| Oracle® TimesTen Application-Tier Database Cache概要 11gリリース2 (11.2.2) B66721-03 |
|


 前 |
 次 |
TimesTenおよびTimesTen Cacheでは、次の仕組みを使用することによって、データの可用性、永続性および整合性を保証しています。
TimesTenまたはTimesTen Cacheのトランザクション・ログは次の目的で使用されます。
システム障害が発生した場合に、トランザクションを再実行する。
ロールバックされるトランザクションを取り消す。
他のTimesTenデータベースまたはTimesTen Cacheデータベースに変更をレプリケートする。
Oracle Databaseに変更をレプリケートする。
アプリケーションでXLAインタフェースを介した表への変更を監視できるようにする。
トランザクション・ログはディスク上のファイルに保存されます。トランザクション・ログの末尾はインメモリー・バッファに存在します。
TimesTenおよびTimesTen Cacheでは、永続コミットごと、チェックポイントごとおよび実装によって定義されているタイミングで、インメモリーのログ・バッファの内容がディスク上のトランザクション・ログ・ファイルに書き込まれます。障害の発生時にコミット済のトランザクションの損失が許容されないアプリケーションでは、読取り専用でないすべてのトランザクションに対して、永続コミットをリクエストする必要があります。この場合、データベースに接続するときに、DurableCommits一般接続属性を1に設定します。
最近コミットした一部のトランザクションの損失が許容されるアプリケーションでは、トランザクションの一部または全部を非永続的にコミットすることによって、パフォーマンスを大幅に向上させることができます。この場合、DurableCommits一般接続属性を0(デフォルト)に設定し、通常、定期的な時間間隔またはアプリケーション・ロジックの特定の時点で明示的に永続コミットをリクエストします。永続コミットをリクエストするには、アプリケーションでttDurableCommit組込みプロシージャをコールします。
トランザクション・ログ・ファイルは、TimesTenまたはTimesTen Cacheで消去可能と宣言されるまで保持されます。トランザクション・ログ・ファイルは、次のすべての処理が完了するまで消去できません。
トランザクション・ログ・ファイル(または前のトランザクション・ログ・ファイル)にログ・レコードを書き込むすべてのトランザクションが、コミットまたはロールバックされる。
トランザクション・ログ・ファイルに記録されたすべての変更が、チェックポイント・ファイルに書き込まれる。
トランザクション・ログ・ファイルに記録されたすべての変更が、レプリケートされる(レプリケーションが使用されている場合)。
トランザクション・ログ・ファイルに記録されたすべての変更が、Oracle Databaseに伝播される(TimesTen Cacheの動作がこのように構成されている場合)。
トランザクション・ログ・ファイルに記録されたすべての変更が、XLAアプリケーションにレポートされる(XLAが使用されている場合)。
ODBCでは、各文の後にコミットを強制する 自動コミット・モードが提供されます。デフォルトでは自動コミットが有効になり、文の実行に成功した直後に暗黙的コミットが発行されます。コミットを意図的に行うように自動コミットを無効にすることをお薦めします。
TimesTenでは、デフォルトで、データ定義言語(DDL)文の前後に暗黙的コミットが発行されます。この動作は、DDLCommitBehavior一般接続属性によって制御されます。この属性を使用すると、DDL文を現在のトランザクションの一部として実行し、トランザクションの残りの部分とともにコミットまたはロールバックできます。
チェックポイントは、データベースのスナップショットを保持するために使用されます。システム障害が発生した場合、TimesTenおよびTimesTen Cacheでは、トランザクション・ログ・ファイルとともにチェックポイント・ファイルを使用して、トランザクションの一貫性が保たれていた最後の状態にデータベースをリストアできます。
最後のチェックポイント処理以降に変更されたデータのみが、チェックポイント・ファイルに書き込まれます。チェックポイント処理では、最後のチェックポイント以降に変更されたブロックのデータベースをスキャンします。次に、それらの変更についてチェックポイント・ファイルを更新し、不要なトランザクション・ログ・ファイルを削除します。
