Oracle Generic Third Party Payroll Backfeed
Oracle Generic Third Party Payroll Backfeed
This essay provides the information that you need to understand and use the Oracle Generic Third Party Payroll Backfeed. To understand this information you should already have a good functional and technical knowledge of the Oracle HRMS product architecture, including:
-
The data model for Oracle HRMS.
-
The API strategy and how to call APIs directly.
-
How to code PL/SQL.
-
The HRMS parameters that control the running of concurrent processes.
-
How to use and configure Data Pump.
Contents
This essay contains the following sections:
-
Provides an overview of Oracle Generic Third Party Payroll Backfeed
-
Setting Up Oracle Generic Third Party Payroll Backfeed
Describes the steps for setting up Third Party Payroll Backfeed at a high level. Each step is explained in more detail in the following sections:
-
Using Backfeed to Upload Payroll Run Results
Describes the steps for using Third Party Payroll Backfeed at a high level. Each step is explained in more detail in the following sections:
-
Viewing Third Party Payroll Run Results in Oracle HRMS
Describes how you view the payroll run results in Oracle HRMS windows.
Overview
If you use a third party payroll system, Oracle Generic Third Party Payroll Backfeed enables you to upload information supplied by your payroll system for a payroll run into the Oracle HRMS tables. This information can include payment information and balance details calculated by your third party payroll system. You can then view this information using Oracle HRMS windows and generate reports based on this information.
Backfeed Process
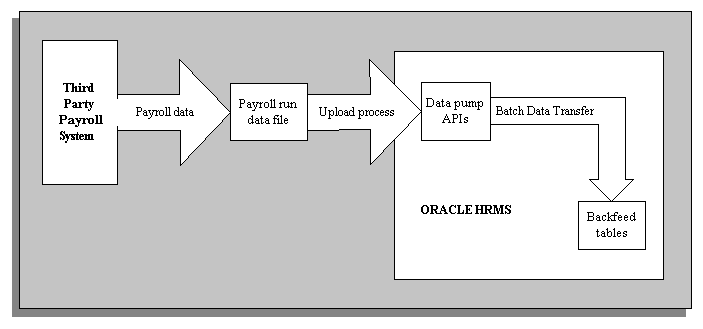
The payroll results data that is uploaded using Backfeed is held in specific Backfeed tables, not tables belonging to Oracle Payroll. This means that if you are using Oracle Payroll and a third party payroll system, your Oracle Payroll implementation is not impacted by Backfeed.
This generic version of Oracle Third Party Payroll Backfeed is vendor independent. It can be configured during implementation to fit the requirements of your third party payroll system and your HRMS implementation.
Setting Up the Generic Payroll Backfeed
To set up the Generic Payroll Backfeed, follow this sequence of tasks:
-
Install the Generic Payroll Backfeed
See: Installing the Oracle Generic Third Party Payroll Backfeed
-
Ensure that payment information is set up for Oracle HRMS if you intend to upload payment information using Backfeed.
See: Payment Information
-
Enter the names of the balance types that will be uploaded into Oracle HRMS from your third party payroll system.
See: Balance Types
-
Decide which upload option to use.
-
Set Up Data Pump.
See: Setting Up Data Pump
-
Run Data Pump Meta-Mapper.
See the Oracle HRMS Data Pump technical essay for further details.
-
Set up Data Uploader
-
Add the View Third Party Payroll Employee Run Results, View Third Party Payroll Organization Run Results and the Enter Third Party Payroll Balance Types form functions to your menus. Use the Menus window.
See: Oracle E-Business Suite System Administrator's Guide - Security
-
Create new folder definitions in the Third Party Payroll Run Employee Results window and the Third Party Payroll Run Organization Results, if required, so information relevant to your enterprise is displayed.
Installing the Oracle Generic Third Party Payroll Backfeed
Release 12 and 11i
If you are using Oracle HRMS release 12 or 11i, backfeed is supplied as part of your base installation. No further steps are required.
