| Oracle® Database XBRL Extension Developer's Guide 11g Release 2 (11.2) Part Number E17070-04 |
|
|
PDF · Mobi · ePub |
| Oracle® Database XBRL Extension Developer's Guide 11g Release 2 (11.2) Part Number E17070-04 |
|
|
PDF · Mobi · ePub |
This chapter explains how to use XBRL Extension to Oracle XML DB to create XBRL applications.
This chapter covers these topics:
See Also:
Chapter 3, "APIs – XBRL Extension to Oracle XML DB" for information about the APIs referred to in this chapterThis section provides general information about building XBRL applications.
The following are some things to consider when defining an XBRL application architecture:
Taxonomy-based data model
XBRL Extension to Oracle XML DB provides a relational representation of your XBRL content. This is a third-normal form (3NF) view of the XBRL data. However, depending on the taxonomies to be supported and the typical query and analysis operations associated with these taxonomies, consider using transforming procedures to define derived views over the XBRL content.
See Also:
"Transforming Procedures: DBMS_ORAXBRLV"Validation Architecture
An XBRL repository relies on your application architecture to ensure that XBRL content has been validated by an external XBRL processing engine (XPE). Validation also ensures that the relevant discoverable taxonomy set (DTS) is loaded into the XBRL repository and that any missing files are downloaded. After XBRL content is validated, the XBRL repository can enforce the integrity of the content and its DTS. The validation itself can be done in either of these ways:
Your application can invoke the XPE validation API just before you load the XBRL content into the XBRL repository.
Your application can invoke XPE asynchronously after you load XBRL content into the XBRL repository.
Deployment architecture
XBRL Extension to Oracle XML DB includes one or more XBRL repositories, which are based on Oracle Database. You can use Oracle Real Application Clusters (Oracle RAC) or partitioning with a deployed XBRL repository. XBRL Extension to Oracle XML DB also requires an external XBRL processing engine that is deployed outside the database. In addition, you can optionally deploy XBRL Extension to Oracle XML DB together with Oracle Business Intelligence Suite Enterprise Edition (OBIEE) and tools that help with XBRL taxonomy design. The deployment architecture must provide sufficient processing capabilities in each tier, depending on application requirements and service-level agreements.
The user whose name is the same as the XBRL repository, xb_rep, has general access to the repository. In general you do not want to give application users this much access. Typically application users are allowed only to load and delete documents.
For security reasons Oracle recommends that you follow the enterprise user security model, as described in Oracle Database Enterprise User Security Administrator's Guide. You create a database user that is granted only the access that you want to provide application users, and then your application users share that database user to access the database.
You restrict access for the shared database user (and hence application users) by defining a PL/SQL package under user xb_rep that has a restricted set of APIs, typically only APIs to load and delete XBRL repository documents.
Example 2-1 illustrates this.
xb_rep is the database user whose name is the same as the XBRL repository; xb_rep_pass is the corresponding password.
xb_app is the shared database user; xb_app_pass is the corresponding password.
xb_app_pkg is the package that provides the APIs you want to make available for application users.
xb_rep grants privilege EXECUTE to xb_app for package xb_app_pkg.
Example 2-1 Creating a PL/SQL Package for Application Users
CONNECT xb_rep/xb_rep_pass CREATE OR REPLACE PACKAGE xb_app_pkg AS PROCEDURE loadSchema(schemaLoc VARCHAR2, schemaDoc XMLType, valid PLS_INTEGER DEFAULT NULL, auxLoc VARCHAR2 DEFAULT NULL); PROCEDURE loadLinkBase(linkbaseLoc VARCHAR2, linkbaseDoc XMLType, valid PLS_INTEGER DEFAULT NULL, auxLoc VARCHAR2 DEFAULT NULL); PROCEDURE loadInstance(instanceLoc VARCHAR2, instanceDoc XMLType, valid PLS_INTEGER DEFAULT NULL, auxLoc VARCHAR2 DEFAULT NULL); PROCEDURE loadAuxDocument(auxDocPath VARCHAR2, auxilliaryDoc XMLType, valid PLS_INTEGER DEFAULT NULL, auxLoc VARCHAR2 DEFAULT NULL); PROCEDURE deleteTaxonomy(schemaTargetNS VARCHAR2, force PLS_INTEGER DEFAULT 0); PROCEDURE deleteLinkbase(linkbaseLoc VARCHAR2, force PLS_INTEGER DEFAULT 0); PROCEDURE deleteInstance(instanceLoc VARCHAR2); PROCEDURE deleteFolder(folder VARCHAR2); PROCEDURE bulkLoadXBRLFiles(operation NUMBER, directory VARCHAR2, filelist VARCHAR2, target VARCHAR2); END xb_app_pkg; / CREATE OR REPLACE PACKAGE BODY xb_app_pkg AS PROCEDURE loadSchema(schemaLoc VARCHAR2, schemaDoc XMLType, valid PLS_INTEGER DEFAULT NULL, auxLoc VARCHAR2 DEFAULT NULL) IS BEGIN DBMS_ORAXBRL.loadSchema(schemaLoc, schemaDoc, valid, auxLoc); EXCEPTION WHEN OTHERS THEN RAISE; END loadSchema; -- Define the other procedure bodies similarly. ... GRANT EXECUTE ON xb_app_pkg TO xb_app;
An application user can then connect to the database as shared database user xb_app and invoke procedures in the package xb_app_pkg, as shown in Example 2-2.
