Tuning the Analytical Engine
It is usually necessary to adjust some parameters to configure the Analytical Engine correctly before running it the first time. Other adjustments can be made later to optimize the behavior and performance.
This chapter covers the following topics:
- Editing Engine Parameters
- Creating or Renaming Engine Profiles
- Tuning Analytics
- Tuning Performance
- Reconfiguring the sales_data_engine Table
- Enabling Engine Models Globally
- Configuring the Engine Mode
- Advanced Analytics (Nodal Tuning)
Editing Engine Parameters
To tune the Analytical Engine, you modify values of two types of engine parameters:
-
Global parameters that apply to the engine or to most or all of the forecasting models. For convenience, you define engine profiles , which are sets of engine parameters with specific values. Demantra provides some predefined profiles for different purposes, and you can define additional engine profiles, as needed.
-
Parameters that apply to specific forecast models.
To edit the global engine parameters
-
Log onto the Business Modeler.
-
Click Parameters > System Parameters. The System Parameters dialog box appears.
-
Click the Engine tab.
-
From the Engine Profile drop-down, select the engine profile whose parameter settings you want to adjust.
-
Find the parameter of interest. The dialog box provides find, sort, and filter capabilities to help you with this. See "Engine Parameters".
-
To change the value of the parameter, click the Value field for that parameter. Type the new value or select a value from the drop-down menu.
-
Click Save to save your changes to this profile.
-
Click Close.
To edit specific model parameters
To edit most model-specific parameters, you must work directly within the Demantra database. For information on the parameters and their locations in the database, see "Engine Parameters".
See also
"Creating or Renaming Engine Profiles"
"Tuning Analytics"
"Enabling Engine Models Globally"
Creating or Renaming Engine Profiles
To create or rename an engine profile
-
Log onto the Business Modeler.
-
Click Parameters > System Parameters. The System Parameters dialog box appears.
-
Click the Engine tab.
-
Do one of the following:
-
To rename an existing profile, click the profile from the Engine Profiles list and then click Edit.
-
To create a new profile, click New.
-
-
Enter a (new) name for the profile.
See also
"Editing Engine Parameters"
"Tuning Analytics"
-
When creating a new Engine Profile, determine whether it is to be a batch or a simulation profile. A simulation profile must be attached to a parent batch forecast, because the simulation is stored in the sim_val column matching the batch parent profile.
For example, a simulation with the batch parent profile ID of 3 is stored in the sim_val_3 column. The internal profile ID can be found in ENGINE_PROFILES table.
-
If this is a simulation profile, select the Simulation Engine Profile check box.
-
If the new profile is a simulation profile, select the Parent batch Profile from the drop-down menu.
-
Click Ok.
Tuning Analytics
For basic parameters related to the forecast tree, see "Specifying Additional Parameters". For information on all parameters (including default values), see "Engine Parameters".
Analytical Parameters
The following parameters control analytics:
Parameters Related to Promotional Causal Factors (PE Mode Only)
The following parameters are related to promotional causal factors:
Parameters Related to Validation (PE Mode Only)
The Analytical Engine applies different forecasting models to each node of the forecast tree, calculates the uplift for each node, and uses that uplift to check whether the model is appropriate for that node. If not, the model is not used for the node.
The Analytical Engine can discard a model for a given node for either of two reasons:
-
The model generated an uplift that was beyond the upper allowed bound, as specified by the UpperUpliftBound parameter.
-
The model generated too many exceptional uplifts. An uplift is considered "exceptional" if it exceeds the lower bound specified by the LowerUpliftBound parameter. The AllowableExceptions parameter controls how many exceptional uplifts are permitted.
Parameters Related to Output (PE Mode Only)
The following parameters control the output of Promotion Effectiveness forecast values:
See also
"Editing Engine Parameters"
"Creating or Renaming Engine Profiles"
Tuning Performance
To improve the performance of the Analytical Engine, check the settings of the following parameters. To access these parameters in Business Modeler, click Parameters > System Parameters and then click the Database tab.
Basic Engine Parameters for Performance
The following engine parameters are critical to good performance. Make sure they are set appropriately for your configuration.
Parameters That Can Speed Performance
The following parameters can help the Analytical Engine run more quickly by omitting processing steps. You should change these only if you are sure that doing so will not cause problems.
The engine divider uses Fast Divider functionality. The engine uses the ENGINE_BRANCH_LIST table to determine the actual branch, not the BRANCH_ID column of the configured combination table. Each time the engine processes a branch, it updates the BRANCH_ID column with the actual allocation.
Database Partitioning for the Engine
You can partition the database so that the Analytical Engine can access data more rapidly. Specifically, you can place different parts of the sales_data, mdp_matrix, and promotion_data tables on different partitions, so that each partition corresponds to a potentially different item and/or location.
The overall process is as follows:
-
Create the partitions and move rows to them as needed. This is beyond the scope of this documentation.
-
To partition only by item, choose a database column that you can use to subdivide the records by item. This column must exist in the sales_data, mdp_matrix, and (in the case of Promotion Effectiveness) promotion_data tables and must have the same name in each of these tables.
For example, it might be suitable to partition by brand. The brand information is available in mdp_matrix as (for example) the t_ep_p2a_ep_id field. You would have to replicate this column to the sales_data and promotion_data tables as well, perhaps by a database trigger.
Similarly, to partition only by location, choose a database column that you can use to subdivide the records by location.
To partition by item and by location, choose a database column that you can use to subdivide the records by item and another column that subdivides them by location.
