APIs in Oracle HRMS
APIs in Oracle HRMS
An Application Programmatic Interface (API) is a logical grouping of external process routines. The Oracle HRMS strategy delivers a set of PL/SQL packaged procedures and functions that together provide an open interface to the database. For convenience we have called each of these packaged procedures an API.
This document provides all the technical information you need to be able to use these APIs and covers the following topics:
-
Describes how you can use the Oracle HRMS APIs and the advantages of this approach.
-
Understanding the Object Version Number (OVN)
Explains the role of the object version number. The APIs use it to check whether a row has been updated by another user, to prevent overwriting their changes.
-
Explains where to find information about the parameters used in each API; parameter naming conventions; the importance of naming parameters in the API call instead of relying on parameter list order; and how to use default values to avoid specifying all parameters. Also explains the operation of certain control parameters, such as those controlling DateTrack operations.
-
Explains that commits are handled by the calling program, not the APIs, and the advantages of this approach. Also explains how to avoid deadlocks when calling more than one API in the same commit unit.
-
Describes how the APIs validate key flexfield and descriptive flexfield values.
-
Explains how to use the Multilingual Support APIs.
-
Explains that we provide legislation-specific APIs for some business processes, such as Create Address.
-
Explains how the APIs raise errors and warnings, and how the calling code can handle them. A message table is provided for handling errors in batch processes.
-
Shows how to load a batch of person address data and how to handle validation errors.
-
Explains how to populate the WHO columns (which record the Applications user who caused the database row to be created or updated) when you use the APIs.
-
A user hook is a location where you can add processing logic or validation to an API. There are hooks in the APIs for adding validation associated with a particular business process. There are also hooks in table-level modules for validation on specific data items. This section explains where user hooks are available and how to implement them. It also explains their advantages over database triggers.
-
Explains how you can write your own APIs that call one or more of the supplied APIs.
-
Handling Object Version Numbers in Oracle Forms
Explains how to implement additional Forms logic to manage the object version number if you write your own forms that call the APIs.
API Overview
Fundamental to the design of all APIs in Oracle HRMS is that they should provide an insulating layer between the user and the data-model that would simplify all data-manipulation tasks and would protect customer extensions on upgrade. They are parameterized and executable PL/SQL packages that provide full data validation and manipulation.
The API layer enables us to capture and execute business rules within the database - not just in the user interface layer. This layer supports the use of alternative interfaces to HRMS, such as web pages or spreadsheets, and guarantees all transactions comply with the business rules that have been implemented in the system. It also simplifies integration of Oracle HRMS with other systems or processes and provides supports for the initial loading
Alternative User Interfaces
The supported APIs can be used as an alternative data entry point into Oracle HRMS. Instead of manually typing in new information or altering existing data using the online forms, you can implement other programs to perform similar operations.
These other programs do not modify data directly in the database. They call the APIs which:
-
Ensure it is appropriate to allow that particular business operation
-
Validate the data passed to the API
-
Insert/update/delete data in the HR schema
APIs are implemented on the server-side and can be used in many ways. For example:
-
Customers who want to upload data from an existing system. Instead of employing temporary data entry clerks to type in data, a program could be written to extract data from the existing system and then transfer the data into Oracle HRMS by calling the APIs.
-
Customers who purchase a number of applications from different vendors to build a complete solution. In an integrated environment a change in one application may require changes to data in another. Instead of users having to remember to go into each application repeating the change, the update to the HRMS applications could be applied electronically. Modifications can be made in batches or immediately on an individual basis.
-
Customers who want to build a custom version of the standard forms supplied with Oracle HRMS. An alternative version of one or more forms could be implemented using the APIs to manage all database transactions.
-
Customers who want to develop web-based interfaces to allow occasional users to access and maintain HR information without the cost of deploying or supporting standard Oracle HRMS forms. This is the basis of most Self-Service functions that allow employees to query and update their own information, such as change of name, address, marital status. This also applies to managers who want to query or maintain details for the employees they manage.
-
Managers who are more familiar with spreadsheet applications may want to export and manipulate data without even being connected to the database and then upload modifications to the HRMS database when reconnected.
In all these examples, the programs would not need to modify data directly in the Oracle HRMS database tables. The specific programs would call one or more APIs and these would ensure that invalid data is not written to the Oracle HRMS database and that existing data is not corrupted.
Advantages of Using APIs
Why use APIs instead of directly modifying data in the database tables?
Oracle does not support any direct manipulation of the data in any application using PL/SQL. APIs provide you with many advantages:
-
APIs enable you to maintain HR and Payroll information without using Oracle forms.
-
APIs insulate you from the need to fully understand every feature of the database structure. They manage all the inter-table relationships and updates.
-
APIs are guaranteed to maintain the integrity of the database. When necessary, database row level locks are used to ensure consistency between different tables. Invalid data cannot be entered into the system and existing data is protected from incorrect alterations.
-
APIs are guaranteed to apply all parts of a business process to the database. When an API is called, either the whole transaction is successful and all the individual database changes are applied, or the complete transaction fails and the database is left in the starting valid state, as if the API had not been called.
-
APIs do not make these changes permanent by issuing a commit. It is the responsibility of the calling program to do this. This provides flexibility between individual record and batch processing. It also ensures that the standard commit processing carried out by client programs such as Forms is not affected.
-
APIs help to protect any customer-specific logic from database structure changes on upgrade. While we cannot guarantee that any API will not change to support improvements or extensions of functionality, we are committed to minimize the number of changes and to provide appropriate notification and documentation if such changes occur.
Note: Writing programs to call APIs in Oracle HRMS requires knowledge of PL/SQL version 2. The rest of this essay explains how to call the APIs and assumes the reader has knowledge of programming in PL/SQL.
Understanding the Object Version Number (OVN)
Nearly every row in every database table is assigned an object_version_number. When a new row is inserted, the API usually sets the object version number to 1. Whenever that row is updated in the database, the object version number is incremented. The row keeps that object version number until it is next updated or deleted. The number is not decremented or reset to a previous value.
Note: The object version number is not unique and does not replace the primary key. There can be many rows in the same table with the same version number. The object version number indicates the version of a specific primary key row.
Whenever a database row is transferred (queried) to a client, the existing object version number is always transferred with the other attributes. If the object is modified by the client and saved back to the server, then the current server object version number is compared with the value passed from the client.
-
If the two object version number values are the same, then the row on the server is in the same state as when the attributes were transferred to the client. As no other changes have occurred, the current change request can continue and the object version number is incremented.
-
If the two values are different, then another user has already changed and committed the row on the server. The current change request is not allowed to continue because the modifications the other user made may be overwritten and lost. (Database locks are used to prevent another user from overwriting uncommitted changes.)
The object version number provides similar validation comparison to the online system. Forms interactively compare all the field values and displays the "Record has been modified by another user" error message if any differences are found. Object version numbers allow transactions to occur across longer periods of time without holding long term database locks. For example, the client application may save the row locally, disconnect from the server and reconnect at a later date to save the change to the database. Additionally, you do not need to check all the values on the client and the server.
Example
Consider creating a new address for a Person. The create_person_address API automatically sets the object_version_number to 1 on the new database row. Then, two separate users query this address at the same time. User A and user B will both see the same address details with the current object_version_number equal to 1.
User A updates the Town field to a different value and calls the update_person_address API passing the current object_version_number equal to 1. As this object_version_number is the same as the value on the database row the update is allowed and the object_version_number is incremented to 2. The new object_version_number is returned to user A and the row is committed in the database.
User B, who has details of the original row, notices that first line of the address is incorrect. User B calls the update_person_address API, passing the new first line and what he thinks is the current object_version_number (1). The API compares this value with the current value on the database row (2). As there is a difference the update is not allowed to continue and an error is returned to user B.
To correct the problem, user B then re-queries this address, seeing the new town and obtains the object_version_number 2. The first line of the address is updated and the update_person_address API is called again. As the object_version_number is the same as the value on the database row the update is allowed to continue.
Therefore both updates have been applied without overwriting the first change.
Understanding the API Control Parameter p_object_version_number
Most published APIs have the p_object_version_number control parameter.
-
For create style APIs, this parameter is defined as an OUT and will always be initialized.
-
For update style APIs, the parameter is defined as an IN OUT and is mandatory.
The API ensures that the object version number(s) match the current value(s) in the database. If the values do not match, the application error HR_7155_OBJECT_LOCKED is generated. At the end of the API call, if there are no errors the new object version number is passed out.
For delete style APIs when the object is not DateTracked, it is a mandatory IN parameter. For delete style APIs when the object is DateTracked, it is a mandatory IN OUT parameter.
The API ensures that the object version number(s) match the current value(s) in the database. When the values do not match, the application error HR_7155_OBJECT_LOCKED is raised. When there are no errors for DateTracked objects that still list, the new object version number is passed out.
See:
Understanding the p_datetrack_update_mode control parameter
Understanding the p_datetrack_delete_mode control parameter
Handling Object Version Numbers in Oracle Forms
Detecting and Handling Object Conflicts
When the row being processed does not have the correct object version number, the application error HR_7155_OBJECT_LOCKED is raised. This error indicates that a particular row has been successfully changed and committed since you selected the information. To ensure that the other changes are not overwritten by mistake, re-select the information, reapply your changes, and re-submit to the API.
API Parameters
This section describes parameter usage in Oracle HRMS.
Locating Parameter Information
You can find the parameters for each API in one of two ways, either by looking at the documentation in the package header creation scripts or by using SQL*Plus.
Oracle Integration Repository
Oracle Integration repository provides a description of each API including the application licensing information, parameter lists, and parameter descriptions. See: Browsing the Interfaces, Oracle Integration Repository User Guide
Oracle only supports the publicly callable business process APIs published and described in Oracle Integration Repository.
Many other database packages include procedures and functions, which may be called from the API code. The application does not support direct calls to any other routines, unless explicitly specified, since users would be able to bypass the API validation and logic steps. This may corrupt the data held within the Oracle HRMS application suite.
The contents of Oracle Integration Repository match the installed code. When new APIs are installed, their details appear in the integration repository.
Using SQL*Plus to List Parameters
If you simply want a list of PL/SQL parameters, use SQL*Plus. At the SQL*Plus prompt, use the describe command followed by the database package name, period, and the name of the API. For example, to list the parameters for the create_grade_rate_value API, enter the following at the SQL> prompt:
describe hr_grade_api.create_grade_rate_value
Parameter Names
Each API has a number of parameters that may or may not be specified. Most parameters map onto a database column in the HR schema. There are some control parameters that affect the processing logic that are not explicitly held on the database.
Every parameter name starts with p_. If the parameter maps onto a database column, the remaining part of the name is usually the same as the column name. Some names may be truncated due to the 30 character length limit. The parameter names have been made slightly different to the actual column name, using a p_ prefix, to avoid coding conflicts when a parameter and the corresponding database column name are both referenced in the same section of code.
When a naming conflict occurs between parameters, a three-letter short code (identifying the database entity) is included in the parameter name. Sometimes there is no physical name conflict, but the three-letter short code is used to avoid any confusion over the entity with which the parameter is associated.