You can bulk-load a set of XBRL documents of the same type, whether that type is schema, link-base, or instance, by invoking procedure DBMA_ORAXBRL.bulkLoadFiles, passing it a parameter file that lists the documents to load.
This section explains how to create such a parameter file. See "Building and Using a Sample XBRL Application: USGAAP 2008" for a specific example of this using the taxonomy set USGAAP 2008 and an instance filing from Bank of America.
Proceed as follows to create a bulk-load parameter file:
Find the lowest file-system directory that contains all of the documents that you want to load. Call this the base directory for the set of documents. Create the (empty) parameter file in this directory.
In the parameter file, create an Upload element with a files element child.
For each document to be loaded, create a file element as a child of element files, and a name element as child of element file. For the text node of element name, use the file name for the document to be loaded, relative to the base directory.
If the documents to be loaded refer to their base taxonomy using an HTTP-based URL, then you must specify the network location of the documents using optional attribute httploc of element files.
For the value of attribute httploc you can start with the value of any of these attributes:
Attribute schemaLocation from an import element of an extension schema.
Attribute xlink:href from a link:schemaRef element of an XBRL instance document or an extension linkbase file.
Attribute href from a locator element of a linkbase file.
Given such a value, for attribute httploc you use everything up to but not including the slash that precedes the path. More precisely:
An HTTP-based URL has the following syntax, where username:password@ and :port are optional (and HTTPS can be used in place of HTTP):
HTTP://username:password@domain:port/path?query_string#anchor
As the value of attribute httploc, you use the part of the URL shown in bold, HTTP://username:password@domain:port, or more typically just HTTP://domain.
For example, if you start with an href attribute of a locator element in a linkbase file, and if that attribute value is http://www.xbrl.org/2003/XLink, then the value of attribute httploc is http://www.xbrl.org.
This section presents the steps to build and use a sample application for a regulatory report submission and acceptance. It uses the taxonomy set USGAAP 2008 and an instance filing from Bank of America.
Copy files schema.xml and linkbase.xml from directory xbrl_xdb/XBRLScripts to a working directory, for example, gaap2008. See "Directory xbrl_xdb" for information about these files.
Download USGAAP 2008 and the Bank of America filing from the following URLs:
Copy those two zip files to your working directory and unzip them. Extract the USGAAP documents to directory gaap2008/us-gaap/1.0/ and the Bank of America filings to directory gaap2008/boa/. Example 2-3 shows the expected directory structure.
Example 2-3 Structure of Directory gaap2008
gaap2008/ | +- schema.xml (list of schemas in us-gaap 2008) +- linkbase.xml (list of linkbases in us-gaap 2008) | +- us-gaap/ (us-gaap 2008) | | | +- 1.0/ | | | + - dis/ | + - elts/ | + - ind/ | + - no-gaap/ | + - stm/ | + - test/ | +- boa/ (filing from Bank of America, including extended taxonomy and instance) | + - boa-20061231.xsd + - boa-20061231_cal.xml + - boa-20061231_pre.xml + - boa-20061231_def.xml + - boa-20061231_lab.xml + - boa-20061231_XML.xml
Example 2-4 shows the format of parameter file schema.xml that is used to bulk-load the documents.
