Oracle Secure Enterprise Search Java SDK
The Oracle Secure Enterprise Search Java SDK contains the following APIs:
-
See Also:
Building Custom Crawlers white paper for detailed information about how to build secure crawlers:http://www.oracle.com/technology/products/oses/pdf/Buidling_Custom_CrawlersJan12_07.doc
Crawler Plug-in API
You can implement a crawler plug-in to crawl and index a proprietary document repository. In Oracle SES, the proprietary repository is called a user-defined source. The module that enables the crawler to access the source is called a crawler plug-in (or connector).
The plug-in collects document URLs and associated metadata from the user-defined source and returns the information to the Oracle SES crawler. The crawler starts processing each URL as it is collected. The crawler plug-in must be implemented in Java using the Oracle SES Crawler Plug-in API. Crawler plug-ins go in the ORACLE_HOME/search/lib/plugins directory.
These are the basic steps to build a crawler plug-in:
-
Compile and build the plug-in jar file.
The Java source code for the plug-in first must be compiled into class files and put into a jar file in the
ORACLE_HOME/search/lib/plugins/directory. The library needed for compilation isORACLE_HOME/search/lib/search_sdk.jar. -
Create a source type.
Before you can create a source for the crawler plug-in, you first must create a source type for it. From the Oracle SES Administration GUI, go to the Global Settings - Source Types page and provide the Java class name and jar file name (created in the previous step).
-
Create the source.
From the Home - Sources page, create a source from the source type you just created. You also must define the parameter for the source type just created.
For example, suppose you want to crawl
/scratch/teston a Linux box for the file crawler plug-in. Specify the seed URL like as follows:file://localhost/scratch/test. -
Run the crawler plug-in.
From the Home - Schedules page, start the schedule for the crawler.
This section includes the following topics:
Crawler Plug-in Overview
The following diagram illustrates the crawler plug-in architecture.
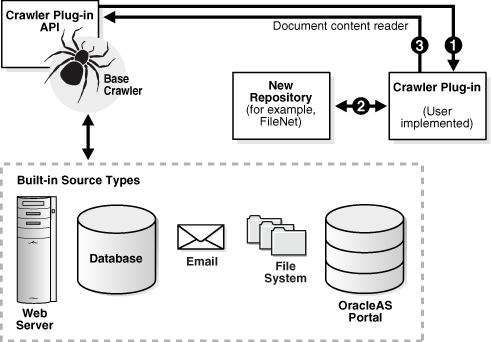
Description of the illustration benri010.gif
Two interfaces in the Crawler Plug-in API (CrawlerPluginManager and CrawlerPlugin) must be implemented to create a crawler plug-in. A crawler plug-in does the following:
-
Provides the metadata of the document in the form of document attributes.
-
Provides access control list information (ACL) if the document is protected.
-
Maps each document attribute to a common attribute name used by end users.
-
Optionally provides the list of URLs that have changed since a given time stamp.
-
Optionally provides an access URL in addition to the display URL for the processing of the document.
-
Provide the document contents in the form of a Java Reader. In other words, the plug-in is responsible for fetching the document.
-
Can submit attribute-only documents to the crawler; that is, a document that has metadata but no document contents.
Document Attributes and Properties
Document attributes, or metadata, describe document properties. Some attributes can be irrelevant to your application. The crawler plug-in creator must decide which document attributes should be extracted and saved. The plug-in also can be created such that the list of collected attributes are configurable. Oracle SES automatically registers attributes returned by the plug-in. The plug-in can decide which attributes to return for a document.
Library Path and Java Class Path
Any other Java class needed by the plug-in should be included in the plug-in jar file. (You could add the paths for the additional jar files needed by the plug-in into the Class-Path of the MANIFEST.MF file in the plug-in jar file.) This is because Oracle SES automatically adds the plug-in jar file to the crawler Java class path, and Oracle SES does not let you add other class paths from the administration interface.
