Parallel Processing
Overview of Parallel Processing
Oracle MRP distributes processing across multiple concurrent processes to maximize performance and make optimal use of machine resources. The architecture of Oracle MRP that enables distributed concurrent processing allows you to:
-
Maximize your throughput by making optimal use of machine resources. Oracle MRP is designed to divide tasks across multiple processes running concurrently to allow you to do more work in less time.
-
Take advantage of multiprocessor architectures. At the same time, Oracle MRP should work optimally, without modification, on single processor machines.
-
Configure Oracle MRP to run optimally on your machine. You can control how Oracle MRP divides the work across separate processes, and how many processes should perform the work.
-
Take advantage of advanced Oracle RDBMS features.
These topics are technical and are not intended for most users. It is not necessary to read them to be able to use Oracle MRP.
Process Control
Oracle MRP breaks tasks into smaller tasks that can be executed concurrently by independent processes. Oracle MRP controls the execution of these processes, independent of the hardware platform.
Concurrent Manager
Oracle MRP uses Oracle Application Object Library's concurrent manager for process control.
Oracle MRP uses Oracle Application Object Library's Application Programmatic Interface (API) to launch new concurrent programs via the concurrent manager by inserting rows to Oracle Application Object Library's concurrent request table.
Oracle MRP also uses the concurrent manager to determine the status of processes that are executing. One process can determine the status of another process by using an API to examine the status of the request in the concurrent request table.
Since Oracle MRP uses the concurrent manager to launch new processes and does not spawn processes directly, Oracle MRP is hardware independent and works on multiple hardware platforms without modification.
Oracle MRP has no direct control over how the operating system distributes the processes across processors. Oracle MRP divides the tasks optimally across separate processes, but depends upon optimization logic on the part of the operating system to distribute the workload effectively across multiple processors.
See also Managing Concurrent Programs and Requests inOracle Applications User's Guide .
Inter-process Communication
Oracle MRP breaks tasks into smaller tasks that are executed concurrently by independent processes (workers). The programs that execute these tasks concurrently need to communicate to coordinate their actions.
Oracle MRP uses the Oracle Server for inter-process communication. For example, a Snapshot Delete Worker needs to be able to communicate to the Snapshot Monitor that it has finished deleting the old plan data from a specific table. The Snapshot Delete Worker does so by updating the appropriate columns in the database and issuing a database commit, instead of relying on hardware-dependent techniques such as signals or sockets. The Snapshot Monitor can then query those columns to receive the message that the data has been deleted and can launch the Loader Worker.
Oracle MRP also uses an Oracle Server feature, database pipes, as a port independent mechanism of asynchronous communication. For example, when the Snapshot Monitor needs to communicate the next task to be executed to the Memory-based Snapshot or the Memory-based Snapshot Workers, it places the task number on a pipe. The Memory-based Snapshot and its Workers listen to the pipe to receive the task number. After the execution of the task, they use the same mechanism to communicate the completion of task to the Snapshot Monitor.
See also Memory-based Planning Engine.
Single Processor Machine
Distributing the workload across multiple independent processes should give performance benefits, even when running on a single processor machine. Many Oracle MRP processes make frequent accesses to the database. Therefore, the processes tend to be I/O bound. That is, the bulk of the time is spent by the processes waiting for the disks to access or retrieve the information requested, and not for the processors themselves to compute.
The total time to execute two I/O bound tasks on a single processor machine is less if they execute simultaneously rather than one after the other. While one task waits for information to be brought back from disk, the single processor can execute the second task.
When there are relatively few processes running, performance of a single processor machine is similar to that of a multiprocessor machine. In general, performance of a single processor machine degrades more quickly than a multiprocessor machine, as the number of simultaneous processes increase.
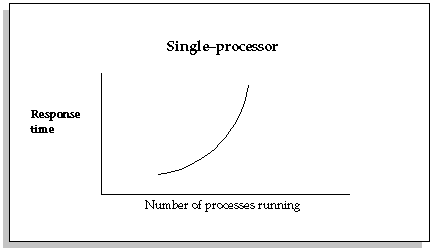
Therefore, both single processor or multiprocessor machines may benefit from distributing tasks across multiple processes. However, a multiple processor machine may be able to distribute the tasks across more processors before realizing performance degradation.
How Many Processes to Launch?
There is no single answer to how many processes to launch. Performance depends upon many factors, such as:
-
What other processes will be running?
-
How many users are logged on?
-
How much memory does the machine have?
-
How many processors does the machine have?
-
What is the data distribution?
-
Does data entry occur all at once, or is data at a relatively constant rate throughout the day?
