




 Copyright 1999 Rogue Wave Software
Copyright 1999 Rogue Wave Software
Copyright 1999 Sun Microsystems, Inc.
コレクションの選択 |
A |
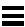 |
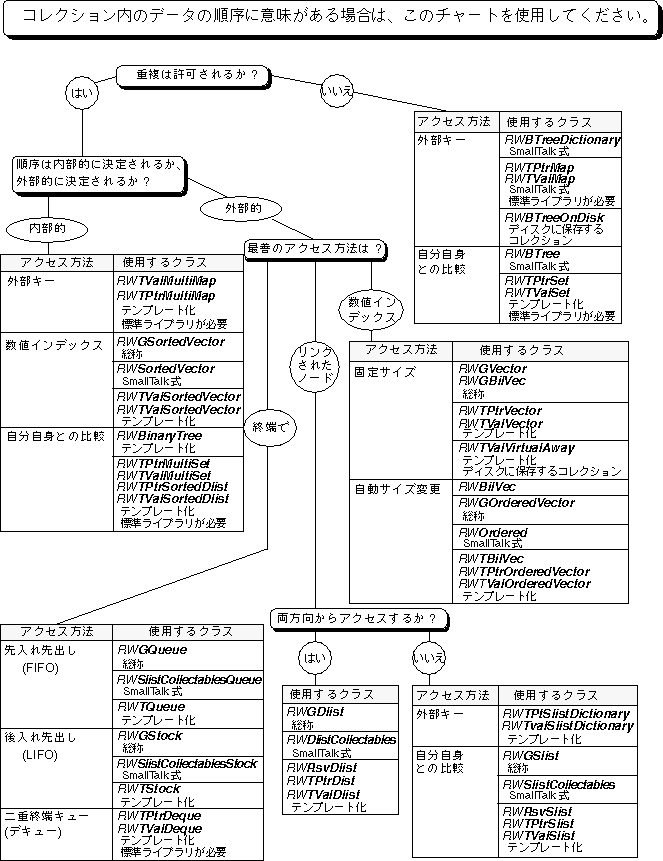
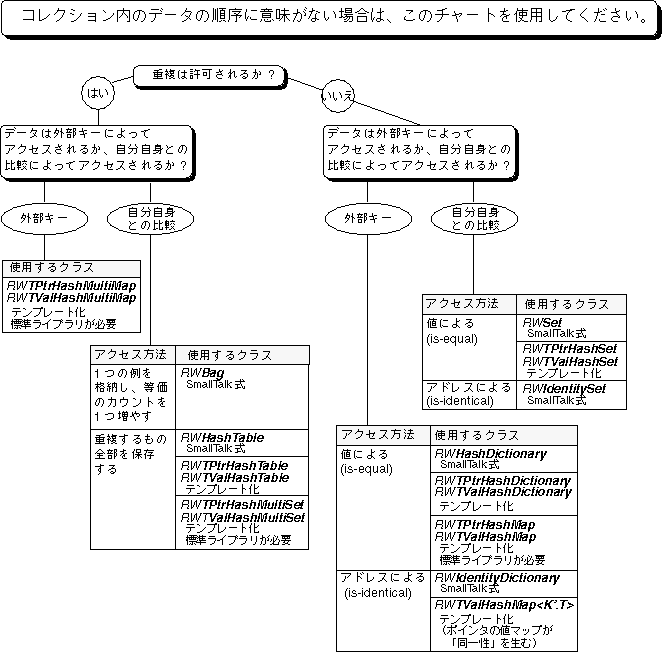
ユーザーの必要性に最適なコレクションを選択する作業は容易ではありません。まず、ユーザーのコレクション内のデータについて考慮する必要があります。コレクションでデータを順番に格納する必要があるか、重複するデータがあるか、またコレクションでのデータの検索または挿入方法はどうするかを考えます。この付録の前半「Tools.h++ コレクションクラスの選択」では、データに関する特定の質問を考え、その答えを通じて、ユーザーのデータ要件に最適なコレクションを即座に選別できるようにする決定ツリー図を示します。この決定ツリーの前半では、ツリー内に示される質問を説明し、ポインタまたは値にもとづくコレクションのどちらを選択するか、順序付きコレクションをいつ使用するか、ディスクにもとづくアクセスで何を使用するかなどの問題に対応する追加の選択基準をいくつか示します。
この付録の後半では、コレクションとコレクションファミリが、挿入、検索、削除などの共通の操作を実行するために必要とする時間とメモリーの違いを大まかに比較します。
Tools.h++ コレクションクラスの選択
決定ツリー図には、コレクションに格納する予定のデータに関する質問が示されています。このツリーを調べることによって、ユーザーのデータとプログラミングプロジェクトに、どの Tools.h++ コレクションクラスが最も適しているかを即座に判断することができます。
データが自分自身との比較によってアクセスされる場合、どのような種類の一致が使用されるかも知る必要があります。一致は、あるオブジェクトを別のオブジェクトと直接比較する等値性にもとづくか、またはオブジェクトアドレスを比較する同一性にもとづきます。
この分析を読む場合は、各種のプロセッサ、オペレーティングシステム、コンパイルの最適化など多数の要因が正確な値に影響を与えることに注意してください。これらの表の目的は、各種のコレクションの動作がどのように違っていて、それ以外のすべてに等しいかを示すことにあります。アルゴリズムの複雑さに関する詳細については、Knuth、Sedgewick などの文献を参照してください。
多くの Tools.h++ コレクションは、基本的に良く似たインタフェースを備えているので、コレクションの選択によってプログラムにどのような影響が及ぶかを簡単に実験して、判断することができます。
次に、各テーブルの内容を説明します。
| 操作 | 時間コスト | 必要記憶容量 |
|---|---|---|
| 端への挿入 | C | 0 |
| 中央への挿入 | C | 0 |
| 検索 (平均項目) | N/2 | 0 |
| 項目の変更/置換 | C | 0 |
| 最初から削除 | C | 0 |
| 最後から削除 | C | 0 |
| 中央から削除 | C | 0 |
| コンテナオーバーヘッド | Mt+0 | |
| コメント |
T の配列に対する単純なラッパー (バイトの bitvec:array を除く) | 指示があったときだけサイズ変更する。 |