If the plug-in code also relies on a particular library file (for example, a .dll file on Windows or a .so file on UNIX), then the library must be put under the ORACLE_HOME/lib directory or the ORACLE_HOME/search/lib/plugins directory. The Java library path is set explicitly by the crawler to those locations.
You should use Java resource bundles instead of properties files whenever possible when developing a custom plug-in. If you must use the properties files as resource bundle files, then take these steps to ensure that the administration API loads the files properly.
To use properties files as resource bundles files:
-
Add the path of
sourceTypeJarPackageNameinto the classpath variable inORACLE_HOME/search/config/searchctl.conf -
Restart the middle tier:
ORACLE_HOME/bin/searchctl restart
Crawler Plug-in Restrictions
The plug-in must handle mimetype rejection and large document rejection itself. For example, the plug-in should reject files it does not want to index based on its type or size, such as zip files. Also, plain text files, such as log files, can grow very large. Because the crawler reads HTML and plain text files into memory, it could run out of memory with very large files.
Crawler Plug-in Functionality
This section describes aspects of the crawler plug-in.
Source Registration
Source registration is automated. After a source type is defined, any instance of that source type can be defined:
-
Source name
-
Description of the source; limit to 4000 bytes
-
Source type ID
-
Default language; default is
en(English) -
Parameter values; for example:
seed - http://www.oracle.com depth – 8
Source Attribute Registration
You can add new attributes to Oracle SES by providing the attribute name and the attribute data type. The data type can be string, number, or date. Attributes returned by an plug-in are automatically registered if they have not been defined.
User-Implemented Crawler Plug-in
The crawler plug-in has the following requirements:
-
The plug-in must be implemented in Java.
-
The plug-in must support the Java plug-in APIs defined by Oracle SES.
-
The plug-in must return the URL attributes and properties.
-
The plug-in must decide which document attributes Oracle SES should keep. Any attribute not defined in Oracle SES is registered automatically.
-
The plug-in can map attributes to source properties. For example, if an attribute ID is the unique ID of a document, then the plug-in should return (document_key, 4) where
IDhas been mapped to the propertydocument_keyand its value is 4 for this particular document. -
If the attribute LOV is available, then the plug-in returns them upon request.
Crawler Plug-in APIs and Classes
The Crawler Plug-in API is a collection of classes and interfaces used to implement a crawler plug-in.
Table 13-3 Crawler Plug-in Interfaces and Classes
| Interface/Class | Description |
|---|---|
|
|
This interface is used by the crawler plug-in to integrate with the Oracle SES crawler. The Oracle SES crawler loads the plug-in manager class and invokes the plug-in manager API to obtain the crawler plug-in instance. Each plug-in instance is run in a thread execution. |
|
|
This interface is used to generate the crawler plug-in instances. It provides general plug-in information for automatic plug-in registration on the administration page for defining user-defined source types. It has the control on which plug-in object (if multiple implementations are available) to return in The |
|
|
This interface is used by a crawler plug-in to perform crawl-related tasks. It has execution context specific to the crawling thread that invokes the plug-in |
|
|
This interface is implemented by the Oracle SES crawler and made available to the plug-in through the This interface is used by a crawler plug-in to manage the current crawled document set. |
|
|
This interface is used by a crawler plug-in to submit access control list (ACL) information for the document. |
|
|
This interface is used by a crawler plug-in to submit or retrieve document information. |
|
|
This interface holds a document's attributes and properties for processing and indexing. This interface is used by a crawler plug-in to submit URL-related data to the crawler. |
|
|
This interface is used by a document service plug-in to submit document attributes and/or document contents to the crawler. |
|
|
This interface is used to register the document service plug-in. It is also used by the crawler to create a DocumentService object. |
|
|
This interface provides Oracle SES service and implemented interface objects to the plug-in. It is implemented by the Oracle SES crawler and made available through plug-in manager initialization. This interface is used by a crawler plug-in to obtain Oracle SES interface objects. |
|
Logger |
This interface is used by a crawler plug-in to output messages to the crawler log file. |
|
LovInfo |
This interface is used by both the crawler and a source plug-in to set and retrieve attribute list of values (LOV) from the source. |
|
|
This interface for a crawler plug-in reads the value of the source parameter. |
|
|
This interface is implemented by the Oracle SES crawler and made available to the plug-in through the This interface is used by the crawler plug-in to submit URL-related data to the crawler. |
|
|
This class describes the general properties of a parameter. |
|
|
This provides a severity code to direct the crawler's response. |
|
|
This class encapsulates information about a data source plug-in-specific error. |
|
|
This class encapsulates information about errors from processing plug-in requests. |
|
|
The crawler manager class must implement this interface to use a crawler that uses attribute-based security. |
Document Service API
The Document Service API is included as part of the Crawler Plug-in API. It is used to register a document service plug-in. A document service accepts input from documents and performs some operation on it. For example, you could create a document service for auditing or to show custom metatags.