The best approach is to experiment. For example, first try running the snapshot with three workers, then increase the number of workers. Assuming other factors are not skewing the results, determine which option provides the best results.
Snapshot
The Snapshot takes a copy, or ”snapshot,” of all the information used by the planning processes so that the planning processes can operate on a picture of the data frozen at a point in time, and report against that snapshot at any future time.
Snapshot Tasks
The work performed by the Snapshot can be broken down into individual tasks. Some tasks involve copying information into the MRP tables, such as inventory quantities, master schedule data, discrete jobs, purchase orders, and repetitive schedules. Other tasks involve deleting information from tables. For example, the information in the MRP discrete job table needs to be deleted before MRP can reload the latest information. Many of the tasks are independent of one another; for example, you can load inventory information at the same time you load discrete job information. The Snapshot launches workers to run these tasks concurrently.
When the Snapshot runs, it populates the Snapshot Task table with all the tasks that need to be executed.
Each task has a start date and a completion date. The values of those columns indicate the status of the tasks. A task with a null start date and null completion date has not been executed yet. A task with a value for the start date but no value for the completion date is currently being processed. A task with values for the start date and for the completion date has been processed. The Snapshot looks at these columns to determine which task should be processed next.
Some tasks may be dependent upon other tasks. For example, you must delete from the MRP discrete job table before you reinsert values for the latest picture of the discrete jobs; or, you must load information on current repetitive schedules before you can calculate information on current aggregate repetitive schedules. The Snapshot ensures that independent tasks are processed before the tasks that depend upon them are processed.
Read Consistency
Certain tasks require a database lock to guarantee a consistent read. For example, discrete job information and inventory quantities require a lock on the inventory transactions table to guarantee a consistent read. Consider the situation where you have a subinventory with a quantity of 100 units, and a discrete job for 25 units. Between the time the Snapshot reads the inventory information and the time the Snapshot reads the discrete job information, 10 units are completed from the job. The Snapshot needs to guarantee that it populates the MRP tables with inventory of 100 and discrete job quantity of 25, or inventory for 110 and discrete job quantity of 15. Because each task may be processed by independent processes, the Snapshot cannot guarantee that both tasks are executed at the same time. Therefore, by locking the inventory transactions table, the Snapshot guarantees a consistent read.
Each task has an attribute which indicates whether the Snapshot needs to have acquired the table lock before the task can be completed. Once the locks have been acquired by the Snapshot, those tasks that require a lock are given highest priority, so that the time the tables are locked is minimized. Once all tasks requiring locks have been completed, the Snapshot releases the locks.
Sometimes it is not necessary to guarantee read consistency. For example, if you are running the planning processes for simulation purposes to estimate medium-term and long-term trends in your material requirements, it may not be necessary to guarantee read consistency. Therefore, you may want to run the planning processes with Snapshot Lock Tables turned off, so that you do not need to restrict or limit other users from performing transactions.
Memory-based Planning Engine
One of the advantages of the Memory-based Planning Engine is its ability to get a consistent image of all planning data without locking users out of the system. The planning engine accomplishes this with the Oracle Server feature called “set transaction read-only.” With this option, you do not need to lock tables for the duration of the planning run. To ensure total consistency, you need only synchronize the times when the Snapshot Workers and the Memory-based Snapshot execute the set transaction feature.
You can achieve two degrees of read consistency under the Memory-based Planning Engine. Set the Snapshot Lock Tables field to Yes to force the Snapshot Workers and the Memory-based Snapshot to execute the set transaction feature simultaneously. Locking tables gives you the highest degree of data consistency, but you cannot perform any transactions while this lock is on. If you set the Snapshot Lock Tables field to No, the Snapshot Workers and the Memory-based Snapshot may execute the set transaction feature at different times. There is a remote possibility of some inconsistencies with this method.
Snapshot Configuration
You can configure the Snapshot to determine how many Snapshot Workers to launch when you define the MRP: Snapshot Workers profile option. See Profile Options.
This provides the capability to perform multiple tasks in parallel. This is a function of the hardware running your processes and the number of Standard Managers you have in your Oracle Applications.
