| Oracle® Retail Analytics Implementation Guide Release 14.1 E58117-01 |
|

 Previous |
 Next |
This chapter describes how Retail Analytics implements customized aggregation by using the Retail Analytics Aggregation Framework.
The Retail Analytics Aggregation Framework is a PL/SQL-based tool designed to simplify the Retail Analytics aggregation process by leveraging the existing Retail Analytics aggregation programs that are mandatory to the Retail Analytics application. It is designed to provide a framework for end users to populate customized aggregation tables to gain better performance on front-end re-porting.
The framework is designed to either generate SQL DML file, or to execute the SQL DML statement, or to do both based on the setting in the ra.env file to populate customized aggregation tables. The client needs to populate the configuration table to provide enough mapping information for the framework to generate the DML statement. This customized process by using the Aggregation Framework can be included in the client's batch scheduler by calling the wrap script aggplp.ksh. Besides providing regular Retail Analytics ETL logging and program status control capability, the framework also generates SQL DML file, message file, and error file under Retail Analytics database utlfile folder to help the end user for the verification.
Due to the security concern, the database connection for the framework is managed by Retail Analytics ODI in a same approach which is utilized by Retail Analytics regular batch programs.
Perform the following steps for the Aggregation Framework installation and initial setup:
|
Note: The <STAGING_DIR> mentioned below is the Retail Analytics installer staging directory. Please refer to the Oracle Retail Analytics Installation Guide for additional information. |
Perform the following procedure to import Aggregation Framework ODI components:
Make sure $ODI_HOME/bin/odiparams.sh is configured correctly.
Copy odi_import.ksh to different folders:
Copy <STAGING_DIR>/ora/installer/ora14/mmhome/full/src/odi_import.ksh to <STAGING_DIR>/ora/installer/Aggregation_Framework/odi folder.
Copy <STAGING_DIR>/ora/installer/ora14/mmhome/full/src/odi_import.ksh to <STAGING_DIR>/ora/installer/Aggregation_Framework/odi/odi_parent folder.
Execute odi_import.ksh from <STAGING_DIR>/ora/installer/Aggregation_Framework/odi/odi_parent/odi_import.ksh, which will import the below Aggregation Framework ODI components
FOLD_Aggregation_Framework.xml
|
Note: Before executing odi_import.ksh, please read the comments inside of the script on how to use the script and set up the ODI_HOME and LOGDIR environment variables correctly. |
Execute odi_import.ksh from <STAGING_DIR>/ora/installer/Aggregation_Framework/odi/odi_import.ksh, which will import the below Aggregation Framework ODI components
VAR_RA_UTLPATH.xml
VAR_RA_AGG_EXEC_MODE.xml
FOLD_PLP_RetailAggregationDaily.xml
PACK_PLP_RetailAggregationDaily.xml
PACK_PLP_RetailAggregationReclass.xml
TRT_RetailAggregationDaily.xml
TRT_RetailAggregationReclass.xml
TRT_RetailAggregationDaily_Debug.xml
TRT_RetailAggregationReclass_Debug.xml
Perform the following step to import the Aggregation Framework shell script:
Copy aggplp.ksh and aggrcplp.ksh from <STAGING_DIR>/ora/installer/Aggregation_Framework/ to $MMHOME/src directory.
Perform the following procedure for initial set up of the Aggregation Framework:
|
Note: The sql files mentioned below can be found under the <STAGING_DIR>/ora/istall/Aggregation_Framework folder. |
Under the Retail Analytics batch user schema, execute the provided script W_RTL_AGGREGATION_DAILY_TMP.sql to create the configuration table W_RTL_AGGREGATION_DAILY_TMP
Under the Retail Analytics batch user schema, execute the script ra_aggregation_daily.sql and ra_aggregation_rec.sql to create a PL/SQL stored procedure RA_AGGREGATION_DAILY and RA_AGGREGATION_REC.
Create customized aggregation tables under the Retail Analytics data mart schema.
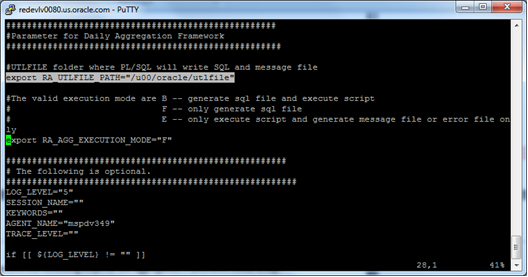
Configure database UTLFILE folder and execution mode in the ra.env file. The Retail Analytics batch user must be given permission to read and write files to this folder. For debug purpose, Retail Analytics batch user should also be given permission to read V$PARAMETER.
Populate the W_RTL_AGGREGATION_DAILY_TMP configuration table. There is one row for each customized aggregation table.
