| Oracle® Enterprise Manager Cloud Control Oracle Fusion Middlewareマネージメント・ガイド リリース12.1.0.8 B66835-11 |
|


 前 |
 次 |
| Oracle® Enterprise Manager Cloud Control Oracle Fusion Middlewareマネージメント・ガイド リリース12.1.0.8 B66835-11 |
|
前 |
次 |
Enterprise Managerのアプリケーションの依存性とパフォーマンス(ADP)機能は、パフォーマンス・メトリックを自動的に選択し、様々なアプリケーションのコンテキストの関係を追跡します。Methodologyは他の重要なアクティビティを集中して処理することで、ユーザーがアプリケーション・パフォーマンス監視環境を効率的に設定し、維持できるようにします。
これらのアクティビティには次のようなものがあります。
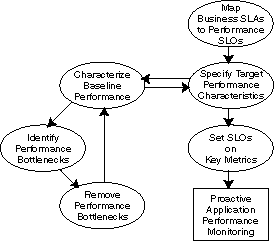
このMethodologyは、ユーザーがEnterprise Managerのアプリケーションの依存性とパフォーマンス機能を利用して、先見的なアプリケーション・パフォーマンス監視環境を確立し、維持するための一連の手順を示しています。図40-1で、これらの手順を順番に説明しています。
ビジネス・サービス・レベル合意(SLA)をパフォーマンス・サービス・レベル目標値(SLO)にマッピングします。
一致したビジネスSLAを使用してパフォーマンスSLOの価値を判断するプロセス。
ターゲット・パフォーマンス特性を指定します。
手順1で確認されたパフォーマンスSLOを使用して、適切なアプリケーション・パフォーマンス特性を指定します。
ベースライン・パフォーマンスを特性化します。
パフォーマンス・ボトルネックを識別します。
パフォーマンス・ボトルネックを削除します。
手順3、4および5を合せると、パフォーマンスが段階的に向上するプロセスになります。手順2で指定したパフォーマンス・ターゲットに合せてアプリケーション・パフォーマンスを向上するために、このプロセスの繰返しが必要になる場合があります。
重要なメトリックでSLOを設定します。
アプリケーション・パフォーマンスがターゲット目標に達したら、パフォーマンスSLOを重要なメトリックで設定して先見的な監視環境を構築する必要があります。この環境では、重要なパフォーマンス・メトリックで異常が報告され始めるとユーザーに警告が送られます。この警告によって、潜在的な問題がビジネスに影響を及ぼす前に事前に解決することができます。
この章では次のアクティビティの詳細を説明します。
ADP Methodologyのアクティビティには次のようなものがあります。
先見的なアプリケーション・パフォーマンス監視環境を問題なく設定するための最初の手順は、一連のビジネス目標を、監視対象となる一連のパフォーマンスしきい値にマッピングすることです。このようなビジネス目標は、しばしばビジネス・サービス・レベル合意(SLA)と呼ばれます。これらのビジネスSLAは、高レベルでの基本的なアプリケーション・パフォーマンス要件を示します。したがって、これらの高レベルのSLAを低レベルのパフォーマンスしきい値に適切にマッピングするのは大変難しいアクティビティです。
テクノロジ・レベル(EJB、JSP、サーブレット、ポートレット、SQLコールなど)でパフォーマンスの測定のみを行うツールを使用してこのタイプのアクティビティを実行しても、低レベルのメトリックと高レベルの目標の相関関係はあいまいな場合がほとんどであるため、難しさは変わりません。その結果、マッピング・アクティビティは科学ではなくアートであるとみなされることもあります。
Enterprise Managerでは、テクノロジ・レベルと機能レベルの両方でパフォーマンスを測定することで、このマッピング・アクティビティの複雑性が大幅に緩和されています。機能的メトリックによって高レベルの構成要素(ビジネス・プロセスまたはポータル・デスクトップなど)のパフォーマンスが測定されるため、ビジネスSLAのパフォーマンスSLO(サービス・レベル目標値)への直接的マッピングは簡単明瞭です。
監視対象アプリケーションのターゲット・パフォーマンス特性の定義は、ビジネスSLAのパフォーマンスSLOへのマッピングの後の2番目の手順です。このようなSLOはアプリケーションの絶対的な最小パフォーマンス要件を表すため、これらの違反しきい値をターゲット・パフォーマンス特性として使用してもほとんど意味がありません。かわりに、正常な操作でのパフォーマンスの許容範囲と、異常なアクティビティの警告アラートを送信するタイミングを定義する必要があります。
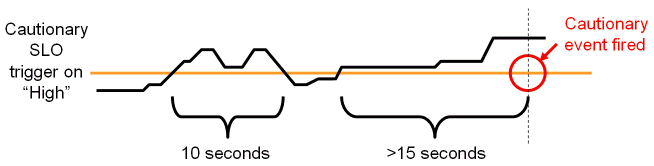
