 Understanding PeopleSoft Search Indexes
Understanding PeopleSoft Search Indexes
This chapter provides an overview of PeopleSoft search indexes and discusses how to:
Configure PeopleSoft search.
Work with indexes.
Build record-based indexes.
Build file system (spider) indexes.
Build HTTP spider indexes.
Administer search indexes.
Modify the VdkVgwKey key.
Understanding PeopleSoft Search Indexes
This section provides an overview of search indexes and discusses:
Types of indexes.
Components of the search architecture.
Index building.
Search index limitations.
User search strategies.
 Overview of Search Indexes
Overview of Search IndexesA search index is a collection of files that is used during a search to quickly find documents of interest. The process of creating the search index is also called building the search index. The set of files that make up the index is a collection. This collection contains a list of words in the indexed documents, an internal documents table containing document field information, and logical pointers to the actual document files.
Fields contain metadata about a document. For example, Author and Title might be fields in an index. VdkVgwKey is a special field that identifies each document and is unique to all of the documents in the collection.
The document table is a relational table with one row for each document and columns of fields. Every index can be modified by defining a set of fields for it.
In PeopleSoft search implementations, every search index has a home location where all of the files pertaining to that index are located. This directory is the home directory of the index and is typically located at PS_CFG_HOME/data/search/INDEXNAME. Under this directory is another directory named for the database to which the application server or the Process Scheduler is connected. The actual collection files reside in this database directory.
Every search index can be modified by changing the configuration files that are associated with the index. These configuration files are known as style files and reside in the style directory. A typical configuration of style files define fields for a particular index.
Types of Indexes
PeopleSoft software supports three types of search indexes:
Record-based indexes.
HTTP spider indexes.
File system indexes.
Record-based indexes are used to create indexes of data in PeopleSoft tables. For example, if the PeopleSoft application has a catalog record that has two fields (Description and PartID), you can create a record-based index to index the contents of the Description and PartID fields. Once the index is created, you can use the PeopleCode search application programming interface (API) to search this index.
HTTP spider indexes index a web repository by accessing the documents from a web server. You typically specify the starting uniform resource locator (URL). Then the indexer walks through all documents by following the document links and indexes the documents in that repository. You can control to what depth the indexer should traverse.
File system indexes are similar to HTTP spider indexes, except that the repository that is indexed is a file system. You typically specify the path to the folder or directory. Then the indexer indexes all documents within that folder. HTTP spider indexes and file system indexes are sometimes collectively referred to as spider indexes. The indexer recognizes a wide variety of document formats, such as Word or Excel documents. Any document that is an unknown format will be skipped by the indexer.
Components of the Search Architecture
PeopleSoft search architecture uses two main technologies: that provided by the PeopleSoft Portal and that provided by Verity. They are connected by the PeopleSoft search API.
PeopleSoft Portal Technologies
The PeopleSoft Portal search technology contains the following components:
Search input field.
Captures a query string that is entered by users in the portal header.
Search API.
Passes the query string that is captured in the search input field to the Verity search engine.
Portal Registry API.
Applies security to filter the search results.
Portal registry.
Contains a repository of content references that can be searched.
Search results page.
Formats and displays search results for the user.
Search options.
Enables users to personalize search behavior and results.
Note. By default, the PeopleSoft search performs case-insensitive searches.
The basic items of the Verity architecture that are incorporated in the PeopleSoft Portal search architecture are:
Verity collection.
This is the set of files forming a search index. When a user performs a search, the search is conducted against the Verity collection. You can create and maintain your own collections with the Search Design and Search Administration PeopleTools.
BIF file.
This is an intermediate file that is created in the process of building a Verity collection. The BIF file is a text file that is used to specify the documents to be submitted to a collection. It contains a unique key, the document size (in bytes), field names and values, and the document location in the file system.
XML file.
This is another intermediate file that is created in the process of building a Verity collection. The XML file is a text file named indexname.xml that contains all of the information from the documents that are searchable but not returned in the results list. This information is stored in zones. Zones are specific regions of a document to which searches can be limited.
Style files.
These files describe a set of configuration options that are used to create the indexes that are associated with a collection.
mkvdk.
This Verity command-line tool is used to:
Index a collection.
Insert new documents into a collection.
Perform simple maintenance tasks, like purging and deleting a collection.
Control indexing behavior and performance.
To create and administer search indexes for use with PeopleSoft software, use the PeopleTools utilities under PeopleTools, Search Engine. The utilities enable you to administer indexes and to create file system, spider, and record-based indexes.
Index Building
For both HTTP spider and file system indexes, options are available to include or exclude certain documents based on file types and Multipurpose Internet Mail Extensions (MIME) types. The index building procedure is different for record-based indexes and the spider indexes. Typically, the index building procedure is carried out from an Application Engine job that is scheduled by using the process scheduler.
The steps for building record-based indexes are:
The data from the application tables is read and two files called indexname.xml and indexname.bif are created.
indexname.xml contains one XML record for each document that needs to be indexed. The XML record contains all of the data that needs to be indexed. indexname.bif contains field information, the VdkVgwKey document, and offsets to denote the start and end of each document in the XML file.