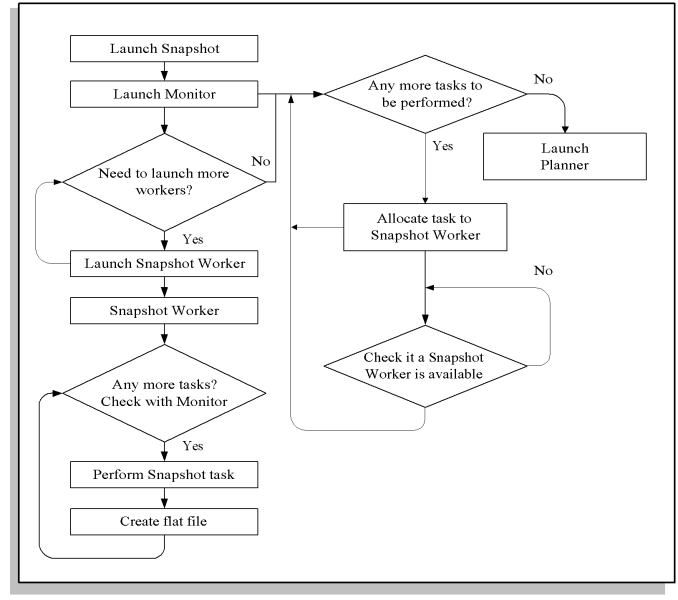
This is a detailed explanation of the Snapshot Process logic under the Standard Planning Engine:
-
Launch X Snapshot Workers via the Concurrent Manager, where X is the number of Snapshot Workers to launch, as defined by the profile option MRP: Snapshot Workers.
-
Did the user specify to lock tables? If not, go to Step 6.
-
Try to lock tables to guarantee a consistent read.
-
Were we able to lock the tables? If No, check to see if we have exceeded the amount of time specified by the user to wait for the table locks.
-
The user specified a length of time to wait for the table locks.
-
Create the lock file. The existence of the lock file signals to the workers that they can execute tasks requiring a table lock, as well as those that do not.
-
Keep looping until all tasks that require table locks have been completed.
-
All tasks requiring a lock have completed. Therefore, there is no need to keep the locks. Issue a database commit to free the table locks.
-
Are there any tasks that have not yet been executed and do not have tasks upon which they are dependent that have not yet completed? If so, execute those tasks.
-
Are there any other tasks to execute? If Yes, those tasks are waiting for the tasks upon which they are dependent to complete. Loop back and try again.
-
Loop until the workers complete.
-
Check the completion status of the workers. If any of the workers exited with error, the plan is invalid and the Snapshot exits with an error.
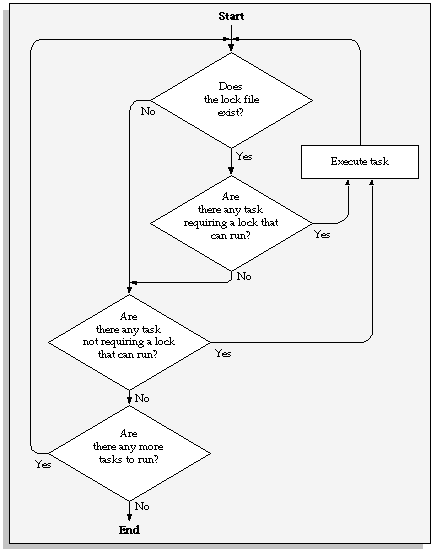
The above diagram illustrates the Snapshot Worker Process logic. Below is a detailed explanation of the logic.
-
Check for the existence of the lock file. If the lock file exists, the Snapshot was able to acquire table locks. Therefore, tasks requiring table locks may be executed.
-
Are there tasks that have not yet been executed, that require a table lock, and do not have tasks upon which they are dependent that have not yet completed? If so, execute those tasks.
-
Are there any tasks that have not yet been executed, and do not have tasks upon which they are dependent that have not yet completed? If yes, execute those tasks.
-
Have all tasks that require table locks been completed? If not, pause and return to step 1.
See also Launching the Planning Process
Snapshot Parallel Processing
The Memory-based Snapshot takes a copy, or ”snapshot,” of all information used by the planning processes so that the planning process can operate on a picture of data frozen at a point in time and report against that snapshot at any future time.
The work performed by the snapshot can be broken down into individual tasks, such as copying on-hand, discrete job, purchase order, bill of material, sourcing information, and so on. These tasks are completely independent of each other and can be performed in parallel. Each of these tasks consists of the following subtasks: deleting data from the last plan run, taking a snapshot of the current data and creating a flat file, and loading the flat file into the MRP tables. While creating the flat file does not require that old data has been deleted, the flat file can only be loaded into the MRP tables after the data from the last plan run has been deleted.
Oracle MRP maximizes the degree of multithreading in all these tasks and subtasks by using multiple processes. For example, the Snapshot Delete Worker deletes the data; the Snapshot and the Snapshot Workers create the flat files; the Loader Workers load the data to MRP tables. The Snapshot Monitor coordinates all these tasks to minimize processing time without violating dependencies among tasks.