Release 11.0
If you are using Oracle HRMS 11.0.x you should apply the patches listed below. You can obtain these patches from My Oracle Support (formerly MetaLink).
Note: These patches are subject to change. Please contact Oracle Support for the latest information.
Install the Backfeed tables - Patch Number 1198005
This patch installs the Third Party Payroll Backfeed tables, APIs, forms, and views.
Install Data Pump - Patch Numbers 1053696 and 1077660
These patches deliver enhancements to Data Pump and some Data Pump configuration data that enables Data Pump to call the Backfeed APIs. Also included are some PL/SQL functions that resolve the Oracle HR system ids. These functions make certain assumptions about your Oracle HRMS implementation. The functions are documented in the Reference Information section of this document. If the assumptions are not valid for your implementation you will have to configure some of the scripts that are delivered by patch 1077660.
Install Data Uploader - Patch Numbers 1325570 and 1176584
These patches deliver the Data Uploader and seed data to enable you to use the Data Uploader functionality as part of your Third Party Payroll Backfeed. If you have changed the PL/SQL functions that are delivered in patch 1077660, you may need to change the seed data delivered by patch 1176584.
Install the Business Views - Patch Number 1198041
This patch delivers the business views for the Oracle Generic Third Party Payroll Backfeed. You should install this if you want to use the business views, for example to create Oracle Discoverer reports.
Payment Information
All employees for whom payments information is to be loaded using the Backfeed must have personal payment methods set up in Oracle HRMS before the Backfeed is run.
This information should be entered using the Organizational Payment Method, and the Personal Payment Method windows.
See: Payrolls and Other Employment Groups, and Employment Information, Oracle Human Resources User's Guide
While uploading payment details a currency code must be provided. This currency code must match the currency of the payment method.
Balance Types
Balances that are maintained by your third party payroll system can be loaded into the Backfeed tables. Each third party payroll balance that you want to hold in the Backfeed tables must be defined as a Backfeed balance type in Oracle HRMS before you run the Backfeed.
Note: Backfeed balance types are not the same as Oracle Payroll balance types.
Balance dimensions can be held for any of the balance types you create. The balance dimensions that can be held for each balance type are:
-
Year-to-date balance
-
Fiscal year-to-date balance
-
Period-to-date balance
-
Month-to-date balance
-
Quarter-to-date balance
-
Run amount
You must set up the balance types required by your enterprise before you upload any payroll run data to the HRMS system. When setting up your balance types you can link them to any user defined element input value. This enables you to easily generate reports that can link the balance types to their associated elements.
When uploading monetary balance amounts a currency code must be provided. This currency code must match the currency of the balance or its associated element, as appropriate. One of the following checks is done to ensure the currency of the balance details being loaded is the same as those defined for the balance type:
-
If the balance type for the amount being uploaded is associated with an element, a check is done to ensure that the amount being uploaded is in the same currency as the input currency for the associated element.
-
If the balance type for the amount being loaded is not associated with an element, a check is done to ensure that the amount being uploaded is in the same currency entered for the balance type.
Balance types must be set up using the Third Party Payroll Balance Types window.
To set up balance types:
-
Enter a display name for the balance type and enter a valid from date. If required, you can also enter a valid to date. The balance type will not be available after this date.
-
Enter an internal name. This is used to identify the balance type internally and must be unique within the Business Group.
-
Enter a category if required. This can be used to group balance types for reporting purposes. For example, you could group together all balance types relating to employee holidays in a category called Holidays.
-
Do one of the following:
-
Select a user defined element and an input value to link to the balance type. The Currency and Unit fields will be populated according to the element and input values you have selected.
-
Select a unit for the balance type and, if required, a currency.
-
-
The In Use check box indicates whether a balance type has any balance amounts recorded against it. If it does you are not permitted to change the balance type's currency, units element name or internal name.
-
Save your changes.