| 操作 | 時間コスト | 必要記憶容量 |
|---|---|---|
| 端への挿入 | C | t + p |
| 中央への挿入 | C (反復子が定位置にある場合を仮定) | t + p |
| 検索 (平均項目) | N/2 | 0 |
| 項目の変更/置換 | C | 0 |
| 最初から削除 | C | t + p (回復済み) |
| 最後から削除 | C | t + p (回復済み) |
| 中央から削除 | C (反復子が定位置にある場合を仮定) | t + p (回復済み) |
| コンテナオーバーヘッド | (2p+i) + N(t+p) | |
| コメント | 挿入ごとに割り当てる。反復子は前方だけに進む。 | 項目ごとに拡大縮小する。二重リンクリストよりも小さい。 |
比較表のキー
| N | M | t | i | p | C |
| 項目のカウント | 項目のスペースのカウント | sizeof (item) | sizeof (int) | sizeof (void*) | 定数 |
| 操作 | 時間コスト | 必要記憶容量 |
|---|---|---|
| 端への挿入 | C | t + p |
| 中央への挿入 | C (反復子が定位置にある場合を仮定) | t + p |
| 検索 (平均項目) | N/2 | 0 |
| 項目の変更/置換 | C | 0 |
| 最初から削除 | C | t + p (回復済み) |
| 最後から削除 | C | t + p (回復済み) |
| 中央から削除 | C (反復子が定位置にある場合を仮定) | t + p (回復済み) |
| コンテナオーバーヘッド | (2p+i) + N(t+p) | |
| コメント | 挿入ごとに割り当てる。反復子は両方向に進む。 | 項目ごとに拡大縮小する。Slist よりも大きい。 |
| 操作 | 時間コスト | 必要記憶容量 |
|---|---|---|
| 端への挿入 | C (償却済み) | t (償却済み) |
| 中央への挿入 | N/2 | t (償却済み) |
| 検索 (平均項目) | N/2 | 0 |
| 項目の変更/置換 | C | 0 |
| 最初から削除 | C | 0 |
| 最後から削除 | C | 0 |
| 中央から削除 | N/2 | 0 |
| コンテナオーバーヘッド | (Mt+ p + 2i) + 0 | |
| コメント | 反復子なし (size_t インデックスを使用)ベクトルが拡大したときだけ割り当てる。 | 一度に多数のエントリにスペースを追加することによって、必要に応じて拡大する。resize() を介するときだけ縮小する。 |
比較表のキー
| N | M | t | i | p | C |
| 項目のカウント | 項目のスペースのカウント | sizeof (item) | sizeof (int) | sizeof (void*) | 定数 |
| 操作 | 時間コスト | 必要記憶容量 |
|---|---|---|
| 挿入 | logN + N/2 (平均) | t (償却済み) |
| 検索 (平均項目) | logN | 0 |
| 項目の変更/置換 | N | 0 |
| 最初から削除 | N | 0 |
| 最後から削除 | C | 0 |
| 中央から削除 | N/2 | 0 |
| コンテナオーバーヘッド | (Mt + p + 2i) + 0 | |