Populate the Retail Analytics program control table C_ODI_PARAM to include the program/customized target tables. The SCENARIO_NAME column should be populated with either PLP_RETAILAGGREGATIONDAILY if it is regular aggregation process or PLP_RETAILAGGREGATIONRECLASS if it is reclassification related process. For each program/target table, the PARAM_NAME must be populated with value of 'TARGET_TABLE_NAME' and PARAM_VALUE with the actual customized table name. The current version does not get ETL_PROC_WID and EXECUTION_ID from this table. The end user can use SP_MAPPING column to populate these columns if these columns are required by the end users.
Perform the following steps for the Aggregation Framework verification:
For daily batch process, execute script aggplp.ksh with the name of customized aggregation table name and execution mode as parameters. For the reclassification only batch process, execute script aggrcplp.ksh with the name of customized aggregation table name and execution mode as parameters.
If the execution mode is not specified in the command line, or the value is not in ("F", "B", "E"), then the value defined in the ra.env file will be used.
Verify result by using the generated sql file with the DML statement. If it is not correct, then go to step 5 in the initial setup to reconfigure the configuration table.
Add step 6 into the batch scheduler, so the populating of the aggregation table will be part of daily ETL job.
The Aggregation Framework must be properly setup and configured before the process can be included in the daily ETL process.
In order to use the framework, the end users must create the aggregation table with the following rules:
The customized aggregation table has to be created under the Retail Analytics data mart schema.
The user should use the following table naming standard:
For day level aggregation table, the table name must contain _DY_.
For day and location level aggregation table, the table name must contain _LC_DY_.
It is a good practice to keep the column name as the same with the column name in the source table. This will reduce the task on the column mapping under the SP_MAPPING column.
The name of aggregateable columns (using sum or average) and only the name of aggregatable columns should end with _AMT, _LCL, _GLOBAL1, _GLOBAL2, _GLOBAL3, _QTY, _COUNT. Otherwise, a column mapping should be provided under SP_MAPPING column in the configuration table.
As a rule of the framework, the transaction date in the aggregation source table has to be named as DT_WID (for a source table at daily level), WK_WID (for a source table at week level), or DAY_DT (for a source TMP table).
For all other Retail Analytics standard columns, please refer to the Oracle Retail Analytics Data Model Guide.
W_RTL_AGGREGATION_DAILY_TMP is a configuration table under the Retail Analytics batch user schema. It has aggregation information utilized by the framework to generate DML statement. In order to use the Retail Analytics Aggregation Framework correctly, the following information has to be provided by the client:
SRC_TABLE
This is the source table that is used as a source of aggregation process.