-
Set the following parameters so that the Analytical Engine can find the partition on which any combination resides:
Parameter Purpose PartitionColumnItem Specifies the name of the column that partitions the data by item. PartitionColumnLoc Specifies the name of the column that partitions the data by location.
Other Database Considerations
Pay attention to the indexes of sales_data and mdp_matrix tables.
Also, for Oracle databases, Demantra writes to multiple tablespaces, as specified during installation. The tablespace assignments are controlled by parameters, which you can edit through the Business Modeler. Make sure that these parameters refer to tablespaces within the appropriate database user, and make sure each has enough storage.
Note: Oracle recommends that you use the standard names for these tablespaces, as documented in the Oracle Demantra Installation Guide. Then it is easier for you to share your database with Oracle Support Services in case of problems.
Additional parameters control the default initial sizes and how much storage is added.
Reconfiguring the sales_data_engine Table
The Analytical Engine creates and uses a table (or view) called sales_data_engine. You can control how the Analytical Engine does this, in order to improve performance.
-
You can adjust the sales_data table for direct use by the Analytical Engine, so that the sales_data_engine table is not needed.
-
Normally, the Analytical Engine internally creates the sales_data_engine table for its own use, and creating this table can be time-consuming. You can speed up the engine by configuring it to use the sales_data table instead of the sales_data_engine table.
-
Normally, when the Analytical Engine runs, it joins sales_data_engine (or its synonym) with the mdp_matrix table. This is not always necessary, and you can prevent this join to speed up the Analytical Engine.
The following table lists the key parameters and some typical settings:
Additional Steps
-
Configure the forecast tree as you normally would. See "Configuring the Forecast Tree".
-
In the database, create a synonym for sales_data. The name of synonym should be sales_data_engine or whatever synonym you plan to use.
-
Rewrite the following database procedures as needed:
-
Consult Demantra for assistance.
-
Test that you have configured the engine correctly.
-
Add new records to sales_data, in any of the following ways: by loading via the Data Model Wizard, by running integration, or by chaining.
-
Run the engine.
-
Check the sales_data table and make sure of the following:
-
This table should have a column for every level in the forecast tree,
-
This table should have a column named do_aggri.
-
This table should have should include non-null data in these columns for at least some of the records.
-
-
Enabling Engine Models Globally
Demantra provides a set of theoretical engine models that the Analytical Engine uses when it creates a forecast. Usually you do not make changes, but you can specify which models to use, as well as set basic parameters for each model.
Caution: Only advanced users should make these changes.
When the Analytical Engine runs, it may use a subset of these models on any particular combination. The engine tests each model for applicability; see "The Forecasting Process".
Note: Optimization can only use linear generalized coefficients
To enable models for the Analytical Engine to use
-
Log onto the Business Modeler.
-
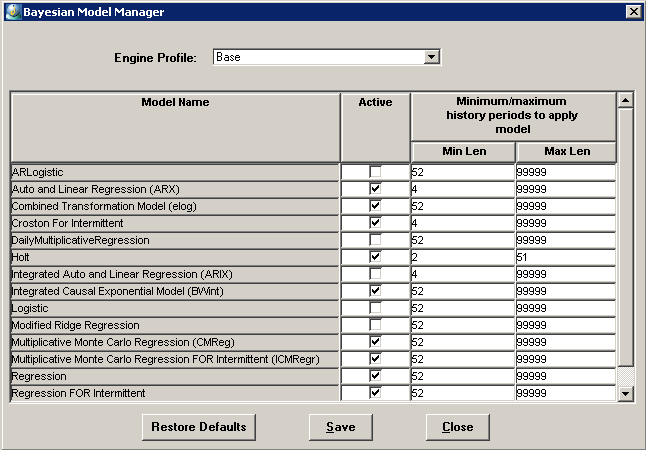
Click Engine > Model Library.
The following dialog box appears.
-
Select the batch engine profile to be associated with the model library configurations.
-
For each model, do the following:
-
To enable the Analytical Engine to use this model, make sure the Active check box is checked. For details on these models, see "Theoretical Engine Models". Note that not all models are supported with any given Analytical Engine.
-
The other two settings control the minimum and maximum number of non zero observations that a combination must have in order for the Analytical Engine to consider using this model for this combination. To specify these values, type integers into the Min Len and Max Len fields.
Note: Min Len must be equal to or greater than the number of causal factors in the forecast, except for the HOLT and FCROST models, which do not use causal factors.
-
-
Click Save and then click Close.
Configuring the Engine Mode
Oracle provides two different modes of the Analytical Engine:
-
The DP mode is for use with Demand Planner or other planning products.
To specify the engine mode
The RUNMODE parameter specifies the mode of the Analytical Engine to use:
-
Use 1 to specify the PE mode.
-
Use 0 to specify the DP mode.
If you use this setting, also be sure that you have defined the forecast tree appropriately. In particular, make sure that the LPL (PROMO_AGGR_LEVEL) is the same as the minimum forecast level. To set this, use the forecast tree editor in the Business Modeler.
See also
"Troubleshooting"
Advanced Analytics (Nodal Tuning)
Normally, the Analytical Engine uses the same options for every node in the forecast tree, but you can make certain adjustments for individual nodes, if necessary. This task is recommended only for advanced users in conjunction with Oracle Support.
Of the models you specify for a given node, when the Analytical Engine runs, it may use a subset of these models, as described in "The Forecasting Process". The Analytical Engine indicates (in the models column of mdp_matrix) the models that it used.
To enable advanced analytics