For example, create_employee contains examples of both these cases. Part of the logic to create a new employee is to insert a person record and insert an assignment record. Both these entities have an object_version_number. The APIs returns both object_version_number values using two OUT parameters. Both parameters cannot be called p_object_version_number, so p_per_object_version_number holds the value for the person record and p_asg_object_version_number holds the value for the assignment record.
Both these entities can have text comments associated with them. When any comments are passed into the create_employee API, they are only noted against the person record. The assignment record comments are left blank.
To avoid any confusion over where the comments have allocated in the database, the API returns the id using the p_per_comment_id parameter.
Parameter Named Notation
When calling the APIs, it is strongly recommended that you use "Named Notation," instead of "Positional Notation." Thus, you should list each parameter name in the call instead of relying on the parameter list order.
Using "Named Notation" helps protect your code from parameter interface changes. With future releases, it eases code maintenance when parameters are added or removed from the API.
For example, consider the following procedure declaration:
procedure change_age
(p_name in varchar2
,p_age in number
;
Calling by 'Named Notation':
begin
change_age
(p_name => 'Bloggs'
,p_age => 21
);
end;
Calling by 'Positional Notation':
begin
change_age
('Bloggs'
,21
);
end;
Using Default Parameter Values
When calling an API it may not be necessary to specify every parameter. Where a PL/SQL default value has been specified it is optional to specify a value.
If you want to call the APIs from your own forms, then all parameters in the API call must be specified. You cannot make use of the PL/SQL declared default values because the way Forms calls server-side PL/SQL does not support this.
Default Parameters with Create Style APIs
For APIs that create new data in the HR schema, optional parameters are usually identified with a default value of null. After validation has been completed, the corresponding database columns will be set to null. When calling the API, you must specify all the parameters that do not have a default value defined.
However, some APIs contain logic to derive some attribute values. When you pass in the PL/SQL default value the API determines a specific value to set on the database column. You can still override this API logic by passing in your own value instead of passing in a null value or not specifying the parameter in the call.
Take care with IN OUT parameters, because you must always include them in the calling parameter list. As the API can pass values out, you must use a variable to pass values into this type of parameter.
These variables must be set with your values before calling the API. If you do not want to specify a value for an IN OUT parameter, use a variable to pass a null value to the parameter.
Important: Check the comments in each API package header creation script for details of when each IN OUT parameter can and cannot be set with a null value.
The create_employee API contains examples of all these different types of parameter.
procedure create_employee
(
...
,p_sex in varchar2
,p_person_type_id in number
default null
...
,p_email_address in varchar2
default null
,p_employee_number in out varchar2
...
,p_person_id out number
,p_assignment_id out number
,p_per_object_version_number out number
,p_asg_object_version_number out number
,p_per_effective_start_date out date
,p_per_effective_end_date out date
,p_full_name out varchar2
,p_per_comment_id out number
,p_assignment_sequence out number
,p_assignment_number out varchar2
,p_name_combination_warning out boolean
,p_assign_payroll_warning out boolean
,p_orig_hire_warning out boolean
);
Because no PL/SQL default value has been defined, the p_sex parameter must be set. The p_person_type_id parameter can be passed in with the ID of an Employee person type. If you do not provide a value, or explicitly pass in a null value, the API sets the database column to the ID of the active default employee system person type for the business group. The comments in each API package header creation script provide more information.
The p_email_address parameter does not have to be passed in. If you do not specify this parameter in your call, a null value is placed on the corresponding database column. (This is similar to the user of a form leaving a displayed field blank.)
The p_employee_number parameter must be specified in each call. When you do not want to set the employee number, the variable used in the calling logic must be set to null. (For the p_employee_number parameter, you must specify a value for the business group when the method of employee number generation is set to manual. Values are only passed out when the generation method is automatic or national identifier.)
Example 1
An example call to the create_employee API where the business group method of employee number generation is manual, the default employee person type is required and the e-mail attributes do not need to be set.
declare
l_emp_num varchar2(30);
l_person_id number;
l_assignment_id number;
l_per_object_version_number number;
l_asg_object_version_number number;
l_per_effective_start_date date;
l_per_effective_end_date date;
l_full_name varchar2(240);
l_per_comment_id number;
l_assignment_sequence number;
l_assignment_number varchar2(30);
l_name_combination_warning boolean;
l_assign_payroll_warning boolean;
l_orig_hire_warning boolean;
begin
--
-- Set variable with the employee number value,
-- which is going to be passed into the API.
--
l_emp_num := 4532;
--
-- Put the new employee details in the database
-- by calling the create_employee API
--
hr_employee.create_employee
(p_hire_date =>
to_date('06-06-1996','DD-MM-YYYY')
,p_business_group_id => 23
,p_last_name => 'Bloggs'
,p_sex => 'M'
,p_employee_number => l_emp_num
,p_person_id => l_person_id
,p_assignment_id => l_assignment_id
,p_per_object_version_number => l_per_object_version_number
,p_asg_object_version_number => l_asg_object_version_number
,p_per_effective_start_date => l_per_effective_start_date
,p_per_effective_end_date => l_per_effective_end_date
,p_full_name => l_full_name
,p_per_comment_id => l_per_comment_id
,p_assignment_sequence => l_assignment_sequence
,p_assignment_number => l_assignment_number
,p_name_combination_warning => l_name_combination_warning
,p_assign_payroll_warning => l_assign_payroll_warning
,p_orig_hire_warning => l_orig_hire_warning
);
end;
Note: The database column for employee_number is defined as varchar2 to allow for when the business group method of employee_number generation is set to National Identifier.
Example 2
An example call to the create_employee API where the business group method of employee number generation is Automatic, a non-default employee person type must be used and the email attribute details must be held.
declare
l_emp_num varchar2(30);
l_person_id number;
l_assignment_id number;
l_per_object_version_number number;
l_asg_object_version_number number;
l_per_effective_start_date date;
l_per_effective_end_date date;
l_full_name varchar2(240);
l_per_comment_id number;
l_assignment_sequence number;
l_assignment_number varchar2(30);
l_name_combination_warning boolean;
l_assign_payroll_warning boolean;
l_orig_hire_warning boolean;
begin
--
-- Clear the employee number variable
--
l_emp_num := null;
--
-- Put the new employee details in the database
-- by calling the create_employee API
--
hr_employee.create_employee
(p_hire_date =>
to_date('06-06-1996','DD-MM-YYYY')
,p_business_group_id => 23
,p_last_name => 'Bloggs'
,p_sex => 'M'
,p_person_type_id => 56
,p_email_address => 'bloggsf@uk.uiq.com'
,p_employee_number => l_emp_num
,p_person_id => l_person_id
,p_assignment_id => l_assignment_id
,p_per_object_version_number => l_per_object_version_number
,p_asg_object_version_number => l_asg_object_version_number
,p_per_effective_start_date => l_per_effective_start_date
,p_per_effective_end_date => l_per_effective_end_date
,p_full_name => l_full_name
,p_per_comment_id => l_per_comment_id
,p_assignment_sequence => l_assignment_sequence
,p_assignment_number => l_assignment_number
,p_name_combination_warning => l_name_combination_warning
,p_assign_payroll_warning => l_assign_payroll_warning
,p_orig_hire_warning => l_orig_hire_warning
);
--
-- The l_emp_num variable is now set with the
-- employee_number allocated by the HR system.
--
end;
Default Parameters with Update Style APIs
With update style APIs the primary key and object version number parameters are usually mandatory. In most cases it is not necessary provide all the parameter values. You only need to specify any control parameters and the attributes you are actually altering. It is not necessary (but it is possible) to pass in the existing values of attributes that are not being modified. Optional parameters have one of the following PL/SQL default values, depending on the datatype as shown in the following table:
| Data Type | Default value |
|---|---|
| varchar2 | hr_api.g_varchar2 |
| number | hr_api.g_number |
| date | hr_api.g_date |
These hr_api.g_ default values are constant definitions, set to special values. They are not hard coded text strings. If you need to specify these values, use the constant name, not the value. The actual values are subject to change.
Care must be taken with IN OUT parameters, because they must always be included in the calling parameter list. As the API is capable of passing values out, you must use a variable to pass values into this type of parameter. These variables must be set with your values before calling the API. If you do not want to explicitly modify that attribute you should set the variable to the hr_api.g_... value for that datatype. The update_emp_asg_criteria API contains examples of these different types of parameters.
procedure update_emp_asg_criteria
(...
,p_assignment_id in number
,p_object_version_number in out number
...
,p_position_id in number
default hr_api.g_number
...
,p_special_ceiling_step_id in out number
...
,p_employment_category in varchar2
default hr_api.g_varchar2
,p_effective_start_date out date
,p_effective_end_date out date
,p_group_name out varchar2
,p_org_now_no_manager_warning out boolean
,p_other_manager_warning out boolean
,p_spp_delete_warning out boolean
,p_entries_changed_warning out varchar2
,p_tax_district_changed_warning out boolean
);
Note: Only the parameters that are of particular interest have been shown. Ellipses (...) indicate where irrelevant parameters to this example have been omitted.
The p_assignment_id and p_object_version_number parameters are mandatory and must be specified in every call. The p_position_id parameter is optional. If you do not want to alter the existing value, then exclude the parameter from your calling logic or pass in the hr_api.g_varchar2 constant or pass in the existing value.
The p_special_ceiling_step_id parameter is IN OUT. With certain cases the API sets this attribute to null on the database and the latest value is passed out of the API. If you do not want to alter this attribute, set the calling logic variable to hr_api.g_number.
Example
The following is an example call to the update_emp_asg_criteria API, with which you do not want to alter the position_id and special_ceiling_step_id attributes, but you do want to modify the employment_category value.
declare
l_assignment_id number;
l_object_version_number number;
l_special_ceiling_step_id number;
...
begin
l_assignment_id := 23121;
l_object_version_number := 4;
l_special_ceiling_step_id := hr_api.g_number;
hr_assignment_api.update_emp_asg_criteria
(...
,p_assignment_id => l_assignment_id
,p_object_version_number => l_object_version_number
...
,p_special_ceiling_step_id => l_special_ceiling_step_id
...
,p_employment_category => 'FT'
...
);
--
-- As p_special_ceiling_step_id is an IN OUT parameter the
-- l_special_ceiling_step_id variable is now set to the same -- value as on the database. i.e. The existing value before -- the API was called or the value which was derived by the -- API. The variable will not be set to hr_api.g_number.
--
end;
Default Parameters with Delete Style APIs
Most delete style APIs do not have default values for any attribute parameters. In rare cases parameters with default values work in a similar way to those of update style APIs.
Parameters with NOCOPY
Starting from Applications Release 11.5.9, many PL/SQL APIs have been enhanced to make use of the PL/SQL pass by reference feature. The NOCOPY compiler directive is defined with OUT and IN OUT parameters. This improves run-time performance and reduces memory usage.
For the majority of calling programs, when an API with or without NOCOPY is called with valid data values, there will be no noticeable difference in behavior. However, there are some subtle differences, which calling programs need to take into consideration.
Use Different Variables
When calling a PL/SQL API, ensure that different variables are used to capture values returned from the OUT and IN OUT parameters. Using the same variable with multiple OUT parameters, or an IN only parameter and also an OUT parameter, can lead to the API behaving incorrectly. In some circumstances this can cause data corruption. Even if you are not interested in knowing or processing the returned value you must use different variables.