アプリケーションによっては、一連の警告パフォーマンスしきい値を指定するだけで十分です。ADPなどのアプリケーション・パフォーマンス監視ツールは、これらのしきい値に違反があると警告アラートを送信します。これらのしきい値は警告を目的としているため、わずかな違反であればアラートが送信されない場合があります。違反の最短期間の定義によって、重複したアラートが生成される数を最小限に抑えることができます。図40-2はこの概念を表しています。
図40-2では、違反の最短期間が15秒に定義されています。したがって、警告状態が15秒以下で終了した場合、警告アラートは発行されません。
他のアプリケーションでは、高および低の両方のパフォーマンスしきい値を定義することが必要です。両方のしきい値を設定することで、これらのアプリケーションの正常な操作の範囲を効率的に定義できます。ADPでは、高および低の両方のトリガーをどのSLOにも設定できます。
一連のターゲット・パフォーマンス特性を明確に定義しておくと、理想的なパフォーマンス範囲の達成にどの程度のパフォーマンス・チューニングが必要かを判断できます。また、一連の警告パフォーマンスしきい値を設定することで、先見的なアプリケーション・パフォーマンス監視環境を構築することができます。
この項で説明するアクティビティを合せると、1つのパフォーマンス向上プロセスになります。このプロセスは、アプリケーションのベースライン・パフォーマンスの特性化から、パフォーマンス・ボトルネックの識別に進み、パフォーマンス・ボトルネックの削除で終了します。アプリケーションのパフォーマンスがターゲット特性に到達するまで、これらのアクティビティを繰り返し行います。
ターゲット・パフォーマンス特性の指定が終了したら、次のアクティビティはアプリケーションのパフォーマンス・ベースラインの取得です。パフォーマンス・ベースラインを一連のターゲット・パフォーマンス特性と比較することで、パフォーマンスの向上がさらに必要かどうかを判断します。必要であれば、パフォーマンスがターゲット特性に到達するまで次の2つの手順を繰り返して、アプリケーションのパフォーマンスを向上します。
パフォーマンス・ボトルネックを識別するには、最初にパフォーマンス・ベースラインで異常なパフォーマンスを分離する必要があります。パフォーマンスの異常を分離したら、その問題が局所的な現象なのか体系的な問題なのかを判断します。ユーザーに提供される監視や診断のツールを使用することで、パフォーマンス・ボトルネックの原因の特定に必要な分析を実行できます。
このようにパフォーマンス・ボトルネックの識別が終了したら、削除方法を決定する必要があります。ボトルネックの削除方針は原因によって変わります。次にいくつか例を示します。
ボトルネックの原因がアプリケーションの不具合である場合、アプリケーション開発チームの協力が必要です。
ボトルネックが構成の問題によって引き起こされている場合、システム管理者の助力が必要になります。
ボトルネックがアプリケーション・サーバーまたはフレームワークに存在する場合、その製品のベンダーに協力を求めることになります。
次のようなボトルネック削除アクティビティが考えられます。
アプリケーション・コードの変更による不具合の修正
環境設定の変更による構成の問題の修正
パッチのインストールによるソフトウェアの不具合の修正
不備のあるハードウェアの入替え
ネットワーク・インフラストラクチャのアップグレード
コンピューティング・リソースの追加
リソースを大量消費するプログラムの削除
バックエンド接続とレスポンス時間のチューニング
この一覧からもわかるように、パフォーマンス・ボトルネックの削除アクティビティは原因によって大きく異なります。パフォーマンス・ボトルネックの解決を支援する適切なグループを正確かつ迅速に探し出すことが、このアクティビティを成功させる鍵となります。パフォーマンス・ボトルネックの削除が終了したら、ベースライン・パフォーマンスの特性化アクティビティを再実行して、実施された修正によって実際にパフォーマンスの改善があったことを確認します。
アプリケーション固有のパフォーマンスしきい値を設定する以外に、重要なシステム・メトリックと抜粋した一部のコンポーネント・メトリックでパフォーマンスしきい値を設定することも重要です。これらのしきい値を設定すると、早期警告システムが確立されることになり、小さな問題が本稼働時の大きな問題に発展する前にアラートが生成されます。
SLOを重要なシステム・メトリックに設定するには、負荷がかかった状態でシステムがどのように動作するかということの基本的な理解が求められます。JDBCの空き接続やExecuteQueueのアイドル・スレッドが不足するとシステムが不安定になったり、処理速度が遅くなる場合、これらのシステム・メトリックを監視する必要があります。
