Alternate Integration Scenarios
This chapter describes how implementers can address common scenarios with the VCP Base Pack integration.
This chapter covers the following topics:
- Information Sharing Options
- Combining Extracts and Collections Across Systems
- Multiple JDE E1 Instances
- User Security
Information Sharing Options
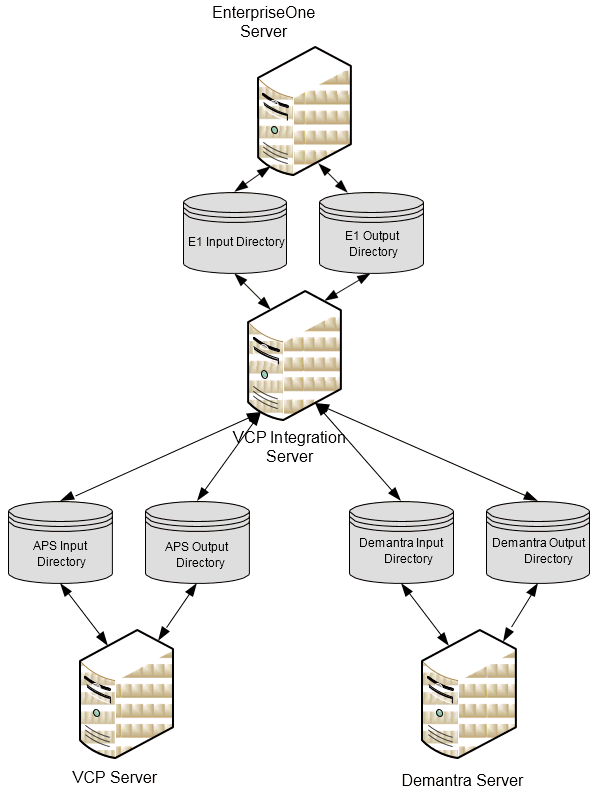
The JDE E1 or PeopleSoft source system and the VCP integration system are typically on different servers. If these servers run different operating systems, you must ensure that the directories can communicate with each other.
For example, many JDE E1 systems operate on the AS400 platform. However, the VCP integration is not supported on the AS400 platform. Directories cannot be shared between AS400 and Unix/Linux systems, so an alternate sharing strategy must be adopted.
Directories used in the integration can be either:
-
Shared or
-
Non-Shared
The use of shared directories is the optimal solution. However, for security or server technology reasons, it might not be possible to use shared directories. In this case, an alternate sharing strategy is to use File Transfer Protocol (FTP).
Shared Directory Access
Shared directories can also be referred to as a network shared drive or as a shared mount.
In the shared directory scenario, a directory needs to be accessible to all the servers accessing that directory, although the directory itself does not need to be on any of the servers involved.
The shared directory must be read and write accessible to any server that needs to read or write files stored on the directory.
-
The ERP and ODI servers both need access to the JDE E1 Input Directory (E1InputDir) and JDE E1 Output directory (E1OutputDir).
-
VCP and ODI servers both need access to the APS Input directory (APSInputDir).
-
Demantra database and ODI servers both need access to the Demantra Input directory (DemInputDir) and Demantra Output directory (DemOutputDir).
Note: DemInputDir and DemOutputDir must be configured in the Demantra database using the data_load.setupSystemObjects() script.
Additional Information: For additional information, see Setting Up Database Directories.
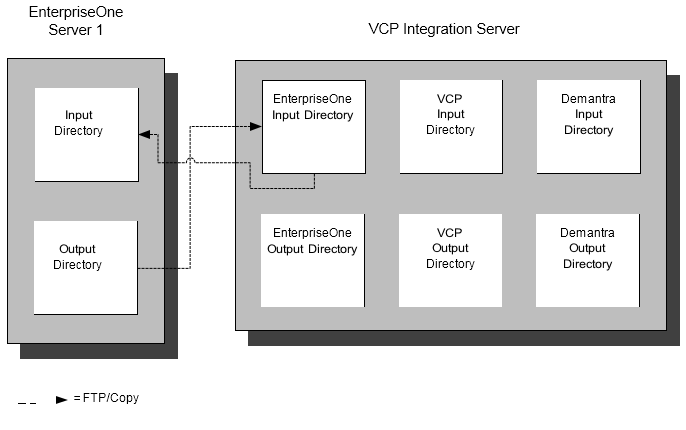
Non-Shared Directory Access
This integration does not provide out-of-the-box file transfer mechanisms between ERP servers and the ODI server when directories cannot be shared . In this case:
-
FTP can be used to copy the files to and from other servers in the solution.
-
The files can also be manually copied.
Oracle recommends that the directories on the application servers are paired with the six core directories on the ODI server.
Note: If there are multiple JDE E1 servers, then each server has a pair of directories that equate to the E1InputDir and E1OutputDir directory pair on the ODI server.
You can also customize the PREPROCESSHOOKPKG ODI package to do the JDE E1 to ODI FTP transfers.
Additional Information: For additional information, see Optional User-Defined Customizations.
Examples of Shared and Non-Shared Directory Access
The following diagrams summarize the directory structures in a both shared and non-shared directory scenarios:
When systems are compatible, it is possible to have shared, networked, or mounted directories, where both servers have common read and write access.
This could be a scenario where:
-
All the servers are Windows servers, or
-
All are Linux/Unix servers, or
-
Third party software has been installed to enable mounted drives between Windows and Unix systems.
When systems are incompatible and shared, networked or mounted directories cannot be used, you could use a different strategy such as FTP.