Error Processing
At the start of any procedure call, PL/SQL sets the variables from the calling program used with OUT only NOCOPY parameters to null. If a validation issue or other problem is detected by the API, an error is raised as a PL/SQL exception. Any OUT parameter values that the API has calculated before the error is detected are cleared with null. This ensures that the variables in the calling program used with the OUT parameters do not contain any misleading values.
When NOCOPY has not been specified, the variables contain the values that existed immediately before the procedure call began. This difference in behavior is noticed only by calling programs that contain an exception handler and that attempt to read the variable expecting to see the value that the variable contained before the call.
If the calling program needs to know the variable value that existed before the API was called, you must declare and populate a separate variable.
There is no change to the behavior of IN only and IN OUT parameters, regardless of the existence of the NOCOPY compiler directive. After an error occurs, the variable used with the IN or IN OUT parameter holds the value that existed immediately before the procedure call began.
Understanding the p_validate Control Parameter
Every published API includes the p_validate control parameter. When this parameter is set to FALSE (the default value), the procedure executes all validation for that business function. If the operation is valid, the database rows/values are inserted or updated or deleted. Any non warning OUT parameters, warning OUT parameters and IN OUT parameters are all set with specific values.
When the p_validate parameter is set to TRUE, the API only checks that the operation is valid. It does so by issuing a savepoint at the start of the procedure and rolling back to that savepoint at the end. You do not have access to these internal savepoints. If the procedure is successful, without raising any validation errors, then non-warning OUT parameters are set to null, warning OUT parameters are set to a specific value, and IN OUT parameters are reset to their IN values.
In some cases you may want to write your PL/SQL routines using the public API procedures as building blocks. This enables you to write routines specific to your business needs. For example, say that you have a business requirement to apply a DateTracked update to a row and then apply a DateTrack delete to the same row in the future. You could write an "update_and_future_del" procedure that calls two of the standard APIs.
When calling each standard API, p_validate must be set to false. If true is used the update procedure call is rolled back. So when the delete procedure is called, it is working on the non-updated version of the row. However when p_validate is set to false, the update is not rolled back. Thus, the delete call operates as if the user really wanted to apply the whole transaction.
If you want to be able to check that the update and delete operation is valid, you must issue your own savepoint and rollback commands. As the APIs do not issue any commits, there is no danger of part of the work being left in the database. It is the responsibility of the calling code to issue commits. The following simulates some of the p_validate true behavior.
Example
[Dummy text - remove in Epic]
savepoint s1;
update_api_prc(.........);
delete_api_prc(..........);
rollback to s1;
You should not use our API procedure names for the savepoint names. An unexpected result may occur if you do not use different names.
Understanding the p_effective_date Control Parameter
Most APIs that insert/update/delete data for at least one DateTrack entity have a p_effective_date control parameter. This mandatory parameter defines the date you want an operation to be applied from. The PL/SQL datatype of this parameter is date.
As the smallest unit of time in DateTrack is one day, the time portion of the p_effective_date parameter is not used. This means that the change always comes into effect just after midnight.
Some APIs have a more specific date for processing. For example, the create_employee API does not have a p_effective_date parameter. The p_hire_date parameter is used as the first day the person details come into effect.
Example 1
This example creates a new grade rate that starts from today.
hr_grade_api.create_grade_rate_value
(...
,p_effective_date => trunc(sysdate)
...);
Example 2
This example creates a new employee who joins the company at the start of March 1997.
hr_employee_api.create_employee
(...
,p_hire_date => to_date('01-03-1997','DD-MM-YYYY')
...);
Some APIs that do not modify data in DateTrack entities still have a p_effective_date parameter. The date value is not used to determine when the changes take effect. It is used to validate Lookup values. Each Lookups value can be specified with a valid date range. The start date indicates when the value can first be used. The end date shows the last date the value can be used on new records and set when updating records. Existing records, which are not changed, can continue to use the Lookup after the end date.
Understanding the p_datetrack_update_mode Control Parameter
Most APIs that update data for at least one DateTrack entity have a p_datetrack_update_mode control parameter. It enables you to define the type of DateTrack change to be made. This mandatory parameter must be set to one of the values in the following table:
| p_datetrack_update_mode Value | Description |
|---|---|
| UPDATE | Keep history of existing information |
| CORRECTION | Correct existing information |
| UPDATE_OVERRIDE | Replace all scheduled changes |
| UPDATE_CHANGE_INSERT | Insert this change before next scheduled change |
It may not be possible to use every mode in every case. For example, if there are no existing future changes for the record you are changing, the DateTrack modes UPDATE_OVERRIDE and UPDATE_CHANGE_INSERT cannot be used.
Some APIs that update DateTrack entities do not have a p_datetrack_update_mode parameter. These APIs automatically perform the DateTrack operations for that business operation.
Each dated instance for the same primary key has a different object_version_number. When calling the API the p_object_version_number parameter should be set to the value that applies as of the date for the operation (that is, p_effective_date).
Example
Assume grade rate values shown in the following table already exist in the pay_grade_rules_f table:
| Grade_rule_id | Effective Start_Date | Effective_ End_Date | Object_Version_ Number | Value |
|---|---|---|---|---|
| 12122 | 01-JAN-1996 | 20-FEB-1996 | 2 | 45 |
| 12122 | 21-FEB-1996 | 20-JUN-1998 | 3 | 50 |
Also assume that the grade rate value was updated to the wrong value on 21-FEB-1996. The update from 45 to 50 should have been 45 to 55 and you want to correct the error.
declare
l_object_version_number number;
l_effective_start_date date;
l_effective_end_date date;
begin
l_object_version_number := 3;
hr_grade_api.update_grade_rate_value
(p_effective_date => to_date('21-02-1996','DD-MM-YYYY')
,p_datetrack_update_mode => 'CORRECTION'
,p_grade_rule_id => 12122
,p_object_version_number => l_object_version_number
,p_value => 55
,p_effective_start_date => l_effective_start_date
,p_effective_end_date => l_effective_end_date
);
-- l_object_version_number will now be set to the value
-- as on database row, as of 21st February 1996.
end;
Understanding the p_datetrack_delete_mode Control Parameter
Most APIs that delete data for at least one DateTrack entity have a p_datetrack_delete_mode control parameter. It enables you to define the type of DateTrack deletion to be made. This mandatory parameter must be set to one of the values in the following table:
| p_datetrack_delete_mode Value | Description |
|---|---|
| ZAP | Completely remove from the database |
| DELETE | Set end date to effective date |
| FUTURE_CHANGE | Remove all scheduled changes |
| DELETE_NEXT_CHANGE | Remove next change |
It may not be possible to use every mode in every case. For example, if there are no existing future changes for the record you are changing, the DateTrack modes FUTURE_CHANGE and DELETE_NEXT_CHANGE cannot be used. Some APIs that update DateTrack entities do not have a p_datetrack_delete_mode parameter. These APIs automatically perform the DateTrack operations for that business operation. Refer to the comments in each API package header creation script for further details.
Each dated instance for the same primary key has a different object_version_number. When calling the API the p_object_version_number parameter should be set to the value that applies as of the date for the operation (that is, p_effective_date).
Example
Assume that the grade rate values shown in the following table already exist in the pay_grade_rules_f table:
| Grade_rule_id | Effective_ Start_Date | Effective_ End_Date | Object_Version_ Number | Value |
|---|---|---|---|---|
| 5482 | 15-JAN-1996 | 23-MAR-1996 | 4 | 10 |
| 5482 | 24-MAR-1996 | 12-AUG-1996 | 8 | 20 |
Also assume that you want to remove all dated instances of this grade rate value from the database.
declare
l_object_version_number number;
l_effective_start_date date;
l_effective_end_date date;
begin
l_object_version_number := 4;
hr_grade_api.update_grade_rate_value
(p_effective_date => to_date('02-02-1996', 'DD-MM-YYYY')
,p_datetrack_delete_mode => 'ZAP'
,p_grade_rule_id => 5482
,p_object_version_number => l_object_version_number
,p_effective_start_date => l_effective_start_date
,p_effective_end_date => l_effective_end_date
);
-- As ZAP mode was used l_object_version_number now is null.
end;
Understanding the p_effective_start_date and p_effective_end_date Parameters
Most APIs that insert/delete/update data for at least one DateTrack entity have the p_effective_start_date and p_effective_end_date control parameters.
Both of these parameters are defined as OUT.
The values returned correspond to the effective_start_date and effective_end_date database column values for the row that is effective as of p_effective_date.
These parameters are set to null when all the DateTracked instances of a particular row are deleted from the database (that is, when a delete style API is called with a DateTrack mode of ZAP).
Example
Assume that the grade rate values in the following table already exist in the pay_grade_rules_f table:
| Grade_rule_id | Effective_ Start_Date | Effective_ End_Date |
|---|---|---|
| 17392 | 01-FEB-1996 | 24-MAY-1996 |
| 17392 | 25-MAY-1996 | 01-SEP-1997 |
The update_grade_rate_value API is called to perform a DateTrack mode of UPDATE_CHANGE_INSERT with an effective date of 10-MAR-1996. The API then modifies the database rows as shown in the following table:
| Grade_rule_id | Effective_ Start_Date | Effective_ End_Date |
|---|---|---|
| 17392 | 01-FEB-1996 | 09-MAR-1996 |
| 17392 | 10-MAR-1996 | 24-MAY-1996 |
| 17392 | 25-MAY-1996 | 01-SEP-1997 |
The API p_effective_start_date parameter is set to 10-MAR-1996 and p_effective_end_date to 24-MAY-1996.
Understanding the p_language_code Parameter
The p_language_code parameter is only available on create and update style Multilingual Support APIs. It enables you to specify which language the translation values apply to. The parameter can be set to the base or any installed language. The parameter default value of hr_api.userenv_lang is equivalent to:
select userenv('LANG')
from dual;
If this parameter is set to null or hr_api.g_varchar2, the hr_api.userenv_lang default is still used.
See: Multilingual Support
API Features
Commit Statements
None of the HRMS APIs issue a commit. It is the responsibility of the calling code to issue commit statements. This ensures that parts of a transaction are not left in the database. If an error occurs, the whole transaction is rolled back. Therefore API work is either all completed or none of the work is done. You can use the HRMS APIs as "building blocks" to construct your own business functions. This gives you the flexibility to issue commits where you decide.
It also avoids conflicts with different client tools. For example, Oracle Forms only issues a commit if all the user's changes are not in error. This could be one or more record changes, which are probably separate API calls.
Avoiding Deadlocks
If calling more than one API in the same commit unit, take care to ensure deadlock situations do not happen. Deadlocks should be avoided by accessing the tables in the order they are listed in the table locking ladder. For example, you should update or delete rows in the table with the lowest Processing Order first.
If more than one row in the same table is being touched, then lock the rows in ascending primary key order. For example, if you are updating all the assignments for one person, then change the row with the lowest assignment_id first.
If it is impossible or impractical for operations to be done in locking ladder order, explicit locking logic is required. When a table is brought forward in the processing order, any table rows that have been jumped and will be touched later must be explicitly locked in advance. Where a table is jumped and none of the rows are going to be updated or deleted, no locks should be taken on that table.