APIs
Data is maintained in the Backfeed tables using business process APIs. These are interfaces that enable you to create, update and delete information from the Oracle tables. These APIs call one or more row handlers. Row handlers maintain the data in a single table by validating the data being passed in before allowing it to be created, updated, or deleted. Row handlers should not be called directly.
See the APIs in Oracle HRMS technical essay for further details.
We recommend you use Data Pump to upload your third party payroll run data into the Oracle HRMS Backfeed tables. You launch Data Pump as a concurrent program from the Run Reports and Process window. Data Pump will automatically call the appropriate Backfeed APIs.
Setting Up Data Pump
One of the features of Data Pump is the ability to resolve internal id values using other information that has been passed in. Functions have to be created when implementing a Data Pump front end to resolve these ids. These functions will differ for each implementation as each enterprise maps the data in different ways depending on how they have implemented Oracle HRMS.
See the Oracle HRMS Data Pump technical essay before you attempt to configure Data Pump.
Configuring the Data Pump Front End
The Generic Payroll Backfeed uses a package called PER_BF_GEN_DATA_PUMP. This contains some functions that are used to resolve the internal system ids, such as payroll_id (the function for this is called get_payroll_id).
The function definitions are delivered in two scripts; pebgendp.pkh and pebgendp.pkb. If you are using Oracle HRMS 11.0 they are located in $PER_TOP/patch/110/sql. If you are using Oracle HRMS 11i or Release 12, they are located in $PER_TOP/patch/115/sql.
If the assumptions made by the supplied functions are not appropriate to your enterprise you will have to modify the functions to reflect the way in which you have implemented Oracle HRMS. We recommend that you make a copy of the package and make your changes to the copy.
If you do not need to alter any of the parameters in the generic functions, but need to change the body of the function, you can do this and run your amended version against your database. To do this you must navigate to the directory containing your configured script and enter the following:
sqlplus <apps_username>/<apps_pwd>@<database_name> @<package_body_name.pkb>
If, however, you need to change the parameters in the functions, or add new functions, as well as altering the package, you will have to run both scripts against the database. To do this navigate to the directory containing your configured scripts and enter the following:
sqlplus <apps_username>/<apps_pwd>@<database_name> @<package_header_name.pkh>
sqlplus <apps_username>/<apps_pwd>@<database_name> @<package_body_name.pkb>
You must also run the Data Pump Meta-Mapper. This regenerates the Data Pump APIs and views specific to the Third Party Payroll Backfeed interface. For more information on how to do this, and other Data Pump functionality that you may want to use, please refer to the Oracle HRMS Data Pump technical essay.
If you do make any changes to the parameters in the supplied generic functions, or add any new functions, you will also need to configure the Data Uploader front end.
See: Configuring the Data Uploader Front End
Deciding Which Upload Option to Use
In order to use Data Pump to upload the third party payroll run data into the Backfeed tables you must first get this data into the Data Pump batch tables. There are two alternative approaches to achieving this:
-
Use APIs generated by the Data Pump Meta-Mapper
If you decide to use this option you will need to write a PL/SQL program to read your payroll results data and insert it into the Data Pump batch tables using the Data Pump APIs.
-
Use Data Uploader
If you decide to use this option you will need to format your payroll run results data file into a flat file in a format that is readable by the Data Uploader.
You must decide which is the best approach for you based on your technical resources and the source of your payroll results data.
Setting Up Data Uploader
Data Uploader takes data held in tab delimited text files and uploads it to the Data Pump batch tables using the packages and views created when Data-Pump Meta-Mapper is run. To use Data Uploader you must get your payroll run data into tab delimited files of the format required by Data Uploader. To help you format your payroll run data files, a Microsoft Excel workbook called bfexampl.xls has been supplied. This shows how your data must be set out. Once formatted you can use the Save Sheets macro to export the data held in the Excel worksheets into the tab delimited text files used by Data Uploader. This, and the Load Sheets macro are supplied in the bfmacros.xls file.
