| Oracle® Beehive Administrator's Guide Release 2 (2.0.1.8) Part Number E16648-07 |
|
|
PDF · Mobi · ePub |
| Oracle® Beehive Administrator's Guide Release 2 (2.0.1.8) Part Number E16648-07 |
|
|
PDF · Mobi · ePub |
Using Oracle Data Guard, you can configure your Oracle Beehive deployment for disaster recovery, in which end-user traffic is diverted to a standby database in the event of a failure or planned downtime in the primary system.
This module contains the following topics:
Using Oracle Data Guard with your Oracle Beehive deployment ensures high availability, data protection, and disaster recovery for enterprise data. Data Guard provides a comprehensive set of services that create, maintain, manage, and monitor one or more standby databases to enable production Oracle databases to survive disasters and data corruptions and to minimize downtime for planned outages. Data Guard maintains these standby databases as copies of the production database. Then, if the production database becomes unavailable because of a planned or an unplanned outage, Data Guard can switch any standby database to the production role, minimizing the downtime associated with the outage. Data Guard can be used with traditional backup, restoration, and cluster techniques to provide a high level of data protection and data availability.
This module assumes you are familiar with installing, configuring, and maintaining Oracle databases, Oracle Beehive, and Oracle Data Guard.
To configure a disaster recovery system for Oracle Beehive, your primary deployment can either be a single-instance Oracle Beehive server, or a deployment with multiple Oracle Beehive servers. Likewise, you can use either a single instance Oracle Database, or a multi-instance RAC deployment, for your primary and standby databases.
These configuration steps show how to set up Oracle Beehive for a switchover or failover to a local or remote standby deployment.
In a planned outage (switchover) scenario, you perform manual steps to reverse database roles between the standby system and the primary system, and then shut down the (former) primary system. This is useful to maintain uptime when performing maintenance on the primary system, such as replacing hardware, that requires the servers to be shut down.
In an unplanned outage (failover) scenario, a failure of the primary system is detected and the standby system is made primary. Depending on your Oracle Data Guard configuration, manual steps may be required, or the failover may be performed automatically.
Local HA Standby (Database-Only) versus Full Deployment
In an Oracle Beehive local High-Availability (HA) standby (sometimes called 'database-only') recovery deployment, you create a standby deployment of the database used by Oracle Beehive. This provides for reduced downtime for planned and unplanned primary database outages. In this scenario, you use your primary deployment's Application tiers with the standby database, so no switchover or failover of the Oracle Beehive Application tier occurs.
In a full deployment scenario, you create a standby deployment of both the database and the Application tier(s). In a switchover or failover, you start the Oracle Beehive Application tiers on the standby system, and then redirect user traffic to the standby Oracle Beehive deployment. This provides for reduced downtime for planned and unplanned outages of the entire primary deployment.
Note:
it is also possible to have a hybrid deployment, in which you maintain both full standby infrastructure and local HA standby database servers.Figure Figure 16-1 shows a typical full-deployment scenario. In this scenario, a deployment with multiple Application tiers and database instances is duplicated by the standby deployment.
Figure 16-1 Oracle Beehive Full-Deployment Disaster Recovery Scenario
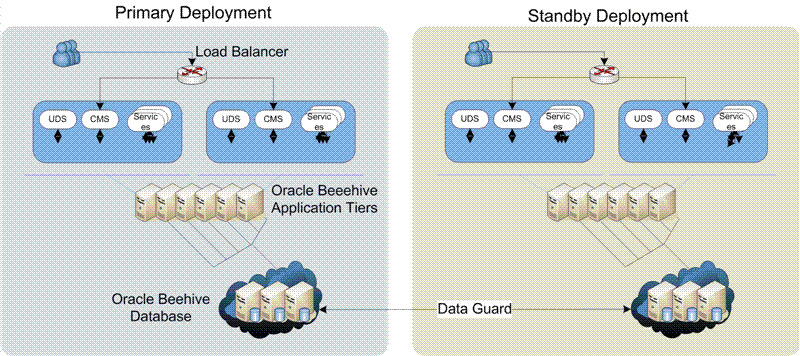
Figure Figure 16-2 shows a typical database-only deployment. In this scenario, there is a standby database that duplicates the primary multi-node database, but there are no standby Application tiers. The primary Application tiers remain active and connect to the standby database. This example provides database redundancy and failover in the event of a failure in the primary database, but there is no provision for Application-tier failover.