監視するシステム・メトリックを決定するには、システム全体のパフォーマンスと特定のシステム・メトリックの相関関係を判断することが不可欠です。この情報を使用して、どのシステム・メトリックを監視するか決定します。適切なシステム・メトリックを識別したら、正常な操作のパフォーマンス範囲を確認して、警告ならびに違反のしきい値を決定します。
監視するシステム・メトリックや、設定するシステム・メトリック・パフォーマンスしきい値の決定は比較的に簡単ですが、重要なコンポーネント・メトリックでのSLOの設定ははるかに難しくなります。理論的に、コンポーネント・レベルのパフォーマンスの低下は、アプリケーション・レベルのパフォーマンスにマイナスの影響を及ぼすと想定されます。ただし、この仮定は現実を正確に反映していない場合があります。
コンポーネント・レベルのパフォーマンス・メトリックを監視してアプリケーション・パフォーマンスを予測するには、特定のコンポーネントのパフォーマンスとアプリケーションのパフォーマンスの間に強い相関関係が必要です。あるコンポーネントでパフォーマンスが低下しても、別のコンポーネントのパフォーマンスの上昇によって相殺されることがあります。コンポーネント・レベルでのこのような反対方向へのパフォーマンスの変化では、基本的にアプリケーション・レベルではほとんど変更が生じません。したがって、強い相関関係が存在しないかぎり、わずかなコンポーネントのパフォーマンスを監視するだけで結論を出さないように注意する必要があります。
最後に実行するタスクは、各種のアクションおよびレスポンスを各種のしきい値違反に関連付けることです。これらの関連付けが終了すると、先見的なアプリケーション・パフォーマンス監視環境の使用を開始できます。
先見的なアプリケーション・パフォーマンス監視を構築するソリューションを企業が購入する大きな理由の1つは、ビジネスSLAを達成するという要求です。エンタープライズ・アプリケーションにとってのビジネスSLAは、社内または社外の顧客によって定義された一連のサービス・レベルの期待値です。ほとんどのケースで、これらのビジネスSLAは高レベルで定義されているため、アプリケーション・パフォーマンス監視ツールでのしきい値の設定には役立ちません。
この結果、ビジネスSLAをパフォーマンスSLOにマッピングするプロセスは、顧客によって設定されたサービス要件を企業が満たすためにきわめて重要になります。Enterprise Managerでは機能レベルとテクノロジ・レベルの両方でパフォーマンスが監視されるため、このマッピング作業を容易に実行することができます。
この項では、例を示すことで、Enterprise Managerのアプリケーションの依存性とパフォーマンス機能を使用して一連のビジネスSLAに対する適切なパフォーマンスしきい値を判別する方法を説明します。
例では、次のような高レベルのビジネスSLAがあります。
| ビジネスSLA | SLA要件 |
|---|---|
|
高速の顧客セルフサービス・ポータル。 |
顧客セルフサービス・ポータルのページは平均で2秒以内にロードされます。このSLA要件は99%の確率で実現する必要があります。 |
|
メインフレーム・システムと同じくらい高速な顧客サービス代理ポータル。 |
顧客サービス代理ポータルのすべてのページは6秒以内にロードされます。このSLA要件は99.9%の確率で実現する必要があります。 |
|
サービス・コールのスケジュールの短縮。 |
サービス・コールのスケジュール設定は平均30秒未満で行われます。このSLA要件は99.99%の確率で実現する必要があります。 |
最初のビジネスSLAをパフォーマンスSLOにマップします。このSLA要件は、顧客セルフサービス・ポータル(デスクトップ)の平均レスポンス時間が2秒未満となる必要があることを示しています。Enterprise Managerで、高レベルのパフォーマンスSLOをデスクトップで設定します。ADP UIの階層を使用して、顧客デスクトップを選択し、右クリックしてSLOを設定します。
ADPでは機能レベルとテクノロジ・レベルの両方でパフォーマンスが監視されるため、ビジネスSLAを機能メトリックのSLOに直接変換することができます。この例では、ポータル・デスクトップ顧客のレスポンス時間です。ここでは、違反のSLOと警告のSLOを設定します。
違反が発生する頻度を計算して、現在のシステムがSLA要件の確率99%を満たすかどうかを判断できます。Enterprise Managerでは、明らかな違反があるかどうかを確認できます。違反またはそれに近い状態がある場合は、実際のデータを調べて確認する必要があります。少なくとも24時間分のデータがある場合は、Enterprise ManagerのApplication Dependency and Performance内でエクスポート機能を使用してこの計算のためにRAWデータを用意します。
他の2つのビジネスSLAについても、適切なメトリックにパフォーマンスSLOを設定します。
