_address_typ AS OBJECT
(street_address VARCHAR2(40),
postal_code VARCHAR2(10),
city VARCHAR2(30),
state_province VARCHAR2(10),
country_id CHAR(2));
/
この型を列オブジェクトとして使用し、customers表を作成します。
CREATE TABLE customers
(customer_id NUMBER(6),
cust_first_name VARCHAR2(20),
cust_last_name VARCHAR2(20),
cust_address cust_address_typ,
phone_numbers phone_list_typ);
customers表のcust_address_typ型のstreet_address属性の古い値を送信および比較する場合は、次のプロシージャを使用して、属性値を送信および比較するように指定します。
BEGIN
DBMS_REPCAT.SEND_OLD_VALUES(
sname => 'oe',
oname => 'customers',
column_list => 'cust_address.street_address', -- object attribute
operation => 'UPDATE',
send => TRUE );
END;
/
BEGIN
DBMS_REPCAT.COMPARE_OLD_VALUES(
sname => 'oe',
oname => 'customers',
column_list => 'cust_address.street_address', -- object attribute
operation => 'UPDATE',
compare => TRUE);
END;
/
|
注意: 1つの列オブジェクトにオブジェクト属性が複数レベルある場合、column_listパラメータに指定できるのは最後の属性(またはリーフ属性)のみです。中間の属性は指定できません。 |
列オブジェクト全体を送信および比較することも指定できます。たとえば、次のプロシージャでは、cust_address列オブジェクト全体を指定しています。
BEGIN
DBMS_REPCAT.SEND_OLD_VALUES(
sname => 'oe',
oname => 'customers',
column_list => 'cust_address', -- entire column object
operation => 'UPDATE',
send => TRUE );
END;
/
BEGIN
DBMS_REPCAT.COMPARE_OLD_VALUES(
sname => 'oe',
oname => 'customers',
column_list => 'cust_address', -- entire column object
operation => 'UPDATE',
compare => TRUE);
END;
/
|
関連項目: DBMS_REPCAT.SEND_OLD_VALUESプロシージャおよびDBMS_REPCAT.COMPARE_OLD_VALUESプロシージャの詳細は、『Oracle Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス』を参照してください。 |