The Secure Enterprise Search Document Summarizer is a document service included by default for search result clustering. It extracts the most significant phrases (and optionally sentences) for a document.
A document service plug-in or document service instance is a Java class that implements the document service API. A document service plug-in accepts document content and attributes to come up with revised document content and new attributes. The title, author, and description attribute values are always used for search hit display. A document service plug-in can also set the document language or replace the input document content with a revised or filtered document.
A document service pipeline is a list of document service instances invoked in the order of the list. The same instance can be assigned to different pipelines, but it cannot be assigned twice in the same pipeline. You can have multiple pipeline definitions; for example, one could be used globally and the other used for certain sources. Not every instance must be in a pipeline.
In the Oracle SES Administration GUI, you can set a global pipeline for all sources on the Global Settings - Crawler Configuration page. Set individual sources to use a particular pipeline on the Home - Sources - Crawling Parameters page for each source. If enabled, the global pipeline is used for all sources, unless a local service pipeline is defined.
DocumentServiceManager is an interface used by the Oracle SES Administration GUI to register the document service plug-in. When you create a document service, you select the type of document service manager. You can either create a new document service manager or select from the list of existing document service managers.
You can create document service managers, instances and pipelines on the Global Settings - Document Service page.
When a document service is invoked, the document parsing, attribute extraction, and language detection has been done. The crawler only honors the change made by the document service plug-in, and then the document is cached for indexing.
You must perform a force re-crawl on a source if you add or change the document service pipeline for the source.
To create and use a document service plug-in:
-
Create a new Java file implementing the
DocumentServiceinterfaceinit,close, andprocessmethods; for example,DocumentSummarizer.java. -
Create a new Java file implementing the
DocumentServiceManagerinterface; for example,DocumentSummarizerManager.java. -
Compile all of the related Java files into class files. For example:
$ORACLE_HOME/jdk/bin/javac -classpath $ORACLE_HOME/search/lib/search_sdk.jar DocumentSummarizer.java
-
Package all the class files into a jar file under the
ORACLE_HOME/search/lib/plugins/docdirectory. For example:$ORACLE_HOME/jdk/bin/jar cv0f $ORACLE_HOME/search/lib/plugins/doc/extractor/extractor.jar DocumentSummarizer.class DocumentSummarizerManager.class
The document service plug-in jar file must be deployed under the
ORACLE_HOME/search/lib/plugins/docdirectory. -
From the Global Setting - Document Service page, register the jar file as a new document service plug-in where the jar file name is
extractor/extractor.jarand the service plug-in manager class name isoracle.search.plugin.doc.extractor.DocumentSummarizerManager.
After registering a document service plug-in, you can create an instance from it.
URL Rewriter API
A URL rewriter is a user supplied Java module that implements the Oracle SES UrlRewriter Java interface. When activated, it is used by the crawler to filter and rewrite extracted URL links before they are inserted into the URL queue.