TimesTenおよびTimesTen Cacheでは、次の2種類のチェックポイントが提供されます。
TimesTenおよびTimesTen Cacheでは、非ブロッキング・チェックポイントが自動的に作成されます。
TimesTenおよびTimesTen Cacheでは、非ブロッキング・チェックポイントがバックグラウンドで自動的に開始されます。非ブロッキング・チェックポイントはファジー・チェックポイントと呼ばれることもあります。このチェックポイントの頻度はアプリケーションで調整できます。非ブロッキング・チェックポイントでは、データベースのロックが必要ないため、チェックポイントの処理中に、複数のアプリケーションが同じデータベースでトランザクションを非同期にコミットまたはロールバックできます。
トランザクション一貫性チェックポイントを構成するために、アプリケーションでttCkptBlocking組込みプロシージャをコールして、ブロッキング・チェックポイントを開始できます。ブロッキング・チェックポイントの処理中、他の新しいトランザクションはチェックポイント・トランザクションの後のキューに入れられます。長時間実行するトランザクションがあると、他の多数のトランザクションを待機させることとなります。チェックポイントの記録にはリカバリに必要な情報が含まれているため、ブロッキング・チェックポイントからのリカバリにログは必要ありません。
システム障害やプロセス障害によって、データベースが無効になったり破損したりすると、データベースへのすべての接続が無効になります。アプリケーションが障害のあったデータベースに再接続すると、サブデーモンがデータベースに新しいメモリー・セグメントを割り当て、チェックポイント・ファイルおよびトランザクション・ログ・ファイルからそのデータをリカバリします。
リカバリ中に、最新のチェックポイント・ファイルがメモリーに読み込まれます。最後のチェックポイント以降にコミットされ、ログ・レコードがディスク上に存在するすべてのトランザクションが、適切なトランザクション・ログ・ファイルからロールフォワードされます。ただし、このようなトランザクションには、永続的にコミットされたすべてのトランザクションのみでなく、ログ・レコードが/インメモリー・ログ・バッファからエージ・アウトされたすべてのトランザクションも含まれることに注意してください。コミットされていないトランザクション、またはロールバックされたトランザクションはリカバリされません。
障害発生時も絶えずTimesTenデータにアクセスする必要のあるアプリケーションについては、「レプリケーション」を参照してください。
レプリケーションの重要な目的は、パフォーマンスへの影響を最小限に抑えて、アプリケーションのデータの可用性を高めることにあります。障害リカバリにおける役割の他に、レプリケーションは、アプリケーション・ワークロードを複数のデータベースに分散してパフォーマンスを最大化させたり、オンライン・アップグレードとメンテナンスを容易にする場合にも有効です。
レプリケーションとは、データをマスター・データベースからサブスクライバ・データベースにコピーするプロセスのことです。マスターおよびサブスクライバの各データベースのレプリケーションは、TCP/IPストリーム・ソケットを介して通信するレプリケーション・エージェントによって制御されます。マスター・データベースのレプリケーション・エージェントは、マスター・データベースのトランザクション・ログからレコードを読み取ります。レプリケートされた要素への変更をサブスクライバ・データベースのレプリケーション・エージェントに転送します。その後、サブスクライバ・データベースのレプリケーション・エージェントが、それらの更新をサブスクライバ・データベースに適用します。マスター・エージェントは、更新転送時にサブスクライバ・エージェントが稼働していない場合、サブスクライバで適用可能になるまでそれらの更新をトランザクション・ログに保持します。
データベースの作成時にパラレル・レプリケーションを構成することで、レプリケーションのスループットを向上できます。パラレル・レプリケーションはデフォルトで有効になっています。サブスクライバに更新を適用するためのスレッド数を構成します。更新はコミット順に転送されます。
TimesTenで可用性を最大限に高めるには、アクティブ・スタンバイ・ペア構成をお薦めします。これは、TimesTen Cacheのレプリケートに使用できる唯一のレプリケーション構成です。