Example
Assume that the locking ladder order is as shown in the following table:
| Table | Processing Order |
|---|---|
| A | 10 |
| B | 20 |
| C | 30 |
| D | 40 |
Also assume that your logic has to update rows in the following order:
| A | 1st |
| D | 2nd |
| C | 3rd |
Then your logic should:
-
Update rows in table A.
-
Lock rows in table C. (Only need to lock the rows that are going to be updated in step 4.)
-
Update rows in table D.
-
Update rows in table C.
Table B is not locked because it is not accessed after D. Your code does not have to explicitly lock rows in tables A or D, because locking is done as one of the first steps in the API.
In summary, you can choose the sequence of updates or deletes, but table rows must be locked in the order shown by the table locking ladder.
Flexfields with APIs
APIs validate the Descriptive Flexfield and Key Flexfield column values using the Flexfield definitions created using the Oracle Application Object Library Forms.
As the API Flexfield validation is performed within the database, the value set definitions should not refer directly to Forms objects such as fields. Server-side validation cannot resolve these references so any checks will fail. Care should also be taken when referencing profiles, as these values may be unavailable in the server-side.
Even where the Forms do not currently call the APIs to perform their commit time processing, it is strongly recommended that you do not directly refer to any Form fields in your value set definitions. Otherwise problems may occur with future upgrades. If you want to perform other field validation or perform Flexfield validation that cannot be implemented in values sets, use API User Hooks.
See: API User Hooks
For further information about, and solutions to, some problems that you may encounter with flexfield validation, see: Validation of Flexfield Values.
The APIs do not enforce Flexfield value security. This can only be done when using the Forms user interface.
For each Descriptive Flexfield, Oracle Applications has defined a structure column. In most cases the structure column name ends with the letters, or is called, "ATTRIBUTE_CATEGORY". The implementation team can associate this structure column with a reference field. The structure column value can affect which Flexfield structure is for validation. When reference fields are defined and you want to call the APIs, it is your responsibility to populate and update the ATTRIBUTE_CATEGORY value with the reference field value.
For Descriptive Flexfields, the APIs usually perform the Flexfield validation after other column validation for the current table. For Key Flexfield segments, values are held on a separate table, known as the combination table. As rows are maintained in the combination table ahead of the main product table, the APIs execute the Flexfield validation before main product table column validation.
In Release 11.0 and before, it was necessary to edit copies of the skeleton Flexfield validation package body creation scripts before the APIs could perform Flexfield validation. The technology constraints that made this technique necessary have now been lifted. These skeleton files *fli.pkb are no longer shipped with the product.
Multilingual Support
Several entities in the HRMS schema provide Multilingual Support (MLS), where translated values are held in _TL tables. For general details of the MLS concept refer to the following documentation:
See: Oracle Applications Concepts Manual for Principles of MLS, and Oracle Applications Install Guide for Configuration of MLS.
As the non-translated and translated values are identified by the same surrogate key ID column and value, the Multilingual Support APIs manage both groups of values in the same PL/SQL procedure call.
Create and update style APIs have a p_language_code parameter which you use to indicate which language the translated values apply to. The API maintains the required rows in the _TL table, setting the source_lang and language columns appropriately. These columns, and the p_language_code parameter, hold a language_code value from the FND_LANGUAGES table.
The p_language_code parameter has a default value of hr_api.userenv_lang, which is equivalent to:
select userenv('LANG')
from dual;
Setting the p_language_code parameter enables you to maintain translated data for different languages within the same database session. If this parameter is set to null or hr_api.g_varchar2 then the hr_api.userenv_lang default is still used.
When a create style Multilingual Support API is called, a row is inserted into the _TL table for each base and installed language. For each row, the source_lang column equals the p_language_code parameter and the translated column values are the same. When the other translated values are available they can be set by calling the update API, setting the p_language_code parameter to the appropriate language code.
Each call to an update style Multilingual Support API can amend the non-translated values and one set of translated values. The API updates the non-translated values in the main table and translated data values on corresponding row, or rows, in the _TL table. The translated columns are updated on rows where the p_language_code parameter matches the language or source_lang columns. Including a matching against the source_lang column ensures translations that have not been explicitly set remain synchronised with the created language. When a translation is being set for the first time the source_lang column is also updated with the p_language_code value. If you want to amend the values for another translation, call the update API again setting the p_language_code and translated parameters appropriately.
For delete style Multilingual Support APIs there is no p_language_code parameter. When the non-translated data is removed, all corresponding translation rows in the _TL table are also removed. So the API does not need to perform the process for a particular language.
When a Multilingual Support API is called more than one row may be processed in the _TL table. To avoid identifying every row that will be modified, _TL tables do not have an object_version_number column. The main table, holding the non-translated values, does have an object_version_number column. When you use a Multilingual Support API, set the p_object_version_number parameter to the value from the main table, even when only updating translated values.
Alternative APIs
In some situations it is possible to perform the same business process using more than one API. This is especially the case where entities hold extra details for different legislations. Usually there is a main API, which can be used for any legislation, and also specific versions for some legislations. Whichever API is called, the same validation and changes are made to the database.
For example, there is an entity to hold addresses for people. For GB style addresses some of the general address attributes are used to hold specific details, as shown in the following table:
| PER_ADDRESSES Table Column Name | create_person_address API Parameter Name | create_gb_person_ address API Parameter Name |
|---|---|---|
| style | p_style | N/A |
| address_line1 | p_address_line1 | p_address_line1 |
| address_line2 | p_address_line2 | p_address_line2 |
| address_line3 | p_address_line3 | p_address_line3 |
| town_or_city | p_town_or_city | p_town |
| region_1 | p_region_1 | p_county |
| region_2 | p_region_2 | N/A for this style |
| region_3 | p_region_3 | N/A for this style |
| postal_code | p_postal_code | p_postcode |
| country | p_country | p_country |
| telephone_number_1 | p_telephone_number_1 | p_telephone_number |
| telephone_number_2 | p_telephone_number_2 | N/A for this style |
| telephone_number_3 | p_telephone_number_3 | N/A for this style |
Note: Not all database columns names or API parameters have been listed.
The p_style parameter does not exist on the create_gb_person_address API because this API only creates addresses for one style.
Not all of the address attributes are used in every style. For example, the region_2 attribute cannot be set for a GB style address. Hence, there is no corresponding parameter on the create_gb_person_address API. When the create_person_address API is called with p_style set to "GB" then p_region_2 must be null.
Both interfaces are provided to give the greatest flexibility. If your company only operates in one location, you may find it more convenient to call the address style interface that corresponds to your country. If your company operates in various locations and you want to store the address details using the local styles, you may find it more convenient to call the general API and specify the required style on creation.
Refer to comments in each API package header creation script for further details of where other alternative interfaces are provided.
See also: User Hooks and Alternative Interface APIs
API Errors and Warnings
Failure Errors
When calling APIs, validation or processing errors may occur. These errors are raised like any other PL/SQL error in Oracle applications.
When an error is raised, all the work done by that single API call is rolled back. As the APIs do not issue any commits, there is no danger that part of the work will be left in the database. It is the responsibility of the calling code to issue commits.
Warning Values
Warnings are returned using OUT parameters. The names of these parameters ends with _WARNING. In most cases the datatype is boolean. When a warning value is raised, the parameter is set to true. Other values are returned when the datatype is not boolean. Refer to the comments in each API package header creation script for further details.
The API assumes that although a warning situation has been flagged, it is acceptable to continue. If there was risk of a serious data problem, a PL/SQL error would have been raised and processing for the current API call would have stopped.
However, in your particular organization you may need to make a note about the warning or perform further checks. If you do not want the change to be kept in the database while this is done, you will need to explicitly roll back the work the API performed.
Example
When the create_employee API is called, the p_name_combination_warning parameter is set to true when person details already in the database include the same combination of last_name, first_name and date_of_birth.
declare
l_name_combination_warning boolean;
l_assign_payroll_warning boolean;
begin
savepoint on_name_warning;
hr_employee.create_employee
(p_validate => false
...
,p_last_name => 'Bloggs'
,p_first_name => 'Fred'
,p_date_of_birth => to_date('06-06-1964', 'DD-MM-YYYY')
...
,p_name_combination_warning => l_name_combination_warning
,p_assign_payroll_warning => l_assign_payroll_warning
);
if l_name_combination_warning then
-- Note that similar person details already exist.
-- Do not hold the details in the database until it is
-- confirmed this is really a different person.
rollback to on_name_warning;
end if;
end;
Note: It would not have been necessary to rollback the API work if the p_validate parameter had been set to true.
You should not use our API procedure names for the savepoint names. An unexpected result may occur if you do not use different names.
Handling Errors in PL/SQL Batch Processes
In a batch environment, errors raised to the batch process must be handled and recorded so that processing can continue. To aid the development of such batch processes, we provide a message table called HR_API_BATCH_MESSAGE_LINES and some APIs, as shown in the following table:
| API Name | Description |
|---|---|
| create_message_line | Adds a single error message to the HR_API_BATCH_MESSAGE_LINES table. |
| delete_message_line | Removes a single error message to the HR_API_BATCH_MESSAGE_LINES table. |
| delete_message_lines | Removes all error message lines for a particular batch run. |
For a full description of each API, refer to the comments in the package header creation script.
For handling API errors in a PL/SQL batch process it is recommended that any messages should be stored in the HR_API_BATCH_MESSAGE_LINES table.
Example PL/SQL Batch Program
Assume a temporary table has been created containing employee addresses. The addresses need to be inserted into the HR schema. The temporary table holding the address is called temp_person_address, as in the following table. It could have been populated from an ASCII file using Sql*Loader.
| Column Name | DataType |
|---|---|
| person_id | number |
| primary_flag | varchar2 |
| date_from | date |
| address_type | varchar2 |
| address_line1 | varchar2 |
| address_line2 | varchar2 |
| address_line3 | varchar2 |
| town | varchar2 |
| county | varchar2 |
| postcode | varchar2 |
| country | varchar2 |
| telephone_number | varchar2 |
Sample Code
declare
--
l_rows_processed number := 0; -- rows processed by api l_commit_point number := 20; - Commit after X successful rows
l_batch_run_number hr_api_batch_message_lines.batch_run_number%type;
l_dummy_line_id hr_api_batch_message_lines.line_id%type; l_address_id per_addresses.address_id%type;
l_object_version_number_id per_addresses.object_version_number_id%type;
--
-- select the next batch run number
--
cursor csr_batch_run_number is
select nvl(max(abm.batch_run_number), 0) + 1
from hr_api_batch_message_lines abm;
--
-- select all the temporary 'GB' address rows
--
cursor csr_tpa is
select tpa.person_id
, tpa.primary_flag
, tpa.date_from
, tpa.address_type
, tpa.address_line1
, tpa.address_line2
, tpa.address_line3
, tpa.town
, tpa.county
, tpa.postcode
, tpa.country
, tpa.telephone_number
, tpa.rowid
from temp_person_addresses tpa
where tpa.address_style = 'GB';
begin
-- open and fetch the batch run number
open csr_batch_run_number;
fetch csr_batch_run_number into l_batch_run_number;
close csr_batch_run_number;
-- open and fetch each temporary address row
for sel in csr_tpa loop
begin
-- create the address in the HR Schema
hr_person_address_api.create_gb_person_address
(p_person_id => sel.person_id
,p_effective_date => trunc(sysdate)
,p_primary_flag => sel.primary_flag
,p_date_from => sel.date_from
,p_address_type => sel.address_type
,p_address_line1 => sel.address_line1
,p_address_line2 => sel.address_line2
,p_address_line3 => sel.address_line3
,p_town => sel.town
,p_county => sel.county
,p_postcode => sel.postcode
,p_country => sel.country
,p_telephone_number => sel.telephone_number
,p_address_id => l_address_id
,p_object_version_number => l_object_version_number
);
-- increment the number of rows processed by the api
l_rows_processed := l_rows_processed + 1;
-- determine if the commit point has been reached
if (mod(l_rows_processed, l_commit_point) = 0) then
-- the commit point has been reached therefore commit
commit;
end if;
exception
when others then
--
-- An API error has occurred
-- Note: As an error has occurred only the work in the -- last API call will be rolled back. The -- uncommitted work done by previous API calls will not be -- affected. If the error is ora-20001 the fnd_message.get -- function will retrieve and substitute all tokens for -- the short and extended message text. If the error is -- not ora-20001, null will be returned.