The URL Rewriter API is included as part of the Crawler Plug-in SDK. The URL Rewriter API is used for Web sources.
Web crawling generally consists of the following steps:
-
Get the next URL from the URL queue. (Web crawling stops when the queue is empty.)
-
Fetch the contents of the URL.
-
Extract URL links from the contents.
-
Insert the links into the URL queue.
The generated new URL link is subject to all existing boundary rules.
There are two possible operations that can be done on the extracted URL link:
-
Filtering: removes the unwanted URL link
-
Rewriting: transforms the URL link
URL Link Filtering
Users control what type of URL links are allowed to be inserted into the queue with the following mechanisms supported by the Oracle SES crawler:
-
robots.txtfile on the target Web site; for example, disallow URLs from the/cgidirectory -
Hosts inclusion and exclusion rules; for example, only allow URLs from
www.example.com -
File path inclusion and exclusion rules; for example, only allow URLs under the
/archivedirectory -
Mimetype inclusion rules; for example, only allow HTML and PDF files
-
Robots metatag
NOFOLLOW; for example, do not extract any link from that page -
Blacklist URLs; for example, URL explicitly singled out not to be crawled
With these mechanisms, only URL links that meet the filtering criteria are processed. However, there are other criteria that users might want to use to filter URL links. For example:
-
Allow URLs with certain file name extensions
-
Allow URLs only from a particular port number
-
Disallow any PDF file from a particular directory
The possible criteria could be very large, so it is delegated to a user-implemented module that can be used by the crawler when evaluating an extracted URL link.
URL Link Rewriting
For some applications, due to security reasons, the URL crawled is different from the one seen by the end user. For example, crawling occurs on an internal Web site behind a firewall without security checking, but when queried by an end user, a corresponding mirror URL outside the firewall must be used.
A display URL is a URL string used for search result display. This is the URL used when users click the search result link. An access URL is a URL string used by the crawler for crawling and indexing. An access URL is optional. If it does not exist, then the crawler uses the display URL for crawling and indexing. If it does exist, then it is used by the crawler instead of the display URL for crawling.
For regular Web crawling, only display URLs are available. But in some situations, the crawler needs an access URL for crawling the internal site while keeping a display URL for external use. For every internal URL, there is an external mirrored URL.
For example:
http://www.example-qa.us.com:9393/index.html http://www.example.com/index.html
When the URL link http://www.example-qa.us.com:9393/index.html is extracted and before it is inserted into the queue, the crawler generates a new display URL and a new access URL for it:
Access URL:
http://www.example-qa.us.com:9393/index.html
Display URL:
http://www.example.com/index.html
The extracted URL link is rewritten, and the crawler crawls the internal Web site without exposing it to the end user.
Another example is when the links that the crawler picks up are generated dynamically and can be different (depending on referencing page or other factor) even though they all point to the same page. For example:
http://compete3.example.com/rt/rt.wwv_media.show?p_type=text&p_id=4424&p_currcornerid=281&p_textid=4423&p_language=us http://compete3.example.com/rt/rt.wwv_media.show?p_type=text&p_id=4424&p_currcornerid=498&p_textid=4423&p_language=us
Because the crawler detects different URLs with the same contents only when there is enough duplication, the URL queue could grow to a huge number of URLs, causing excessive URL link generation. In this situation, allow "normalization" of the extracted links so that URLs pointing to the same page have the same URL. The algorithm for rewriting these URLs is application dependent and cannot be handled by the crawler in a generic way.
When a URL link goes through a rewriter, the following outcomes are possible:
-
The link is inserted with no changes.
-
The link is discarded; it is not inserted.
-
A new display URL is returned, replacing the URL link for insertion.
-
A display URL and an access URL are returned. The display URL might or might not be identical to the URL link.