The XML and the bulk insert file (BIF) files are typically generated through PeopleCode and reside in the home location of the index. The Verity utility, mkvdk, is called, passing in the BIF file as the argument to build the index.
The steps for building spider indexes are:
The Verity utility, vspider, is called.
The vspider utility takes a number of arguments, but the most important ones are the starting URL or directory to spider and the number of links to follow.
The vspider utility walks through all of the documents in the repository and builds the index.
Search Index Limitations
Following are the PeopleSoft search index limitations:
Verity collections must reside on the PeopleSoft application server or be accessible from it through a shared drive.
Satisfying this requirement can take several forms, depending on the application server's operating system. On Microsoft Windows, this could be a network drive. On UNIX, this could be an NFS-mounted drive.
Verity collections are most efficient if you index large groups of data, rather than indexing one or two documents at a time.
Small updates degrade the index and require that you run the Verity cleanup utility.
Style files are located in the style subdirectory of the index.
To make style changes, apply them to the files in this directory.
You can have only one language per collection.
Additionally, a number of Verity search index features are limited to certain maximum values, as follows:
|
Feature |
Limitation |
|
Wildcards |
Wildcard auto-expansion is limited to 16,000 matches. |
|
Number of collections |
The maximum number of physical collections that can be searched at one time is 128. |
|
Documents per collection |
The maximum number of documents allowed per collection is 16 million, subject to disk space availabilty. |
|
Fields per collection |
The maximum number of fields allowed per collection is 250. |
|
Field length |
The maximum length of any field is 32 kilobytes. Note. The actual number of characters that translates to depends on the character set being used. |
|
Field value length in bulk files |
The maximum length of a field value in a bulk file is 32 kilobytes. Note. The actual number of characters that translates to depends on the character set being used. |
|
Zones per document |
The number of zones allowed per document is unlimited. |
|
Characters in path |
The maximum path size allowed is 256 characters. |
|
Maximum documents with sort specification |
The maximum number of documents that are returned when a sort specification is applied is 16,000. |
|
Sort fields per search |
The maximum number of fields that can be included in a sort specification is 16. |
Refer to the Verity documentation for details about these features.
User Search Strategies
A user submits a search request by entering a search string into the search input form field in the portal header. The “<form action=...>” element in the portal header is generated at runtime to link to a PeopleSoft Internet Architecture page, and a Java script submits the form. The query string is passed to the Search API as a parameter named PortalSearchQuery to find matching results. Those results are filtered for security through PeopleCode by the Portal Registry API. The search results page echoes the original query string and displays a list of content references that match the request. If the user clicks the Go button but does not enter a search query, the search results page displays without any results.
The search results page performs the following steps:
Changes the case of the entered text to all uppercase characters.
By default, the Verity search engine searches for all mixed-case variations when a query string is entered in all lowercase or in all uppercase. However, search queries that are entered in mixed-case automatically become case sensitive. (For example, a query on Apple behaves as if the user had specified Apple, which would find only the precise string Apple, while a query on apple finds APPLE, Apple, and apple.) But the portal makes one important change: It changes the case of the query sting to all uppercase, prohibiting users from truly executing case-sensitive searches. This avoids situations where mixed-case searches would otherwise return no results. On the search results page, however, the original case is echoed back to the user.
Formats the query string to pass to the Search API.
This includes filtering out expired and hidden content reference, and content references that are not valid yet.
Calls the Search API.
This returns the query results.
Calls the Portal Registry API.
This is done to apply security filtering to the results. Security is applied in PeopleCode by checking the Authorized property.
Formats and displays search results.
This completes the user's search request.
Configuring PeopleSoft SearchThis section contains an overview and discusses how to:
Configure search to run natively within the application server (Type-1).
Configure search to run as a separate process managed by the application server (Type-2).
Configure a separate Search Server (Type-3).
Understanding PeopleSoft Search ConfigurationsPeopleSoft offers these configuration options for enabling PeopleSoft search:
Type-1: Verity running within the application server domain.
Type-2: Verity running within a separate process managed by the application server.
Type-3: Verity running within a separate search server.
Note. In some cases, the operating system determines which search configuration options can be used. Always refer to the PeopleSoft Hardware and Software Requirements guide, the Certifications area on Metalink, or customer support for the most recent support information.
Type-1: Verity Running within the Application Server Domain
In this configuration, Verity runs within the application server. Its libraries are linked to the application server. For example, the Verity VDK is bound to the PSAPPSRV server process. When a search request is submitted, the VDK bound to PSAPPSRV processes the request with the PSVERITY library.
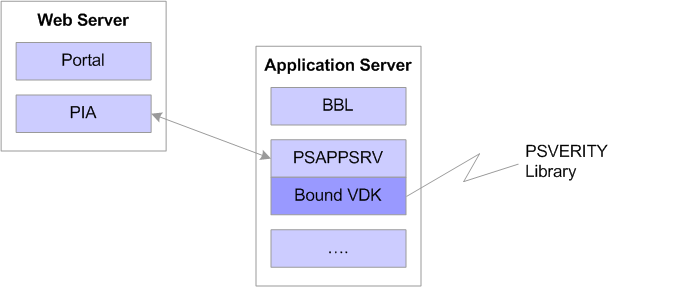
Type 1 search configuration: VDK bound to PSAPPSRV processes the request with the PSVERITY library
Note. This configuration has been used in PeopleSoft applications in all previous releases of the PeopleSoft Internet Architecture.