--
hr_batch_message_line_api.create_message_line
(p_batch_run_number => l_batch_run_number
,p_api_name =>
'hr_person_address_api.create_gb_person_address'
,p_status => 'F'
,p_error_number => sqlcode
,p_error_message => sqlerrm
,p_extended_error_message => fnd_message.get
,p_source_row_information => to_char(sel.rowid)
,p_line_id => l_dummy_line_id);
end;
end loop;
-- commit any final rows
commit;
end;
You can view any errors that might have been created during the processes by selecting from the HR_API_BATCH_MESSAGE_LINES table for the batch run completed, as follows:
select * from hr_api_batch_message_lines abm where abm.batch_run_number = :batch_run_number order by abm.line_id;
WHO Columns and Oracle Alert
In many tables in Oracle Applications there are standard WHO columns. These include:
-
LAST_UPDATE_DATE
-
LAST_UPDATED_BY
-
LAST_UPDATE_LOGIN
-
CREATED_BY
-
CREATION_DATE
The values held in these columns usually refer to the Applications User who caused the database row to be created or updated. In the Oracle HRMS Applications these columns are maintained by database triggers. You cannot directly populate these columns, as corresponding API parameters have not been provided.
When the APIs are executed from an Application Form or concurrent manager session, then these columns will be maintained just as if the Form had carried out the database changes.
When the APIs are called from a SQL*Plus database session, the CREATION_DATE and LAST_UPDATE_DATE column will still be populated with the database sysdate value. As there are no application user details, the CREATED_BY, LAST_UPDATED_BY and LAST_UPDATE_LOGIN column will be set to the "anonymous user" values.
If you want the CREATED_BY and LAST_UPDATED_BY columns to be populated with details of a known application user in a SQL*Plus database session, then before executing any HRMS APIs, call the following server-side package procedure once:
fnd_global.apps_initialize
If you call this procedure it is your responsibility to pass in valid values, as incorrect values are not rejected. The above procedure should also be called if you want to use Oracle Alert and the APIs.
By using AOL profiles, it is possible to associate a HR security profile with an AOL responsibility. Care should be taken when setting the apps_initialize resp_id parameter to a responsibility associated with a restricted HR security profile. To ensure API validation is not over restrictive, you should only maintain data held within that responsibility's business group.
To maintain data in more than one business group in the same database session, use a responsibility associated with an unrestricted HR security profile.
API User Hooks
APIs in Oracle HRMS support the addition of custom business logic. We have called this feature `API User Hooks'. These hooks enable you to extend the standard business rules that are executed by the APIs. You can include your own validation rules or further processing logic and have it executed automatically whenever the associated API is executed.
Consider:
-
Customer-specific data validation
When an employee is promoted you might want to restrict the change of grade to a single step, unless they work at a specific location, or have been in the grade for longer than six months.
-
Maintenance of data held in extra customer-specific tables
You may want to store specific market or evaluation information about your employees in database tables that were not supplied by Oracle Applications.
-
Capturing the fact that a particular business event has occurred
You may want to capture the fact that an employee is leaving the enterprise to send an electronic message directly to your separate security database, so the employee's office security pass can be disabled.
User hooks are locations in the APIs where extra logic can be executed. When the API processing reaches a user hook, the main processing stops and any custom logic is executed. Then, assuming no errors have occurred, the main API processing continues.
Caution: You must not edit the API code files supplied by Oracle. These are part of the delivered product code and, if they are modified, Oracle may be unable to support or upgrade your implementation. Oracle Applications support direct calls only to the published APIs. Direct calls to any other server-side package procedures or functions that are written as part of the Oracle HRMS product set are not supported, unless explicitly specified.
Implementing API User Hooks
All the extra logic that you want to associate with APIs should be implemented as separate server-side package procedures using PL/SQL. The analysis and design of your business rules model is specific to your implementation. This essay focuses on how you can associate the rules you decide to write with the API user hooks.
After you have written and loaded into the database your server-side package, you need to associate your package with one or more specific user hooks. There are 3 special APIs to insert, update and delete this information. To create the links between the delivered APIs and the extra logic, execute the supplied pre-processor program. This looks at the data you have defined, the package procedure you want to call and builds logic to execute your PL/SQL from the specific user hooks. This step is provided to optimize the overall performance of API execution with user hooks. Effectively each API knows the extra logic to perform without needing to check explicitly.
As the link between the APIs and the extra logic is held in data, upgrades are easier to support. Where the same API user hooks and parameters exist in the new version, the pre-processor program can be executed again. This process rebuilds the extra code needed to execute your PL/SQL from the specific user hooks without the need for manual edits to Oracle applications or your own source code files.
To implement API user hooks
-
Identify the APIs and user hooks where you want to attach your extra logic.
See: Available User Hooks
-
Identify the data values available at the user hooks you intend to use.
-
Implement your extra logic in a PL/SQL server-side package procedure.
See: Implementing Extra Logic in a Separate Procedure Package
-
Register your extra PL/SQL packages with the appropriate API user hooks by calling the hr_api_hook_call_api.create_api_hook_call API. Define the mapping data between the user hook and the server-side package procedure.
-
Execute the user hook pre-processor program. This validates the parameters to your PL/SQL server-side package procedure and dynamically generates another package body directly into the database. This generated code contains PL/SQL to call the custom package procedures from the API user hooks.
Available User Hooks
API user hooks are provided in the HRMS APIs that create, maintain or delete information. For example, the create_employee and update_emp_asg_criteria APIs.
Note: User hooks are not provided in alternative interface APIs. For example, create_us_employee and create_gb_employee are both alternatives to the create_employee API. You should associate any extra logic with the main API. Also user hooks are not provided in utility style APIs such as create_message_line.
A PL/SQL script is available that lists all the different user hooks.
See: API User Hook Support Scripts
In the main APIs for HRMS there are two user hooks:
-
Before Process
-
After Process
There are different versions of these two user hooks in each API.
There is a Before Process and an After Process user hook in the create_employee API, and a different Before Process and After Process user hook in the update_person API. This enables you to link your own logic to a specific API and user hook.
Main API User Hooks

Before Process Logic
Before Process user hooks execute any extra logic before the main API processing logic modifies any data in the database. In this case, the majority of validation will not have been executed. If you implement extra logic from this type of user hook, you must remember that none of the context and data values have been validated. It is possible the values are invalid and will be rejected when the main API processing logic is executed.
After Process Logic
After Process user hooks execute any extra logic after all the main API validation and processing logic has successfully completed. All the database changes that are going to be made by the API have been made. Any values provided from these user hooks have passed the validation checks. Your extra validation can assume the values provided are correct. If the main processing logic does not finish, due to an error, the After Process user hook is not called.
Note: You cannot alter the core product logic, which is executed between the 'Before Process' and 'After Process' user hooks. You can only add extra custom logic at the user hooks.
Core Product Logic
Core Product Logic is split into a number of components. For tables that can be altered by an API there is an internal row handler code module. These rows handlers are implemented for nearly all the tables in the system where APIs are available. They control all the insert, update, delete and lock processing required by the main APIs. For example, if a main API needs to insert a new row into the PER_ALL_PEOPLE_F table it will not perform the DML itself. Instead it will execute the PER_ALL_PEOPLE_F row handler module.
Oracle Applications does not support any direct calls to these internal row handlers, as they do not contain the complete validation and processing logic. Calls are only allowed to the list of supported and published APIs as provided in Oracle Integration Repository.
See: Oracle Integration Repository Overview , Oracle Integration Repository User's Guide
Refer to the Licensing section in the API description in the integration repository to know what product license is required to use the API. Where multiple licences are specified, you only require one of them to be able to use the API. To know about user hooks and data pump support, see the Category Information section. If Extensions has the category value HRMS User Hooks provided, it indicates that Before Process and After Process user hooks points are available. Similarly, the category value DataPump support provided for Extensions indicates that data pump support is available.
See: Searching for an Interface, Oracle Integration Repository User's Guide
In each of the row handler modules three more user hooks are available, After Insert, After Update and After Delete. The user hook extra logic is executed after the validation specific to the current table columns has been successfully completed and immediately after the corresponding table DML statement.
These row handler user hooks are provided after the DML has been completed for two reasons:
-
All core product validation has been carried out. So you know that the change to that particular table is valid.
-
For inserts, the primary key value is not known until the row has actually been inserted.
Note: Although the update or delete DML statements may have been executed, the previous - before DML, column values are still available for use in any user hook logic. This is explained in more detail in a later section of this essay.
When an API inserts, updates or deletes records in more than one table there are many user hooks available for your use. For example, the create_employee API can create data in up to six different tables.
Create Employee API Summary Code Module Structure
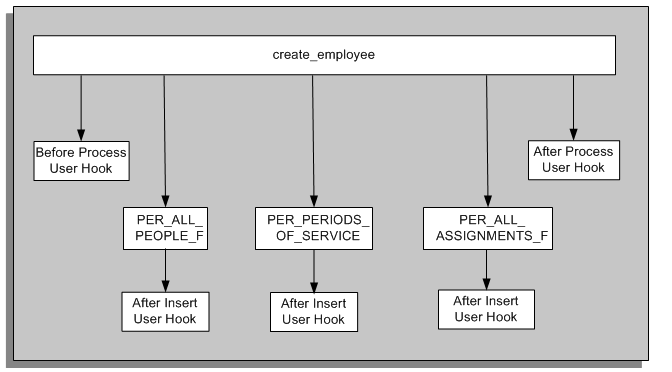
In the above diagram, create_employee is the supported and published API. Only three of the internal row handlers have been shown, PER_ALL_PEOPLE_F, PER_PERIODS_OF_SERVICE and PER_ALL_ASSIGNMENTS_F. These internal row handlers must not be called directly.
Order of user hook execution:
-
Create employee API Before Process user hook.
-
PER_ALL_PEOPLE_F row handler After Insert user hook.
-
PER_PERIODS_OF_SERVICE row handler After Insert user hook.
-
PER_ALL_ASSIGNMENT_F row handler After Insert user hook.
