| Oracle® Health Sciences Clinical Development Analytics Administrator's Guide Release 2.2 for Standard Configuration E25023-03 |
|
|
PDF · Mobi · ePub |
| Oracle® Health Sciences Clinical Development Analytics Administrator's Guide Release 2.2 for Standard Configuration E25023-03 |
|
|
PDF · Mobi · ePub |
This chapter contains the following topics:
Preliminaries to Using Oracle Healthcare Master Person Index Deduplication Projects
Processes for Using Oracle Healthcare Master Person Index Deduplication Projects
Oracle Health Sciences Clinical Development Analytics' Match Rules
Multi-source integration is an optional capability introduced in OHSCDA 2.2. It provides a mechanism for identifying duplicate dimension value records, merging them into a single record, and adjusting fact record foreign keys accordingly. All of this can be done when loading the OHSCDA warehouse from multiple transactional databases.
The purpose of multi-source integration is to permit data to be loaded into the OHSCDA warehouse from two or more source databases, while providing means to ensure that duplicate records across the sources are represented by single records in the warehouse. For instance, every database used as a source for OHSCDA will have a Studies table. If you load data from two source databases, and both have an entry for the same investigator (for example, Joseph Smith), it is desirable that this investigator be represented only once in the Investigator dimension in the warehouse.
There are two reasons why deduplicating dimension data is important:
If it is not done, the duplicated data will be displayed as multiple separate rows in OBIEE prompts, which are used to dynamically filter the data to be displayed in reports. For example, there would be two rows in the Prompt drop down list for Joseph Smith.
| Investigators |
|---|
| Andy Jones |
| Claudine Roberts |
| ..... |
| Joseph Smith |
| Joseph Smith |
| ..... |
A user wanting to see all the data for that Investigator would have to select both rows. Multiple selections might not always be possible).
The duplicated data will result in multiple rows in reports where there should only be one row. For instance, suppose a report asks for Number of Queries by Investigator. Assume that database 1 records 20 queries for Joseph Smith, and database 2 records an additional 30 queries for Joseph Smith. Presume that these are distinct queries. Then, if no deduplication was done, the result of the query would be
| Investigator | Number of Queries |
|---|---|
| Joseph Smith | 20 |
| Joseph Smith | 30 |
| ..... | ..... |
To arrive at the final number of queries, you will have to take the sum of the two rows.
Deduplication of dimension data eliminates both these problems from the presentation of the data in the dashboard.
Note:
It is necessary to identify which records are duplicates, before deduplication can be performed. For instance, determining whether Joe Smith and Joseph Smith are two different people, or are the same person, is a matter of identification. This must be performed by a person with the necessary knowledge and to a certain extent this process can be embedded in rules. The details of the process are described below.Figure 3-1 illustrates how one dimension is loaded when using OHSCDA's multi-source integration capability.
Figure 3-1 OHSCDA Multi-Source Integration Paths
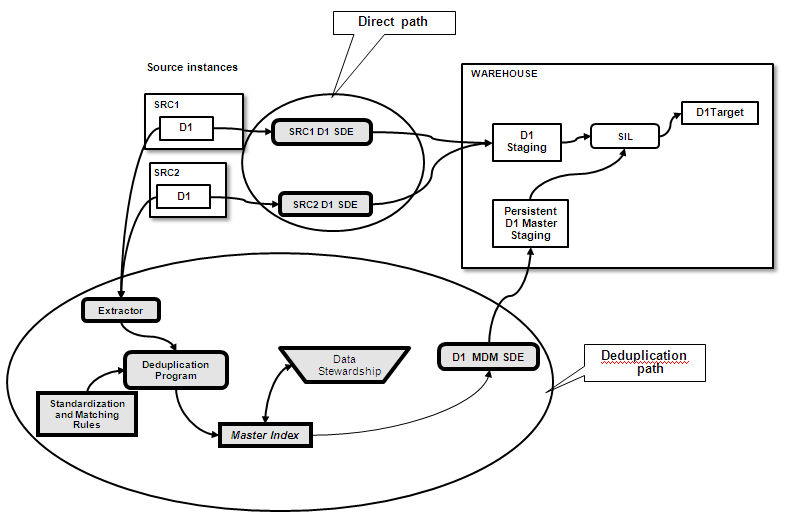
Data for the dimension flows into the warehouse by following two paths:
Direct path - This is the path by which data is always loaded, whether or not it needs deduplication.
Deduplication path - This is a supplementary path that supports the identification and confirmation of matches, and the loading of that information into the warehouse.
The two paths converge during the source independent load (SIL) execution of the dimension. The SIL applies the results of deduplication that arrived through the deduplication path to the complete set of data that arrives through the direct path. When SIL execution completes, the deduplication information has been applied to the warehouse table for the dimension. For every set of duplicates that has been identified, there is only one record in the warehouse that will be accessible by queries from OBIEE.
Note:
OHSCDA retains all the records in the duplicate set, but marks them as merged. OHSCDA creates a single best record in lieu of them, and it is this record which is accessible to OBIEE queries.Following is the sequence of the loading process when it includes deduplication:
The deduplication system performs all deduplication, provides all attributes, and captures linkages between source records and result records.
The Data Steward makes decisions about potential matches not automatically resolved by rules. Until this happens, such records are treated as singletons.
An SDE mapping that knows how to read the dimension from the Master Index does so, writing records to a persistent staging table.
On the Direct Path, the source-specific SDE mappings for the dimension executes, populating the dimension staging table with all the contributor records (that is, the raw materials for deduplication).
On the Direct Path, the SIL writes the contributor records to the dimension target table.
Turning its attention to the Deduplication Path, the SIL reads the Persistent Master Staging table. If the SIL finds any new records there (telling what records are to be considered duplicates), it adjusts the dimension target table so that those sets of duplicates already in the target table are reduced to single records.
Note:
All the records stay in the target, but the ones composing a group of duplicates are marked as merged, while a new Single Best Record representing the whole set is created in the target table. The merged records are excluded from OBIEE queries, so in effect there is only one record in the warehouse for the set.If duplicate dimensions are merged into a single representative record in the warehouse, the ETL process must also adjust the foreign keys of fact records in the warehouse so that they point at the correct dimension record.
In the source databases, records that contribute to warehouse facts have foreign keys to source dimension table records. For instance, suppose that in source 1 there is a record describing a query sent to an investigator. The identity of the investigator will be specified by the value of the investigator foreign key in the queries table. The value will match the value of the investigator table primary key for the relevant investigator.
If no deduplication is applied to the investigator while extracting records to the warehouse, the following sequence occurs:
Records from the investigator table are loaded into the warehouse dimension table. Each record is given a new, warehouse-specific, primary key value in the Row_wid column. The primary key value of the record in the source database is retained in the record's integration_id column. So the Investigator table in the warehouse will be as follows:
| Row_wid | Investigator | Integration_id |
|---|---|---|
| 1 | Andy Jones | 101 |
| 2 | Claudine Roberts | 102 |
| ... | ... | ... |
| 13 | Joseph Smith | 113 |
Fact records are loaded next. As each fact record is entered into its warehouse target, its foreign key value is set for each dimension. A query fact table would start out like this:
Deduplicating a dimension involves reducing each set of duplicates across the various databases to single representations of each unique entity.
Deduplication is performed separately for each dimension depending on whether they are ascertained to contain duplicates. For example, you might have two instances of Oracle Clinical, one for studies for Product A and another for studies for Product B. Then you could load the Study dimension from both databases into OHSCDA without need for deduplication. However, if some of the same Investigators were used for studies in both databases, then you would have duplicates on the Investigator dimension across the databases. In this case, you will have to deduplicate the Investigator dimension.
In general, deduplication of a dimension is required if you know (or suspect) that there are duplicates in the dimension, that is, there are two records standing for the same entity instance.
In general, a dimension loaded from two or more databases is a candidate for deduplication. However, this cannot be assumed. Deduplication of a particular dimension is not needed if you are confident that there are no duplicate records in the source tables for that dimension in the source databases. For example, if one database is used only for Product A, and another only for product B, there is no need to deduplicate the Product dimension when loading data from those two databases.
