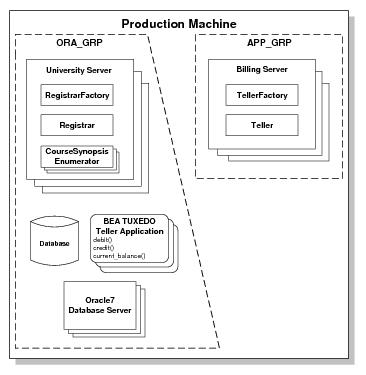
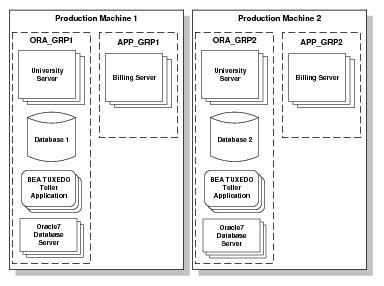
Figure 8‑2 shows the Production sample application groups replicated on another machine, as specified in the application’s
UBBCONFIG file, as ORA_GRP2 and APP_GRP2.
In Figure 8‑2, the only difference between the content of the groups on Production Machines 1 and 2 is the database. The database for Production Machine 1 contains student and account information for a subset of students. The database for Production Machine 2 contains student and account information for a different subset of students. (The course information table in both databases is identical.) Note that the student information in a given database may be completely unrelated to the account information in the same database.
|
2.
|
In the GROUPS section, specify the names of the groups you want to configure.
|
|
3.
|
In the SERVERS section, enter the following information for the server process you want to replicate:
|
|
•
|
The GROUP parameter, which specifies the name of the group to which the server process belongs. If you are replicating a server process across multiple groups, specify the server process once for each group.
|
|
•
|
The SRVID parameter, which specifies a numeric identifier, giving the server process a unique identity.
|
|
•
|
The MIN parameter, which specifies the number of instances of the server process to start when the application is booted.
|
|
•
|
The MAX parameter, which specifies the maximum number of server processes that can be running at any one time.
|
Thus the MIN and
MAX parameters determine the degree to which a given server application can process requests on a given object in parallel. During run time, the system administrator can examine resource bottlenecks and start additional server processes, if necessary. In this sense, the application is designed so that the system administrator can scale it.
As stated in Chapter 1, “CORBA Server Application Concepts,” object state management is a fundamentally important concern of large-scale client/server systems because it is critically important that such systems achieve optimized throughput and response time. This section explains how you can use object state management to increase the scalability of the objects managed by an Oracle Tuxedo server application, using the
Registrar and
Teller objects in the Production sample applications as an example.
To achieve scalability gains, the Registrar and
Teller objects are configured in the Production server application to have the
method activation policy. The
method activation policy assigned to these two objects results in the following behavior changes:
With the Basic through the Wrapper sample applications, the Registrar object was process-bound. All client requests on that object invariably went to the same object instance in the machine’s memory. The Basic sample application design may be adequate for a small-scale deployment. However, as client application demands increase, client requests on the
Registrar object eventually become queued, and response time drops.
However, when the Registrar and
Teller objects are stateless, and the server processes that manage these objects are replicated, these objects can be made available to process client requests on them in parallel. The only constraint on the number of simultaneous client requests that these objects can handle is the number of server processes that are available that can instantiate these objects. These stateless objects, thereby, make for more efficient use of machine resources and reduced client response time.
|
•
|
Client application requests to the Registrar object are routed based on the student ID. That is, requests on behalf of one subset of students go to one group; and requests on behalf of another subset of students go to another group.
|
|
•
|
Requests to the Teller object are routed based on the account number. That is, billing requests on behalf of one subset of accounts go to one group; and requests on behalf of another subset of accounts go to another group.
|
|
•
|
Data in the INTERFACES and ROUTING sections of the UBBCONFIG file.
|
|
1.
|
The INTERFACES section lists the names of the interfaces for which you want to enable factory-based routing. For each interface, this section specifies what kinds of criteria the interface routes on. This section specifies the routing criteria via an identifier, FACTORYROUTING, as in the following example:
|
|
2.
|
The ROUTING section specifies the following data for each routing value:
|
|
•
|
The TYPE parameter, which specifies the type of routing. In the Production sample, the type of routing is factory-based routing. Therefore, this parameter is defined to FACTORY.
|
|
•
|
The FIELD parameter, which specifies the name that the factory inserts in the routing value. In the Production sample, the field parameters are student_id and account_number, respectively.