Type-2: Verity Running as a Separate Process Managed by the Application Server Domain
Having Verity run as a separately managed process enables application server domains running within the 64-bit framework to interoperate with Verity running within the 32-bit framework.
In this configuration, when the first search request is submitted, the PSAPPSRV server process spawns an auxiliary process to run within the application server domain. The spawned process hosts the VDK processing on behalf of the application server domain. A proxy search library within the application server routes search requests from the PeopleSoft Internet Architecture to the auxiliary search process.
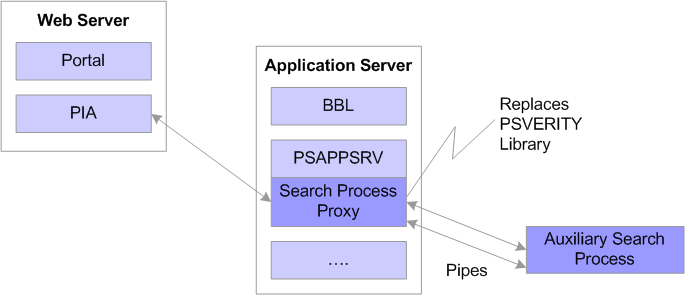
Type 2 search configuration: The spawned process hosts the VDK processing on behalf of the application server domain
The proxy search library and the auxiliary search process transmit data using efficient system resources (anonymous pipes). Having both processes running on the same computer can reduce performance degradation introduced from the extra communication layer of the network in a Type-3 configuration.
Type-3: Verity Running within a Separate Search Server
To centralize the configuration of the search features as well as the maintenance and storage of search indexes, you can implement the Type-3 search configuration.
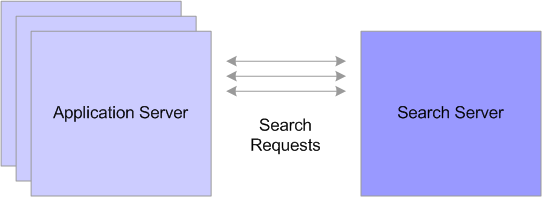
Type 3 search configuration: application server domain sends search requests to the search server on a separate physical machine
In this configuration, the application server domain routes search requests to the search domain running on a remote search server. Multiple application server domains may use the same search server to execute search requests. In this scenario, the application server domain is the "client," submitting search requests and the search domain is the "server," processing requests and returning results.
Note. Tuxedo must be installed on both the application server machine and search server machine.
Configuring Search to run within the Application Server (Type-1)This configuration requires the application server to be installed as outlined in the PeopleTools Installation guide for your platform. This installation process installs the required application server and Verity software.
In the Search section of PSADMIN, enter 1 for the Deployment Type parameter.
Values for config section - Search Deployment Type=1 Application Server Port= Remote Search Server Credentials=
Note. If you do not assign a value to the Deployment Type parameter, the system assumes the default configuration for your operating system.
Configuring Search to Run as a Separate Process (Type-2)This configuration requires the application server to be installed as outlined in the PeopleTools Installation guide for your platform. This installation process installs the required application server and Verity software.
In the Search section of PSADMIN, enter 2 for the Deployment Type parameter.
Values for config section - Search Deployment Type=2 Application Server Port= Remote Search Server Credentials=
Note. If you do not assign a value to the Deployment Option parameter, the system assumes the default configuration for your operating system.
Configuring a Separate Search Server (Type-3)Setting up a remote search server to process requests for application server domains requires you to complete configuration steps on the:
search server.
application server(s).
Configuring the Search Server Domain
To configure a separate search server:
Ensure the environment is set up correctly.
Configuring a search domain is comparable to creating an application server domain on an application server. You need to make sure:
Tuxedo is installed locally.
PS_HOME is available (locally or remotely)
PS_CFG_HOME is set correctly on the search server machine.
Launch PSADMIN, and select Search Server from the PeopleSoft Server Administration menu.
-------------------------------- PeopleSoft Server Administration -------------------------------- 1) Application Server 2) Process Scheduler 3) Search Server 4) Service Setup q) Quit Command to execute (1-4, q): 3
On the PeopleSoft Search Server Administration menu select 2) Create a domain, and enter a name for the search domain.
-------------------------------------------- PeopleSoft Search Server Administration -------------------------------------------- 1) Administer a domain 2) Create a domain 3) Delete a domain q) Quit Command to execute (1-3, q) : 2 Please enter name of domain to create :SAMPLE
Select 1) search, for a configuration template.
Configuration templates: 1) search Select config template number: 1
When prompted to configure the search domain and change any configuration values, enter y to indicate "yes."
In the [Startup] section, add the information required for the search domain to connect to the application database.