Example 2-4 Format of Bulk-Load Parameter File schema.xml
<Upload>
<files httploc="http://xbrl.us" commitnum=10>
<file>
<name>/us-gaap/1.0/dis/us-gaap-dis-acec-2008-03-31.xsd</name>
</file>
<file>
<name>/us-gaap/1.0/dis/us-gaap-dis-ap-2008-03-31.xsd</name>
</file>
…
</files>
</Upload>
The values of the name elements are the names of the files to be loaded, relative to the directory where the files are located (their base directory).
Attribute httploc of element files specifies that the files are to be loaded using HTTP. It tells XBRL Extension to Oracle XML DB to prepend the URL prefix http://xbrl.us to each of the file names when loading. This is required because the XBRL documents in the US-GAAP taxonomy refer to each other using HTTP-based URLs. See "Creating a Parameter File for Bulk-Loading a Set of XBRL Documents".
Attribute commitnum is optional. It specifies an automatic commit frequency for bulk-loading instance documents: a COMMIT operation is performed after every N instance-document insertions, where N is the commitnum value. The default value is 1000. This attribute has no effect on bulk-loading other types of documents: for non-instance documents a COMMIT is performed after loading each document.
Load the base taxonomy set, USGAAP 2008, using the bulkLoadXBRLFiles API.
First, connect as the user whose name is the same as the XBRL repository, xb_rep.
CONNECT xb_rep/xb_rep_pass
Then create a database directory that points to working_directory/gaap2008:
CREATE OR REPLACE DIRECTORY usgaap AS 'working_directory/gaap2008';
Then invoke the bulkLoadXBRLFiles procedure which populates the system tables:
EXEC DBMS_ORAXBRL.bulkLoadXBRLFiles(1, 'USGAAP', 'schema.xml', NULL); EXEC DBMS_ORAXBRL.bulkLoadXBRLFiles(2, 'USGAAP', 'linkbase.xml', NULL);
The application can directly query the relational views, invoke the network generation API, or create views using the network generation API. See "Instance Network Functions: DBMS_ORAXBRLI" for details
Query relational views:
SELECT count(*) FROM oraxbrl_xs_element; SELECT count(*) FROM oraxbrl_calculation_linkbase; SELECT count(*) FROM oraxbrl_pres_linkbase;
Query using network generation APIs:
SELECT DBMS_ORAXBRLT.concepts_network(
'http://xbrl.us/us-gaap-entryPoint-std/2008-03-31',
'http://xbrl.us/us-gaap/role/statement/StatementOfIncome',
NULL,
'presentationArc',
'http://www.xbrl.org/2003/arcrole/parent-child',
'http://www.xbrl.org/2003/role/link',
'http://www.xbrl.org/2003/arcrole/concept-label',
'http://www.xbrl.org/2003/role/label','en-US',
NULL)
FROM DUAL;
Create views using the network generation API:
EXEC DBMS_ORAXBRLV.createViewForConceptTree( 'pres_network', 'http://xbrl.us/us-gaap-entryPoint-std/2008-03-31', NULL, NULL, 'http://xbrl.us/us-gaap/role/statement/StatementOfIncome', NULL, 'presentationArc', 'http://www.xbrl.org/2003/arcrole/parent-child', NULL, NULL, NULL, 'en-US', -1);
Applications accept new report submissions and invoke the XBRL repository load APIs to load the new reports. If a report overwrites an older report submission, the application invokes the XBRL repository deletion APIs to delete the old documents while maintaining the integrity of the remaining content in the XBRL repository.
Load the Bank of America filing:
EXEC DBMS_ORAXBRL.loadSchema('/boa/boa-20061231.xsd',
XMLType(BFILENAME('USGAAP', '/boa/boa-20061231.xsd'),
nls_charset_id('AL32UTF8')));
EXEC DBMS_ORAXBRL.loadLinkbase('/boa/boa-20061231_pre.xml',
XMLType(BFILENAME('USGAAP',
'/boa/boa-20061231_pre.xml'),
nls_charset_id('AL32UTF8')));
EXEC DBMS_ORAXBRL.loadLinkbase('/boa/boa-20061231_def.xml',
XMLType(BFILENAME('USGAAP',
'/boa/boa-20061231_def.xml'),
nls_charset_id('AL32UTF8')));
EXEC DBMS_ORAXBRL.loadLinkbase('/boa/boa-20061231_lab.xml',
XMLType(BFILENAME('USGAAP',
'/boa/boa-20061231_lab.xml'),
nls_charset_id('AL32UTF8')));
EXEC DBMS_ORAXBRL.loadLinkbase('/boa/boa-20061231_cal.xml',
XMLType(BFILENAME('USGAAP',
'/boa/boa-20061231_cal.xml'),
nls_charset_id('AL32UTF8')));
EXEC DBMS_ORAXBRL.loadInstance('/boa/boa-20061231_XML.xml',
XMLType(BFILENAME('USGAAP',
'/boa/boa-20061231_XML.xml'),
nls_charset_id('AL32UTF8')));
An application can query the instance using XBRL relational views or by invoking network generation APIs. Or it can generate derived views using transforming procedures, and then use Oracle Business Intelligence Suite Enterprise Edition (OBIEE) to generate business intelligence reports.