Note:
URL rewriting is available for Web sources only.To create and use a URL rewriter:
-
Create a new Java file implementing the UrlRewriter interface
open,close, andrewritemethods. -
Compile the rewriter Java file into a class file. For example:
$ORACLE_HOME/jdk/bin/javac -classpath $ORACLE_HOME/search/lib/search_sdk.jar SampleRewriter.java
-
Package the rewriter class file into a jar file under the
ORACLE_HOME/search/lib/plugins/directory. For example:$ORACLE_HOME/jdk/bin/jar cv0f $ORACLE_HOME/search/lib/plugins/sample.jar SampleRewriter.class
-
Enable the
UrlRewriteroption and specify the rewriter class name and jar file name (for example,SampleRewriterandsample.jar) in the Oracle SES Administration GUI Home - Sources - Crawling Parameters page of an existing Web source -
Crawl the target Web source by launching the corresponding schedule. The crawler log file confirms the use of the URL rewriter with the message Loading URL rewriter "SampleRewriter"...
See Also:
Oracle Secure Enterprise Search Java API Reference for the API (oracle.search.sdk.crawler package)Security APIs
In addition to the extensible crawler plug-in framework that lets you crawl and index proprietary document repositories (Crawler Plug-in API), Oracle SES also includes an extensible authentication and authorization framework. This lets you use any identity management system to authorize users (Identity Plug-in API). You can also define your own security model for each source (Authorization Plug-in API).
Identity Plug-in API
The Identity Plug-in API communicates with the identity management system to authenticate a user at login with a user name and password. It also provides a list of groups (or roles) for a specified user.
The identity plug-in manager manages initialization parameters and returns the IdentityPlugin object.
To add an identity plug-in, click Register New Identity Plug-in on the Global Settings - Identity Management Setup page, and enter the class name and jar file name for the identity plug-in manager.
Authorization Plug-in API
For sources with authorization requirements that do not fit the user/group model, an authorization plug-in provides a more flexible security model. (Authentication is still handled by an identity plug-in.)
With an authorization plug-in, a crawler plug-in can add security attributes similar to document attributes. The authorization plug-in is invoked at login time to build security filters onto the query string. The security filters are applied against the values of the security attributes for each document. Only documents whose security attribute values match the security filter are returned to the user. (All security attributes have string values.)
The authorization plug-in contains the following component:
-
ResultFilterPlugin: Implements query-time authorization (QTA). When building the hit list, Oracle SES calls a result filter plug-in to check if the user is authorized to view to each document. Only documents the user is authorized to view are listed in the hit list. The result filter can be used as the only security device., or it can be used with other security. The result filter can also be used to modify the title or display URL.
User-Defined Security Model
With the user-defined security model, Oracle SES displays an Authorization page before a new user-defined source can be completed. The UserDefinedSecurityModel interface provides a method that returns the name of the class implementing the AuthorizationManager interface and the names and types (GRANT or DENY) of the security attributes used to build the security filter for a given user.
If you must change the AuthorizationManager plug-in class name or jar file name, then you must turn off security for that source to allow the change. After changing and applying the ACL setting to No Access Control List, you can edit the AuthorizationManager details. The new AuthorizationManager should share the same security attribute model as the previous one.
Caution:
While security is turned off, any user can access the documents in the affected source.See Also:
Oracle Secure Enterprise Search Java API Reference for the API (oracle.search.sdk.security package)Query-time Authorization API
Query-time authorization enables you to associate a Java class with a source that, at search time, validates every document fetched out of the Oracle SES repository belonging to the protected source. This result filter class can dynamically check access rights to ensure that the current search user has the credentials to view each document.
You can apply this authorization model to any source other than self service or federated sources. Besides acting as the sole provider of access control for a source, it can also be used as a post-filter. For example, a source can be stamped with a more generic ACL, while query-time authorization can be used to fine tune the results.
Overview of Query-time Authorization
Query-time authorization has the following characteristics:
-
It allows dynamic access control at search time compared to more static ACL stamping.
-
It filters documents returned to a search user.
-
It controls the Browse functionality to determine whether a folder is visible to a search user.