The values entered should be identical to the connect information in any application server domain connecting to the same database.
Note. The search domain must connect to the same database as the application servers sending requests to the search domain.
In the [Database Options] section, select the same options you use for other application server domains in your environment.
In the [Domain Settings] section, select the same options you use for other application server domains in your environment, including, for example, Add To Path for specifying database driver locations.
Note. Make note of the unique Domain ID value. It is required when configuring the application server domains using the search server.
Modify the options in the [PSSRCHSRV] section.
|
Min Instances, Max Instances, Service Timeout |
These parameters operate the same as PSAPPSRV. See PSAPPSRV Options. |
|
Search Server Port |
Enter the port address the search domain will monitor for search requests. The default is 7778. |
|
Application Server Credentials |
Enter a list of application server domains that will be using the search domain. The application servers need to be identified by Domain ID, Server ID, and port in the following format.
Note. Server ID can be an IP Address or a hostname. When multiple domains use the same search server, separate the entries by a comma (,). For example, the following illustrates how to enter two different domains running on two different servers.
Note. The Domain ID value can be found in the [Domain Settings] section of PSADMIN. |
Configuring an Application Server Domain to use a remote Search Server
Once you have a remote search domain configured, you then need to modify each application server domain that will use that search server to process search requests.
To configure an application server domain to use a remote search server:
Launch PSADMIN, and initiate the configuration interface for the desired application server domain.
Modify the [Search] section.
|
Deployment Type |
Enter 3 to indicate Type-3 configuration. |
|
Application Server Port |
Enter the port number on which the application server domain will "listen" for responses from the search domain. Make sure this value is the same port number you specified in the search domain in the Application Server Credentials parameter. |
|
Remote Search Server Credentials |
Specify the search server domain that will be used by the application server domain. The search server needs to be identified by Domain ID, Server ID, and port in the following format.
|
When prompted to configure Domains Gateway (External Search Server) indicate y for "yes."
Note. The Domains Gateway can also be enabled in the Quick Configure menu.
Setting Up Failover Search Domains
To provide high availability and to compensate for the possibility of issues with the network, a server machine, a search domain, or simply having to shut down a search domain for maintenance, you can configure failover search domains. In these situations, the unavailability of a primary search domain does not affect end users.
Failover search domains only process search requests when the primary search domain is unavailable. If the primary search domain is unavailable, the system seamlessly routes search requests to the next search domain specified in the failover string sequence.
For example, assume an application server domain has the following search domains specified in the search domain failover string in this order:
SRCH_PRIMARY
SRCH_FAILOVER1
SRCH_FAILOVER2
If SRCH_PRIMARY is unavailable, the system checks to see if SRCH_FAILOVER1 is available, and if so, begins routing search requests to SRCH_FAILOVER1. If SRCH_FAILOVER1 is not available, then the system checks the availability of SRCH_FAILOVER2, and so on. When the primary search domain becomes available again, the system begins routing search requests to that search domain.
To set up failover search domains:
Install and configure the number of failover search domains you require.
It is recommended that each failover search domain reside on a separate server machine for optimal failover coverage.
For each failover search server domain, specify the complete list of application server domains that could potentially use the search domain for failover coverage.
Use PSADMIN, or edit the PSSRCHSRV.CFG manually. Specify the application server domains using the Application Server Credentials parameter in the PSSRCHSRV section.
For each application server domain using a particular set of search server domains, modify the Remote Search Server Credentials parameter in the [Search] section to include the connect information for each search domain, with the primary search domain appearing first and a comma (,) separating multiple values.
<Domain ID>|<Server ID>:<port>,<Domain ID>|<Server ID>:<port>
For example,
Remote Search Server Credentials=SRCH_PRIMARY|ts-sun04:7778,SRCH_FAILOVER1|ts-⇒ sun05:7778,SRCH_FAILOVER2|ts-sun06:7778
Search Server AdministrationWhile the administrative tasks associated with search servers are similar to your application server or Process Scheduler administration, keep the following items in mind when managing search servers.
Working with Search Domains in PSADMIN
When administering search server domains, you use a subset of PSADMIN menu options.
-------------------------------- PeopleSoft Search Domain Administration -------------------------------- Domain Name: search01 1) Boot this domain 2) Domain shutdown menu 3) Domain status menu 4) Configure this domain 5) TUXEDO command line (tmadmin) 6) Edit configuration/log files menu 7) Clean IPC resources of this domain 8) Domain Gateway TUXEDO command line (dmadmin) q) Quit Command to execute (1-8, q) :
Using these menus is similar to the menus for an application server domain, except that items that are not applicable do not appear. For example, there are no menu options for purging cache, preloading cache, or setting up messaging servers because they do not apply in the context of search servers.
See Using PSADMIN Menus.
For search servers, the following options differ slightly from application server domain options:
|
Boot this domain |
For application server domains, you have options to boot a domain in serial or parallel mode. Because the number of server processes within a search domain are typically fewer than a large domain, the option of a parallel boot to save time is unnecessary. With search domains, you are not presented with boot options, and the domain boots in serial mode. |
|
Domain Gateway TUXEDO command line (dmadmin) |
The dmadmin is similar to the tmadmin interface. dmadmin is an interactive command interpreter used for the administration of domain gateway groups defined for a particular Tuxedo application. |
Locating Logging Information in Type-3 Search Configurations
The system writes logging information to these files:
TUXLOG for both the application server and search server domain.