For a regular daily batch, the source table has to be a temp table owned by the Retail Analytics batch user schema. In most case, it is generated by a Retail Analytics ETL batch program which is mandatory to be executed.
For a reclassification batch that is only executed when there is a reclassification, the source table is a fact table at item/location/day level for transaction fact or at item/day or item/week for positional fact. These source fact tables should be owned by the Retail Analytics data mart schema and populated by Retail Analytics mandatory batch programs.
TGT_TABLE
This is the customized aggregation table. It is under the Retail Analytics data mart schema.
AGGREGATION_TYPE
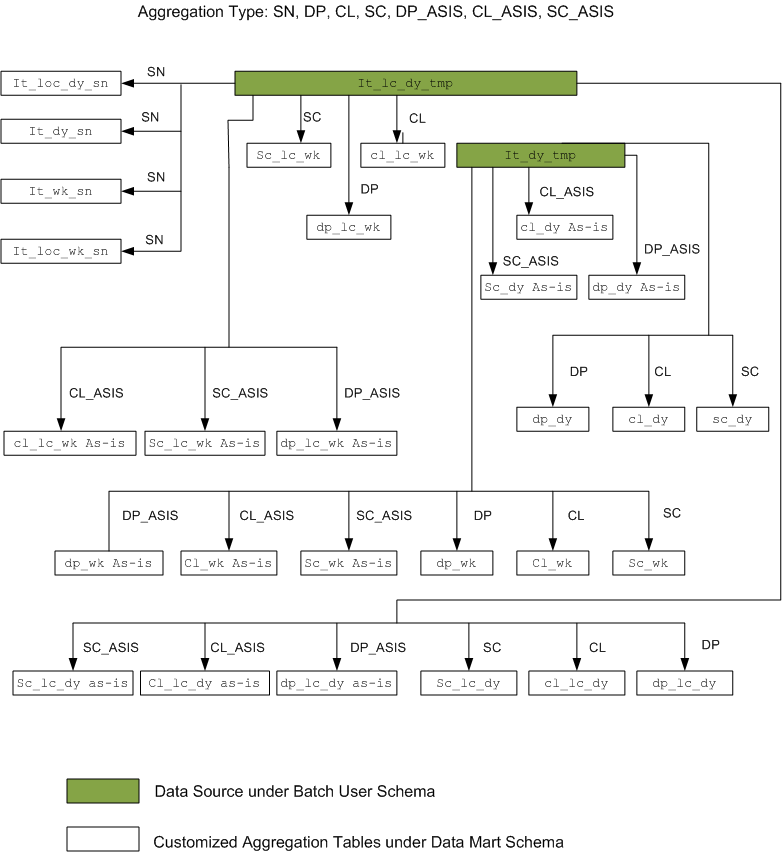
This column specified the aggregation type that the framework supports. Currently the framework supports aggregation on product hierarchy, time hierarchy (to week), and product season. The valid values are:
SC: from item to subclass based on as-was
CL: from item to class based on as-was
DP: from item to department based on as-was
SC_ASIS: from item to subclass based on as-is
CL_ASIS: from item to class based on as-is
DP_ASIS: from item to department based on as-is
SN: from item to item season based on the transaction date
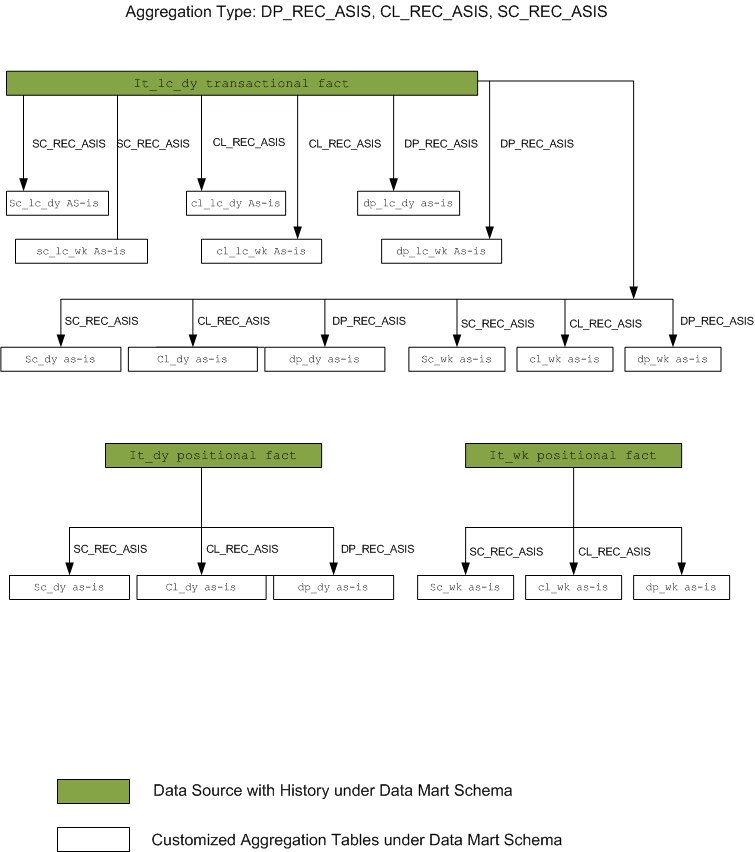
SC_REC_ASIS: fact recalculation on reclassification day from item to subclass based on as-is. When this type is selected, the program will re-aggregate fact data from item level to subclass level based on the as-is. A temporary table is generated under the Retail Analytics batch user schema to store the re-calculation result which can be used for further aggregation to class or department level. The temporary table name can be found in the DML statement file generated by the program under the UTLFILE folder.
CL_REC_ASIS: fact re-calculation on reclassification day from item to class based on as-is. The batch program that uses SC_RC_ASIS aggregation type is a pre-requirement for the batch program that uses CL_REC_ASIS and both should have the same source table name under SRC_TABLE column.
DP_REC_ASIS: fact re-calculation on reclassification day from item to department based on as-is. The batch program that uses SC_RC_ASIS aggregation type is a pre-requirement for the batch program that uses DP_RC_ASIS and both should have the same source table name under SRC_TABLE column.
|
Note: For reclassification type of aggregation, due to performance concern, the subclass/location/day level is mandatory before clients can aggregate to other levels. All other levels will use the result from the process to continue higher level aggregation. |
SEQ_NAME
This is the name of the sequence that will be used as ROW_WID on the target table.
AVG_COLUMNS
This is a list of columns that use average logic in the aggregation. The name of columns should be separated by comma.
PK_COLUMNS
This lists primary key columns for the customized aggregation table. The name of columns should be separated by comma.
SP_MAPPING
The framework provides auto column mapping for the following cases:
The column name in the target table is the same as a source column in the source table.
The amount columns _AMT, _AMT_GLOBAL1, _AMT_GLOBAL2, _AMT_GLOBAL3 are mapped to the source columns as _AMT_LCL/LOC_EXCHANGE_RATE if the configuration CURRENCY_EXPAND_IND is set to 'Y'.