Figure 16-2 Oracle Beehive Local HA Standby Recovery Scenario
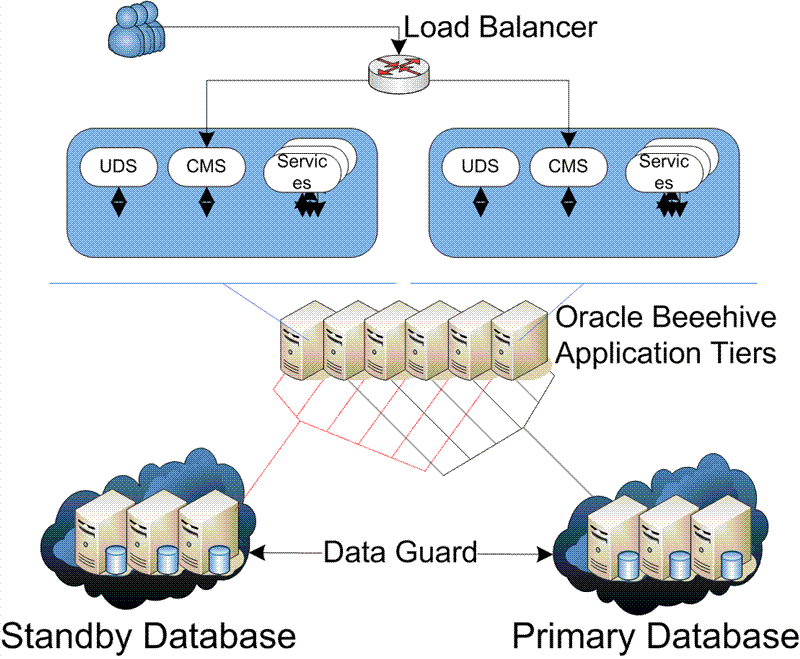
To configure Oracle Beehive for use in these scenarios, perform the following procedures:
There are multiple ways to create the physical standby database. Whether the standby is local or remote you can find the steps for creating a standby database in the Data Guard Administration guide, or on the Oracle Technology Network website at the following URL:
http://www.otn.oracle.com/goto/maa.
After you create the standby database, verify that it is performing properly as detailed in the Data Guard Administration guide in section 3.2.7. If it is a RAC deployment, also ensure that the new physical standby database is registered with the cluster database configuration. For example:
srvctl add database -d stby_orcl -o $ORACLE_HOME -m us.oracle.com -p "+DATA/bhdc/spfilebhdc.ora" -n stby_orcl -r physical_standby srvctl add instance -d stby_orcl -i stby_orcl1 -n stby_db1 srvctl add instance -d stby_orcl -i stby_orcl2 -n stby_db2
If this standby database is for a remote disaster recovery site, make sure when cloning the Oracle Beehive Application tiers that the --do_not_start_at_end option is used on the clone_midtier command.
Additionally, the standby Oracle Beehive servers should be disabled. To disable the standby Oracle Beehive servers, perform the following steps:
From any Oracle Beehive Oracle Home in the standby deployment, use the beectl list_components command to get the instance identifier for each standby Oracle Beehive server:
beectl> list_components --type BeehiveInstance
For each instance, use the beectl modify_property command to disable the server:
beectl> modify_property --component <component_id> --name Status --value DISABLED
After making property changes, you must run the beectl activate_configuration command to activate your proposed configuration changes:
beectl> activate_configuration
Having a record of the details of your primary and standby environments will be useful during setup, configuration, and maintenance of your disaster-recovery configuration.