APPSRV_MMDD.LOG for the application server domain.
SRCHSRV_MMDD.LOG for the search server domain.
Monitoring Domain Gateway Connections
The domain gateway is a subcomponent of a Tuxedo domain that allows it to communicate with another domain through the network. The domain gateway ensures that the application server and search server domains are successfully connected and able to transmit data. An application server domain and search domain can start independent of one another and do not report any obvious signs of being successfully connected when they start.
When working with search domains and troubleshooting Domain Gateway issues:
Ensure that the domain gateway is enabled. Check the Tuxedo logs of both the application server and the search server. Both logs should indicate the gateway connection.
Check machine and port configuration. Failure to connect, or connections with numerous disconnections can be caused by incorrect port and machine address information or another machine using the same port. Use canonical names if you are using a non-numerical IP address.
Use the dmadmin command line interface to monitor a Domain Gateway connection between a local and remote domain. Access this interface through the PeopleSoft Search Domain Administration menu in PSADMIN. The following commands can be helpful when working with search domains.
|
Command |
Description |
|
Use the pd (print domain) command to confirm whether or not the application server and search server domains are connecting and transmitting data. Confirm successful connection by viewing the 'Connected domains' list. The <LOCAL DOMAIN ACCESSPOINT_ID> is formed by prepending "SS" to the domain ID. For example, if the domain ID is SRCHSERV the value of <LOCAL DOMAIN ACCESSPOINT_ID> is SS_SRCHSERV. The following is sample output:
If the search domain is not connected to the application server domain you will see output similar to this:
This examples show only one application server domain and one search domain. In reality, multiple application server domains would connect to one search domain. The pd command lists the status of each of the application server domains connected to a search domain. |
|
Use the pstats command to extract monitoring statistics from the Tuxedo MIB regarding the domain gateway connection. This can help to identify the amount of requests being processed for application server domain clients. |
|
Displays and describes all dmadmin commands. |
See Oracle Tuxedo documentation for complete dmadmin documentation.
Building Search Indices
For a search server (Type-3 configuration), a Process Scheduler deployed on the search machine should be used for indexing. Because Verity libraries may be available only on the search machine, and because any index would be used by the search server on the search machine, it is recommended to build the indices on the search machine to avoid having to relocate indexes from other machines. A recommended approach is to deploy a Process Scheduler server along side the search server and specify that Process Scheduler server for generating indexes (PeopleTools, Search Engine, Administration, Schedule).
Note. For building search indexes on a Type-3 configuration, it is strongly recommended to use the PSNT Process Scheduler Server running on the same server machine as the Type-3 configuration.
If Verity is not supported on the operating system where your production application server domains run, another option is deploying an application server domain along side the search server. This application server would be accessible through its own web server instance possibly on a different port than the production application server. This provides access to an application server with Verity support, allowing the creation of indices interactively. Also, the indices would be created where the search server can locate them.
Working with IndexesThis section provides overviews of common controls and supported MIME types, and discusses how to:
Open existing collections.
Create new collections.
Understanding Common Controls
The following controls appear on the pages that are used for designing record-based, file system, or HTTP spider indexes.
|
Index |
Shows the name of the index that you opened or the name that you gave the index on the Add New Value page. |
|
Build Index |
Invokes the collection build program. Before clicking this button, select all of the appropriate options for the collection. |
|
Test Index |
After building an index, click to test that the build program assembled the index properly. The Test Index page contains a single text field with a query button. Enter text to search for in the collection and click the [?] button to submit the query. The results return a list of the keys that are stored by Verity in the collection. |
|
Show Logs |
View the log files that are produced by the collection build program during execution. This is used mainly for troubleshooting. |
|
Append to Verity Command Line |
This control is for PeopleSoft internal use only. |
Understanding Supported MIME Types
The following list contains the supported document MIME types. Any document that is not one of these types is ignored during the indexing process.
application/msword
application/wordperfect5.1
application/x-ms-excel
application/x-ms-powerpoint
application/x-ms-works
application/postscript
application/rtf
application/x-lotus-amipro
application/x-lotus-123
application/x-ms-wordpc
application/x-corel-wordperfect
application/x-wordprocessor
application/x-spreadsheet
application/x-presentation
application/x-graphics
application/x-keyview
application/x-ms-write
application/pdf
application/x-executable
message/rfc822
message/news
text/html
text/sgml
text/xml
text/ascii
text/enriched
text/richtext
text/tab-separated-values
text/plain
text/x-empty
image/gif
application/x-verity
Opening Existing Collections
To open an existing collection:
Select PeopleTools, Search Engine.
From the available menus, select the type of collection that you want to open, as in record-based indexes, file system indexes, or HTTP spider indexes.
On the Find an Existing Value tab, use the Search for drop-down list box to select the appropriate criteria (begins with or contains).