Likewise, if you are loading data from only one database, you probably do not require multi-source integration. However, there is a possible exception to consider - if your single source database itself contains duplicates on a dimension, you could use multi-source integration to manage those duplicates. For example, suppose your list of investigators includes both Joe Smith and Joseph Smith, both the same person. These will give rise to multiple rows in prompts and reports, when there should be only one. You can clean this up by correcting the source database, which entails redirecting all foreign key references from Joe Smith to Joseph Smith, and then deleting the entry for Joe Smith. Or you can use OHSCDA's multi-source integration, which allows you to produce the same effects.
You may have undertaken to ensure that values for a dimension are coordinated across source databases. Coordination typically means that there is no Investigator in Source 2 that is not also present in Source 1, and that the name of each investigator is spelled identically in both databases. Depending on the nature of the coordination procedure, it may also be the case that the set of investigators in both databases is identical - every investigator in Source 1 also appears in Source 2, and vice versa.
This coordination can be accomplished by several means:
A standard operating procedure that is carefully followed when creating Investigator names.
A procedure under which you create new Investigators only in Source 1, and they are programmatically propagated to Source 2 (for example, by Oracle AIA).
Both databases being populated from a third table that is designated as the single gold source, for example, through use of a Master Data Management tool.
If you are loading the Investigator dimension in OHSCDA from two source databases where Investigator has been coordinated, it is necessary to deduplicate the dimension when loading its values from the two (or more) source databases. Even though there is no uncertainty about whether Joseph Smith in Source 1 is the same person as Joseph Smith in Source 2, if you simply load the Investigator dimension from both sources into the OHSCDA warehouse, you will end up with two entries in the Investigators table for Joseph Smith, with the resulting problem -- multiple rows in prompts and reports.
If you want to forestall these problems, deduplication is needed. However, deduplication is a two-step process: first, rules are followed to identify actual and potential matches; then a data steward determines whether potential matches are to be treated as actual matches or non-matches. If data for a dimension has been coordinated, then the rules will never identify any potential matches that require stewardship. This will substantially simplify the effort to perform initial and ongoing deduplication.
Note:
If you have used a Master Data Management (MDM) system to coordinate values in a dimension, you may want to use that MDM system in place of the OHMPI project supplied by Oracle for that dimension. For more information, refer Section 3.3, "Processes for Using Oracle Healthcare Master Person Index Deduplication Projects".All descriptions of deduplication in this document describe the process for one dimension. Your decisions about whether to use multi-source integration, OHMPI or another deduplication program, and what identification rules suit your data, will have to be made for each of the dimensions for which deduplication multi-source integration is supported. Table 3-1 lists the dimensions for which OHSCDA provides multi-source integration support.
Table 3-1 Warehouse Dimensions Supported by Multi-Source Integration
| Warehouse Table |
|---|
|
W_EMPLOYEE_D |
|
W_GEO_D |
|
W_HS_APPLICATION_USER_D |
|
W_LOV_D |
|
W_PARTY_D |
|
W_PARTY_ORG_D |
|
W_PARTY_PER_D |
|
W_PRODUCT_D |
|
W_RXI_CRF_BOOK_D |
|
W_RXI_CRF_D |
|
W_RXI_PROGRAM_D |
|
W_RXI_SITE_D |
|
W_RXI_STUDY_D |
|
W_RXI_STUDY_REGION_D |
|
W_RXI_STUDY_SITE_D |
|
W_RXI_STUDY_SUBJECT_D |
|
W_RXI_VALDTN_PROCEDURE_D |
|
W_USER_D |
OHSCDA's multi-source integration capability is layered on top of its Direct Path loading capability. The Direct Path loads all records from the source and does not have any knowledge of whether records are duplicates of one another.
The purpose of the Deduplication Path is to provide a way to communicate to the dimension's SIL that certain records loaded through the Direct Path are to be treated as duplicates. The SIL then applies that information to the records that it has loaded into the target warehouse table, reducing the designated duplicates to a single representative, and adjusting fact foreign keys accordingly.
The Deduplication Program allows you to use a combination of stored rules and human judgment to identify which records are duplicates and to determine what values should go into the warehouse record that consolidates those duplicates.
All dimensions have a Direct Path, but you can choose which of your dimensions are to be passed through the Deduplication Path.
OHSCDA has been designed to work with Oracle Healthcare Master Person Index (OHMPI) as its deduplication program. OHSCDA provides all the files required to integrate OHMPI into its Deduplication Path. You can, however, use another deduplication program to serve this role. An outline of the tasks necessary to enable this is in section 2.5.2.5. The remainder of this document, other than Section 2.5.2.5, describes how OHSCDA works with OHMPI as its deduplication program.
The Direct Path and the Deduplication Path intersect at the SIL for the dimension. This is the program that reads the data from the Staging table, does the necessary transformations on it, and writes the dimension data to its warehouse table.
In OHSCDA 2.2, the SIL for each dimension does an additional task, which is to incorporate data from the Deduplication Path for that dimension. The SIL always checks to see if there is anything new in the Persistent Staging table for the dimension. If the SIL finds anything new in the Persistent Staging table, it applies this deduplication information to the dimension's target table. If you are not using deduplication for the dimension, nothing will show up in the Persistent Staging table, and the Direct proceeds unchanged.
Deduplication applies to the initial load and to subsequent incremental loads.
In the Direct Path, there is little difference between the initial load and incremental loads. The differences are that indexes on warehouse tables are dropped, tables are truncated, and the starting date is set to the earliest date for which data is to be loaded, before an initial load. In incremental loads on the Direct Path, the ETL loads information only from records that have been created, changed, or deleted since the last ETL execution.
In the Deduplication Path, there is a marked difference between initial and incremental loads. For the initial load, you must initially create the Master Index for each dimension. To create a Master Index, perform the following steps:
Extract the dimension data from the various source databases into a flat file. OHSCDA provides a DAC Execution plan for doing this.
Profile the data for the dimension. This gives insight into patterns and groupings in the data. This may lead you to adjust the pre-defined rules for identifying matches.
Cleanse the dimension data by passing it through filters that identify records which, left unchanged, and would fail to be processed by the OHMPI deduplication program.
Run the Bulk Match by passing the data through the deduplication program, and get a report that indicates which records would be considered assumed matches. This again may lead you to adjust the pre-defined rules for identifying matches.
Run the Bulk Load. In this step, the rules are applied and the results are placed in the Master Index. This completes the initial load for the dimension.
Incremental load on the Deduplication Path is more automatic. If you've configured OHMPI and OHSCDA to run the Deduplication Path for a dimension, then OHSCDA will perform the following tasks whenever a job is executed for an incremental load.
OHSCDA will gather information about any new duplicates from the Master Index for the dimension.
OHSCDA runs the incremental load along the Direct Path.
OHSCDA adjusts the dimension target table so that the newly identified sets of duplicates already in the target table are merged into single records. If you have elected to unmerge records since the last execution of the SDE for the dimension, OHSCDA will adjust the dimension target table accordingly.
Note:
Merging records implies that a new Single Best Record is created, as indicated by your decisions in the OHMPI deduplication program, and the contributing records are marked as merged, meaning that they are invisible to queries from OBIEE.Incremental deduplication has an additional activity. If your match rules are set up so that the deduplication program can create potential matches, and such potential matches are identified, those potential matches have no immediate effect on the OHSCDA warehouse tables. Each of the records in a potential match is treated as if it were unique. A Data Steward must use the OHMPI Master Index Data Manager (MIDM) for the dimension to inspect each potential match, and decide how to deal with it. If the Steward has decided that it is indeed a match, then the erstwhile potential-match records become part of an assumed match. The next time the SIL for the dimension is executed, OHSCDA learns of the new assumed match, and makes the appropriate changes to the warehouse table.