-
Optionally, it allows pruning of an entire source from the results to reduce performance costs of filtering each document individually.
-
It is applicable to all source types except self service and federated sources.
-
The result filter can modify the Title or Display URL for the result returned to the search user.
Query-time filtering is handled by class implementations of the ResultFilterPlugin interface.
Filtering Document Access
Filtering document access is handled by the filterDocuments method of the ResultFilterPlugin interface. The most common situation for filtering occur with a search request, in which this method is invoked with batches of documents from the result list. Based on the values returned by this method, all, some, or none of the documents might be removed from the results returned to the search user.
Access of individual documents is also controlled. For example, viewing a cached copy of a document or accessing the in-links and out-links requires a call into filterDocuments to determine the authorization for the search user.
Filtering Folder Browsing
The ResultFilterPlugin implementation is also responsible for controlling the access to, and visibility of folders in, the Browse application. If a folder belongs to a source protected by a query-time filter, then the folder name in the Browse page does not have a document count listed next to it. Instead, the folder shows a view_all link.
For performance reasons, it can be costly to determine the exact number of documents visible to the current search user for every query-time filtered folder displayed on a Browse page. This calculation requires that every document in every folder be processed by the filter. To prevent this comprehensive and potentially time-consuming operation, document counts are not used. Instead, folder visibility is explicitly determined by the query-time filter.
Based on the results from the filterBrowseFolders method, a folder might be hidden or shown in the Browse page. This result also controls access to the single folder browsing page, which displays the documents contained in a folder.
If the security of folder names is not a concern for a particular source, then the filterBrowseFolders method can blindly authorize all folders to be visible in the Browse application. After a folder is selected, the document list is still filtered through the filterDocuments method. This strategy should not be employed if folder names could reveal sensitive information.
If security is very critical, then it might be easiest to hide all folders for browsing. The documents from the source are still available for search queries from the Basic and Advanced Search boxes, but users are not able to browse the source in the Browse pages of the search application.
Limitations of folder filtering:
-
The
filterBrowseFoldersmethod does not implicitly restrict access to subfolders. For example, if folder/Miscellaneous/www.example.com/privateis hidden for a search user, then it is still possible for that user to view any subfolder, such as/Miscellaneous/www.example.com/private/a/b, if that subfolder is not also explicitly filtered out by this method. It would be possible to view this subfolder if the user followed a bookmark or outside link directly to the authorized subfolder in the Browse application. -
This method does not affect functionality outside of the Browse application. This is not a generic folder pruning method. Search queries and document retrieval outside of the Browse application are only affected by the
filterDocumentsandpruneSourcemethods.
Pruning Access to an Entire Source
The ResultFilterPlugin interface provides the ability to determine access privileges at the source level. This is achieved through calls to the pruneSource method. This method can be called in situations where there are a large number of documents or folders to be filtered. Authorizing or unauthorizing the entire source for a given user could provide a large performance gain over filtering each document individually.
The implementation of ResultFilterPlugin must not rely on this method to secure access to documents or folders. This method is strictly an optimization feature. There is no guarantee that it is invoked for any particular search request or document access. For example, when performing authorization for a single document, Oracle SES may call the filterDocuments method directly without invoking this method at all. Therefore, the filterDocuments and filterBrowseFolders methods must be implemented to provide full security without pruning.
Determining the Authenticated User
A query-time filter is free to define a search user's access privileges to sources and documents based on any criteria available. For example, a filter could be written to deny access to a source depending on the time of day.
In most cases, however, a filter imposes restrictions based on the authenticated user for that search request. The Oracle SES authenticated user name for a request is contained in the RequestInfo object. The steps for accessing this user name value depend on whether the request originated from the JSP search application or the Oracle SES Query Web Services interface. For either type of request, the key used to access the authenticated user name is the string value AUTH_USER. The user name is not case-sensitive.