In the edit box to the right, enter the character string that reflects the appropriate begins with or contains criteria.
Click Search.
Creating New Collections
To create a new collection:
Select PeopleTools, Search Engine.
From the available menus, select the type of collection that you want to create, as in record-based indexes, file system indexes, or HTTP spider indexes.
Select the Add a New Value page.
Enter a name for the collection.
Click Add.
Specify the appropriate attributes for the collection as described in the following sections.
Save your work.
Note. You cannot create indexes of the same name even if they are of different types; for example, record, HTTP, or file.
Build the index.
Building Record-Based Indexes
The record-based index extracts data from database tables and inserts the data into BIF and XML files, which are then indexed by Verity. The individual creating the index chooses the records (tables) to be indexed.
Note. The record-based index supports only data that is stored in PeopleSoft databases.
This section discusses how to:
Modify record-based index properties.
Add subrecords to search indexes.
Modifying Record-Based Index Properties
Select PeopleTools, Search Engine, Record-Based Indexes to access the Design a Search Index page.
Parent Data Record
|
Record (Table Name) |
Enter tables, views, or a PeopleSoft view that contains data. To combine the data from multiple PeopleSoft tables, to create a view on those tables and specify the name of that view here. |
|
WHERE clause to append |
Fine-tune the data that you receive by entering a Structured Query Language (SQL) WHERE clause. |
|
Key returned in search results |
Use to synthesize the VdkVgwKey, which supports an XML-like syntax enabling you to modify the tag that is returned by Verity. You have the following options:
|
|
Edit Key |
Click to access the page where you can change the results that are returned by the Key returned in search results functionality. |
Fields
|
How to Zone the Index |
One Zone: Select to put all of the data into one zone. With this option, the collection builds more quickly but the application can't restrict searches to the portions of the index that come from a particular field. Field Zones: Select to create one zone for each PeopleSoft field on the record. Applications can specify that they want to access that particular zone in their searches. |
|
Field Name |
After you specify a record name, the fields in that record appear in this grid. Select the following options for each field in the record: Verity Field, Word Index, or Has Attachment (each option is explained in the following sections). |
|
Verity Field |
Select if the PeopleSoft field should be indexed as a Verity field. In general, PeopleSoft fields that contain a lot of descriptive text, such as description fields, should be indexed as word indexes (See the following definition) and PeopleSoft fields that contain metadata about what is being indexed (such as ProductID) should be indexed as Verity fields. |
|
Word Index |
Select if this PeopleSoft field should be indexed as a word index. See the preceding Verity Field definition for guidelines on defining a PeopleSoft field as a Verity field versus defining it as a word index. |
|
Has attachment |
Enables you to index attachments that are referenced in the field as uniform resource identifiers (URIs). Refer to the PeopleCode Developer's Guide for a description of file attachments. If this field contains the URL to an attachment, select this check box. The indexer downloads the attachment and indexes it as part of the document. This item is enabled only if the corresponding PeopleSoft field contains character data, because numeric fields cannot contain URLs. To use this field, you need a record that is designed with this feature in mind. In the record, each row has a text field that contains a URI or an empty string. The text must be a valid File Transfer Protocol (FTP) URI (including the login and password string) of the following form:
The third form references an entry in the URL table (Utilities, Administration, URLs). If the URL ID that is named in the name attribute is valid, the entire URI is rewritten with the part in brackets replaced by the actual URI. For example, if A_URLID is equal to ftp://anonymous:user@resumes.peoplesoft.com, the entire string in the previous example becomes ftp://anonymous:user@resumes.peoplesoft.com/path/to/file.doc and is treated like any other FTP URI. Rows of data with empty strings in the URI field are ignored with no error. If the string is one of these three valid URI forms and a document can be retrieved at that URI, the document is indexed with the same key as the rest of the row of data and is searchable. |
To add subrecords to the index, select the Subrecords tab, and insert the child records that you want to include in the index.
Adding Subrecords to Search Indexes
Select PeopleTools, Search Engine, Record-Based Indexes, Subrecords.
To index more than one record as a single document, the records must be hierarchically related. For example, the record that is specified on the previous page must be a parent of all the others. Formally, this means that the keys of each subrecord named must be a superset of the keys of the parent record. The parent record is the one that you specify in the Record (Table Name) field on the Primary Record page.
To add subrecords to an index:
Create and save the index definition.
Select PeopleTools, Search Engine, Record-Based Indexes, Subrecords.
Click the Add a new row button to insert the names of the records that are children of the parent record that is defined on the Primary Record page.
On the Primary Record page, the fields of the child record are added to the Fields grid. When you build the index, data from the child records whose keys match the row in the parent record is included as part of the parent record. When an end user searches for data that is found in the child record, the system returns a reference (VdkVgwKey) for the parent record.
Building File System (Spider) Indexes
You can index file systems that are local to the application server. This refers to any file system on the physical server on which your application server domain runs, and it also refers to any drives that are accessible from the application server machine. File systems might include file servers, report repositories, and so on.