The OHMPI Deduplication process consists of a Match Engine, which carries out Matching Rules to decide which input records are duplicates. Results of the decisions are stored in the Master Index. This section provides a conceptual introduction to the Match Engine, Master Index, and the Matching Rules.
The Match Engine is the part of OHMPI that applies the Match rules to evaluate whether incoming source records are duplicates of records already in the Master Index. For more information, refer to the Oracle Healthcare Master Person Index Data Manager's Guide.
The Master Index consists of all source records that have already been matched against one another. Each source record in the Master Index is a member of a Profile. Each Profile is a set of source records that have been determined to represent the same entity in the dimension. A Profile may consist of one or more source records. In addition to its source records, each Profile also has an additional record called its Single Best Record (SBR). The SBR is the representative for the Profile. Its attribute values are set to be the best available from across the contributing source records in the Profile.
The Match Engine receives each new source record from a queue. Each queued record is compared against the Master Index, as follows:
The Match Engine looks among the Profiles in the Master Index for the closest match. Matching is based on the values of the key fields that have been defined for the dimension. The Engine identifies which Profile (if any) in the Master Index is most similar to the new source record. This comparison is done by computing a weight for the similarity of the incoming record's key values to the corresponding values of the Profile's SBR, and then summing those weights. The greater the similarity, the higher the summed weights.
While the actual algorithm for doing it is more efficient, the Engine behaves as if it compares each record against every Profile in the Master Index. At the end of this, it will have identified one existing Profile that is most similar to the incoming record, unless the record under consideration is the initial one loaded into the Master Index.
Having identified the likeliest-match Profile, the Engine places the incoming record into one of three categories relative to this likeliest-match Profile, based on the summed similarity weight. The summed weight for the comparison is compared against two thresholds. These thresholds are Match Threshold and the Duplicate Threshold. The following three scenarios are possible:
If the summed weight is equal to or greater than the Match threshold, the incoming record is considered to represent the same entity as the likeliest-match Profile does. In this case the record is an assumed match, and is added to the Profile in the Master Index.
If the sum of the weights is equal to or greater than the Duplicate threshold, and less than the Match threshold, the Match Engine can only conclude that the incoming record may describe the same entity as the likeliest-match Profile does, but human judgment is needed to make a determination. In this case, the record is marked as a potential match to the Profile.
If the sum of the weights is less than the Duplicate threshold, the incoming record is deemed to not describe the same entity as the likeliest-match Profile. Therefore it is a non-match to that Profile (and a non-match to all other Profiles, since they had already been determined to be less similar to it that the likeliest-match Profile). Therefore, the incoming record represents a new entity, and it becomes the first source record in a new Profile.
The Match Engine makes its decisions based on several Configuration parameters. These are collectively called the Matching Rules for the dimension. There are two global configuration parameters in a Project:
Duplicate Threshold - a record must have a sum of weights greater than this to be considered a potential match to a Profile in the Master Index.
Match Threshold - a record must have a sum of weights greater than this value to be considered an assumed match to a Profile in the Master Index.
The Configuration also identifies which fields in the incoming records are the keys. For each key, the Configuration determines the MatchType to be used to compare the value of the incoming record to the corresponding value in the likeliest-match SBR. The MatchType in turn determines:
The algorithm used to compare the values
The range of weights to be given, depending on how different or similar the values are. This range is bounded by a Disagreement weight and an Agreement weight. The weight given to a particular comparison can fall between these endpoints, depending on the MatchType's algorithm
The weight to be given to the comparison in the event that one or both of the fields being compared is null or an empty string
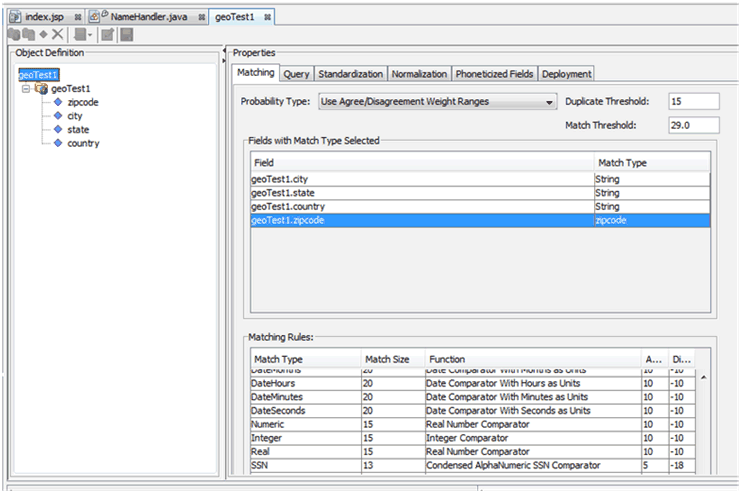
While OHMPI provides numerous pre-built MatchTypes, it is also possible to define new ones as needed for particular match fields. All the parameters in a project's Configuration can be adjusted through the Project Configuration Screen. Figure 3-2 shows the configuration screen for a project.
For more information, refer to the Oracle Healthcare Master Person Index Match Engine Reference.
Note:
Special handling is required if either of the records being matched has a null value for any of these fields.Normally, the keys used in matching not null columns in the source database are mandatory. Geography represents an exception to this rule. Because you draw GEO records from information about investigators and sites, the source systems do not require zipcode, city, state, and country for each investigator and site. This requires special handling for deduplication of the geography dimension.
If there is a match on zipcode and any other field in the preferred record is null, OHMPI processing results in a discrepancy between the integration ID of the record loaded on the direct path and the integration ID of the record loaded through the deduplication path. This is because OHMPI, while creating the SBR, automatically replaces null with the value of the key from the contributor record. This is contrary to our general rule that no attribute merge of integration ID keys is permitted. When the rule is broken, the integration key of the SBR is no longer identical to that of the preferred source record, and adjustment of foreign keys to point to the SBR fails.
You must prevent OHMPI from merging attribute of Geo key values.
Clean up the source data in the preferred source so that it contains as few null values as possible for the key Geography fields.
This forestalls any attribute merge of key values. It is not essential to clean up nulls in the non-preferred source.
Put into effect an SOP that requires that when a new address is added to a source table in the preferred source, the values of all four keys must be entered.
Override OHMPI's automatic swapping of values from the contributor source if null values still remain in the preferred source. To do so, Data Steward must be involved in MIDM.
You can use one approach for few records, and another approach for other records. The values of Zipcode, City, State, and Country in the SBR must be same as their values in the preferred record for the SBR, including null values, if any.
If you perform these actions, there will be no geography dimension SBRs with invalid integration IDs.
This section defines each of the components in the deduplication path for one dimension. Each dimension will have its own copy of these components.
This is used during Initial load only. It represents a set of activities that you must perform to prepare your existing data, and then call the deduplication program to load them into the Master Index. For more information, refer to Section 3.3.6, "Initial Load Processes" .
The extractor is used during Incremental loads only. This program determines which dimension record is new, has changed, or has been deleted since the last execution of the SDE. For each such record, it calls the API provided by the deduplication program, asking it to apply the match rules to this record, comparing it to all records already present in the Master Index for the dimension. The deduplication program makes the comparison, and takes one of the following actions:
If the record is determined to be a duplicate of a record in the Master Index (if it is an assumed match), the record is marked as a contributor to the SBR for that set of duplicates.
If the record is deemed to potentially match one or more records in the Master Index, it is marked as a potential match, awaiting a final decision by the Data Steward.
If the record is determined to not match any of the records in the Master Index, it is placed in the Master Index as a non-duplicate.
The Deduplication Program is the dimension-specific body of code (an OHMPI Project) that provides the capability to match an input record against the contents of the dimension's Master Index. It consults its match rules for the dimension, and estimates whether the record is an assumed match, a potential match, or a non-duplicate.
Matching Rules determine which records are assumed matches, which are potential duplicates, and which are non-duplicates. OHMPI provides an interface for specifying these rules.
This represents the activity of using the Master Index Data Management (MIDM) web application to review potential matches and decide their fate. Each dimension that is deduplicated has its own MIDM application.