Query directly using XBRL relational views:
SELECT * FROM (SELECT instance_path, item_id, arc_arcrole,
footnote_role, footnote_title, footnote_lang,
footnote_content
FROM oraxbrl_footnotes ORDER BY instance_path, item_id)
WHERE ROWNUM < 10;
Query using a network generation API:
SELECT DBMS_ORAXBRLI.Instance_Network(
'http://xbrl.boa.com/2006-12-31',
'0000070858',
DATE'2005-01-01',
DATE'2006-01-01',
'http://xbrl.boa.com/2006-12-31/ext/IncomeStatement',
NULL,
'presentationArc',
'http://www.xbrl.org/2003/arcrole/parent-child',
NULL,
NULL,
NULL,
'en-US',
1)
FROM DUAL;
Query using a transforming procedure. This SQL statement creates fact table user_STATEMENTTABLE, dimension table user_ STATEMENTEQUITYCOMPONENT, and view boa.
EXEC DBMS_ORAXBRLV.createHyperCubeSuperFactTable(
'boa',
'0000070858',
'http://xbrl.boa.com/2006-12-31',
'http://xbrl.us/us-gaap/2008-03-31',
'StatementTable',
'http://xbrl.boa.com/2006-12-31/ext/StockholdersEquity',
'segment',
'http://xbrl.boa.com/2006-12-31/ext/StockholdersEquity');
See Also:
"Demo-BIFiles" for a sample business intelligence report for Bank of America that uses the derived views generated hereIntegrate with Oracle Business Intelligence Suite Enterprise Edition (OBIEE). There is a sample business intelligence report for Bank of America that uses the derived views generated in "Step 5: Query the Instance or Generate Derived Views".
Drop the individual filing using the deletion APIs.
EXEC DBMS_ORAXBRL.deleteInstance('/boa/boa-20061231_XML.xml');
EXEC DBMS_ORAXBRL.deleteTaxonomy('/boa/boa-20061231.xsd');
The order of execution is important here. Invoking deleteTaxonomy before deleteInstance raises an error, because the taxonomy is still referred to by the instance.
Drop USGAAP 2008:
EXEC DBMS_ORAXBRL.deleteFolder('http://xbrl.us');
http://xbrl.us is used as the folder. This is because attribute httploc is specified in schema.xml and linkbase.xml, as described in "Step 1: Set Up USGAAP".
This section illustrates the steps needed to build and use a sample XBRL application with tuples.
Download the following XBRL standard schema files from http://www.xbrl.org, and copy them to a working directory, xb_cd.
Edit the downloaded schema files to update attribute schemaLocation of element import. Prefix each schemaLocation value with http://www.xbrl.org/200N/, where N corresponds to the downloaded schema.
For example, for schema xl-2003-12-31.xsd the original schemaLocation value is "xlink-2003-12-31.xsd". You must change it to "http://www.xbrl.org/2003/xlink-2003-12-31.xsd".
Run SQL script $ORACLE_HOME/rdbms/xbrl_xdb/XBRLScripts/xbrlregschema.sql to register the XBRL standard schemas.
Set events 31098 and 31156, load the taxonomy (XML schema), and register it with Oracle XML DB. The taxonomy to be registered is oraclexbrltupledemo.xsd. The data table for tuple element ComplexItems is complexitemstab.