| コメント | 挿入はソート順序にもとづいて起こる。反復子なし (size_t インデックスを使用)。ソートを維持するために、置換には削除/追加の順序が必要である。ベクトルが拡大したときだけ割り当てる。 | 一度に多数のエントリにスペースを追加することによって、必要に応じて拡大する。resize() を介するときだけ縮小する。 |
| 操作 | 時間コスト | 必要記憶容量 |
|---|---|---|
| 端への挿入 | logN + N/2 (平均) | t + p |
| 削除 (ポップ) | logN | t + p (回復済み) |
| コンテナオーバーヘッド | (2p+i) + N(t+p) | |
| コメント |
片方向リストとして実装される。 テンプレート化バージョンでは、コンテナを選択できる。時間とスペースのコストはこの選択を反映する。 |
比較表のキー
| N | M | t | i | p | C |
| 項目のカウント | 項目のスペースのカウント | sizeof (item) | sizeof (int) | sizeof (void*) | 定数 |
| 操作 | 時間コスト | 必要記憶容量 |
|---|---|---|
| 端への挿入 | C | t (償却済み) |
| 検索 (平均項目) | N/2 | 0 |
| 項目の変更/置換 | C | |
| 最初から削除 | C | t (償却済み、回復済み) |
| 最後から削除 | C | t (償却済み、回復済み) |
| 中央から削除 | N/2 | t (償却済み、回復済み) |
| コンテナオーバーヘッド | (2p+i) + N(t+p) | |
| コメント |
配列内の循環キューとして実装される。 コレクションが拡大したときだけ割り当てる。 | 必要に応じて拡大縮小し、余分な拡大分をサイズの増加とともにキャッシュする。 |
| 操作 | 時間コスト | 必要記憶容量 |
|---|---|---|
| 挿入 | logN+C | 2p+t |
| 検索 (平均項目) | logN | 0 |
| 項目の変更/置換 | 2(logN + C) | 0 |
| 最初から削除 | logN + C | 2p+t (回復済み) |
| 最後から削除 | logN + C | 2p+t (回復済み) |
| 中央から削除 | logN + C | 2p+t (回復済み) |
| コンテナオーバーヘッド | (p+i) + N(2t+p) | |
| コメント |
挿入はソート順序にもとづいて起こる。 挿入ごとに割り当てる。 順序を維持するために、置換には削除/追加の順序が必要である。 自動的には均衡化されない。 上記の数字は均衡化されたツリーを仮定する。 | 項目ごとのコストは二重リンクリストと同じである。 |
比較表のキー
| N | M | t | i | p | C |
| 項目のカウント | 項目のスペースのカウント | sizeof (item) | sizeof (int) | sizeof (void*) | 定数 |
| 操作 | 時間コスト | 必要記憶容量 |
|---|---|---|
| 挿入 | logN+C | 2p+t |
| 検索 (平均項目) | logN | 0 |
| 項目の変更/置換 | 2(logN+C) または C | 0 |
| 最初から削除 | logN (最悪の場合) | 2p+t (回復済み) |
| 最後から削除 | logN (最悪の場合) | 2p+t (回復済み) |
| 中央から削除 | logN (最悪の場合) | 2p+t (回復済み) |
| コンテナオーバーヘッド | 再平均化は、挿入/削除ごとに起こる。 | (3p+i) + N(2p+t) |