The Master Index is a database schema that holds all of the records for the dimension that have been processed by the deduplication program. It has attributes by which each record is identified as being either part of match, a potential match, or a non-duplicate.
Note:
Every record in the Master index is a member of an Object Profile. Each Object Profile represents one dimension entity, and has a Single Best Record to represent the Profile. Some Profiles have one contributor record, others have multiple contributor records. For more information on of Object Profile concepts, refer to the Oracle Healthcare Master Person Index Data Manager's Guide.The Dimension MDM SDE is a query that reads from the Master Index table for the dimension, and writes to the Persistent Master Staging table for the dimension. This query selects only records describing assumed matches and potential matches confirmed by the Data Steward. Of these, the query selects only the records that have been created since the last execution of the SDE. As a result, it updates the Persistent Master Staging table with new deduplication information that must be acted upon by the SIL.
The Persistent Master Staging Table accumulates all merge decisions defined by the deduplication program for the dimension. This information is used by the dimension's SIL to apply that merge information to the data in the dimension warehouse table, thus reducing each set of duplicates to a representative Single Best Record.
This section describes how to carry out the processes required using the deduplication path and the starting point from which you begin those processes. That starting point is the state of the OHSCDA system after the Installation (or Upgrade) process has completed.
The process of installing or upgrading OHSCDA 2.2 provides all the pre-built objects required for performing deduplication with OHMPI.
Note:
Some of these items are installed by you, as pre-requisites to the OHSCDA installation. Others are installed as part of the OHSCDA installation itself.Some of the items are packaged per-dimension. These are:
Two common Execution Plans one for full load and other for Incremental load. This includes extraction logic for all dimensions.
OHMPI Project files structure for the dimension. This includes the match rules, configurations, and the files needed to install the MIDM application in WebLogic. Each dimension's file structure is a folder under a root NetBeansProjects folder.
Persistent Staging table for the dimension
SIL that reads both Direct and Deduplication Paths
A database schema to hold the Master Index for the dimension
There is one item that is not dimension-specific. This is the DAC execution plan to do extractions for the Extractor component of the Deduplication path.
This set of components represents the starting point for carrying out the processes described below.
In order to carry out these processes, it is helpful to have an understanding of where OHMPI files will be found.
The files pertaining to a dimension are maintained in a Project. Each Project is rooted in a folder with a name corresponding to the dimension it loads. These are called project folders. All project folders are contained within a folder named NetBeansProjects.
A project has a fairly deep and complex folder structure. However, for normal purposes, you need to open files in only a few of these folders. These are:
| Folder | Description |
|---|---|
|
cleanser |
Work in this directory to do cleansing of the extracted, profiled data prior to bulk load |
|
loader |
Work in this directory to do bulk matching and loading of the cleansed data. Also known as the Master IBML Tool home directory. |
|
mdm |
This directory is also used by the Bulk Loader. It is referred to in the OHMPI documentation as the working directory. This directory is not automatically created when you create a Project. You must create it, and place it in the location specified in the loader-config.xml file. |
|
profiler |
Work in this directory to do profiling of the extracted data prior to cleansing. |
|
src\Configuration |
This directory contains the configuration files for the Project. These files can be edited or viewed here, but it is preferable to view and modify them under the Configuration folder in the NetBeans IDE representation of the Project. |
This section provides descriptions of processes that must (or in the case of optional processes, may) be carried out when performing deduplication using OHMPI. This section describes processes in terms of what you do for one dimension. You will need to repeat these processes for each dimension that you elect to deduplicate using OHMPI. If you use a different deduplication system, the names of the processes will vary, but the tasks will essentially remain the same.
There are three classes of processes: project configuration, initial load, and incremental loads.
For each source database, add a processing code for the database. See Oracle Healthcare Master Person Index User's Guide.
Project configuration sets the values of the parameters that determine how the project processes the data for the dimension. For more information, refer to Section 3.1.8.2, "Matching Rules Using Project Configuration" .
Oracle provides pre-defined configuration settings for each dimension project we ship.
Note:
These pre-defined configurations are intended to be a starting point only. They represent a set of assumptions about how you might want the dimensions processed. However, they are generic, and not tuned to your specific data. It is essential that you review and adjust these configuration settings so that they are appropriate to your data.You should adjust the configuration so that they provide the right balance of assumed, potential, and non-duplicates, given what you know about your data. You should adjust the configuration so that assumed matches occur only for real duplicates, and avoid false assumed matches. To do this, adjust weights and the match threshold such that only records you know to be identical will have weights equal to or greater than the match threshold.
You should also adjust the configuration to avoid creating non-matches where the records are really duplicates. Do this by adjusting weights and the duplicate threshold such that only records you know to be unique will fall below the duplicate threshold.
Oracle urges you to carefully read the OHMPI documentation on this topic, and to work carefully on adjusting each dimension's configuration so as to avoid mis-identifications.
O CDA's deduplication capability has been designed so that you can make some adjustments after the fact: you can merge two profiles into one, and CDA will make the corresponding adjustment in the next execution of the dimension's SIL.
While OHSCDA lets you make these adjustments, the effort needed to accomplish them in the MIDM is complex. The only adjustment that is simple in the MIDM is that of resolving a potential match, either to a merge or to two separate profiles. Therefore, Oracle strongly recommends that you configure your projects such that, when there's any doubt about the right disposition, it creates potential matches.
In pre-defining configurations for projects, we have tried to define rules in this manner, but you must review and refine them in light of your knowledge of your data.
One configuration change that you may want to perform is to take an attribute that is part of the SBR for a record, and add it to the set of Match Fields for the dimension's Project.
For example, the shipped Project for the Study dimension has only one match field, STDY_NM. If your study naming conventions let you use the same study name in different Programs, you would want to add Program as a match field in the Study Project.
Since Program is an attribute of the Study dimension, it is already included in the SDE that extracts the Study dimension data. It can serve as a match field. Perform the following to define it as a match field:
Create a new Match Type for Program if none of the pre-defined strings have the correct size, comparator, and agreement and disagreement weights.
In the field's properties, change its Match Type from None to the desired Match Type.
Include the Program Name as part of block query in query.xml.
Adjust the duplicate and match threshold values to take the new match field's weight into consideration. The simplest change is to increase both thresholds by the agreement weight of the new match field. You should also consider what impact of agreement or disagreement on this field you want to have on the match outcome.
Clean and build the Project.
Save a copy of the current Cleanser directory and regenerate the Cleanser.
Add Program to the cleansing rules.
Regenerate the Loader.
Empty the Master Index tables, if they have been populated.
Run Bulk Match in Analysis mode to confirm that Program now differentiates.
Deploy the Project on your Application Server.
Refer to Master Person Index Database in the Oracle Healthcare Master Person Index User's Guide. Follow the instructions in this guide to create and seed the database schema that will hold the Master Index for the dimension.
The MIDM is the web application that allows the Data Steward to evaluate potential matches, and inspect the properties of all Profiles in the Master Index. Refer to Oracle Healthcare Master Person Index WebLogic User's Guide and Oracle Healthcare Master Person Index User's Guide, Generating the Master Person Index Application to generate and deploy the application to the WebLogic Application Server.
This process extracts data from the source databases for use in initial load. The output of this process is a flat file that conforms to the OHMPI specification. This file is used as input during the Profile, Cleanse, Bulk Match and Load Processes.
For more information on the format of the file, refer to Oracle Healthcare Master Person Index User's Guide.
Use the DAC execution plan, CDA - Complete Initial De Dup, for extracting the flat files for cleansing.
This process is optional. Consult the reference noted below to determine if profiling is useful for your data. Profiling gives insight into patterns and groupings in the data. It takes an OHMPI-conformant flat file as input, and yields reports on patterns and groupings. For more information, see Oracle Healthcare Master Person Index User's Guide.
The basic steps of this process are:
Generate and unzip the profiler directory for the project.
Note:
You must grant recursive write privileges on the profiler directory to the current user.Make a copy of sampleConfig.xml.
