About Discovery
Discovery is the process that allows you to identify the business components that make up a composite application and to understand how they relate to one another (their dependencies.) This section explains the concepts and processes you must understand to get exactly the information you need during the discovery process. It explains
-
how Business Transaction Management models a wide variety of component types
-
the steps of the discovery process
-
how you can limit discovery for technologies that include a large number of intermediate endpoints
-
how you can manually register services that are not automatically discoverable
-
how you can model JDBC calls
For information about resolving discovery problems, see Resolving Discovery Issues.
What Can Be Discovered
Business Transaction Management can discover the following elements:
-
Application components: this includes the logical service that designates a deployed component type, the endpoints (instances of that service), and the operations that can be invoked on an endpoint.
-
Containers
-
The dependencies between components
Business Transaction Management can discover a wide variety of component types and the containers in which they reside. The same model is used to represent interconnected components no matter what the component type: the model consists of services that interact by sending request and response XML messages. The model also assumes that each of the services is described by a WSDL specifying the service's location and its interface. If such a WSDL does not exist because the component is not a web service, Business Transaction Management constructs an artificial WSDL that it uses to enable the system to process the component consistently. The model is illustrated by the following figure.
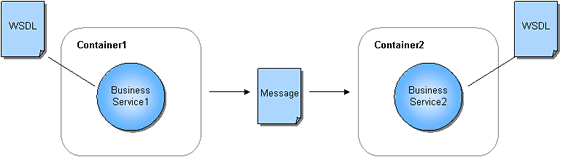
Description of the illustration svcs_and_msgs.gif
For example, if you have a composite application consisting of a web service that calls an EJB that accesses a database via JDBC, it will be modeled as three services that communicate using XML messages. When you use the Business Transaction Management console to view discovered components, these are listed as services, and the messages they exchange are listed as operations belonging to these services. A message corresponds to either the request or response phase of an operation.
In some cases, the observed traffic type suits this model perfectly; for example, a JAX-WS service or a JAX-RPC service. In other cases, Business Transaction Management must map the component type in a way that is compatible with its basic model. The detail of this mapping might be important if you plan to discover and monitor components that are not web services.
Business Transaction Management discovers components by observing the message traffic that flows from one component to another. Based on the data derived from observing this traffic, Business Transaction Management can also discover how these components are related to one another and draw a map of their dependencies. Dependency information provides an accurate picture of how your composite application is really behaving. It might alert you to the fact that certain components are never called, and it provides a basis for defining business transactions.
The Discovery Process
The most important fact to understand about discovery is that it is entirely traffic-based. If messages are not flowing through the observed endpoints, Business Transaction Management cannot discover any application components nor can it discover the dependencies between these components. When in doubt, send traffic. This section outlines the steps involved in discovering distributed application components in your observed environment. To learn more, read the sections that are linked to from the following steps.
Before discovery can happen, you must install the observers in the environment you want to observe, and you must configure the observer communication policy to define communication between the observers and the monitor or monitor groups responsible for the further processing of the data discovered by the observers.
Discovery happens in two stages: during the priming stage, observed traffic causes the observer to start communicating with the monitor; during the observation stage, a measurement policy is applied to the data that flows from observer to monitor. This is to say that it might take a little while to build a complete picture of your working system. One symptom of this is that if you send 100 messages and Business Transaction Management reports seeing only 98, the messages that are not accounted for are the messages that served to prime the discovery process.
Discovery involves the following steps:
-
Send traffic through your system.
-
Check the containers being observed. If load balancers are being used, these must also be visible. (Restarting the containers after installing Business Transaction Management is not enough to make them visible, you must send traffic to have them be seen.)
-
View services to see that all the services you are interested in observing have been discovered.
-
Check that measurements are being taken by looking at the Summary or Analysis tab for a service. Throughput, traffic, maximum response time, and average response time should be available for all the services involved in message traffic. If measurements are inaccurate or missing, it's possible that not enough time has elapsed for Business Transaction Management to calculate traffic measurements or perhaps monitoring was disabled.
-
Look at dependencies in the Service Map to see how traffic is flowing in your system.
-
Adjust as necessary. Generally speaking if the discovered picture does not meet your expectations, the first thing to do is run more traffic to make sure Business Transaction Management has had time to see all pieces of your system. If that does not resolve your problem, you might need to do one or more of the following:
-
enable probes that are appropriate for the objects you are trying to discover.
-
manually register a service; see Manually Registering a Service.
-
resolve discovery problems due to versioning policy or replication problem.