This sample implementation of the ResultFilterPlugin.getCurrentUserName method illustrates how to retrieve the current authenticated user from either a JSP or Web Services request:
public String getCurrentUserName( RequestInfo req )
throws PluginException
{
HttpServletRequest servReq = req.getHttpRequest();
Map sessCtx = req.getSessionContext();
String user = null;
if( servReq != null )
{
HttpSession session = servReq.getSession();
if( session != null )
user = ( String ) session.getAttribute( "AUTH_USER" );
}
else if( sessCtx != null )
{
// Web Service request
user = ( String ) sessCtx.get( "AUTH_USER" );
}
if( user == null )
user = "unknown";
return user;
}
See Also:
"Authentication Methods"Query-time Authorization Interfaces and Exceptions
The oracle.search.sdk package contains all interfaces and exceptions for the Query-time Authorization API.
To write a query-time authorization filter, implement the ResultFilterPlugin interface. The methods in this interface may throw instances of PluginException.
Objects that implement the RequestInfo, DocumentInfo, and FolderInfo interfaces are passed in as arguments for filtering, but these interfaces do not need to be implemented by the filter writer.
The API contains the following interfaces and exceptions:
Table 13-4 Query-time Authorization Interfaces and Exceptions
| Interface/Exception | Description |
|---|---|
|
|
This interface filters search results and access to document information at search time. If an object implementing this interface has been assigned to a source, then any search results or other retrieval of documents belonging to the source are passed through this filter before being presented to the end user. |
|
|
This exception is thrown by methods in the |
|
|
This interface represents information about a document that can be passed to a |
|
|
This interface represents information about a folder that can be passed to a |
|
|
This interface represents information about a request that can be passed to a |
Thread-Safety of the Filter Implementation
Classes that implement the ResultFilterPlugin interface should be designed to persist for the lifetime of a running Oracle SES search application. A single instance of ResultFilterPlugin generally handles multiple concurrent requests from different search end users. Therefore, the filterDocuments, pruneSource, filterBrowseFolders, and getCurrentUserName methods in this class must be both reentrant and thread-safe.
Compiling and Packaging the Query-Time Filter
To compile your query-time filter class, you must include at least the two following files in the Java CLASSPATH. These files can be found in the Oracle SES server directory.
-
ORACLE_HOME/search/lib/search_query.jar -
ORACLE_HOME/lib/servlet.jar
Oracle recommends that you build a jar file containing your ResultFilterPlugin class (or classes) and any supporting Java classes. Place this jar file in a secure location for access by the Oracle SES server. If this jar file is compromised, then the security of document access in the search server can be compromised.
Your query-time filter might require other class or jar files that are not included in the jar file you build and are not located in the Oracle SES class path. If so, add these files to the Class-Path attribute of the JAR file manifest. Include this manifest file in the jar file that you build.
If Oracle SES cannot locate a class used by a ResultFilterPlugin during run-time, then an error message is written to the log file and all documents from that source are filtered out for the search request being processed.
See Also:
https://download.oracle.com/javase/1.4.2/docs/guide/jar/jar.html for more information about jar file manifestsNote:
The Oracle SES 10g Administration API is deprecated in this release (searchadminctl and the associated Web services). The Oracle SES Release 11g Administration API replaces it. Therefore, the following public Web services are deprecated in this release:
-
oracle.search.admin.ws.client.SearchAdminClient. The operations for this service include:getEstimatedIndexFragmentation getSchedules getScheduleStatus optimizeIndexNow startSchedule stopSchedule login logout
-
oracle.search.admin.ws.client.Schedule -
oracle.search.admin.ws.client.ScheduleStatus
Note:
In previous releases, the base path of Oracle SES was referred to asORACLE_HOME. In Oracle SES release 11g, the base path is referred to as ORACLE_BASE. This represents the Software Location that you specify at the time of installing Oracle SES.
ORACLE_HOME now refers to the path ORACLE_BASE/seshome.
For more information about ORACLE_BASE, see "Conventions".