Using Excel to Create Files
Although you can use the Excel macros during the early stages of a Backfeed implementation to create files that can be read by Data Uploader, you should stop using Excel once you are using Backfeed in a production environment. We suggest that you automate the creation of the tab delimited Data Uploader files, instead.
You can continue to use Excel for debugging purposes, if the files are small enough for Excel to handle, if problems occur when running the Data Uploader part of Backfeed.
Example Files
The example files consist of:
bfexampl.xls
-
Header Sheet. This contains basic information for the workbook such as the individual worksheet names.
-
Payroll Run Sheet. This holds details relating to the entire run such as the processing date. This contains data to be used by the the create_payroll_run API.
-
Balance Amounts Sheet. This holds the employee balance details for the run defined in the Payroll Run worksheet. This contains data to be used by the the create_balance_amount API.
-
Payment Details Sheet. This holds the employee payment details for the run defined in the Payroll Run worksheet. This contains data to be used by the create_payment_details API.
-
Processed Assignments Sheet. This holds the processed assignment details for a particular employee assignment relating to the run defined in the Payroll Run worksheet. This contains data to be used by the create_processed_assignment API.
bfmacros.xls
-
Save Sheets Macro. This is a macro that saves the individual sheets in the workbook as individual tab delimited text files
-
Load Sheets Macro. This is a macro that loads the individual text files based on the Header file.
Header Sheet
The Header Sheet contains information about the complete set of data that is to be uploaded. It defines standard information such as batch name and date, and also specifies the files that are to be used in this upload.
You must enter a batch name that will uniquely identify this upload. You will be asked for this batch name when you run the Data Pump process.
The text between the Files Start and Files End rows are the file names for the individual sheets. The first column contains the name of the sheet, and the second column contains the name of the text file. This is the name that the related sheet will be saved as, or uploaded from if you use the macros.
Payroll Run Sheet
Every payroll run has information that relates to the entire run such as processing date, periods start and end dates, and a unique identifier for the run. This worksheet contains this type of information.
At the top of the sheet, between the Descriptor Start and Descriptor End columns, the details relating to the run are held. It is likely that these will remain the same for all your data uploads.
The User Key row contains an entry that allows the Data Uploader and Data Pump functionality to uniquely refer to the payroll run that is being inserted from other sheets that need this reference, such as the Balance Amounts Sheet and the Payment Details Sheet. The default entry for this is %$Business Group%:payroll_identifier. You should not need to change this as the combination of Business Group ID and the payroll identifier should always uniquely identify a payroll run.
The ID column is the way the Data Uploader identifies a row in the spreadsheet and can be used by other sheets in the same workbook to refer to a particular row. In this case, both the Balance Amount Sheet and the Payment Details Sheet have a column called Payroll_run_id that will refer to the row in this sheet. Each row of your data should have a different, sequential number in the ID column.
Balance Amounts Sheet
The Balance Amounts worksheet holds the balance information relating to each employee for a particular payroll run.
The row beneath the the Data Start row contains the column titles of the API. Your payroll run balance amount details for each employee need to go between this row and the Data End row. A currency code must be provided for all monetary amounts.
The ID column needs to be populated with sequential numbers starting from 1.
The column named Payroll_Run_id refers to the ID column in the Payroll Run worksheet. This number will be the same for all the rows in the payroll run.
Payment Details Sheet
The Payment Amount Sheet holds the payment details for each employee processed in a payroll run.
The row beneath the the Data Start row contains the column titles of the API. Your payment details for a particular run need to go between this row and the Data End rows. You must provide a currency code for all monetary amounts.
The ID column needs to be populated with sequential numbers starting from 1.
The column named Payroll_Run_id refers to the ID column in the Payroll Run worksheet. This number will be the same for all the rows in the payroll run.
Processed Assignments Sheet
The Processed Assignment Sheet holds the assignment details for each employee processed on a payroll run.
The row beneath the Data Start row contains the column titles of the API. Your processed assignment details for a particular employee and payroll run need to go between this row and the Data End row.
The ID column needs to be populated with sequential numbers starting from 1.