-
Limiting Discovery
Depending on the technology, some messages flow directly from a client to a service; others flow through a host of intermediate endpoints before they reach their actual destination. Such intermediate endpoints might comprise the implementation of a messaging system, a job scheduling system, a distributed system, and so on. When installing probes for technologies that use intermediate endpoints, Business Transaction Management allows you to specify whether you want to monitor all endpoints or just the endpoints at the edge of such systems; often these are the endpoints that directly represent the business services of interest. By default, the monitoring of intermediary endpoints is turned off. This improves monitoring performance and eliminates data that is not essential to monitoring your distributed applications.
Figure 3-1 shows a number of observers monitoring endpoints conveying messages from a client to a service (EP5). Note endpoint EP1 and endpoint EP4 at the edge of the message flow. Note also the dotted line which indicates the relaying of context information. If you choose to monitor all endpoints, all the endpoints shown in the figure will be discovered and monitored by Business Transaction Management.
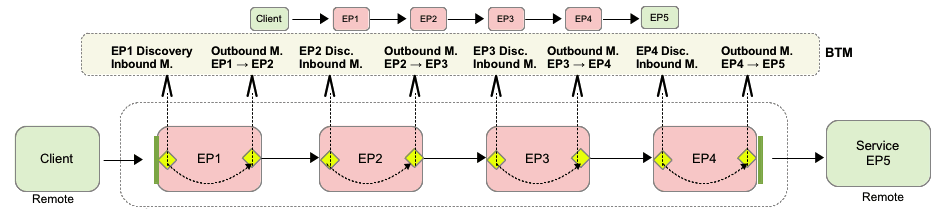
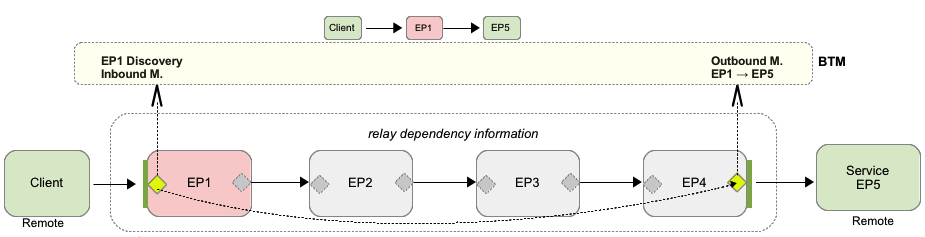
Figure 3-2 shows you how message flow is modeled if you choose to restrict the number of endpoints monitored. In this case, only the client, EP, and EP5 are discovered and monitored. Context information is still conveyed from the client to the final recipient, EP5.
The observer communication policy gives you the option of controlling the monitoring of intermediate endpoints for SOA, OSB, and EJB probes. Options for monitoring different technologies vary slightly. For example, in monitoring EJBs, you have the following options: you can choose to model the edge of flow, which models only the first local EJB in a local request flow; you can choose to model all, which models all local EJBs; and you have the option to model none (no local EJBs). How you model local EJBs has no effect on the modeling and monitoring of remote EJBs, which are always monitored. For additional information about the observer communication policy, see Configuring the Observer and Monitor, especially Advanced Settings Field Reference, which describes the options you use to control the monitoring of intermediate endpoints.
Modeling JDBC Calls
Very large transactions or high JDBC volume might strain BTM resources when the JDBC probe is enabled and instance logging is turned on. It is also possible that calling one operation can result in a large number of calls to the database. For example, one Fusion Application operation can translate into hundreds of SQL statements. To reduce this overhead and free up resources, you can elect to have Business Transaction Management record a summary of these calls rather than noting each one individually. If you decide to enable JDBC summary but also want to investigate individual calls, you can use data base management tools to do so.
This section describes the information displayed by BTM when JDBC summary is enabled.
When JDBC summary is enabled, JDBC calls are represented as shown in the figure below. The measurements given for the JDBC call specify the average time for the call and the number of calls. In the case illustrated below, 22 calls have been made, averaging 20 ms each. In summary mode, the operation name is always execute.
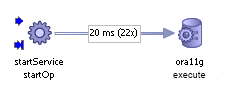
To enable JDBC summary, you must change the observer communication policy as described in Advanced Settings Field Reference.
When JDBC summary is enabled, BTM records all JDBC operations individually, but when logging message content, the information is sent in one abridged summary observation per caller, which includes payload information only for the number of slowest SQL statements and faults you specified in the observer communication policy settings. The main idea behind the JDBC summary option is to make BTM performance more efficient while, at the same time, allowing you to get information about slow or faulty operations.
