![]()
![]()
![]()
![]()
前節では、rdbuf() 関数でファイルの内容をそのまま読み取る方法を説明しました。この節では、別の方法を説明します。ファイルを追加する前に解析をしなければならないような、ヘッダー情報を持ったファイルがあるとします。また、現在のファイルの内容を、標準出力ストリームに書き込まずに、追加前に内容を処理するものとします。この場合、後処理のためにファイルの内容をそのままメモリーに書き込むには、文字列ストリームを作成して、ファイルのストリームバッファを文字列ストリームに挿入する方法が最も簡単です。
fstream fil("/tmp/inout");
stringstream header_stream; //1
header_stream << fil.rdbuf(); //2
// ヘッダーなどを処理する
string word;
header_stream >> word; //3
| //1 | 後処理のためにファイルの内容をそのままメモリーに書き込む方法として、最も簡単なのは文字列ストリームを作成し、 |
| //2 | ファイルのストリームバッファを文字列ストリームに挿入する方法です。 |
| //3 | これで、operator>>()、read()、get() などに匹敵するヘッダー情報の読み取り、解析用の入力ストリームの一般的な機能ができました。 |
この方法で不十分な場合は、ヘッダー情報を組み込んだ文字列を作成し、文字列演算 find()、compare() などで処理します。
fstream fil("/tmp/inout");
header_stream << fil.rdbuf();
string header_string = header_stream.str();
// ヘッダーなどを処理する
string::size_type pos = header_string.rfind('.');
テキストデータの代わりにバイナリデータがヘッダーにある場合は、文字列でも不十分です。すなわち、通常の char* バッファなどの、単なるバイトシーケンスのヘッダーが必要な場合です。ただし、ファイルストリームに対応するロケールによっては、すでにコード変換が行われている可能性もあります。バイナリデータを処理する場合、対応するロケールに非変換コード変換ファセットがあることを確認してください。
fstream fil("/tmp/inout");
header_stream << fil.rdbuf();
string header_string = header_stream.str();
const char* header_char_ptr = header_string.data();
// ヘッダーなどを処理する
int idx;
memcpy((char*) &idx,header_char_ptr,sizeof(int));
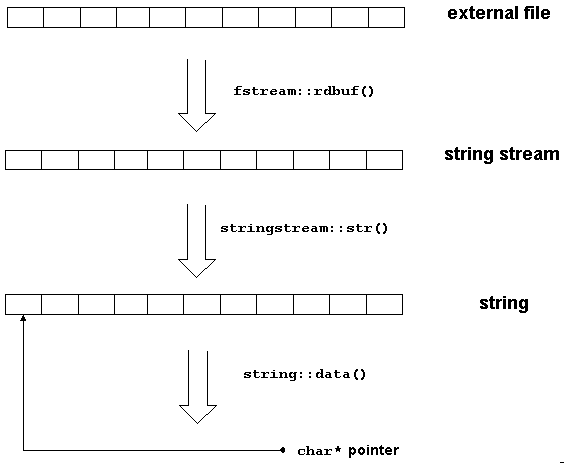
効率上の注意: ヘッダー情報の範囲が広い場合、前の例ではコピー演算の数量を考慮する必要があります。図 35 に、このコピーの作成方法を示します。
rdbuf() で得られたポインタが文字列ストリームに挿入されるとき、ファイルの内容が文字列ストリームのバッファに書き込まれます。文字列ストリームの関数 str() を呼び出すと、2 番目のコピーが作成されます。21 文字列の関数 data() では、次のコピーはまだ作成されていません。ただし、文字列の内部データまでのポインタが返ります。
![]()
![]()
![]()
![]()
Copyright (c) 1998, Rogue Wave Software, Inc.
このマニュアルに関する誤りのご指摘やご質問は、電子メールにてお送りください。
OEM リリース, 1998 年 6 月