| コメント |
挿入はソート順序にもとづいて起こる。 挿入ごとに割り当てる。 セットの場合、置換には削除/挿入が必要である。 マップの場合、値は所定の場所にコピーされる。 均衡化 (赤黒) 二分木として実装される。 |
比較表のキー
| N | M | t | i | p | C |
| 項目のカウント | 項目のスペースのカウント | sizeof (item) | sizeof (int) | sizeof (void*) | 定数 |
| 操作 | 時間コスト | 必要記憶容量 |
|---|---|---|
| 挿入 | logN+C | 2p + t + small (完全に償却済み) |
| 検索 (平均項目) | logN | 0 |
| 項目の変更/置換 | 2logN+2 or C | 0 |
| 最初から削除 | 2logN(log2(ORDER))+C (最悪の場合) | 2p+t (回復済み) |
| 最後から削除 | 2logN(log2(ORDER))+C (最悪の場合) | 2p+t (回復済み) |
| 中央から削除 | 2logN(log2(ORDER))+C (最悪の場合) | 2p+t (回復済み) |
| コンテナオーバーヘッド | 再平均化は、挿入/削除ごとに起こる。しかし、バランス化バイナリツリーの場合ほど頻繁には起こらない。 | これは、ノードがどれぐらい完全にパックされたかによって決まる。各ノードのコストは ORDER (2p+t+1) で、2N/ORDER 以下、min (N/ORDER,1) 以上のノードがある。事前にソートされた項目を挿入すると、サイズが最大化しやすい。Sedgewick は、ランダムデータでのサイズは 1.44 N/ORDER に近いと言っている。 |
| コメント |
挿入はソート順序にもとづいて起こる。対数はおよそ基底 ORDER で、これは b ツリーの広がりである (実際には、基底は b ツリーの実際のロードによって ORDER と 2ORDER の間になる)。
b ツリーの置換には、削除、次に挿入が必要である。btreedictionary の場合、値は所定の位置にコピーされる。 |
| 操作 | 時間コスト | 必要記憶容量 |
|---|---|---|
| 挿入 | C | p+t |
| 検索 (平均項目) | C | 0 |
| 項目の変更/置換 | C または 2C | 0 |
| 削除 | C | p+r (回復済み) |
| コンテナオーバーヘッド |
((M+2)p+i) + N(p+r) (1) (Mp+ (2p+i)b_used + N(p+t) (2)
1: 標準準拠バージョン 2: b_used は「V6.1」ハッシュコレクションの「使用されたスロットの数」を示す。 | |
| コメント |
挿入はハッシュ関数にもとづいて起こる。
定数時間コストは、項目がハッシュスロットに適切に分散されることを前提とする。最悪の場合は、スロットあたりの項目数に比例する。 辞書またはマップの場合、置換する。新しい値は所定の場所にコピーされる。 そうでない場合、削除、次に挿入が必要である。 |
自動的にサイズ変更を行わない。
項目数は、頻繁に使用するスロットの数の 1.5 倍から 2 倍の間に設定することを推奨する。 |
比較表のキー
| N | M | t | i | p | C |
| 項目のカウント | 項目のスペースのカウント | sizeof (item) | sizeof (int) | sizeof (void*) | 定数 |