この項の後半の内容は次のとおりです。
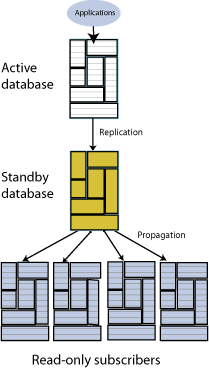
アクティブ・スタンバイ・ペアには、アクティブ・データベース、スタンバイ・データベース、オプションの読取り専用サブスクライバ・データベース、データベースを構成する表およびキャッシュ・グループが含まれます。図6-1に、アクティブ・スタンバイ・ペアを示します。
アクティブ・スタンバイ・ペアでは、2つのデータベースがマスターとして定義されます。1つは、アクティブ・データベースで、もう1つはスタンバイ・データベースです。アクティブ・データベースは直接更新されます。スタンバイ・データベースは、直接更新できません。これは、アクティブ・データベースからの更新を受信し、それらの変更を読取り専用サブスクライバに伝播します。この構成では、スタンバイ・データベースが読取り専用サブスクライバより常に先行し、アクティブ・データベースで障害が発生した場合は、スタンバイ・データベースに即時にフェイルオーバーできます。
1つのマスター・データベースのみが、特定の時間にアクティブ・データベースとして機能できます。アクティブ・データベースで障害が発生した場合は、障害が発生したデータベースをスタンバイ・データベースとしてリカバリする前に、スタンバイ・データベースのロールをアクティブに変更する必要があります。新しいスタンバイ・データベースで、レプリケーション・エージェントを起動する必要があります。
スタンバイ・データベースで障害が発生した場合は、アクティブ・データベースから読取り専用サブスクライバに変更を直接レプリケートします。スタンバイ・データベースは、リカバリ後、アクティブ・データベースに接続し、スタンバイ・データベースの停止またはリカバリ中に読取り専用サブスクライバに送信された更新を受信します。アクティブ・データベースとスタンバイ・データベースで同期が取られている場合、スタンバイ・データベースは、サブスクライバへの変更の伝播を再開します。
アクティブ・スタンバイ・レプリケーションをTimesTen Cacheとともに使用すると、層をまたいだ高可用性を実現できます。アクティブ・スタンバイ・レプリケーションは、読取り専用キャッシュ・グループおよび非同期のWRITETHROUGHキャッシュ・グループの両方で使用可能です。読取り専用キャッシュ・グループとともに使用する場合、更新はOracle Databaseからアクティブ・データベースに送信されます。つまり、この構成のOracle Databaseは、アプリケーションの役割を果たします。同期のWRITETHROUGHキャッシュ・グループとともに使用する場合、スタンバイ・データベースはアクティブ・データベースから受信した更新をOracle Databaseに伝播します。この場合、Oracle Databaseは読取り専用サブスクライバの役割を果たします。
これらのタイプのキャッシュ・グループのいずれかをレプリケートするアクティブ・スタンバイ・ペアでは、フェイルオーバーを実行できるため、データ損失を最小限に抑えて自動的にリカバリを実行できます。『Oracle TimesTen In-Memory Database開発者および管理者ガイド』のキャッシュ・グループを使用するアクティブ・スタンバイ・ペアに関する説明を参照してください。
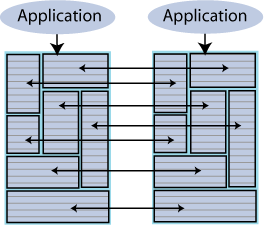
TimesTenレプリケーション・アーキテクチャには、パフォーマンスおよび可用性のバランスをとることのできる十分な柔軟性が備えられています。通常、マスターから1つ以上のサブスクライバへの単方向、またはマスターとサブスクライバの両方として機能する2つ以上のデータベース間の双方向になるよう、クラシック・レプリケーションを構成できます。
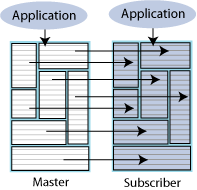
図6-2に、単方向レプリケーション・スキームを示します。アプリケーションが両方のホストに構成され、マスター・ホストで障害が発生した場合にはサブスクライバが処理を引き継ぎます。マスター・ノードが稼働中の場合、アプリケーションからマスター・データベースへの更新がサブスクライバ・データベースにレプリケートされます。サブスクライバ・ホスト上のアプリケーションはサブスクライバ・データベースに対する更新は実行しませんが、サブスクライバ・データベースからの読取りを行うことがあります。マスターで障害が発生した場合、サブスクライバ・ホスト上のアプリケーションは更新機能を引き継ぎ、サブスクライバ・データベースの更新を開始します。