The column named Payroll_Run_id refers to the ID column in the Payroll Run Worksheet. This number will be the same for all the rows in the payroll run.
This worksheet is only required if additional information is held within the processed assignment descriptive flexfield. If there is no additional information then the processed assignment will be created by the balance amount api or payment detail api.
If this worksheet is not required (for reasons mentioned above) then the name and text file for processed assignment must be removed from the header sheet.
Save Sheets Macro
This Excel macro saves the individual Worksheets as tab delimited text files. The name of each text file, with the exception of the Header Sheet, is held in the Header Sheet. You are prompted to enter a name for the Header Sheet when you run the macro.
Load Sheets Macro
To use this macro you must have a tab delimited text file of your Header Sheet. This macro loads the text files specified in the Header Sheet as worksheets into workbook from which the macro was run. The text files to be loaded must be in the same directory as the selected Header Sheet text file.
Specifying the Upload Directories for Data Uploader
You must specify the location in which files to be imported using the Data Uploader must be placed. The following steps describe the tasks that must be completed to do this:
-
In the initialization file for the database, your Database Administrator must specify the directory that will hold the files to be uploaded. This is done by including the path of the required directory in the UTL_FILE_DIR parameter.
-
Your System Administrator must enter the full path to this directory in the HR: Data Exchange Directory user profile option. Use the System Profile Values window. You can set this profile option at site, application and responsibility level, depending on the security you want to impose.
Configuring the Data Uploader Front End
The generic Data Uploader parameters are defined in a script called pedugens.sql. It is separated into different sections for creating parameters for Payroll Run, Balance Amounts etc.
If you are using Oracle HRMS 11.0 this script is located in $PER_TOP/patch/110/sql. If you are using Oracle HRMS 11i or Release 12, it is located in $PER_TOP/patch/115/sql.
If you have changed the parameters in the Data Pump functions to resolve the system ids, or added new functions and used Meta-Mapper to regenerate the Data Pump APIs, you must include a column containing the data specified in the new parameters in the appropriate sheet of your Excel upload workbook. See: Creating an Upload Workbook.
You must then amend the pedugens.sql script to map the new data in the Excel column to the API used by the Data Uploader.
The following is an example of code that is used to create the Data Uploader mapping details for the create_balance_amount API:
HRDU_DO_API_TRANSLATE.hrdu_insert_mapping(
p_api_module => 'create_balance_amount',
p_column_name => 'balance_type_name',
p_mapped_to_name => 'p_balance_type_name');
The p_api_module parameter identifies which Microsoft Excel worksheet holds the data that will be uploaded using this api. In this case it is create_balance_amount. The p_column_name parameter passes in the associated Excel worksheet column name, in this case, balance_type_name. The p_mapped_to_name parameter passes the Data Pump view column that is to be associated with the Excel worksheet, in this case p_balance_type_name.
You will need to add an insert statement for any new columns that you have added to the upload workbook, whether they are in existing or new functions.
Using Backfeed to Upload Payroll Run Results
To upload payroll run results using Backfeed, follow this sequence of tasks:
-
Save the payroll run results from your third party payroll system into a text file.
-
Create an upload workbook.
-
Format the payroll run data into the format required by Data Uploader.
See: Formatting the Payroll Run Data into the Format Required by Data Uploader
-
Use Data Uploader concurrent process to load the information from the text file into the Data Pump batch tables.
Note: If you decided not to use Data Uploader to load the payroll run data into the Data Pump Batch table, but to write a PL/SQL program that uploads the data using the APIs generated by the Data Pump Meta-Mapper, you should ignore steps 3 and 4.
-
Run the Data Pump concurrent process to upload the data from the Data Pump batch tables into the Backfeed tables.
See: Running Data Pump
Creating an Upload Workbook
You must create an upload workbook based on the bfexampl.xls file that meets the need of your enterprise before you use Data Uploader.