The index is compiled by using vspider. The program descends into the directory structure recursively and indexes the file types that you've selected to be indexed. It indexes only files that Verity supports for collections.
This section discusses how to:
Set file system options
Define what to index
Setting File System Options
Select PeopleTools, Search Engine, Filesystem Indexes to access the Design a Search Index page.
|
List local filesystem paths to spider |
Specify the network file system path that contains the documents to index. Ensure that the local application server has the proper access to the file systems that you include in the list. For Microsoft Windows, this means the drive mappings must be set up from the applications server. For UNIX, this means the correct network file system (NFS) mappings must be set on the application server. To add a system path to the list, click the plus button. To remove a file system, click the minus button. |
|
Remap Path to This URL |
Do not use. |
Defining What to Index
Select PeopleTools, Search Engine, Filesystem Indexes, What to Index to access the What to Index page.
|
Index all Mime-types |
Select to index all MIME types on a website. |
|
Index only these Mime-types |
Select to index only a certain MIME type, and specify the file type in the MIME/Types Allowed list box. Separate multiple MIME types with a space. |
|
Exclude these Mime-types |
Select to exclude a set of MIME types, and specify the MIME types to exclude. Separate multiple MIME types with a space. |
|
MIME/Types Allowed |
Add a list of MIME types, separated by spaces, if you selected Index only these Mime-types or Exclude these Mime-types. |
Filenames
|
Index all filenames |
Select to index all file types. |
|
Index only these filenames |
Select to index only a certain file type, and specify the file type in the Pathname Globs List list box. |
|
Exclude these filenames |
Select to exclude a set of file types, such as temporary files, but to index all others. Also specify the file types to exclude. |
|
Pathname Globs List |
Add the files that you want to incorporate into your index. Separate the entries with spaces. You can use wildcard characters (*) to denote a string and “?” to denote a single character. For example, the string '*.doc 19??.excel' means select all files that end with the “.doc” suffix and Microsoft Excel files that start with 19, followed by 2 characters. |
Building HTTP Spider Indexes
HTTP spider indexes are similar to the indexes that the spider functionality compiles for the file system index. When using the spider index on a website, vspider starts at the home page of the site and then follows each link on that page to the next level of the site. For each page at the next level, vspider follows each link on each page. After following a link, vspider indexes all of the data on the target page.
You can specify as many websites as you want, and you can configure the depth, or number of layers of links, that vspider follows into a website and index.
This section discusses how to:
Define HTTP gateway settings.
Define what to index.
Defining HTTP Gateway Settings
Select PeopleTools, Search Engine, HTTP Spider Indexes to access the HTTP Gateway page.
|
Depth of Links to Follow |
Set the level of detail that you want to index within a certain site. If you enter 1, vspider starts at the homepage and follows each link on that page and indexes all of the data on the target pages. Then it stops. If you enter 2, vspider follows the links on the previous pages and indexes one more level into the website. As you increase the number, the number of links that vspider follows increases geometrically. Do not set this value too high, because it can impact performance negatively. You should not need to set this value higher than 10. |
|
List http://URLs to spider |
Click the plus button to add multiple URLs to spider. Click the minus button to remove a URL from the list. If you forget to include the http:// (scheme) portion of the URL, the system automatically includes it. URLs should contain only the alphanumeric characters as specified in RFC 1738. Any special character must be encoded. For example, encode a space character as %20, and encode a < as %3c. Additional examples are available. |
|
Stay in Domain |
Select to limit spidering to a single domain. For example, suppose that you are spidering www.peoplesoft.com and you select this option. If a link points to a site outside the PeopleSoft domain (as in yahoo.com), the collection ignores the link. |
|
Stay in Host |
Select to further limit spidering within a single server. If you select this option, the collection contains references to content only on the current web server or host. Links to content on other web servers within the domain are ignored. For example, if you are spidering www.peoplesoft.com and you select this option, you can index documents on www.peoplesoft.com, but not on www1.peoplesoft.com. |
|
Proxy Hostname and Proxy Port |
Enter a host and port for vspider to use. Enter the same settings that you would use in your web browser if you need a proxy to access the internet. |
Defining What to Index
Select PeopleTools, Search Engine, HTTP Spider Indexes, What to Index. The fields on this page are documented in a previous section.
Administering Search Indexes
After you design and build your search indexes, the Search Administration interface enables you to schedule when and how frequently the indexes must be rebuilt. An important aspect of maintaining the collections involves scheduling PeopleSoft Process Scheduler jobs that, on a regular basis, rebuild the collection completely or incrementally update the index. Search index administration also includes deleting old indexes and building indexes to support additional languages.
This section discusses how to:
Specify the index location.
Administer the search index.
Edit properties.
Schedule administration.
Share indexes between application servers and PeopleSoft Process Scheduler.
Specifying the Index Location
By default, search index files are located in:
PS_CFG_HOME/data/search/indexname/db_name/language_code
You can store indexes in different locations, but you need to specify the custom location in the CFG file for an application server, Process Scheduler, or search server. Use the [Search Indexes] section in the PSAPPSRV.CFG, PSPRCS.CFG, or PSSRCHSRV.CFG files to specify alternate search index locations and multiple locations, if necessary.