The column W_INSERT_DT and W_UPDATE_DT on the target column are mapped to system time from the database.
The sequence name defined in the configuration table is used as ROW_WID when ROW_WID column exists in the target table.
If the target column cannot be found in the source table by matching column name and at the same time, the target column name does not exist in the customized column mapping under SP_MAPPING, then value 0 will be used for the mapping and a warning message will be written to the message file.
The INTEGRATION_ID column is mapped with the concatenation of primary key provided in the configuration table. The order of the concatenation is the same as the order of primary key provided in the PK_COLUMNS column in the configuration table. This auto mapping may use surrogate key instead of the ID from source system if the surrogate key is used as part of primary key.
Besides the capability of auto mapping, this framework also provides customized column mapping by using the column SP_MAPPING in the configuration table.
The syntax for the customized mapping is column1=value1. The column1 is a column name on the target table. The value1 can be either constant value or a column name on the source table.
If there are multiple customized mappings, '&' should be used between each mapping. For example column1=value1 & column2=value2.
The SQL aggregation function (sum, average, min) should be considered if the target column in the customized mapping is not part of the primary key specified in the column PK_COLUMNS.
The customized mapping using SP_MAPPING column only supports regular update. Once a column mapping is specified, the update on this column will always use TARGET.COLUMN1=SOURCE.COLUMN1 regardless of the configuration value specified in the column POSITIONAL_IND.
CURRENCY_EXPAND_IND
This column is to indicate if the target table has an amount column in a primary currency or global currency that will be derived from the source table by a calculation. The valid values are 'Y' or 'N'.
PARA_DEGREE
This column has the parallel degree for the DML process. The default value is 0.
POSITIONAL_IND
This column indicates if the amount columns, quantity columns, or count columns on this table are stored in positional format or in transactional format. The valid values are 'Y' or 'N'. If the value is 'N', the target column will be updated by TARGET.COLUMN1=NVL(SOURCE.COLUMN1, 0) +NVL(TARGET.COLUMN1,0). If the value is 'Y', the target column will be updated by TARGET.COLUMN1=SOURCE.COLUMN1. If there is any exception, the end user can use customized mapping on column SP_MAPPING for those exceptional columns.
Once the configuration is completed and tested, the customized aggregation table can be populated as daily ETL batch process. The syntax to kick off the process is:
For daily batch process, calling Unix script aggplp.ksh TARGET_TABLE_NAME, in which TARGET_TABLE_NAME is the name of customized aggregation table and it should be already configured in W_RTL_AGGREGATION_DAILY_TMP table.
For reclassification only process, calling Unix script aggrcplp.ksh TARGET_TABLE_NAME, in which TARGET_TABLE_NAME is the name of customized aggregation table and it should be already configured in W_RTL_AGGREGATION_DAILY_TMP table. For transactional fact, the execution of subclass/location/day level is the pre-requirement for all other levels. For positional fact, the execution of subclass/day and subclass/week is the pre-requirement for other corporate/day level and corporate/week level.
Please refer to the Oracle Retail Analytics Data Model Guide for Retail Analytics table naming standards.
The process from calling aggplp.ksh or aggrcplp.ksh will also cause the framework to insert a record to the Retail Analytics batch status control table C_LOAD_DATES with PLP_RETAILAGGREGATIONDAILY or PLP_RETAILAGGREGATIONRECLASS as PACAKGE_NAME and the name of customized aggregation table as TARGET_TABLE_NAME. The client has to either execute etlrefreshgenplp.ksh to remove this record from C_LOAD_DATES or manually delete this status record from C_LOAD_DATES before the same ETL batch process can be executed again against the same aggregation table. This batch control process is consistent with the process used by Retail Analytics mandatory batch programs.
The Retail Analytics Aggregation Framework writes batch logging information into a Retail Analytics log file that is used by Retail Analytics regular batch programs. The end user can also view the detailed logging information though ODI operator. This is in consistence with the logging from Retail Analytics regular batch programs.
Besides the standard Retail Analytics logging, the framework also provides a message file, a SQL file, and an error file under the Oracle utlfile folder. The message file uses table name or [TABLE_NAME]_rc as file name and "msg" as file name extension. It provides in-formation when the target column cannot be found in the source table and when the customized column mapping cannot be found in the configuration table. The error file uses table name as file name or [TABLE_NAME]_rc and "err" as file name extension. It provides any error information. The SQL file is available when the execution mode is set to 'B' or 'F' in ra.env file. It uses table name or [TABLE_NAME]_rc as file name and contains the DML statement that will be used to populate the customized aggregation table. All these files can be used to help the end user to verify the ETL process result during framework setup time or during the regular batch process.