You can change the names of the files specified in the Header Sheets to whatever you would like the files saved as. For example, if you want to keep a file record of all the payroll runs you have uploaded into the Backfeed tables, you may want to prefix the files with the payroll identifier for the run they relate to.
You can amend the layout of the worksheet and remove any unnecessary worksheets as detailed below:
If you are only using the balance detail functionality and not the payment detail functionality, you can remove the line from the Header Sheet detailing the Payment Detail sheet and delete the Payment Detail Sheet. You can also remove the Balance Details functionality in the same way if you do not want to use it.
If there are any non-essential columns, such as check_type or ftd_amount, that you are not using, you can remove them from the worksheet. Ensure that you do not remove any columns that will prevent the data being loaded via Data Pump. For example, you cannot remove the ID or payroll identifier columns because these are essential to the operation of both Data Pump and Data Uploader.
As well as this, you can change the order of the data columns (with the exception of the ID column) to suit your preference. You must also add any new columns required by changes you have made to your Data Pump front end.
See: Configuring the Data Pump Front End
Formatting the Payroll Run Data into the Format Required by Data Uploader
There are a number of methods that you can use to format the payroll run data into the format required by Data Uploader. You can choose the method that suits the working practices of your enterprise.
One method would be to format your payroll run data using your operating system tools and load it into another spreadsheet. You can then cut and paste it into position in the upload workbook and use the Save Sheets macro to save the worksheets into individual tab delimited text files.
Alternatively, you could save the upload worksheets without any data in using the Save Sheets macro, and use operating system tools to put the data into the correct position. To ensure that the data is correctly formatted you could use the Load Sheets macro to reload the data into Excel so that you can view it. Reloading the data into Excel to check it is not necessary for correct operation of the Data Uploader tool, but it is recommended.
For worksheets with minimal data, another method would be to enter the data manually into Excel and then save it using the Save Sheets macro.
Using the Load Sheets Macro
The Load Sheets macro enables you to load the text files specified in a tab delimited text file version of your Header Sheet into a workbook. The files are loaded from the same directory in which the header text file is stored
To run the Load Sheets macro
-
Ensure you have a version of your Header Sheet, in the same format as the first worksheet in bfexampl.xls, saved as a tab delimited text file. This defines the text files you want to load and the names of the Excel worksheets that should be created when they are loaded.
-
Ensure that the text files you want to upload are stored in the same directory as the Header Sheet text file.
-
Open the workbook into which you want to load the files. If this workbook does not contain the Load Sheets macro you must copy it in from another workbook.
-
Choose Macro from the Tools menu and select the Load Sheets macro in the displayed Macros window.
-
Enter the path of the directory that contains the Header Sheet text file and choose OK.
Note: The last character you must enter in this path must be a "\", for example C:\upload\.
-
Enter the name of the Header Sheet text file and choose OK. The files are loaded into the workbook.
Note: When the files are loaded into the workbook the name of the worksheet containing the header information, i.e. the first worksheet, will always be header_sheet.
Using the Save Sheets Macro
The Save Sheets macro enables you to save a multiple sheet Excel workbook into corresponding tab delimited text files. Each text file will be given the name specified in the Header Sheet and will be saved in the specified directory. The first worksheet in the workbook, the Header Sheet, will create the header file that will be used by Data Uploader.
To run the Save Sheets macro:
-
Ensure that the required Excel workbook is open. If this workbook does not contain the Save Sheets macro you must copy it in from another workbook.
-
Ensure the worksheet containing the Header information is called header_sheet. If it is not you must rename this worksheet or the macro will fail.
-
Choose Macro from the Tools menu and select the Save Sheets macro in the displayed Macros window.
-
Enter the path of the directory in which you want to save the text files. This should be the directory defined by your System Administrator during the set up of Backfeed. Choose OK.
Note: The last character you must enter in this path must be a "\", for example C:\upload\.
-
Enter a name for the header file. This will default to the name of the first worksheet in the workbook. You will need to specify this file when you run the Data Uploader process. Choose OK.