-
...
last) Create employee API After Process user hook.
Note: Core product validation and processing logic is executed between each of the user hooks.
When a validation or processing error is detected, processing is immediately aborted by raising a PL/SQL exception. API validation is carried out in each of the separate code modules. For example, when the create_employee API is used, validation logic is executed in each of the row handlers that are executed. Let's assume that a validation check is violated in the PER_PERIODS_OF_SERVICE row handler. The logic defined against the first two user hooks is executed. As a PL/SQL exception is raised, the 3rd and all remaining user hooks for that API call are not executed.
Note: When a DateTrack operation is carried out on a particular record, only one row handler user hook is executed. For example, when updating a person record using the DateTrack mode 'UPDATE', only the After Update user hook is executed in the PER_ALL_PEOPLE_F row handler.
The published APIs are also known as Business Processes as they perform a business event within HRMS.
Data Values Available at User Hooks
In general, where a value is known inside the API it will be available to the custom user hook code.
All values are read only. None of the values can be altered by user hook logic.
None of the AOL WHO values are available at any user hook, including:
-
LAST_UPDATE_DATE
-
LAST_UPDATED_BY
-
LAST_UPDATE_LOGIN
-
CREATED_BY
-
CREATION_DATE
The p_validate parameter value is not available at any user hook. Any additional processing should be done regardless of the p_validate value.
Data values are made available to user hook logic using individual PL/SQL procedure parameters. In most cases the parameter name matches the name of the corresponding database column name with a p_ prefix. For example, the NATIONALITY column on the PER_ALL_PEOPLE_F table has a corresponding user hook parameter name of p_nationality.
Before Process and After Process User Hook Data Values
-
IN parameter values on each published API are available at the Before Process and After Process user hooks. At the Before Process hook none of the values are validated.
-
OUT parameter values on the published API are only available from the After Process user hook. They are unavailable from the Before Process user hook because no core product logic has been executed to derive them.
-
IN OUT parameter values on the published API are available at the Before Process and After Process user hooks. The potentially invalid IN value is available at the Before Process user hook. The value passed out of the published API is available at the After Process user hook.
From the row handler After Insert user hook only column values that can be populated or are derived during insert are available.
From the After Update user hook two sets of values are available: the new values and the old values. That is, the values that correspond to the updated record and the values that existed on the record before the DML statement was executed. The new value parameter names correspond to the database column name with a p_ prefix. The old values parameter names match the database column name with a p_ prefix and a _o suffix. For example, the new value parameter name for the NATIONALITY column on the PER_ALL_PEOPLE_F table is p_nationality. The old value parameter name is p_nationality_o.
Except for the primary key ID, if a database column cannot be updated a new value parameter is not available. There is still a corresponding parameter without the _o suffix. For example, the BUSINESS_GROUP_ID column cannot be updated on the PER_ALL_PEOPLE_F table. At the After Update user hook a p_business_group_id_o parameter is available. But there is no new value p_business_group_id parameter.
From the After Delete user hooks only old values are available with _o suffix style parameter names. The primary key ID value is available with a parameter that does not have the _o suffix.
Old values are only made available at the row handler After Update and After Delete user hooks. Old values are NOT available from any of the Before Process, After Process or After Insert user hooks.
Wherever the database column name is used, the end of the name may be truncated, to fit the PL/SQL 30 character limit for parameter names.
For DateTrack table row handlers, whenever data values are made available from the After Insert, After Update or After Delete user hooks, the provided new and old values apply as of the operation's effective_date. If past or future values are required the custom logic needs to select them explicitly from the database table. The effective_start_date and effective_end_date column and DateTrack mode value are made available.
A complete list of available user hooks and the data values provided can be found by executing a PL/SQL script.
See: API User Hook Support Scripts
Implementing Extra Logic In a Separate Package Procedure
Any extra logic that you want to link to an API with a user hook must be implemented inside a PL/SQL server-side package procedure.
Note: These procedures can do anything that can be implemented in PL/SQL except `commit' and full `rollbacks'.
The APIs have been designed to perform all of the work associated with a business process. If it is not possible to complete all of the database changes then the API fails and rolls back all changes. This is achieved by not committing any values to the database within an API. If an error occurs in later processing all database changes made up to that point are rolled back automatically.
Important: Commits or full rollbacks are not allowed in any API code as they would interfere with this mechanism. This includes user-hooks and extra logic. If you attempt to issue a commit or full rollback statement, the user hook mechanism will detect this and raise its own error.
When an invalid value is detected by extra validation, you should raise an error using a PL/SQL exception. This automatically rolls back any database changes carried out by the current call to the published API. This rollback includes any changes made by earlier user hooks.
The user hook code does not support any optional or decision logic to decide when your custom code should be executed. If you link extra logic to a user hook it will always be called when that API processing point is reached. You must implement any conditional logic inside your custom package procedure. For example, suppose you want to check that `Administrators' are promoted by one grade step only with each change. As your extra logic will be called for all assignments, regardless of job type, you should decide if you need to check for the job of `Administrator' before checking the grade details.
Limitations
There are some limitations to implementing extra logic as custom PL/SQL code. Only calls to server-side package procedures are supported. But more than one package procedure can be executed from the same user hook. Custom PL/SQL cannot be executed from user hooks if it is implemented in:
-
Stand alone procedures (not defined within a package)
-
Package functions
-
Stand alone package functions (not defined within a package)
-
Package procedures that have overloaded versions
Note: Do not try to implement commit or full rollback statements in your custom PL/SQL. This will interfere with the API processing and will generate an error.
When a parameter name is defined it must match exactly the name of a data value parameter that is available at the user hooks where it will be executed. The parameter must have the same datatype as the user hook data value. Any normal implicit PL/SQL data conversions are not supported from user hooks. All the package procedure parameters must be defined as IN, without any default value. OUT and IN OUT parameters are not supported in the custom package procedure.
At all user hooks many data values are available. When implementing a custom package procedure every data value does not have to be listed. Only the data values for parameters that are required for the custom PL/SQL need to be listed.
A complete list of available user hooks, data values provided and their datatypes can be found by executing a PL/SQL script.
See: API User Hook Support Scripts
When you have completed your custom PL/SQL package you should execute the package creation scripts on the database and test that the package procedure compiles. Then test that this carries out the intended validation on a test database.
Example
A particular enterprise requires the previous last name for all married females when they are entered in the system. This requirement is not implemented in the core product, but an implementation team can code this extra validation in a separate package procedure and call it using API user hooks. When marital status is `Married' and sex is `Female', use a PL/SQL exception to raise an error if the previous last name is null. The following sample code provides a server-side package procedure to perform this validation rule.
Create Or Replace Package cus_extra_person_rules as
procedure extra_name_checks
(p_previous_last_name in varchar2
,p_sex in varchar2
,p_marital_status in varchar2
);
end cus_extra_person_rules;
/
exit;
Create Or Replace Package Body cus_extra_person_rules as
procedure extra_name_checks
(p_previous_last_name in varchar2
,p_sex in varchar2
,p_marital_status in varchar2
) is
begin
-- When the person is a married female raise an
-- error if the previous last name has not been
-- entered
if p_marital_status = 'M' and p_sex = 'F' then
if p_previous_last_name is null then
dbms_standard.raise_application_error
(num => -20999
,msg => 'Previous last name must be entered for married females'
);
end if;
end if;
end extra_name_checks;
end cus_extra_person_rules;
/
exit;
Linking Custom Procedures to User Hooks
After you have executed the package creation scripts on your intended database, link the custom package procedures to the appropriate API user hooks. The linking between user hooks and custom package procedures is defined as data in the HR_API_HOOK_CALLS table.
There are three special APIs to maintain data in this table:
-
hr_api_hook_call_api.create_api_hook_call
-
hr_api_hook_call_api.update_api_hook_call
-
hr_api_hook_call_api.delete_api_hook_call
HR_API_HOOK_CALLS
-
The HR_API_HOOK_CALLS table must contain one row for each package procedure linking to a specific user hook.
-
The API_HOOK_CALL_ID column is the unique identifier.
-
The API_HOOK_ID column specifies the user hook to link to the package procedure.
This is a foreign key to the HR_API_HOOKS table. Currently the user hooks mechanism only support calls to package procedures, so the API_HOOK_CALL_TYPE column must be set to 'PP'.
-
The ENABLED_FLAG column indicates if the user hook call should be included.
It must be set to 'Y' for Yes, or 'N' for No.
-
The SEQUENCE column is used to indicate the sequence of hook calls. Lowest numbers are processed first.
The user hook mechanism is also used by Oracle to supply application, legislation, and vertical market specific PL/SQL. The sequence numbers from 1000 to 1999 inclusive, are reserved for Oracle internal use.
You can use sequence numbers less than 1000 or greater than 1999 for custom logic. Where possible we recommend you use sequence numbers greater than 2000. Oracle specific user hook logic will then be executed first. This will avoid the need to duplicate Oracle's additional logic in the custom logic.
There are two other tables that contain data used by the API user hook mechanism, HR_API_MODULES and HR_API_HOOKS.
HR_API_MODULES Table
The HR_API_MODULES table contains a row for every API code module that contains user hooks.
| HR_API_MODULES Main Columns | Description |
|---|---|
| API_MODULE_ID | Unique identifier |
| API_MODULE_TYPE | A code value representing the type of the API code module. 'BP' for Business Process APIs - the published APIs. 'RH' for the internal Row Handler code modules. |
| MODULE_NAME | The value depends on the module type. For 'BP' the name of the published API, such as CREATE_EMPLOYEE. For 'RH' modules the name of the table, such as PER_PERIODS_OF_SERVICE. |
HR_API_HOOKS Table
The HR_API_HOOKS table is a child of the HR_API_MODULES table. It contains a record for each user hook in a particular API code module.
| HR_API_HOOKS Main Columns | Description |
|---|---|
| API_HOOK_ID | Unique identifier. |
| API_MODULE_ID | Foreign key. Parent ID to the HR_API_MODULES table. |
| API_HOOK_TYPE | Code value representing the type of user hook. |
The API_HOOK_TYPE code represents the type of user hook, as shown in the following table:
| User Hook Type | API_HOOK_TYPE |
|---|---|
| After Insert | AI |
| After Update | AU |
| After Delete | AD |
| Before Process | BP |
| After Process | AP |
Caution: Data in the HR_API_MODULES and HR_API_HOOKS tables is supplied and owned by Oracle. Oracle also supplies some data in the HR_API_HOOK_CALLS table. Customers must not modify data in these tables. Any changes you make to these tables may affect product functionality and may invalidate your support agreement with Oracle.
Note: Data in these tables may come from more than one source and API_MODULE_IDs and API_HOOK_IDs may have different values on different databases. Any scripts you write must allow for this difference.
Full details for each of these tables can be found in the Oracle HRMS electronic Technical Reference Manual (eTRM) available on My Oracle Support.
Example
For the example where you want to make sure previous name is entered, the extra validation needs to be executed whenever a new person is entered into the system. The best place to execute this validation is from the PER_ALL_PEOPLE_F row handler After Insert user hook.