Adjust your config.xml to specify the desired reports.
Extract data from the source databases into an OHMPI-conformant flat file. Use the flat file generated as part of DAC execution plan.
Edit run.bat to execute your sampleConfig.xml.
Run run.bat.
Review reports. Determine what changes in matching rules, or addition to matching rules, are necessary given the profile of the data for the dimension.
Modify the source data based on conclusions drawn from reports.
Repeat steps 5-8 until data is satisfactory.
The output of the Profile process is an OHMPI-conformant flat file that satisfies all profiling requirements.
This process is optional, but strongly recommended. Cleansing identifies those records in the OHMPI-conformant flat file that will fail to pass successfully through the bulk loader. The cleansing process takes an OHMPI-conformant flat file as input, and yields two output files. By default they are named good.txt and bad.txt. Records in good.txt will be acceptable to the bulk loader engine; Records in bad.txt will fail to be processed by the bulk loader. The goal of the cleansing process is to iteratively clean the source data until cleansing the extracted flat file produces no rejected records. For more information, refer to Rule three in Section 3.5.1, "Rules" .
The basic steps of this process are:
Generate and unzip the cleanser directory for the project. You can create this directory from NetBeans IDE.
Note:
You must grant recursive write privileges on the cleanser directory to the current user.Make a copy of sampleConfig.xml.
Adjust your config.xml to specify the desired reports.
Extract data from the source databases into an OHMPI-conformant flat file.
All hash (#) character occurrences which are not prefixed by tilde (~) should be prefixed by tilde (~) in the flat file.
All new line characters within a given record should be removed from the flat file.
Edit run.bat to execute your sampleConfig.xml.
Run run.bat.
Review the bad.txt file. For each record that it contains, determine why it was rejected by the match engine. Then either:
clean the source data to fix the error (for example, correct typos such as alphabetic characters in fields declared to be numeric)
modify the configuration rules in the Project so that the record will pass (for example, modify data type)
Note:
The OHMPI guide suggests that you can use the Cleansing process to modify data that otherwise would be rejected. For use with OHSCDA, Oracle recommends that you do not use the cleansing process to modify dimension data. Instead, you should modify the data in the source database. Refer to Rule one in Section 3.5.1, "Rules" .Modify the source data based on conclusions drawn from reports.
Repeat steps 5-8 until data is satisfactory.
The output of the Cleanse process is an OHMPI-conformant flat file that will produce no rejects if passed through the cleanser again.
For more information, refer to Oracle Healthcare Master Person Index User's Guide and Oracle Healthcare Master Person Index Analyzing and Cleansing Data User's Guide.
This process is optional, but highly recommended. The reason is that its output also includes a report on which input records get treated as assumed matches under the current set of match rules. By running the Bulk Match process standalone, you can use the report to tune the match rules until you get the set of assumed matches you deem correct for your input data.
Generate the project's loader.zip file. Expand the zip file.
Note:
You must grant recursive write privileges on the loader directory to the current user.Edit...\loader\conf\.
Set the /loader/system/properties/property/@matchAnalyzerMode property to true, instructing the loader to perform analysis, rather than generating a load file.
Iterate on this cycle:
Run Bulk Match.
Review the Bulk Match report. Compare the outcome to your expectations.
Note:
The Bulk Match report provides the sum of the weights for each pairing of input records. It is reported as the weight for the Systemcode and LocalID attributes of the records.If the outcomes are not what you want:
Adjust the match rules. For more information, refer to Section 3.1.8.2, "Matching Rules Using Project Configuration" .
Clean and build the Project.
Run cluster-truncate.sql in the project database schema.
Execute steps 3-5 again.
For more information, refer to Oracle Healthcare Master Person Index User's Guide and Oracle Healthcare Master Person Index Loading the Initial Data Set User's Guide.
When the matching rules are giving the results you want, that is, all records are correctly directed to the appropriate category, use Bulk Match to generate a set of load files. You can choose to have it carry out the load into the dimension's master index tables as part of the generation, or do it as a separate step. Use the BulkLoad property in Edit ...\loader\conf\loader-config.xml to determine this behavior. For more information, refer to the Oracle Healthcare Master Person Index Loading the Initial Data Set User's Guide.
OHMPI project provides generates a web application for inspecting the results of testing incoming source records against the Master Index according to the dimension's matching rules. This is the Master Index Data Manager (MIDM). In MIDM, a Data Steward can review potential matches, and determine whether the records should be treated as duplicates or not. If they are to be treated as duplicates, the Steward can also override the rule-based decisions about which data source provides the value for each attribute in the result record.
At any time, the Master Index for the dimension contains a cumulative set of records that result from the evaluation of source records. Use the MIDM for the following purposes:
Decide on the fate of potential matches
Merge attributes into single best record
Unmerge records from profiles
Merge currently separate profiles
For most fact tables, the consequence of deduplication is limited to adjustment of foreign keys. Adjustment occurs when a dimension record to which the fact had a foreign key is identified as a contributor to an SBR in the dimension. The SBR gets a new ROW_WID in the dimension table; the foreign key in the fact is correspondingly updated so that it points to the SBR, rather than to the contributor record.
There are certain situations in which Dimension Deduplication has additional effects on Fact tables in the warehouse. These are discussed in the following subsections.
One of the dimensions that can be deduplicated starting in OHSCDA 2.2 is the LOV dimension. This dimension holds sets of values for different codelists. Values from a particular codelist share a common value on R_TYPE. With deduplication, two values in an R_TYPE may be identified as referring to the same value. The consequence would be that an SBR is created, using the codelist value from the preferred source.
For instance the source for the Subject_Status codelist might include both Enroll and Enrolled. Both of these records would be loaded into the LOV dimension in the warehouse. During deduplication, however, the records will have been identified as a potential match, and the Data Steward will have selected a value for the VAL column in the SBR.
Now, if the subject status fact table happens to contain two records about Subject 101, one which pointed to an LOV value of Enroll, and another record which pointed to an LOV value of Enrolled, these records are now discovered to be duplicates of one another. This is because, after foreign key adjustment, they both will be found pointing to the same record in the LOV table. The Subject Status table is constrained to hold only one instance of a particular status for a subject; therefore one of the two fact records will have to be treated as the winner, and the other suppressed.
In the case outlined here, both come from the same database, so it is not possible to choose based on which contributor dimension record came from the preferred source for the dimension. Instead, for LOV, OHSCDA uses the original status code of the preferred LOV source record, i.e. the LOV record that was selected as the winner during deduplication. So, if the LOV record with the value Enrolled was chosen as the preferred source during deduplication of the LOV dimension, then the Subject Status fact record that originally pointed to that dimension record will be the winner.
While this seems obscure, it has a very practical consequence. Each of the subject status fact records has a date on which the subject achieved the status. Since only one of them survives, the date it carries is the date that is displayed for the subject achieving the status.
Driving Dimensions
This section applies to the following:
Study-site Enrollment Plan (Table W_RXI_SITE_ENRLMNT_PLN_F)
Region Enrollment Plan (Table W_RXI_RGN_ENRLMNT_PLN_F)
Study Enrollment Plan (Table W_RXI_STDY_ENRLMNT_PLN_F)
Subject Participation (Table W_RXI_SUBJECT_PRTCPTN_F)
Subject Status (Table W_RXI_SUBJECT_STATUS_F)
Study (Table W_RXI_STUDY_F)
Study Region (Table W_RXI_STUDY_REGION_F)
Study-site (Table W_RXI_STUDY_SITE_F)
Study Region (Table W_RXI_STUDY_REGION_TGT)
Program (Table W_RXI_PROGRAM_TGT)
Study-site (Table W_RXI_STUDY_SITE_TGT)
Study (Table W_RXI_STUDY_TGT)
Region (Table W_RXI_REGION_TGT)
Therapeutic Area (Table W_RXI_THERAPEUTIC_AREA_TGT)
For each of these tables, deduplication of the dimension that is at the grain of the fact table (the driving dimension for the fact) can cause multiple records in the fact table to point to the same dimension record, which will violate uniqueness requirements. To resolve this, OHSCDA merges fact records where necessary, to maintain the correct grain in the fact. The retained fact record is the one that comes from the same source as the SBR in the driving table.