See also Memory-based Planning Engine.
Planner Parallel Processing
The Memory-based Planner is the process within the planning engine that performs a gross-to-net explosion. That is, for each level in the bill of material, it nets available inventory and scheduled receipts against gross requirements, and recommends a set of planned orders and order reschedules to meet gross requirements. The Memory-based Planner passes demand from an assembly down to its components, and then performs the same netting process on the components.
Thus, the Memory-based Planner first loads all the supply, demand, BOM, and low-level code information into memory. In order to maximize multithreading Oracle MRP ensure that the Memory-based Planner loads the data from the Snapshot generated flat files rather than waiting until the data is loaded into the MRP tables.
After it has performed the gross-to-net explosion, the Memory-based Planner flushes the output of the plan to MRP tables. Similar to the Memory-based Snapshot, it writes the data to flat files and launches Loader Workers to load the data to MRP tables.
You can configure the Memory-based Snapshot to control how many Snapshot Workers and Snapshot Delete Workers should be launched. To do so, define the profile option MRP: Snapshot Workers. See Profile Options.
See Also:
-
Defining Managers and Their Work Shifts, in Oracle Applications User's Guide
-
Phases of the Planning Process
-
Overview of the Memory-based Planning Engine
-
Snapshot
-
Locking Tables Within the Snapshot
-
Available to Promise
Planning Manager
The Planning Manager periodically performs many tasks that require processing rows in an interface table. These are tasks such as forecast consumption, master production schedule consumption, forecast interface load, schedule interface load, and master demand schedule relief.
The Planning Manager has been designed to:
-
Process the work itself, if there are only a few rows to process, rather than incurring the overhead of launching a new concurrent program.
-
Divide the work across one or more Planning Manager Worker processes if there are many rows to process.
-
Launch more Planning Manager Workers when there are more rows to process, and fewer workers when there are fewer rows to process.
-
Avoid delaying the processing of one task due to another task. For example, relief of the master production schedule should not be delayed because the Planning Manager is busy processing rows for forecast consumption.
-
Allow the user to configure the Planning Manager.
You can configure the Planning Manager to control how it divides the rows to be processed, and across how many processes those rows are divided. You can define the following profile options:
-
MRP: Planning Manager Batch Size
-
MRP: Planning Manager Workers
See Profile Options
The Planning Manager and Planning Manager Workers perform the following tasks:
-
Consume the master production schedule when work orders or purchase orders are created
-
Consume the master demand schedule when sales orders have shipped
-
Consume the forecast when sales orders are entered
-
Load forecasts from outside systems when rows are inserted into the interface table from an outside system
-
Load master schedules from outside systems when rows are inserted into the interface table from an outside system
See also Starting the Planning Manager.
This is a detailed explanation of the Planning Manager Worker Process logic:
-
Update rows in the interface table where the status indicates that they are waiting to be processed. Update at most X rows, where X is the value of the profile option MRP: Planning Manager Batch Size.
-
Check to see if any rows were updated in Step 1. If not, there are no rows waiting to be processed.
-
Were the number of rows updated in Step 1 equal to the batch size? If not, all the remaining rows in the interface table can be processed by this process. If the number of rows updated equals the batch size, there could be more rows to process. Go to Step 4 to try to launch a Snapshot Worker.
-
The number of rows updated never exceeds the batch size, because we have limited the update in Step 1 to be less than or equal to the batch size number of rows.
-
It is possible that occasionally Oracle MRP launches a Snapshot Worker unnecessarily if the number of rows processed exactly matches the batch size. This is not a serious problem, however, as that extra worker simply wakes up, sees there is nothing to process, and exits.
-
Is the number of Planning Manager Workers running or pending less than the maximum number of workers? If yes, launch a Planning Manager Worker. Otherwise, do not launch a new Planning Manager Worker.
-
Process the rows that were updated in Step 1 according to the type of task being performed. If any errors occur during processing, update the status of the row to ”Error”. Otherwise, update the status of the row to ”Processed”.
-
Is this process the Planning Manager or a Planning Manager Worker? If this is the Planning Manager Worker, loop back to Step 1 and try to grab another set of rows to process. If this is the Planning Manager itself that is running, there should be no more rows to process. Do not grab more rows, as that may cause a delay in processing other tasks.
-
If this is the Planning Manager, move on to the next task to process. If there are no other tasks to process this cycle, resubmit the Planning Manager to wake up again after the interval of time set in the profile option. If this is a Planning Manager Worker, terminate the program.