The following is the sample environment used in examples in this chapter. The example Primary deployment consists of a two-node RAC database and a Beehive deployment using two Application tiers. The Standby deployment duplicates this configuration.
Tip:
Refer back to this section as you read through the rest of this chapter. In all of the examples, you can use the example values to see what your actual values should be.Example Deployment
Bootstrap Service: A common service defined on all nodes, specifically used for service relocation. In this chapter, beehivedg is the example common service name on all nodes
Primary:
RAC Nodes (and Virtual IP): These are defined in the DNS and/or in /etc/hosts. In this chapter, pr_db1 (pr_db1_vip) and pr_db2 (pr_db2_vip) are the example primary database nodes
Oracle Database Name: In this chapter, the example primary database is pr_orcl
ORACLE_SID: In this chapter, pr_orcl1 and pr_orcl2 are the example ORACLE_SIDs
Application tiers: In this chapter, pr_app1 and pr_app2 are the example primary Application tiers
Standby:
See also:
MAA 10g Setup Guide: Creating a RAC Physical Standby Database for a RAC Primary DatabaseRAC Nodes (and Virtual IP): In this chapter, stby_db1 (stby_db1_vip) and stby_db2 (stby_db2_vip) are the example standby database nodes
Oracle Database Name: In this chapter, the example standby database is stby_orcl
ORACLE_SID: In this chapter, stby_orcl1 and stby_orcl2 are the example standby ORACLE_SIDs
Application tiers: In this chapter, stby_app1 and stby_app2 are the example standby Application tiers
IP Addresses: You may find it useful to make a note of the IP addresses for each database node. IP addresses can be used as a RAC configuration method, or as a part of the DNS and/or /etc/hosts file.
To configure service relocation and database triggers, perform the steps in the following sections:
Perform the following steps to create managed services:
Caution:
When creating managed services, do not include the managed service names in the databaseSERVICE_NAMES parameter.If you are using a RAC database deployment, add a CRS-managed bootstrap service and the affinity services for the primary and standby databases by running the following commands:
For the primary, run the following commands on any primary RAC node:
srvctl add service -d pr_orcl -s beehivedg -r pr_orcl1,pr_orcl2 srvctl add service -d pr_orcl -s aff1 -r pr_orcl1 srvctl add service -d pr_orcl -s aff2 -r pr_orcl2
For the standby, run the following commands on any standby RAC node:
srvctl add service -d stby_orcl -s beehivedg -r stby_orcl1,stby_orcl2 srvctl add service -d stby_orcl -s aff1 -r stby_orcl1 srvctl add service -d stby_orcl -s aff2 -r stby_orcl2
If you are using a single-instance database deployment, create the managed service using the dbms_service package. In SQL*Plus, connect as SYS or SYSDBA and enter the following:
begin
dbms_service.create_service(service_name => 'beehivedg',
network_name => 'beehivedg' );
end;
/
When a switchover or failover to a standby database occurs, managed services are not automatically started. Perform the following steps to create a trigger to start up database-related services.
See Also:
"Using Fast Application Notification Callouts" in Chapter 4, "Introduction to Automatic Workload Management" of the Oracle Real Application Clusters Administration and Deployment GuideSetup Service Startup
In a RAC deployment, install a RAC callout script that will start the services when the database is opened.
Note:
Instructions for setting up affinity services are included in the RAC post-install steps in the Oracle Beehive Installation Guide for your platform.For a single instance deployment, create a database startup trigger on the primary database (Oracle Data Guard will subsequently replicate your trigger on the standby database). For example:
CREATE OR REPLACE TRIGGER manage_services_start after startup on database
DECLARE
role VARCHAR(30);
BEGIN
SELECT DATABASE_ROLE INTO role FROM V$DATABASE;
IF role = 'PRIMARY' THEN
DBMS_SERVICE.START_SERVICE('beehivedg');
ELSE
DBMS_SERVICE.STOP_SERVICE('beehivedg');
END IF;
END;
/
To test the setup, you can restart the database (in a RAC deployment, restart the primary RAC node database). The related services should start automatically:
srvctl stop database -d pr_db1 srvctl start database -d pr_db1 srvctl status service -d pr_db1
You must configure the FAN ONS Publisher and Database Role Change trigger in order to enable database failover operations. (In a "full deployment" scenario, the switchover or failover between database deployments includes a transition to a new set of Oracle Beehive Application tier nodes. Since the remote application tier does not receive FAN events, you can skip this step.)