To understand this better, consider the following example. Table 3-3 displays the results of deduplication of the Study-Site dimension. Data sources 1 and 2 have a Study-Site identified as SS-1. During deduplication, it has been established that they are duplicates since they refer to the same actual Study-Site. A Single Best Record, with ROW_WID = 103, has been defined for the set of duplicates. The preferred source for the SBR has been set as Datasource 1.
Table 3-3 Study-Site Dimension Table After Deduplication
| ROW_WID | Study Site Identification # | Integration_ID | Datasource_num_ID | Winner_Row_Wid | Merge_Flag | SBR_Flag |
|---|---|---|---|---|---|---|
|
101 |
SS-1 |
SS-1 |
1 |
103 |
Y |
N |
|
102 |
SS-2 |
SS-2 |
2 |
103 |
Y |
N |
|
103 |
SS-1 |
SS-1 |
1 |
(blank) |
N |
Y |
Let us consider a fact that has Study-Site as its grain (and therefore has the Study-Site dimension as its driving dimension). Table 3-4, "Study-Site Enrollment Plan Fact After Key Adjustment and Dimension-driven Deduplication" displays records in the Study-Site Enrollment Plan Fact table.
As shown in the Orig_Study_wid column, these two fact records, originally pointed to Study-Site dimension records 101 and 102. But Study-Site dimension records 102 and 103 have been merged into the SBR, record 103. Neither the Enrollment Plan fact records cannot point to Study-site rows 102 and 103 nor can both of them point to the SBR Study-Site record 103. If they both did, there would be two records in the Study-Site Enrollment Plan Fact, both claiming to represent Study-Site SS-1.
Since the grain of the Study-Site Enrollment Plan Fact is one record per Study-Site, there can only be one fact record for each Study-Site. One of the fact records has to be suppressed (its Merge_Flag is set to Y), and the other gets its Merge_Flag set to N, marking it as the only record describing the enrollment plan for Study-Site SS-1.
Table 3-4 Study-Site Enrollment Plan Fact After Key Adjustment and Dimension-driven Deduplication
| ROW_WID | Study_wid | Orig_Study_wid | Study_site_wid | Orig_Study_Site_wid | Planned_Subject_Enrolled_Cnt | Datasource_num_ID | Merge_Flag |
|---|---|---|---|---|---|---|---|
|
1001 |
1 |
1 |
103 |
101 |
100 |
1 |
N |
|
1002 |
1 |
1 |
103 |
102 |
120 |
2 |
Y |
OHSCDA uses this method to establish which record is suppressed and which is retained. The setting of the value of Merge_Flag in these fact tables depends on the integration of SBR record in Driving dimension table. The fact table record, related to integration_id selected in SBR record of Driving dimension, will be treated as the survivor record. It will be marked as Merge Flag = N and the other records will be marked as Merge Flag = Y. The fact table record coming from the same data-source as the data-source of the SBR of the Driving dimension will be treated as survivor record (Merge Flag = N), while the other record coming from the non-SBR data-source gets marked as Merge Flag = Y. In the example, the data-source for the Study-Site SBR (record 103 in the Study-Site dimension table) is source 1. For two records in the fact table pointing to Study-Site row 103, the one that gets Merge_Flag set to N is the one that shares the same data-source as the Study-Site SBR, and that is fact row 1001.
This section lists the rules that you must follow when deduplicating data, and adds some recommendations on best practices.
When merging attributes into an SBR, do not blend values of the dimension's integration ID from multiple sources.
Do not use the Cleansing process to modify the data. Make any needed changes in the original data source. Doing otherwise will lead to inconsistencies between data loaded via the Direct and Deduplication paths. Also, since cleansing is typically done only during initial load, changes that you make via cleansing will be lost if a cleansed record is subsequently reloaded.
When cleansing data, keep modifying source data (or altering matching configuration) until there are no rejected records. Any record that is rejected during cleansing is a record that will not be included in the Master Index, and therefore will not take part in deduplication.
When merging attributes into an SBR, do not blend the unique key attributes.
In Geography dimension, match cannot be left null.
If there is more than one database for either application, it is the user's responsibility to choose which of them is to be the preferred source for that application.
Oracle strongly recommends that you carefully review and revise the configuration of each project. Oracle has supplied pre-defined configurations, but these are intended only as starting points for your tuning. They definitely should not be used blindly. See 4.1 above for details on this recommendation.
OHMPI has a configuration parameter, SameSystemMatch that determines whether two profiles from the same source database are allowed to be programmatically merged into one profile. A setting of true prevents merging records from the same source database, regardless of whether the summed weights are greater than the Match threshold. A setting of false allows merger of records from the same source if the summed weights are greater than the Match threshold. In the Projects shipped by Oracle, this parameter is set to false. You should consider whether this setting is correct for your data. Refer to the Oracle Healthcare Master Person Index Configuration Guide.
OHMPI has a configuration parameter, OneExactMatch that determines the number of source records that can be incorporated into a Profile. If OneExactMatch is set to true and there is more than one record above the match threshold, then none of the records are considered an assumed match and all are flagged as potential duplicates. If OneExactMatch is set to false and there is more than one record above the match threshold, then all matching records are considered an assumed match. In the Projects shipped by Oracle, this parameter is set to false. You should consider whether this setting is correct for your data. Refer to the Oracle Healthcare Master Person Index Configuration Guide.
If new data is going to be loaded into a dimension, and you have any reason to be concerned that the current rules for the dimension will not properly categorize the new records, extract the new records into a flat file, and use the cleanser and Bulk Match Analyzer to see how they will be handled by the match engine. If necessary, adjust the matching rules so they categorize the records properly. Then load the records into the source database, and allow them to be processed by the next incremental load.
This section provides information about the matching rules that are shipped with each OHSCDA dimension's Project. These matching rules are intended as a starting point only. it is imperative that you at least review these rules to determine whether they meet your needs. It is very likely that they will not suffice without modification.
This section describes how OHSCDA will define the rules it ships for identifying duplicates in its dimensions. For each dimension it gives:
The general policies are as follows. However, they may be overridden for particular dimensions.
To be above the match threshold, the match fields being compared must be strictly identical.
OHSCDA's default match rules attempt to identify records as non-duplicates only if it is clear that there is no possibility that they could be part of a potential match. When in doubt, the default rules lean toward marking records as potential matches. It is easy for the steward to push data from the potential category into either assumed match or non-match. It is possible, but more work, to take non-matches and turn them into matches.
In creating an assumed or potential match SBR, use the values from the preferred source. See Table 3-5, "Preferred Source for Each Deduplicated Dimension" for the preferred sources defined in the Projects shipped by OHSCDA.
If two or more records match, OHSCDA's default match rules set the values of the attributes of the Single Best Record (SBR) to be the attributes of the preferred source. For preferred source, refer Table 3-5, "Preferred Source for Each Deduplicated Dimension"
If the preferred record has an attribute corresponding to an attribute required by the SBR, but its value is null, leave it null in the SBR. That is, if the preferred record contains an attribute that is needed for the BR, always take the value supplied by the preferred record, even if that value is NULL.
If the preferred record does not have an attribute corresponding to a given target record attribute, but that attribute is available in a donor record, use the attribute value from the highest ranking donor record. For example, if Oracle Clinical is the preferred source for Study, since OC lacks an attribute for EUDRA_NUMBER, take the value of EUDRA_NUMBER from SC.