The following PL/SQL code is an example script to call the create_api_hook_call API. This tells the user hook mechanism that the cus_extra_person_rules.extra_name_checks package procedure should be executed from the PER_ALL_PEOPLE_F row handler After Insert user hook.
declare
--
-- Declare cursor statements
--
cursor cur_api_hook is
select ahk.api_hook_id
from hr_api_hooks ahk
, hr_api_modules ahm
where ahm.module_name = 'PER_ALL_PEOPLE_F'
and ahm.api_module_type = 'RH'
and ahk.api_hook_type = 'AI'
and ahk.api_module_id = ahm.api_module_id;
--
-- Declare local variables
--
l_api_hook_id number;
l_api_hook_call_id number;
l_object_version_number number;
begin
--
-- Obtain the ID if the PER_ALL_PEOPLE_F
-- row handler After Insert API user hook.
--
open cursor csr_api_hook;
fetch csr_api_hook into l_api_hook_id;
if csr_api_hook %notfound then
close csr_api_hook;
dbms_standard.raise_application_error
(num => -20999
,msg => 'The ID of the API user hook was not found'
);
end if;
close csr_api_hook;
--
-- Tell the API user hook mechanism to call the
-- cus_extra_person_rules.extra_name_checks
-- package procedure from the PER_ALL_PEOPLE_F row
-- handler module 'After Insert' user hook.
--
hr_api_hook_call_api.create_api_hook_call
(p_validate => false
,p_effective_date =>
to_date('01-01-1997', 'DD-MM-YYYY')
,p_api_hook_id => l_api_hook_id
,p_api_hook_call_type => 'PP'
,p_sequence => 3000
,p_enabled_flag => 'Y'
,p_call_package =>
'CUS_EXTRA_PERSON_RULES'
,p_call_procedure => 'EXTRA_NAME_CHECKS'
,p_api_hook_call_id => l_api_hook_call_id
,p_object_version_number =>
l_object_version_number
);
commit;
end;
In this example, the previous_last_name, sex and marital_status values can be updated. If you want to perform the same checks when the marital_status is changed, then the same validation will need to be executed from the PER_ALL_PEOPLE_F After Update user hook. As the same data values are available for this user hook, the same custom package procedure can be used. Another API hook call definition should be created in HR_API_HOOK_CALLS by calling the create_api_hook_call API again. This time the p_api_hook_id parameter needs to be set to the ID of the PER_ALL_PEOPLE_F After Update user hook.
The API User Hook Pre-processor Program
Adding rows to the HR_API_HOOK_CALLS table does not mean the extra logic will be called automatically from the user hooks. You must run the API user hooks pre-processor program after the definition and the custom package procedure have both been created in the database. This looks at the calling definitions in the HR_API_HOOK_CALLS table and the parameters listed on the custom server-side package procedures.
Note: Another package body will be dynamically built in the database. This is known as the hook package body.
There is no operating system file that contains a creation script for the hook package body. It is dynamically created by the API user hook pre-processor program. Assuming the various validation checks succeed, this package will contain hard coded calls to the custom package procedures.
If no extra logic is implemented, the corresponding hook package body will still be dynamically created. It will have no calls to any other package procedures.
The pre-processor program is automatically executed at the end of some server-side Oracle install and upgrade scripts. This ensures versions of hook packages bodies exist in the database. If you do not want to use API user hooks then no further setup steps are required.
The user hook mechanism is used by Oracle to provide extra logic for some applications, legislations, and vertical versions of the products. Calls to this PL/SQL are also generated into the hook package body.
Caution: It is IMPORTANT that you do not make any direct edits to the generated hook package body. Any changes you make may affect product functionality and may invalidate your support agreement with Oracle. If you choose to make alternations, these will be lost the next time the pre-processor program is run. This will occur when the Oracle install or upgrade scripts are executed. Other developers in the implementation team could execute the pre-processor program.
If any changes are required, modify the custom packages or the calling definition data in the HR_API_HOOK_CALLS table. Then rerun the pre-processor program to generate a new version of the hook package body. For example, if you want to stop calling a particular custom package procedure then:
-
Call the hr_api_hook_call_api.update_api_hook_call API, setting the p_enabled_flag parameter to 'N'.
-
Execute the API user hook pre-processor program so the latest definitions are read again and the hook package body is dynamically recreated.
If you want to include the call again, then repeat these steps and set the p_enabled_flag parameter in the hr_api_hook_call_api.update_api_hook_call API to 'Y'.
If you want to permanently remove a custom call from a user hook then remove the corresponding calling definition. Call the hr_api_hook_call_api.delete_api_hook_call API.
Remember that the actual call from the user hook package body will be removed only when the pre-processor program is rerun.
Running the Pre-processor Program
The pre-processor program can be run in two ways.
-
Execute the hrahkall.sql script in SQL*Plus
This creates the hook package bodies for all of the different API code modules.
-
Execute the hrahkone.sql script in SQL*Plus
This creates the hook package bodies for just one API code module - one main API or one internal row handler module.
An api_module_id must be specified with this script. The required ID values are found in the HR_API_MODULES table.
Both the hrahkall.sql and hrahkone.sql scripts are stored in the $PER_TOP/admin/sql operating system directory.
Example
Continuing the previous example: After the calling definitions and custom package procedure have been successfully created in the database the api_module_id can be found with the following SQL statement:
select api_module_id
from hr_api_modules
where api_module_type = 'RH'
and module_name = 'PER_ALL_PEOPLE_F';
Then execute the hrahkone.sql script. When prompted, enter the api_module_id returned by the SQL statement above. This will generate the hook package bodies for all of the PER_ALL_PEOPLE_F row handler module user hooks After Insert, After Update and After Delete.
Log Report
Both pre-processor programs produce a log report. The hrahkall.sql script only lists errors. So if no text is shown after the 'Created on' statement, all the hook package bodies have been created without any PL/SQL or application errors. The hrahkone.sql script outputs a successful comment or error details. If any errors occurred, a PL/SQL exception is deliberately raised at the end of both scripts. This highlights to the calling program that a problem has occurred.
When errors do occur the hook package body code may still be created with valid PL/SQL. For example, if a custom package procedure lists a parameter that is not available, the hook package body is still successfully created. No code is created to execute that particular custom package procedure. If other custom package procedures need to be executed from the same user hook, code to perform those calls is still created - assuming they pass all the standard PL/SQL checks and validation checks.
Important: It is important that you check these log reports to confirm the results of the scripts. If a call could not be built the corresponding row in the HR_API_HOOK_CALLS table will also be updated. The STATUS column will be set to 'I' for Invalid Call and the ENCODED_ERROR column will be populated with the AOL application error message in the encoded format.
The encoded format can be converted into translated text by the following PL/SQL:
declare l_encoded_error varchar2(2000); l_user_read_text varchar2(2000); begin -- Substitute ??? with the value held in the -- HR_API_HOOK_CALLS.ENCODED_ERROR column. l_encoded_error := ???; fnd_message.set_encoded(encoded_error); l_user_read_text := fnd_message.get; end;
It is your responsibility to review and resolve any problems recorded in the log reports. Options:
-
Alter the parameters in the custom package procedures.
-
If required, change the data defined in the HR_API_HOOK_CALLS table.
When you have resolved any problems, rerun the pre-processor program.
The generated user hook package bodies must be less than 32K in size. This restriction is a limit in PL/SQL. If you reach this limit, you should reduce the number of separate package procedures called from each user hook. Try to combine your custom logic into fewer procedures.
Note: Each linked custom package procedure can be greater than 32K in size. Only the user hook package body that is dynamically created in the database must be less than 32K.
One advantage of implementing the API user hook approach is that your extra logic is called every time the APIs are called. This includes any HRMS Forms or Web pages that perform their processing logic by calling the APIs.
Important: The user hook mechanism that calls your custom logic is supported as part of the standard product. However the logic in your own custom PL/SQL procedures cannot be supported by Oracle Support.
Recommendations for Using the Different Types of User Hook
Consider your validation rules in two categories:
-
Data Item Rules
Rules associated with a specific field in a form or column in a table. For example, grade assigned must always be valid for the Job assigned.
-
Business Process Rules
Rules associated with a specific transaction or process. For example, when you create a secondary assignment you must include a special descriptive segment value.
Data Item Rules
The published APIs are designed to support business processes. This means that individual data items can be modified by more than one API. To perform extra data validation on specific data items (table columns), use the internal row handler module user hooks.
By implementing any extra logic from the internal row handler code user hooks, you will cover all of the cases where that column value can change. Otherwise you will need to identify all the APIs that can set or alter that database column.
Use the After Insert, After Update or After Delete user hooks for data validation. These hooks are preferred because all of the validation associated with the database table row must be completed successfully before these user hooks are executed. Any data values passed to custom logic will be valid as far as the core product is concerned.
If the hook call definition is created with a sequence number greater than 1999, then any Oracle legislation or vertical market specific logic will also have been successfully executed.
Note: If extra validation is implemented on the After Insert user hook, and the relevant data values can be updated, then you should consider excluding similar logic from the After Update user hook. Old values - before DML, are available from the After Update and After Delete user hooks.
Business Process Rules
If you want to detect that a particular business event has occurred, or you only want to perform some extra logic for a particular published API, use the Before Process and After Process user hooks.
Where possible, use the After Process user hook, as all core product validation for the whole API will have been completed. If you use the Before Process user hook you must consider that all data values could be invalid in your custom logic. None of the core product validation has been carried out at that point. References to the HR_LOOKUPS view, any views that join to HR_LOOKUPS and lookup code validation cannot be performed at the Before Process user hook. Values that affect the lookup code validation are not derived and set until after this point.
Data values provided at the Before Process and After Process user hooks will be the same as the values passed into the API. For update type business processes the API caller has to specify only the mandatory parameters and the values they actually want to change. When the API caller does not explicitly provide a parameter value, the system reserved default values will be used, as shown in the vollowing table:
| Data Type | Default Value |
|---|---|
| varchar2 | hr_api.g_varchar2 |
| number | hr_api.g_number |
| date | hr_api.g_date |
Depending on the parameters specified by the API caller, these default values may be provided to Before Process and After Process user hooks. That is, the existing column value in the database is only provided if the API calling code happens to pass the same new value. If the real database value is required then the custom package procedures must select it explicitly from the database.
This is another reason why After Update and After Delete user hooks are preferred. At the row handler user hooks the actual data value is always provided. Any system default values will have been reset with their existing database column value in the row handler modules. Any extra logic from these user hooks does need to be concerned with the system reserved default values.
If any After Process extra logic must access the old database values then a different user hook needs to be used. It will not be possible to use the After Process user hook because all the relevant database rows will have been modified and the old values will not be provided by the user hook mechanism. Where API specific extra logic requires the old values, they will need to be explicitly selected in the Before Process user hook.
User Hooks and Alternative Interface APIs
Alternative Interface APIs provide an alternative version of the generic APIs. Currently there are legislative or vertical specific versions of the generic APIs.
For example, create_us_employee and create_gb_employee are two alternative interfaces to the generic create_employee API. These alternatives make clear how specific legislative parameters are mapped onto the parameters of the generic API.
In the future other alternative APIs may be provided to support specific implementations of generic features, such as elements and input values.
Important: User hooks are not provided in alternative interface APIs. User hooks are provided only in the generic APIs. In this example the user hooks are provided in the create_employee API and not in the create_us_employee and create_gb_employee APIs.