Running Data Uploader
The Data Uploader takes the information held in the text files you have created and loads them into the Data Pump batch tables. The files that are used in each upload are defined by the header file you select when running the HR Data Uploader concurrent process.
Note: You can load the payroll run data into the Data Pump tables using another method if you desire.
Once the setup tasks have been completed you run the Data Uploader in the Submit Requests window.
To run the Data Uploader process:
-
Ensure that the files you want to upload are in the directory specified during the Backfeed setup by your Database and System Administrators.
-
In the Submit Requests window, select the HR Data Uploader concurrent process.
-
Enter the file name of the header file you want to use and choose submit.
Tracking Errors Using Data Uploader
If any errors are detected whilst using Data Uploader, you must view the concurrent request log file for more information.
Running Data Pump
Once you have the payroll run data in the Data Pump batch tables you must run the Data Pump Engine concurrent process to upload the data into the Backfeed tables.
To run the Data Pump Engine concurrent process:
-
Select the Data Pump Engine concurrent process.
-
Enter the required batch name and indicate whether you want the process to be validated.
The batch name will be of the form: <batch name>-<batch ID> where batch name relates to the batch name entered in the header file and batch ID is the internally allocated ID. For example:
Week12-1234
-
Choose Submit.
For information on finding and fixing errors in Data Pump see the Oracle HRMS Data Pump technical essay.
Viewing Third Party Payroll Results in Oracle HRMS
After uploading your third party payroll results into the Backfeed tables, you can view them by:
-
Employee (in the Third Party Payroll Run Employee Results window)
-
Organization, job, grade, group, position, or location (in the Third Party Payroll Run Organization Results window)
These windows each contain two folders, Balance Details and Payment Details, that enable you to display the information you require using the standard folder utilities.
To query payroll run details using the Find Third Party Payroll Run Employee Results window:
-
Do one or any number of the following:
-
Enter a full or partial query on the person's name. Where a prefix has been defined for the person, a full name query should be in the format 'Maddox, Miss Julie'.
-
Enter a query on employee number, assignment number, payroll, or payroll identifier.
-
Specify an earliest and latest date for payroll period start and end dates, and payroll process dates. This means that you can retrieve a range of payroll run results.
-
-
Choose the Find button.
The payroll run details found by the query are displayed in the Third Party Payroll Run Employee Results window. If the query found more than one record, you can use the [Down Arrow] key or choose Next Record from the Go menu to display the next record.
To query payroll run details using the Find Third Party Payroll Run Organization Results window:
-
Do one or any number of the following:
-
Enter a query on organization, people group, job, position, grade, or location.
-
Enter a query on payroll, or payroll identifier.
-
Specify an earliest and latest date for payroll period start and end dates, and payroll process dates. This means that you can retrieve a range of payroll run results.
-
-
Choose the Find button.
The payroll run details found by the query are displayed in the Third Party Payroll Run Organization Results window. If the query found more than one record, you can use the [Down Arrow] key or choose Next Record from the Go menu to display the next record.
To view third party payroll run results:
-
Query the required information using the Find Third Party Payroll Run Employee Results window or the Find Third Party Payroll Run Organization Results window.
-
If you queried using the Find Third Party Payroll Run Employee Results window, details about the employee and the payroll run are displayed, including additional flexfield information.
-
If you queried using the Find Third Party Payroll Run Organization Results window, details about the payroll run are displayed, including additional flexfield information. The find window remains open in the background so that you can refer to it to see the query that has retrieved the displayed results.
-
-
Choose the Balance Details alternative region. This displays all the balance information relating to the displayed employee and payroll run such as run amount, financial year to date amount, and element name. Any additional flexfield information will also be displayed here. You can use standard folder tools to control the data that is displayed in this folder.
-
Choose the Payment Details alternative region. This displays all the payment information relating to the displayed employee and payroll run such as check number, payment date, and amount. Any additional flexfield information will also be displayed here. You can use standard folder tools to control the data that is displayed in this folder.