Example 2-5 Register Sample XBRL Taxonomy for Tuple Application
ALTER SESSION SET EVENTS = '31098 trace name context forever';
ALTER SESSION SET EVENTS = '31156 trace name context forever, level 1';
DECLARE
xmlSchema XMLType;
BEGIN
xmlSchema := XMLType(bfilename('DEMODIR', 'oraclexbrltupledemo.xsd'),
nls_charset_id('AL32UTF8'));
DBMS_ORAXBRL.loadSchema('http://www.oracle.com/oraclexbrltupledemo.xsd',
xmlSchema, NULL, NULL);
DBMS_ORAXBRL.registerTaxonomySchema(
'http://www.oracle.com/oraclexbrltupledemo.xsd',
XMLType('<schemaAnnotation>
<element>
<elementName>ComplexItems</elementName>
<defaultTableName>complexitemstab</defaultTableName>
</element>
</schemaAnnotation>'));
END;
/
-- Show the tuple elements and corresponding tables created during registration.
SELECT table_name, element_name FROM oraxbrl_tuple_tables ORDER BY table_name;
A given taxonomy can contain multiple top-level tuple elements: occurrences of element element that have an attribute substitutionGroup with value xbrli:tuple. For each such top-level tuple element you can create a tuple data table. Example 2-5 creates one such a tuple data table at the time of taxonomy registration.
You can use procedure createTupleDataTable to create tuple data tables for additional top-level tuple elements. Alternatively you can register the taxonomy without creating any tuple data tables and then use createTupleDataTable to create them. In that case, you would pass NULL as the second argument to procedure registerTaxonomySchema. Example 2-6 illustrates this — it presumes that Example 2-5 was used with NULL as the second argument in place of the XMLType construction.
Example 2-7 uses procedure loadInstance to load the tuple data for element ComplexItems from file-system file oraclexbrltupledemo-inst.xml into a tuple data table.
Example 2-7 Loading an XBRL Instance with Tuple Data
EXEC DBMS_ORAXBRL.loadInstance(
'http://www.oracle.com/oraclexbrltupledemo-inst.xml',
XMLType(bfilename('DEMODIR', 'oraclexbrltupledemo-inst.xml'),
nls_charset_id('AL32UTF8')));
Example 2-8 shows how to query this tuple data. It queries elements ComplexItems/DescriptionContent and ComplexItems/AmountTotal, retrieving their text nodes and values of attribute contextRef.
Example 2-8 Querying Tuple Data
SELECT t1.contextRef, t1.description, t2.totalvalue
FROM ora$xbrlpath p,
complexitemstab t,
XMLTable(XMLNamespaces(DEFAULT 'http://www.oracle.com/oraclexbrltupledemo'),
'/ComplexItems' PASSING t.tupledata
COLUMNS description PATH 'DescriptionContent/text()',
contextRef VARCHAR2(4000) PATH 'DescriptionContent/@contextRef',
totalamount XMLType PATH 'AmountTotal') t1,
XMLTable(XMLNamespaces(DEFAULT 'http://www.oracle.com/oraclexbrltupledemo'),
'/AmountTotal' PASSING t1.totalamount
COLUMNS totalvalue PATH 'text()',
contextRef PATH '@contextRef') t2
WHERE p.DOCOID = t.DOCOID
AND p.DOCPATH = 'http://www.oracle.com/oraclexbrltupledemo-inst.xml'
AND t1.contextRef = t2.contextRef;
You deploy XBRL Extension to Oracle XML DB in a traditional three-tier architecture, with XBRL repositories in the database-tier, the XBRL processing engine and optionally Oracle BI Suite as a separate instance in the mid-tier, and a set of tools in the client-tier (desktop). This is illustrated in Figure 2-1.
These functional pieces can be combined using an XBRL workflow suite from a third-party vendor. Alternatively, you can create a custom deployment by combining functional pieces using portals and Business Process Execution Language (BPEL)
Figure 2-1 XBRL Extension to Oracle XML DB: Deployment
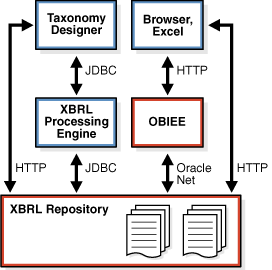
Deployment requires the usual evaluations of application requirements and service-level agreements to determine the scale of processing needed in the database, XBRL processing engine, and Oracle BI Suite. Query- and analysis-intensive applications can require scaling up Oracle BI Suite and the database tier using Oracle Real Application Clusters (Oracle RAC) or partitioning. XBRL processing-intensive applications can require scaling up the XBRL processing capabilities.
|
Copyright © 2010, 2012, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|