|
|
•
|
The FIELDTYPE parameter, which specifies the data type of the routing value. In the Production sample, the field types for student_id and account_number are long.
|
|
•
|
The RANGES parameter, which specifies the values that are routed to each group.
|
The preceding example shows that Registrar object references for students with IDs in one range are routed to one server group, and
Registrar object references for students with IDs in another range are routed to another group. Likewise,
Teller object references for accounts in one range are routed to one server group, and
Teller object references for accounts in another range are routed to another group.
|
3.
|
The groups specified by the RANGES identifier in the ROUTING section of the UBBCONFIG file need to be identified and configured. For example, the Production sample specifies four groups: APP_GRP1, APP_GRP2, ORA_GRP1, and ORA_GRP2. These groups need to be configured, and the machines on which they run need to be identified.
|
The following example shows the GROUPS section of the Production sample
UBBCONFIG file, in which the ORA_GRP1 and ORA_GRP2 groups are configured. Notice how the names in the
GROUPS section match the group names specified in the
ROUTING section; this is critical for factory-based routing to work correctly. Furthermore, any change in the way groups are configured in an application must be reflected in the
ROUTING section. (Note that the Production sample packaged with the Oracle Tuxedo software is configured to run entirely on one machine. However, you can easily configure this application to run on multiple machines.)
The third parameter to this operation, criteria, specifies a list of named values to be used for factory-based routing. Therefore, the work of implementing factory-based routing in a factory is in building the
NVlist.
As stated previously, the RegistrarFactory object in the Production sample application specifies the value
STU_ID. This value must match exactly the following in the
UBBCONFIG file:
The RegistrarFactory object inserts the student ID into the
NVlist using the following code:
The RegistrarFactory object has the following invocation to the
TP::create_object_reference() operation, passing the
NVlist created in the preceding code example:
|
2.
|
The RegistrarFactory inserts the student ID into an NVlist, which is used as the routing criteria.
|
|
3.
|
The RegistrarFactory invokes the TP::create_object_reference() operation, passing the Registrar interface name, a unique OID, and the NVlist.
|
|
•
|
How to ensure that the Registrar and Teller objects work properly for the Production deployment environment; namely, across multiple replicated server processes and multiple groups. Given that the University and Billing server processes are replicated, the design must consider how these two objects should be instantiated.
|
To make each Registrar and
Teller object unique, the factories for those objects must change the way in which they make object references to them. For example, when the
RegistrarFactory object in the Basic sample application created an object reference to the
Registrar object, the
TP::create_object_reference() operation specified an OID that consisted only of the string
registrar. However, in the Production sample application, the same
TP::create_object_reference() operation uses a generated unique OID instead.
A consequence of giving each Registrar and
Teller object a unique OID is that there may be multiple instances of these objects running simultaneously in the Oracle Tuxedo domain. This characteristic is typical of the stateless object model, and is an example of how the Oracle Tuxedo domain can be highly scalable and at the same time offer high performance.
And last, since unique Registrar and
Teller objects need to be brought into memory for each client request on them, it is critical that these objects be deactivated when the invocations on them are completed so that any object state associated with them does not remain idle in memory. The Production server application addresses this issue by assigning the
method activation policy to these two objects in the ICF file.
For example, when the client application sends a request to the RegistrarFactory object to get an object reference to a
Registrar object, the client application includes a student ID in that request. The client application must use the object reference that the
RegistrarFactory object returns to make all subsequent invocations on a
Registrar object on a particular student’s behalf, because the object reference returned by the factory is group-specific. Therefore, for example, when the client application subsequently invokes the
get_student_details() operation on the
Registrar object, the client application can be assured that the
Registrar object is active in the server group associated with the database containing data for that student. To show how this works, consider the following execution scenario, which is implemented in the Production sample application:
|
3.
|
The RegistrarFactory object uses the student ID to create an object reference to a Registrar object in ORA_GRP1, based on the routing information in the UBBCONFIG file, and returns that object reference to the client application.
|
The RegistrarFactory object from the preceding scenario returns to the client application a unique reference to a
Registrar object that can be instantiated only in ORA_GRP1, which runs on Production Machine 1 and has a database containing student data for students with IDs in the range 100001 to 100005. Therefore, when the client application sends subsequent requests to this
Registrar object on behalf of a given student, the
Registrar object interacts with the correct database.
However, because factory-based routing is used in the TellerFactory object, the
Registrar object passes the student’s account number when the
Registrar object requests a reference to a
Teller object. This way, the
TellerFactory object creates a reference to a
Teller object in the group that has the correct database.