See Also:
Pages 11-13 of "Client Failover in Data Guard Configurations for Highly Available Oracle Databases: Oracle Database 10g Release 2" Oracle Maximum Availability Architecture White Paper, found at the following link on the Oracle Technology Network website:Configure the FAN ONS Publisher Configuration File in $ORACLE_HOME/dbs/cfo${ORACLE_SID}.ora (on both the primary and the standby deployments).
For example (including affinity):
pr_orcl peer=stby_orcl stby_orcl peer=pr_orcl pr_orcl service=beehivedg location=pr_db1,pr_orcl1:pr_db2,pr_orcl2 pr_orcl service=aff1 location=pr_db1,pr_orcl1 pr_orcl service=aff2 location=pr_db2,pr_orcl2 stby_orcl service=beehivedg location=stby_db1,stby_orcl1:stby_db2,stby_orcl2 stby_orcl service=aff1 location=stby_db1,stby_orcl1 stby_orcl service=aff2 location=stby_db2,stby_orcl2
On all primary and standby RAC nodes, copy the $ORACLE_HOME/dbs/cfo${ORACLE_SID}.ora file to each node and rename it with the appropriate ORACLE_SID
Build a wrapper script around the Publisher program:
$ORACLE_HOME/bin/cfo.sh #!/bin/ksh export TZ=PST8PDT export ORACLE_SID=pr_orcl1 export ORACLE_HOME=/u01/app/oracle/product/11.1.0/db_1 export LD_LIBRARY_PATH=$ORACLE_HOME/lib export PATH=$ORACLE_HOME/bin:$PATH $ORACLE_HOME/bin/cfo r echo `date` "executed $0" > /tmp/cfo.log
Copy cfo.sh to each node, and edit each copy to change the ORACLE_SID value on each node appropriately.
Create a database role change trigger:
CREATE OR REPLACE TRIGGER ons_JDBCpublish AFTER DB_ROLE_CHANGE ON DATABASE BEGIN dbms_scheduler.create_job( job_name=>'publish_events', job_type=>'executable', job_action=>'/u01/app/oracle/product/11.1.0/db/bin/cfo.sh', enabled=>TRUE ); END;
Configure your Oracle Beehive servers by performing the following steps:
Notes:
You only need to perform these steps on one Application tier in an Oracle Beehive deployment
In steps 1, 2, and 3, if you have both a local and a remote standby, include connection strings for all three sets of database nodes
You only need to configure affinity services (step 2) for RAC configurations
Update bootstrap connect_string to use service relocation:
Run beectl> stop --all
Run the following command:
beectl> modify_bootstrap_configuration --connect_string \ "(DESCRIPTION=(ADDRESS_LIST=(LOAD_BALANCE=yes)(FAILOVER=on)\ (ADDRESS=(PROTOCOL=TCP)(HOST=pr_db1_vip.example.com)(PORT=1521))\ (ADDRESS=(PROTOCOL=TCP)(HOST=pr_db2_vip.example.com)(PORT=1521))\ (ADDRESS=(PROTOCOL=TCP)(HOST=stby_db1_vip.example.com)(PORT=1521))\ (ADDRESS=(PROTOCOL=TCP)(HOST=stby_db2_vip.example.com)(PORT=1521)))\ (CONNECT_DATA=(SERVER=DEDICATED)(SERVICE_NAME=beehivedg.us.oracle.com)))"
Update the affinity service connect string:
Note:
You only need to configure affinity services for RAC configurations. If you are not using RAC, you can skip this step.beectl> modify_property --component _CURRENT_SITE:Database \ --name AffinityServiceNames \ --value '((DESCRIPTION= (ADDRESS=(PROTOCOL=TCP)(HOST=pr_db1_vip.example.com)(PORT=1521)) (ADDRESS=(PROTOCOL=TCP)(HOST=stby_db1_vip.example.com)(PORT=1521)) (LOAD_BALANCE=yes)(FAILOVER=on) (CONNECT_DATA=(SERVER=DEDICATED)(SERVICE_NAME=bhaffsvc1.us.oracle.com)))' \ --value '((DESCRIPTION= (ADDRESS=(PROTOCOL=TCP)(HOST=pr_db2_vip.example.com)(PORT=1521)) (ADDRESS=(PROTOCOL=TCP)(HOST=stby_db2_vip.example.com)(PORT=1521)) (LOAD_BALANCE=yes)(FAILOVER=on) (CONNECT_DATA=(SERVER=DEDICATED)(SERVICE_NAME=bhaffsvc2.us.oracle.com)))'
Update the ONS entries by modifying the ONS setup to include the standby nodes:
Note:
6200 is the current setting forremoteport in the $CRS_HOME/opmn/conf/ons.config file and should also show in the $CRS_HOME/bin/onsctl ping outputbeectl> modify_property --component _current_site:Database \ --name OnsNodeConfiguration \ --value pr_db1.example.com:6200 \ --value pr_db2.example.com:6200 \ --value stby_db1.example.com:6200 \ --value stby_db2.example.com:6200
Activate the Configuration on the first Oracle Beehive Application tier by running the following commands:
beectl> activate_configuration beectl> modify_local_configuration_files beectl> start --all
One at a time, run the following commands on each remaining Application tier instance:
beectl> stop -all beectl> modify_local_configuration_files -restart_needed false beectl> start --all
An Oracle Data Guard configuration consists of one database that functions in the primary role and one or more databases that function in the standby role. Typically, the role of each database does not change. However, if Data Guard is used to maintain service in response to a primary database outage, you must initiate a role transition between the current primary database and one standby database in the configuration.
A database operates in one of the following mutually exclusive roles: primary or standby. Data Guard enables you to change these roles dynamically by issuing SQL statements, or by using either of the Data Guard broker's interfaces (command line or Oracle Enterprise Manager).
See Also:
Chapter 1, "Oracle Data Guard Broker Concepts," of Oracle Data Guard BrokerOracle Data Guard supports the following role transitions:
Switchover
Allows the primary database to switch roles with one of its standby databases. There is no data loss during a switchover. After a switchover, each database continues to participate in the Data Guard configuration with its new role. Switchover is generally used for planned outages.
Failover
Changes a standby database to the primary role in response to a primary database failure. If the primary database was not operating in either maximum protection mode or maximum availability mode before the failure, some data loss may occur. If Flashback Database is enabled on the primary database, it can be reinstated as a standby for the new primary database once the reason for the failure is corrected. Failover is used when unplanned outages occur.
To perform a database-only switchover operation follow the steps in MetaLink Note 751600.1.
To perform a switchover operation in a full-deployment scenario, perform the following steps:
Stop Oracle Beehive on the primary site application nodes:
beectl> stop --all
Follow the steps in MetaLink Note 751600.1.
If this is a switchover in a full deployment configuration, disable the old primary site Application tiers and enable the new primary site Application tiers:
Use the beectl list_components command to list all beehive instances:
beectl> list_components --type BeehiveInstance
Use the beectl modify_property command to disable each of the old Application tiers:
beectl> modify_property --component <component_id> --name Status --value DISABLED
Use the beectl modify_property command to enable each of the new Application tiers:
beectl> modify_property --component <component_id> --name Status --value ENABLED
Activate your changes by running the beectl activate_configuration command:
beectl> activate_configuration
Start the Oracle Beehive Application tiers in your standby deployment:
beectl> start --all
Once the standby Oracle Beehive system is up and running, if this is a full deployment, you can redirect user traffic to the new primary deployment.