This could be a scenario where:
-
On server is AS400, and the others are Windows
-
There is a mix of Unix and Windows servers
-
Security policies restrict shared directories
Combining Extracts and Collections Across Systems
There are two ways that user extension can be used to perform the extraction and collection processes with a single action.
-
For JDE E1 users only: On the JDE E1 server, all JDE E1 UBEs support pre-process and post-process command scripts. In this case, the UBE post process script can be used to activate the collection process on the EBS server.
-
On the VCP Server, all-concurrent processes support pre-process and post-process ODI packages and SQL hooks. In this case, the pre-process can be used to call a runubexml extract script on the JDE E1 server.
Example: Using a JDE E1 Script to Call VCP Collections
As an example, consider the main JDE E1 extract and Legacy Planning Load. You could trigger the combined process from JD E1 by following these steps:
-
Create a remote script on the JDE E1 server that calls the VCP Base Pack Integration collections process on the VCP server.
-
Call the script created above from the UBE post-process option.
In this setup, every time you trigger the JDE E1 extract, the VCP Base Pack Integration collections process is automatically triggered when the extract finishes.
Example: Using a VCP Script to Call JDE E1 Extracts
You could also trigger the combined process from VCP JDE E1 Collections Menu by following these steps:
-
Create a RUNUBEXML batch script to run the planning extracts on the JDE E1 server.
-
On the VCP server, create a script to call the JDE E1 RUNUBEXML script remotely.
-
Incorporate this script into the ODI pre-process script.
In this case, triggering the collections load from within the VCP Base Pack Integration menu. Before running the collections process, the extracts on the JDE E1 server trigger automatically.
Additional Information: For additional information, see Optional User-Defined Customizations.
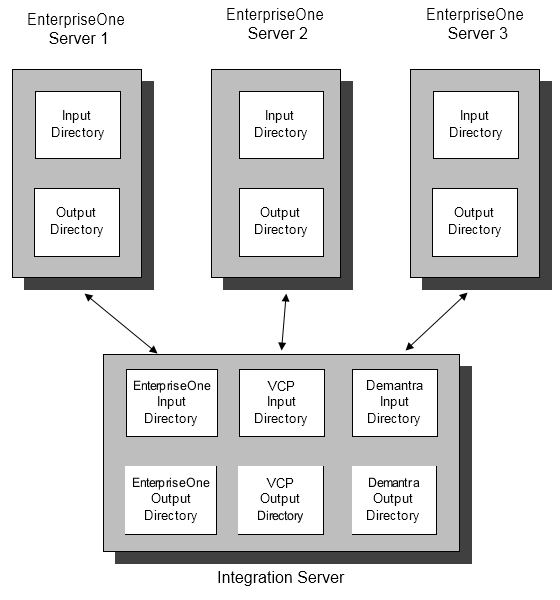
Multiple JDE E1 Instances
If there is a single ERP server, this server can directly write to and read from E1InputDir and E1OutputDir; no further setup is required.
This integration needs extensions to support multiple ERP instances. You can run multiple ERP instances by either:
-
Running in sequence
-
Setting up separate directories
In source environments with multiple instances, it is critical to ensure that there is no conflict between global entities such as trading partners or calendars.
Running in Sequence
In this scenario, the user runs the ERP instances' extracts and collections in sequence. The run sequence for a sample two-instance environment is as follows:
-
The JDE E1 Instance A extracts data to E1OutputDir.
-
Legacy collections run for JDE E1 Instance A.
-
Back up the extracted data from JDE E1 Instance A for use in the latter publish process.
-
After JDE Instance A's collection is complete, JDE E1 Instance B extract to E1OutputDir begins.
-
Legacy collections run for JDE E1 Instance B.
-
Back up the extracted data from JDE E1 Instance B for use in the latter publish process.
If this method is chosen, then the entire processing for Instance A, from extract through to collections must be completed before Instance B can begin its extracts to ensure that there is no conflict.
Also note, the publish process accesses files used in the previous extract process. Extracted files for the instance being published must be present in the JDE E1 extract directory at the time of the publish. The publish extracts do not filter by branch, user extensions are required.
Overlapping Collections
You can also set up separate directories where each ERP instance writes its extracts from E1OutDir or reads its imports from E1InputDir.
The run sequence for a sample two-instance environment with separate directories includes:
-
Extracts on JDE E1 servers can be run in parallel:
-
JDE E1 Instance One extracts to Instance One extract directory.
-
JDE E1 Instance Two extracts to Instance Two extract directory.
-
-
Collections must be run in sequence:
-
Copy the JDE E1 Instance One files to E1OutDir and run Legacy collections JDE E1 Instance Two.
-
Copy the JDE E1 Instance Two to E1OutDir and run Legacy collections for JDE E1 Instance Two.
-
The advantage of this method is a shorter processing time. The disadvantage is that you need to set up multiple directories and perform different file copies.
This method also requires user-defined integration extensions to copy a JDE E1 instance's extracts to the common JDE E1 Output directory.
User Security
There is no user security synchronization between ERP and Oracle Value Chain Planning Suite.
You must be created as a user in the Oracle Value Chain Planning suite and assigned one or more of the following responsibilities:
-
Advanced Supply Chain Planner (for both forecasting and planning functions)
-
Demand Management System Administrator
-
Advanced Planning Administrator
Single sign-on configuration is supported between Oracle Value Chain Planning suite and Oracle Demantra applications. Users created in the Oracle Value Chain Planning suite can access the Oracle Demantra system without additionally logging in to Oracle Demantra.
Additional Information: For more information on configuring Single Sign On between Oracle EBS Value Chain Planning and Oracle Demantra, please refer to the Oracle Demantra Implementation guide.