Note. This procedure assumes that you've already used the Search Index Designer to define, build, and store the search indexes that you will specify in the CFG file.
Note. You must edit the CFG file manually to include the locations. You do not add search index locations through PSADMIN.
To add a search index location:
Open the CFG file.
Locate the Search Indexes configuration section.
For example:
[Search Indexes] ;========================================================================= ; Search index settings ;========================================================================= : Search indexes can be given alternate locations if there is an entry here. ; Entries look like: IndexName=fs location (ie EMPLOYEE=c:\temp)
Add an entry for each search index location that you want to specify by using the following syntax:
index_name=location
For example, to specify the location for search INDEX_A and INDEX_B, your entries would look similar to the following:
[Search Indexes] ;========================================================================= ; Search index settings ;========================================================================= : Search indexes can be given alternate locations if there is an entry here. ; Entries look like: IndexName=fs location (ie EMPLOYEE=c:\temp) INDEX_A=c:\temp INDEX_B=n:\search
Note. Make sure that your entries are not commented out with a semicolon (;) appearing before them.
Note. For the Process Scheduler configuration file, PSPRCS.CFG, include the same location as specified in the application server configuration file.
Note. When specifying the index to be generated in a custom location, the directory structure the system builds within the custom location will be slightly different from that built in the default location. The directory structure within custom index locations will not have a directory for the database name.
Save the CFG file.
Administering the Search Index
Select PeopleTools, Search Engine, Administration to access the Search Index Admin page.
|
Index |
Displays the name of the index so that you can identify specific indexes. To select an index, select the check box to the left of the index name. |
|
Index Location |
Displays the current location of the index. |
|
Edit Properties |
Click to access the interface for changing the index location and to build indexes to support additional languages. |
|
Schedule |
Click to access the interface for scheduling the program that maintains your collection. |
|
Delete checked Indexes |
If you have selected indexes to be deleted, click this button to remove them from the system. The deletion process deletes the index definition and the collections that are stored in the file system. |
Note. If you attempt to delete a scheduled index, you may see SQL errors on IBM DB2 UDB or Sybase database platforms.
Editing Properties
Select PeopleTools, Search Engine, Administration, Edit Properties.
|
Index Location |
Displays the current location of the index. |
|
Language Code |
Select the language for which you want to build an index. |
|
Language to Map |
Currently disabled. |
|
Build |
After you add the additional indexes, click to create the indexes. |
Note. Style files are located in the style subdirectory of the index. To make style changes, apply them to the files in this directory.
Scheduling Administration
Select PeopleTools, Search Engine, Administration, Schedule.
|
Add a new Recurrence Definition |
In PeopleSoft Process Scheduler, you define run recurrence definitions that enable you to schedule jobs to run at regular intervals, such as monthly, weekly, daily, and so on. The more current you keep the collections, the more accurate your search results will be. |
|
Type of Build |
Rebuild: Select to drop the existing collection and rebuild a new collection. This applies to all types of collections. Increment: Use only for the spider indexes. For record-based indexes, only the Rebuild option is available. |
|
Run Recurrence Name |
Select the appropriate run recurrence definition for the collection maintenance requirements. |
|
Server Name |
Specify the PeopleSoft Process Scheduler server on which you want the build program to run. The PeopleSoft Process Scheduler system must be installed and configured before you can schedule the collection build program to run as a job. |
Sharing Indexes Between Application Servers and PeopleSoft Process
Scheduler
The index files reside on a file system at the home location and must be accessible to all application servers and process schedulers that will manipulate the index. An application server uses the index for searching while the process scheduler invokes an Application Engine program that builds the indexes. Therefore, if you are running a process scheduler on a different machine than the application server, ensure that the index files are accessible to both. You can do this three ways:
Make a Microsoft Windows shared drive or NFS file system available for the index.
Specify the index location in both the application server and the process scheduler to point to the shared directory.
Run an instance of the process scheduler on the application server host and schedule only the building of indexes on this process scheduler.
Because the process scheduler and the application servers are running on the same host, they create and read files from the same location.
Use an external program such as FTP or Secure Copy (SCP) to copy all of the files and directories in the index home location from the process scheduler host (after the index has been built) to the application server host so that they are available for searching.
Modifying the VdkVgwKey Key
To make the VdkVgwKey more readable and easier to parse, use the following XML-like syntax:
<field fieldname='MYFIELD'/> <row/> <pairs/> <sql stmt="SELECT 'Y' FROM PS_INSTALLATION"/>
Fieldname and the SQL statement support single and double quotes, as well as no quotes at all (in which case only the first word is considered part of the option).
Using double quotes for the SQL statement is recommended.
The SQL statement must return only one column.
Multiple rows are ignored. Trying to return more than one column results in a collection-build-time error.
Currently, the only tag style that is supported is <tag/> with the slash (/) at the end.
The VdkVgwKey can include any amount of literal text interspersed with the tags.
This text is copied into the VdkVgwKey that goes into the BIF file, unmodified.
Field names are automatically set in uppercase.