To perform a database-only failover operation follow the steps in section 8.2.2, "Performing a Failover to a Physical Standby Database," in Chapter 8 of the Oracle Data Guard Concepts and Administration Guide.
To perform a failover operation in a full-deployment scenario, perform the following steps:
If possible, stop Oracle Beehive on the primary site application nodes:
beectl> stop --all
Follow the steps in section 8.2.2, "Performing a Failover to a Physical Standby Database," in Chapter 8 of the Oracle Data Guard Concepts and Administration Guide
If this is a failover in a full deployment configuration, disable the old primary site Application tiers and enable the new primary site Application tiers:
Use the beectl list_components command to list all beehive instances:
beectl> list_components --type BeehiveInstance
Use the beectl modify_property command to disable each of the old Application tiers:
beectl> modify_property --component <component_id> --name Status --value DISABLED
Use the beectl modify_property command to enable each of the new Application tiers:
beectl> modify_property --component <component_id> --name Status --value ENABLED
Activate your changes by running the beectl activate_configuration command:
beectl> activate_configuration
Start the Oracle Beehive Application tiers in your standby deployment:
beectl> start --all
Once the standby Oracle Beehive system is up and running, if this is a full deployment, you can redirect user traffic to the new primary deployment.
This section includes the following topics
You can modify the outbound connect timeout.
See Also:
Page 5 of "Client Failover in Data Guard Configurations for Highly Available Oracle Databases: Oracle Database 10g Release 2" Oracle Maximum Availability Architecture White Paper, found at the following link on the Oracle Technology Network website:For example, to modify the outbound connect timeout to three seconds:
beectl modify_property --component _current_site:Database:DefaultNonXaPool \ --name ConnectionProperties \ --value oracle.net.ns.SQLnetDef.TCP_CONNTIMEOUT_STR:3000
Listener throttling is a performance adjustment you can make to the database listener that may be necessary for the standby database to operate efficiently during and after a switchover or failover. When the system initially moves from the primary to the standby, there will be a very high number of connections moved all at once to the standby system, which can cause a "connection storm." Listener throttling is a method of controlling the number of simultaneous connections made to the database.
The appropriate value to use depends on the size of your deployment (number of concurrent users), and the capability of your database hardware.
See Also:
For complete details of this procedure, see Appendix E, "Listener Connection Rate Throttling," of "Optimizing Availability During Unplanned Outages Using Oracle Clusterware and RAC " Oracle Maximum Availability Architecture White Paper, found at the following link on the Oracle Technology Network website:The CONNECTION_RATE_<listener_name> parameter indicates the connection rate per second for all addresses with RATE_LIMIT set to YES, yes, or a specific rate.
In this example, 10 connections will be spawned per second only for the first address in the address list. The RATE_LIMIT parameter can also specify the rate itself instead of only turning throttling on at the default rate. For example, RATE_LIMIT=5 on a particular address indicates a specific setting for just that address. When specifying a RATE_LIMIT at the address level, you should not specify the CONNECTION_RATE_<listener_name> property.
Note:
If both the global rate and a specific rate are specified, the global rate is the one enforced.Perform the following procedure to enable listener throttling on each database node:
Edit the listener.ora file. In Example 16-1, only the first address has throttling enabled. Note that the setting of 10 is an example; the actual setting depends on the details of your environment
Example 16-1 Example listener.ora File for Listener Throttling
LISTENER_PR_DB1 = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = pr_db1_vip)(PORT = 1521)(RATE_LIMIT=YES)(QUEUESIZE=1024)(IP = FIRST)) ) (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = <X.X.X.X>)(PORT = 1521)(IP = FIRST)) ) (ADDRESS_LIST = (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC)) ) ) ) CONNECTION_RATE_LISTENER_PR_DB1=30
Substitute the correct IP address for the corresponding non-VIP node (pr_db1 in this example) for <X.X.X.X>.
Implement the listener.ora changes by running the following command:
lsnrctl reload LISTENER_PR_DB1
|
Copyright © 2008, 2013, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|