Alternative interface APIs always perform their processing by executing the generic API and any extra logic in the generic API user hooks is executed automatically when the alternative APIs are called. This guarantees consistency in executing any extra logic and reduces the administrative effort to set up and maintain the links.
Example 1
You want to perform extra validation on the job and payroll components of employee assignments to make sure only `Machine Workers' are included in the `Weekly' payroll. There is more than one published API that allows the values to be set when a new assignment is created or an existing assignment is updated.
Tip: Implement the extra validation in a custom server-side package procedure. Link this to the two user hooks, After Insert and After Update, in the PER_ALL_ASSIGNMENTS_F table internal row handler module.
Example 2
You have a custom table and you want to create data in this table when a new employee is created in the system, or an existing applicant is converted into an employee. The data in the custom table does not need to be created in any other scenario.
Tip: Implement the third party table; insert DML statements in a custom server-side package procedure. Link this to two user hooks: After Process in the create_employee API module and After Process in the hire_applicant API module.
Comparison with Database Triggers
User hooks have a number of advantages over database triggers for implementing extra logic.
-
Database triggers can only be defined against individual table DML statements. The context of a particular business event may be unavailable at the table level because the event details are not held in any of the columns on that table.
-
Executing a database trigger is inefficient compared with executing a server-side package procedure.
-
The mutating table restriction stops values being selected from table rows that are being modified. This prevents complex multi-row validation being implemented from database triggers. This complex validation can be implemented from API user hooks, as there are no similar restrictions.
-
On DateTrack tables it is extremely difficult to implement any useful logic from database triggers. With many DateTrack modes, a single transaction may affect more than one row in the same database table. Each dated instance of a DateTrack record is physically held on a different database row.
For example, a database trigger that fires on insert cannot tell the difference between a new record being created or an insert row from a DateTrack 'UPDATE' operation.
Note: DateTrack 'UPDATE' carries out one insert and one update statement. The context of the DateTrack mode is lost at the database table level. You cannot re-derive this in a database trigger due to the mutating table restriction.
-
With DateTrack table row handler user hooks more context and data values are available. The After Insert user hook is only executed when a new record is created. The DateTrack mode name is available at After Update and After Delete user hooks. The date range over which the record is being modified is also available at these user hooks. The validation_start_date value is the first day the record is affected by the current DateTrack operation. The last day the record is affected is known as the validation_end_date.
API User Hook Support Scripts
You can create a complete list of available user hooks and the data values provided by executing the hrahkpar.sql script in SQL*Plus. This script can be found in the $PER_TOP/admin/sql operating system directory. As the output is long, it is recommended to spool the output to an operating system text file.
The user hook pre-processor program can be executed in two ways. To create the hook package bodies for all of the different API code modules, execute the hrahkall.sql script in SQL*Plus. To create the hook package bodies for just one API code module, such as one main API or one internal row handler module, execute the hrahkone.sql script in SQL*Plus. An api_module_id must be specified with this second script. The required api_module_id value can be obtained from the HR_API_MODULES table. Both the hrahkall.sql and hrahkone.sql scripts can be found in the $PER_TOP/admin/sql operating system directory.
Using APIs as Building Blocks
The API code files supplied with the product must not be edited directly for any custom use.
Caution: Any changes you make may affect product functionality and may invalidate your support agreement with Oracle and prevent product upgrades.
Oracle Applications supports direct calls to the published APIs. Direct calls to any other server-side package procedures or functions written as part of the Oracle HRMS product set are not supported, unless explicitly specified.
There are supported methods for adding custom logic, using the APIs provided. In addition to the API user hook mechanism, you can use the published APIs as building blocks to construct custom APIs.
Example
Suppose you always obtain a new employee's home address when they join your enterprise. The address details must be recorded in the HR system because you run reports that expect every employee to have an address.
You could write your own API to create new employees with an address. This API would call the standard create_employee API and then immediately afterwards call the standard create_address API.
Create Employee/Create Address APIs

With API user hooks it is not possible to change any of the data values. So the building block approach can be used to default or set any values before the published API is called.
The major disadvantage with the building block approach is that any Forms or Web pages supplied by Oracle will NOT call any custom APIs. If a user interface is required then you must also create your own custom Forms or Web pages to implement calls to your custom APIs.
Handling Object Version Numbers in Oracle Forms
If you intend to write your own Forms that call the APIs, you will need to implement additional Forms logic to correctly manage the object version number. This is required because of the way Forms can process more than one row in the same commit unit.
Example
Consider the following example of what can happen if only one form's block item is used to hold the object version number:
-
The user queries two rows and updates both.
Row OVN in Database OVN in Form A 6 6 B 3 3 -
The user presses commit.
Row A has no user errors and is validated in the API. The OVN is updated in the database and the new OVN is returned to the form.
Row OVN in Database OVN in Form A 7 7 B 3 3 -
The form calls the API again for row B.
This time there is a validation error on the user-entered change. An error message is raised in the form and Forms issues a rollback to the database. However, the OVN for row A in the form is now different from the OVN in the database.
Row OVN in Database OVN in Form A 6 7 B 3 3 -
The user corrects the problem with row B and commits again.
Now the API will error when it validates the changes to row A. The two OVNs are different.
Solution
The solution to this problem is to use a non-basetable item to hold the new version number. This item is not populated at query time.
-
The user queries two rows and updates both.
Row OVN in Database OVN in Form New_OVN in Form A 6 6 B 3 3 -
The user presses commit.
Row A is valid, so the OVN is updated in the database and the new OVN is returned to the form.
Note: The actual OVN in the form is not updated.
Row OVN in Database OVN in Form New_OVN in Form A 7 6 7 B 3 3 -
The forms calls the API again for row B.
The validation fails and an error message is raised in the form. Forms issues a rollback to the database.
Row OVN in Database OVN in Form New_OVN in Form A 6 6 7 B 3 3 -
The user corrects the problem with row B and commits again.
The API is called to validate row A again. The OVN value is passed, not the NEW_OVN. There is no error because the OVN in the database now matches the OVN it was passed. The API passes back the updated OVN value.
Row OVN in Database OVN in Form New_OVN in Form A 7 6 7 B 3 3 -
The API is called again to validate row B.
The validation is successful; the OVN is updated in the database and the new OVN value is returned to the form. The commit in the form and the database is successful.
Row OVN in Database OVN in Form New_OVN in Form A 7 6 7 B 4 3 4 What would happen when the user updates the same row again without re-querying? Following on from the previous step:
-
When the user starts to update row A, the on-lock trigger will fire.
The trigger updates the OVN when New_OVN is not null. (Theoretically the on-lock trigger will only fire if the previous commit has been successful. Therefore the New_OVN is the OVN value in the database.)
Row OVN in Database OVN in Form New_OVN in Form A 7 7 7 -
The on-lock trigger then calls the API to take out a lock using OVN.
The lock is successful as the OVN values match.
Row OVN in Database OVN in Form New_OVN in Form A 7 7 7 -
The user continues with the update, the update API is called, and the commit is successful.
Row OVN in Database OVN in Form New_OVN in Form A 8 7 8
If user does delete instead of update, the on_lock will work in the same way. When key_delrec is pressed, the delete API should be called with p_validate set to true. Doing so ensures that the delete is valid without removing the row from the database.
Therefore, the OVN value in the form should be set with the New_OVN, when New_OVN is not null. This ensures that the delete logic is called with the OVN value in the database.
However, there is another special case that has to be taken into consideration. It is possible for the user to update a row (causing a new OVN value to be returned from the API), the update of the next row in the same commit unit fails, the user navigates back to the first row and decides to delete it. To stop the new_OVN from being copied into the OVN in the form, only do the copy in key_delrec if the record_status is query.
Example Code Using the Grade Rate Values
The above descriptions are handled in the following example. In this example, <block_name>.object_version_number is a basetable item and <block_name>.new_object_version_number is non-basetable.
Forms Procedure Called from the ON-INSERT Trigger
procedure insert_row is
begin
--
-- Call the api insert routine
--
hr_grade_api.create_grade_rate_value
(<parameters>
,p_object_version_number => :<block_name>.object_version_number
,p_validate => false
);
end insert_row;
Forms Procedure Called from the ON-UPDATE Trigger
procedure update_row is
l_api_ovn number;
begin
-- Send the old object version number to the API
l_api_ovn := :<block_name>.object_version_number;
--
-- Call the api update routine
--
hr_grade_api.update_grade_rate_values
(<parameters>
,p_object_version_number => l_api_ovn
,p_validate => false
);
-- Remember the new object version number returned from the API
:<block_name>.new_object_version_number := l_api_ovn;
end update_row;
Forms Procedure Called from the ON-DELETE Trigger
procedure delete_row is
begin
--
-- Call the api delete routine
--
hr_grade_api.delete_grade_rate_values
(<parameters>
,p_object_version_number => :<block_name>.object_version_number
,p_validate => false
);
end delete_row;
Forms Procedure Called from the KEY-DELREC Trigger
procedure key_delrec_row is
l_api_ovn number;
l_rec_status varchar2(30);
begin
-- Ask user to confirm they really want to delete this row.
--
-- Only perform the delete checks if the
-- row really exists in the database.
--
l_rec_status := :system.record_status;
if (l_rec_status = `QUERY') or (l_rec_status = `CHANGED') then
--
-- If this row just updated then the
-- new_object_version_number will be not null.
-- If that commit was successful then the
-- record_status will be QUERY, therefore use
-- the new_object_version_number. If the commit
-- was not successful then the user must have
-- updated the row and then decided to delete
-- it instead. Therefore just use the
-- object_version_number.
--(Cannot just copy the new_ovn into ovn
-- because if the new_ovn does not match the
-- value in the database the error message will
-- be displayed twice. Once from key-delrec and
-- again when the on-lock trigger fires.)
--
if (:<block_name>.new_object_version_number is not null) and
(l_rec_status = 'QUERY') then
l_api_ovn := :<block_name>.new_object_version_number;
else
l_api_ovn := :<block_name>.object_version_number;
end if;
--
-- Call the api delete routine in validate mode
--
hr_grade_api.delete_grade_rate_values
(p_validate => true
,<parameters>
,p_object_version_number => l_api_ovn
,p_validate => true
);
end if;
--
delete_record;
end key_delrec_row;
Forms Procedure Called from the ON-LOCK Trigger
procedure lock_row is
l_counter number;
begin
l_counter := 0;
LOOP
BEGIN
l_counter := l_counter + 1;
--
-- If this row has just been updated then
-- the new_object_version_number will be not null.
-- That commit unit must have been successful for the
-- on_lock trigger to fire again, so use the
-- new_object_version_number.
--
if :<block_name>.new_object_version_number is not null then
:<block_name>.object_version_number :=
:<block_name>.new_object_version_number;
end if;
--
-- Call the table handler api lock routine
--
pay_grr_shd.lck
(<parameters>
,p_object_version_number => :<block_name>.object_version_number
);
return;
EXCEPTION
When APP_EXCEPTIONS.RECORD_LOCK_EXCEPTION then
APP_EXCEPTION.Record_Lock_Error(l_counter);
END;
end LOOP;
end lock_row;