Table 3-5 Preferred Source for Each Deduplicated Dimension
| Warehouse Table | Preferred Source |
|---|---|
|
W_EMPLOYEE_D |
Siebel Clinical |
|
W_GEO_D |
Siebel Clinical |
|
W_HS_APPLICATION_USER_D |
Siebel Clinical |
|
W_LOV_D |
Siebel Clinical |
|
W_PARTY_D |
Siebel Clinical |
|
W_PARTY_ORG_D |
Siebel Clinical |
|
W_PARTY_PER_D |
Siebel Clinical |
|
W_PRODUCT_D |
Siebel Clinical |
|
W_RXI_CRF_BOOK_D |
Oracle Clinical |
|
W_RXI_CRF_D |
Oracle Clinical |
|
W_RXI_PROGRAM_D |
Siebel Clinical |
|
W_RXI_SITE_D |
Siebel Clinical |
|
W_RXI_STUDY_D |
Siebel Clinical |
|
W_RXI_STUDY_REGION_D |
Siebel Clinical |
|
W_RXI_STUDY_SITE_D |
Siebel Clinical |
|
W_RXI_STUDY_SUBJECT_D |
Oracle Clinical |
|
W_RXI_VALDTN_PROCEDURE_D |
Oracle Clinical |
|
W_USER_D |
Siebel Clinical |
Table describes the configuration of the OHMPI Projects shipped with OHSCDA. For each Project, it lists:
Dimension Name - the name of the dimension in the warehouse
Project Name - the name given to the OHMPI Project for that dimension
Duplicate Threshold - the minimum summed weight that will cause a record to be considered a potential match
Match Threshold - the minimum summed weight that will cause a record to be considered an assumed match
Attributes of the key fields for the dimension:
Match Attribute - the name of the attribute
Match Type - the MatchType used for determining the similarity of the field between the records being compared. Note that all fields sharing a MatchType in a Project use the same Disagree and Agree weights
Customized/Built-in - Where an existing MatchType would not serve, OHSCDA created a new MatchType. Typically this was done to use the same comparator function, but different weights than another field
Comparator Function - an algorithm for determining similarity of fields
Disagree Weight - the field's contribution to the summed weight if the values being compared differ completely (per the Comparator function)
Agree Weight - the field's contribution to the summed weight if the values being compared agree completely (per the Comparator function)
Null Field - the impact of the field on the summed weight if one or both records being compared have a null or empty string for the field
Table 3-6 Project Weights and Thresholds
| Dimension Name | Project Name | Duplicate Threshold | Match Threshold | Match Attribute | Match Type | ICustomized or Built-in | Comparator Function | Disagree Weight | Agree Weight | Null Field |
|---|---|---|---|---|---|---|---|---|---|---|
|
Validation Procedure |
OCDA_Valdtn |
25 |
30 |
STUDY_NAME |
StudyName |
Customized |
Condensed String Comparator |
0 |
10 |
Zero Weight |
|
Validation Procedure |
OCDA_Valdtn |
25 |
30 |
VALDTN_PROC_NAME |
String |
Built-in |
Condensed String Comparator |
0 |
20 |
Zero Weight |
|
User |
OCDA_User |
10 |
10 |
LOGIN |
String |
Built-in |
Condensed String Comparator |
-10 |
10 |
Zero Weight |
|
Study Site |
OCDA_Study_Site |
20 |
40 |
SITE_NAME |
String |
Built-in |
Condensed String Comparator |
0 |
10 |
Zero Weight |
|
Study Site |
OCDA_Study_Site |
20 |
40 |
STUDY_NAME |
String |
Built-in |
Condensed String Comparator |
0 |
10 |
Zero Weight |
|
Study Site |
OCDA_Study_Site |
20 |
40 |
STUDY_SITE_IDENTIFICATION |
String |
Customized |
Condensed String Comparator |
0 |
20 |
Zero Weight |
|
Study Subject |
OCDA_Study_Subject |
20 |
20 |
SUB_IDENTIFICATION |
String |
Built-in |
Condensed String Comparator |
-10 |
10 |
Zero Weight |
|
Study Subject |
OCDA_Study_Subject |
20 |
20 |
STUDY_NAME |
String |
Built-in |
Condensed String Comparator |
-10 |
10 |
Zero Weight |
|
Product |
OCDA_Product |
10 |
10 |
PROD_NAME |
String |
Built-in |
Condensed String Comparator |
-10 |
10 |
Zero Weight |
|
Site |
OCDA_Site |
80 |
160 |
SITE_NAME |
String |
Built-in |
Condensed String Comparator |
0 |
80 |
Full Agreement Weight |
|
Site |
OCDA_Site |
80 |
160 |
ADDRESS_StName |
StreetName |
Built-in |
Condensed String Comparator |
0 |
10 |
Full Agreement Weight |
|
Site |
OCDA_Site |
80 |
160 |
ADDRESS_HouseNo |
HouseNumber |
Built-in |
Advanced Jaro Adjusted for HouseNumbers |
0 |
10 |
Full Agreement Weight |
|
Site |
OCDA_Site |
80 |
160 |
ADDRESS_StDir |
StreetDir |
Built-in |
Advanced Jaro String Comparator |
0 |
10 |
Full Agreement Weight |
|
Site |
OCDA_Site |
80 |
160 |
ADDRESS_StType |
StreetType |
Built-in |
Advanced Jaro String Comparator |
0 |
10 |
Full Agreement Weight |
|
Site |
OCDA_Site |
80 |
160 |
SITE_COUNTRY |
CountryStateCityZip |
Customized |
Condensed String Comparator |
0 |
10 |
Full Agreement Weight |
|
Site |
OCDA_Site |
80 |
160 |
SITE_STATE |
CountryStateCityZip |
Customized |
Condensed String Comparator |
0 |
10 |
Full Agreement Weight |
|
Site |
OCDA_Site |
80 |
160 |
SITE_CITY |
CountryStateCityZip |
Customized |
Condensed String Comparator |
0 |
10 |
Full Agreement Weight |
|
Site |
OCDA_Site |
80 |
160 |
SITE_ZIPCODE |
CountryStateCityZip |
Customized |
Condensed String Comparator |
0 |
10 |
Full Agreement Weight |
|
Program |
OCDA_Program |
13 |
13 |
PROGRAM_NAME_Name |
PrimaryName |
Built-in |
Condensed String Comparator |
-2 |
13 |
Zero Weight |
|
Program |
OCDA_Program |
13 |
13 |
PROGRAM_NAME_OrgType |
OrgTypeKeyword |
Built-in |
Condensed String Comparator |
-6 |
8 |
Zero Weight |
|
Program |
OCDA_Program |
13 |
13 |
PROGRAM_NAME_AssocType |
AssocTypeKeyword |
Built-in |
Condensed String Comparator |
-3 |
5 |
Zero Weight |
|
Program |
OCDA_Program |
13 |
13 |
PROGRAM_NAME_Sector |
IndustrySectorList |
Built-in |
Condensed String Comparator |
-4 |
5 |
Zero Weight |
|
Program |
OCDA_Program |
13 |
13 |
PROGRAM_NAME_Industry |
IndustryTypeKeyword |
Built-in |
Condensed String Comparator |
-4 |
7 |
Zero Weight |
|
Program |
OCDA_Program |
13 |
13 |
PROGRAM_NAME_Url |
Url |
Built-in |
Condensed String Comparator |
-4 |
8 |
Zero Weight |
|
Lov |
OCDA_Lov |
18 |
20 |
R_TYPE |
String |
Built-in |
Condensed String Comparator |
-10 |
10 |
Zero Weight |
|
Lov |
OCDA_Lov |
19 |
20 |
VAL |
String |
Built-in |
Condensed String Comparator |
-10 |
10 |
Zero Weight |
|
Geography |
OCDA_Geography |
25 |
85 |
CITY |
OCDACityString |
Customized |
Condensed String Comparator |
0 |
25 |
Zero Weight |
|
Geography |
OCDA_Geography |
25 |
85 |
COUNTRY |
OCDACountryString |
Customized |
Condensed String Comparator |
-6 |
10 |
Zero Weight |
|
Geography |
OCDA_Geography |
25 |
85 |
STATE_PROV |
OCDAStateString |
Customized |
Condensed String Comparator |
0 |
20 |
Zero Weight |
|
Geography |
OCDA_Geography |
25 |
85 |
ZIPCODE |
OCDAZipString |
Customized |
Condensed String Comparator |
-30 |
30 |
Zero Weight |
|
Study |
OCDA_Study |
7 |
10 |
STDY_NM |
String |
Built-in |
Condensed String Comparator |
-10 |
10 |
Zero Weight |
|