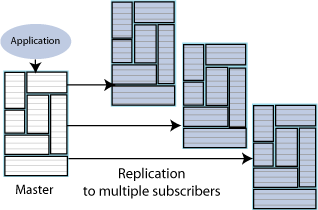
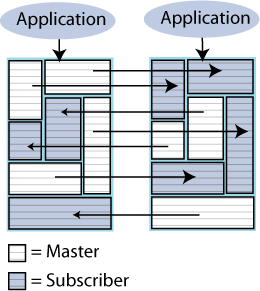
レプリケーションは、更新を1つのマスター・データベースから多くのサブスクライバ・データベースにコピーする場合にも使用できます。図6-3に、複数のサブスクライバが存在するレプリケーション・スキームを示します。
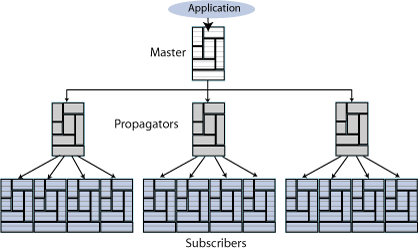
図6-4に、伝播の構成を示します。1つのマスターによって、3つのサブスクライバに更新が伝播されます。これらのサブスクライバは、さらに他のサブスクライバへ更新を伝播するマスターでもあります。
TimesTenレプリケーションは、デフォルトでは非同期メカニズムになります。非同期レプリケーションを使用する場合、アプリケーションは、マスター・データベースを更新すると、サブスクライバがその更新を受信するまで待機せずに処理を続行します。マスターおよびサブスクライバのデータベースには、サブスクライバが更新を正常に受信およびコミットしたことを確認するための内部メカニズムがあります。これらのメカニズムは、更新がサブスクライバで1回のみ適用されることを保証しますが、アプリケーションでは透過的です。
非同期レプリケーションは最高のパフォーマンスを実現しますが、アプリケーションは、サブスクライバ上のレプリケートされた要素の受信プロセスと完全に切り離されます。また、TimesTenでは、レプリケートされたデータがマスター・データベースとサブスクライバ・データベース間で一貫していることをより高いレベルで保証する必要があるアプリケーションに、2つのRETURNサービス・オプションを提供します。
RETURN RECEIPTサービスでは、サブスクライバ・レプリケーション・エージェントが更新を受信したことがレプリケーションで確認されるまでアプリケーションをブロックすることによって、アプリケーションをレプリケーション・メカニズムと同期化します。
RETURN TWOSAFEサービスでは、サブスクライバが更新を受信およびコミットしたことがレプリケーションで確認されるまでアプリケーションをブロックすることによって、完全な同期レプリケーションが可能です。
|
注意: RETURN TWOSAFEサービスを分散ワークロード構成で使用しないでください。デッドロックが発生する可能性があります。 |
RETURNサービスを使用するアプリケーションでは、パフォーマンスは低下しますが、マスター・データベースとサブスクライバ・データベース間でのより高いレベルの一貫性が保証され、トランザクションが失われる可能性が軽減されます。このアプリケーションでは、マスターで障害が発生した場合でも、マスターでコミットされたトランザクションがサブスクライバ・データベースに保持されることが高度なレベルで保証されます。RETURN RECEIPTのレプリケーションでは、トランザクションが失われる可能性を低くすることによって、RETURN TWOSAFEのレプリケーションよりパフォーマンスへの影響が小さくなっています。
パフォーマンスに及ぼす影響を最小限に抑え、アプリケーションのデータの可用性を高めるには、できるかぎりシームレスに、障害のあったデータベースから、保持されているそのバックアップにアプリケーションを移動することが必要になります。
Oracle Clusterwareを使用すると、アクティブ・スタンバイ・ペアを使用するシステムにおける障害を自動的に管理できます。その他の種類のレプリケーション・スキームを管理するには、カスタムまたはサード・パーティのクラスタ・マネージャを使用します。クラスタ・マネージャは障害を検出し、障害が発生したデータベースからスタンバイ・データベースまたはサブスクライバにユーザーまたはアプリケーションをリダイレクトし、障害が発生したデータベースのリカバリを管理します。クラスタ・マネージャまたは管理者は、TimesTenのユーティリティおよび関数を使用して、障害の発生していないデータベースを複製し、障害の発生したデータベースをリカバリできます。
通常、サブスクライバの障害は、マスター・データベースに接続したアプリケーションに影響を及ぼすことはなく、ユーザー・サービスを中断させることなくリカバリできます。マスター・データベースで障害が発生した場合、サービスを中断させずに、または最小限の中断でサービスを継続するために、クラスタ・マネージャはアプリケーション負荷をスタンバイ・データベースまたはサブスクライバにリダイレクトする必要があります。