Effects of Enabling JDBC Summary
With JDBC summary enabled, the transaction instance and message log display will include two additional columns showing the summary count and fault count for each calling service. (In the observer communication policy you can specify a time-out value. If SQL call times exceed this value, BTM will send an extra time-out summary message; the response time for this time-out message will be shown to be -1.)
The next figure shows the additional information shown when JDBC summary is enabled. Note the way response time is reported for the execute statement (only part of the display is shown). Any row containing summary information will be marked with a sigma symbol.
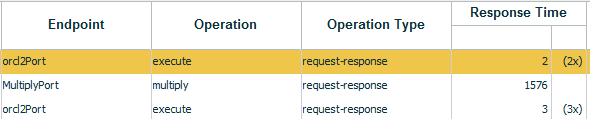
Two additional built-in properties are defined for the request phase of a message to support JDBC summary mode: aggregateCount and aggregateFaultCount.You can use these properties in searches. For example, you could look for an execute message whose aggregate fault count is greater than 100.
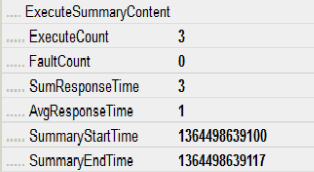
When you display message content for a summary observation, you will see a section titled "Execute Summary Content" that shows the following information for summary observations:
-
ExecuteCount: the total JDBC calls made, including exceptions
-
FaultCount: count of all JDBC exceptions that occurred in this summary
-
SumResponseTime: The sum of all SQL statements' response time
-
AvgResponseTime: The average of response times across the summed JDBC call
-
SummaryStartTime
-
SummaryEndTime
The following figure shows the part of the display that relates to summary observations.
In the communication policy, you can also specify the number of exceptions you want captured. For each such exception, the following information is shown:
-
ArrivalTime: the time when the exception arrived
-
Content: The SQL statement where the exception occurred
-
FaultContent: The full text of the SQL exception content
-
The service, and operation that called the SQL statement
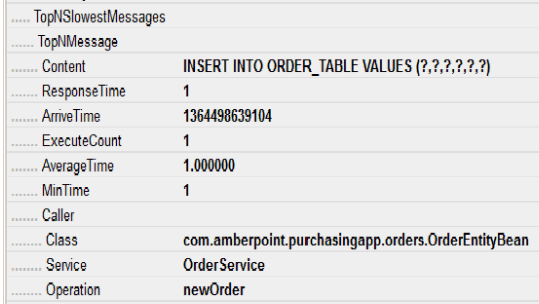
In addition, for each of the N slowest SQL statements, the following information is shown. (You specify a value for N using the communication policy.)
-
Content: SQL statement name (but not the parameters passed to these)
-
ResponseTime: the execution time in microseconds for this SQL statement
-
ArriveTime: Start time
-
ExecuteCount: how many times this SQL statement was called
-
AverageTime: the average time for all SQL statements recorded
-
MinTime: the minimum time for all SQL statements recorded
-
Caller method, service and operation information for caller of SQL statement
Times for ArriveTime, SummaryStartTime, and SummaryEndTime are given using a UNIX timestamp (based on seconds since 1/1/1970). To convert this value to a readable date and time, look for a conversion tool on the Internet by searching for "UNIX time conversion."
Updating Transaction Definitions After Changing Summary Options
If you have already created a transaction and you decide to change the setting of JDBC summary, you will need to run more traffic and then update your transaction definition. This is because, depending on your JDBC summary setting, BTM will discover the JDBC service operations for SQL execution under different names.
-
When JDBC summary is disabled, the
executePrepStmt,executePrepStmtBatch,executeQuery, andexecuteBatchstatements will all be individually discovered -
When JDBC summary is enabled, the
executePrepStmt,executePrepStmtBatch,executeQuery, andexecuteBatchstatements will all be combined into a singleexecuteoperation
If you change the JDBC summary setting after creating a transaction definition, please do the following:
-
Run traffic through the JDBC service again to discover the new operations.
-
Edit the transactions that use JDBC services by removing the old operations and including the newly discovered ones.
If you don't update your transaction definition, BTM will be unable to recognize the newly discovered JDBC service operations as being part of the transaction, and it will not be able to record measurements for traffic to that service.
Registering a Service Manually
There are cases where Business Transaction Management cannot discover SOA-type components directly: for example, the service resides in a container that cannot be observed or the service resides in a container where no observer has been installed. In such cases, it might still be able to discover the object if you manually register the service.
While it is possible to discover services in this way, it is not usually possible to monitor their performance without the services being directly observed. For more information, see Manually Registering a Service.