Application User |
OCDA_APP_USER |
8 |
10 |
APP_USR_NM |
String |
Built-in |
Condensed String Comparator |
-10 |
10 |
Zero Weight |
|
CRF |
OCDA_CRF |
20 |
20 |
CRF_NAME |
String |
Built-in |
Condensed String Comparator |
-10 |
10 |
Zero Weight |
|
CRF |
OCDA_CRF |
20 |
20 |
STUDY_NAME |
String |
Built-in |
Condensed String Comparator |
-10 |
10 |
Zero Weight |
|
CRF_BOOK |
OCDA_CRF_BOOK |
20 |
20 |
CRF_BOOK_NAME |
String |
Built-in |
Condensed String Comparator |
-10 |
10 |
Zero Weight |
|
CRF_BOOK |
OCDA_CRF_BOOK |
20 |
20 |
STUDY_NAME |
String |
Built-in |
Condensed String Comparator |
-10 |
10 |
Zero Weight |
|
Party_Per |
OCDA_Investigator |
160 |
235 |
Last_Name_Std |
LastName |
Built-in |
Advanced Jaro Adjusted for Last Names |
0 |
80 |
Full Combination Weight |
|
Party_Per |
OCDA_Investigator |
160 |
235 |
FULL_ADDRESS_StName |
StreetName |
Built-in |
Condensed String Comparator |
0 |
5 |
Full Combination Weight |
|
Party_Per |
OCDA_Investigator |
160 |
235 |
FULL_ADDRESS_HouseNo |
HouseNumber |
Built-in |
Advanced Jaro Adjusted for HouseNumbers |
0 |
5 |
Full Combination Weight |
|
Party_Per |
OCDA_Investigator |
160 |
235 |
FULL_ADDRESS_StDir |
StreetDir |
Built-in |
Advanced Jaro String Comparator |
0 |
5 |
Full Combination Weight |
|
Party_Per |
OCDA_Investigator |
160 |
235 |
FULL_ADDRESS_StType |
StreetType |
Built-in |
Advanced Jaro String Comparator |
0 |
5 |
Full Combination Weight |
|
Party_Per |
OCDA_Investigator |
160 |
235 |
ORIG_FST_NAME |
OrigNameWegt |
Customized |
Condensed String Comparator |
0 |
5 |
Full Combination Weight |
|
Party_Per |
OCDA_Investigator |
160 |
235 |
ORIG_LAST_NAME |
OrigLastName |
Customized |
Condensed String Comparator |
0 |
5 |
Full Combination Weight |
|
Party_Per |
OCDA_Investigator |
160 |
235 |
ORIG_MIDDLE_NAME |
OrigNameWegt |
Customized |
Condensed String Comparator |
0 |
5 |
Full Combination Weight |
|
Party_Per |
OCDA_Investigator |
160 |
235 |
FST_NAME_Std |
FirstName |
Built-in |
Advanced Jaro Adjusted for First Names |
0 |
80 |
Full Combination Weight |
|
Party_Per |
OCDA_Investigator |
160 |
235 |
MID_NAME |
MiddleNMString |
Customized |
Condensed String Comparator |
0 |
20 |
Full Combination Weight |
|
Party_Per |
OCDA_Investigator |
160 |
235 |
STATE |
String |
Built-in |
Condensed String Comparator |
0 |
5 |
Full Combination Weight |
|
Party_Per |
OCDA_Investigator |
160 |
235 |
ZIP |
String |
Built-in |
Condensed String Comparator |
0 |
5 |
Full Combination Weight |
|
Party_Per |
OCDA_Investigator |
160 |
235 |
COUNTRY |
String |
Built-in |
Condensed String Comparator |
0 |
5 |
Full Combination Weight |
|
Party_Per |
OCDA_Investigator |
160 |
235 |
CITY |
String |
Built-in |
Condensed String Comparator |
0 |
5 |
Full Combination Weight |
If you want to use a deduplication program other than OHMPI, the program must plug into the OHSCDA deduplication path at two points: it must read from the source databases for the dimension, and it must write to the Persistent Staging tables. Therefore, to implement a non-OHMPI deduplication program, you must supply the following:
a set of match rules
an Extractor
a program for processing extracted records according to the match rules
a warehouse schema for the dimension's Master Index
the SIL to read the dimension's Master Index, and write to the relevant Persistent Staging tables. Each dimension has a dimension-specific Persistent Staging table, with a prefix W_MDM_. For each set of duplicates identified, this table must receive copies of the Single Best Record for the set, and all the members of the set. Additionally, the SIL must write to a common table, W_HS_MDM_MAPPING_S that maps each Single Best Record to its contributors.
The process for carrying this out cannot be detailed here, since it depends on the nature of the non-OHMPI deduplication program and it's Master Index.
Suppose that you have a column M in a transactional source (S1) for OHSCDA. Column M is not part of the OHSCDA warehouse and is an attribute of a dimension (D1) that is deduplicated. If you want column M to be available in the OHSCDA presentation layer, then following is the overall list of the tasks that have to be accomplished:
Table 3-7 Extension Tasks by Load Path
| Task | Path |
|---|---|
|
Add M to the Sites Staging table |
Direct |
|
Add M to the Sites warehouse table |
Direct |
|
Add M to the Persistent staging table |
Deduplication |
|
Add M to the SIL that reads from the Master Index for dimension D1, and writes to the Persistent Staging Tables |
Deduplication |
|
Add M to the OHMPI Project definition |
Deduplication |
|
Add M to S1 Sites SDE |
Direct |
|
Add M to Sites SIL |
Direct |
|
Add M to OBIEE Physical, Business and Presentation Layer |
Direct |
The modifications required for the Direct path are discussed in the following sections.
Table 3-8 shows the Informatica mappings that have a role in the deduplication path.
For each mapping the table indicates its location in the deduplication path (Direct path SDE and SIL are included for completeness, although they do not act on the deduplication path). It also shows the source and target of the mapping, and briefly describes what the mapping does.
Table 3-8 Informatica Mappings used by Multi-Source Integration
| Typical Mappings | Path | Segment ID | Segment | Source | Target | Initial/Incremental | Description |
|---|---|---|---|---|---|---|---|
|
SDE_<Source_App>_<Dimension>_Dim_Init |
Dedup |
Dedup 1 |
Bulk Load |
Source database |
Flat file |
Initial |
Full extract to generate a flat file for use with the bulk loader in initial load |
|
SDE_<Source_App>_<Dimension>_Dim_Inc |
Dedup |
Dedup 2 |
Extractor |
Source database |
Master Index |
Incremental |
Incremental extract for call to OHMPI API. |
|
SIL_MPI_<Dimension>_DIM |
Dedup |
Dedup 3 |
Convertor |
Master Index |
Persistent Staging |
Both |
Populate Persistent Staging from Master Index |
|
SIL_CDA_PS_<Dimension>_Dim |
Dedup |
Dedup 4a |
Apply Merge to Target |
Persistent Staging |
Dimension table |
Both |
Extract SBR from Persistent Staging, insert/update it in the Target dimension table |
|
SIL_CDA_PS_<Dimension>_Dim_Match_Merge |
Dedup |
Dedup 4b |
Apply Merge to Target |
Persistent Staging |
Dimension table |
Both |
Merge records in Dimension target table into their SBR. |
|
SDE_<Source_App>_<Dimension>_Dim |
Direct |
Direct 1 |
SDE |
Source database |
Staging table |
Both |
Extract source records for both initial and incremental loads |
|
SIL_<Dimension>_Dim |
Direct |
Direct 2 |
SIL |
Staging table |
Dimension table |
Both |
Transform Staged data to Target data for both initial and incremental loads |
|
Copyright © 2010, 2012, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|