ベースライン・パフォーマンスの特性化は、パフォーマンスのベースライン設定とも呼ばれますが、特定レベルのロードでのシステムのベースライン・パフォーマンスを取得する一連のアクティビティが含まれます。たとえば、WebLogicクラスタにデプロイされているポータル・アプリケーションのベースライン・パフォーマンスを測定することができます。
たとえば、ロード・テストの最初の4時間のパフォーマンス・データを表示できます。当初90分間はアクティブ・セッションの数が一定のペースで増加します。やがて、新たなセッションと期限切れになるセッションの数が均衡して、アクティブ・セッションの数は約700で止まります。
ポータルのパフォーマンスは、当初のパフォーマンスは遅く、次第に安定した状態に到達するという典型的なパターンをたどります。アプリケーション・サーバーがコンポーネントをメモリーにロードし、データをキャッシュ・メカニズムに移入するため、当初の遅いパフォーマンスは想定済のものです。パフォーマンスは次第に向上し、およそ30分後には安定した状態になります。この初期30分間のパフォーマンス・パターンは、ロードの増加時の起動パフォーマンスとして特徴付けられます。30分以降にはポータル・アプリケーションのパフォーマンスは安定します。
アプリケーション・パフォーマンス監視環境を迅速に確立するEnterprise Managerの機能によって、ベースライン・パフォーマンスの特性化を容易に行うことができます。Enterprise Managerではクラスタ・レベルと個別サーバー・レベルの両方で監視できるため、クラスタ全体または個別サーバーのパフォーマンスを特性化できます。
ロードの少ないサーバーはリソース使用率が低く、パフォーマンスが速いことを検証して、この環境で実行するポータル・アプリケーションのパフォーマンス特徴に関して次のような観察結果を導くことができます。
サーバーAのリソース使用率が最大値に近づいているため、そのサーバーのロードを個別サーバーの上限値として使用できます。個別サーバーのロードの上限値を計算するには、Enterprise Managerのアプリケーションの依存性とパフォーマンス機能に備わるロード・メトリックを使用します。
ロード・バランシング・アルゴリズムおよびロード・バランサの構成を調べる必要があります。
クラスタ内の2つのサーバーのロードとリソース使用率を比較すると、リソース使用率がロードに反比例することを確認できます。
|
注意: これは、個別サーバーの非常に基本的なパフォーマンスの特性化です。複数サーバー・クラスタのパフォーマンスは、クラスタ構成に付随するオーバーヘッドがあるため、個別サーバーのパフォーマンス特性を掛け合せて求めることはできません。クラスタ・レベルのパフォーマンスは、Enterprise Managerのようなアプリケーション・パフォーマンス監視ツールで測定する必要があります。 |
Enterprise Managerを使用すると、QA、ステージングおよび本番設定におけるパフォーマンス・ボトルネックも迅速に識別できます。Enterprise Managerのアプリケーションの依存性とパフォーマンス機能内の階層モデルを使用して、アプリケーションのパフォーマンス・ボトルネックを識別できます。さらに、リソース不足によって引き起こされたアプリケーションのパフォーマンスの問題を追跡する際もEnterprise Managerを使用できます。
パフォーマンスの問題がすべてのコンポーネントに同様に影響しているように見えるため、システム・レベルでなんらかのパフォーマンス低下があるのではないかと考えてみます。システム・レベルのパフォーマンス・データを確認するには、リソース階層の下を調べます。リソース階層の下のパフォーマンス・メトリックから、相関関係分析を実行するためのRAWデータを得ることができます。このようなタイプの分析は、リソース不足がパフォーマンス低下の原因かどうかを判別するために必要です。
グラフから興味深いパターンが明らかになることもあります。
OSエージェントの異常
問題の期間に、CPU使用率の急激な低下とディスク使用率の急激な上昇があることに気づきます。このパターンは、このマシンでの大容量の仮想メモリー・ページング・アクティビティを示しています。ディスクへのメモリー・ページングは、非常にコストがかかる処理であり、CPU使用率の低下に示されるようにリクエストの処理を遅らせます。ページングが発生する理由を理解するために、JVMに関するパフォーマンス・メトリックを調べます。
JVMヒープ・サイズ
この例では、最初の12時間に、JVM合計ヒープ・サイズとJVM空きヒープ・サイズの両方が少しずつ増えていることがわかります。JVM合計ヒープ・サイズの増加は512MBで止まっています。WebLogicの最大ヒープ・サイズを512MBに構成しているため、これは想定済の動作です。合計ヒープ・サイズが512MBになった後はJVM空きヒープ・サイズの増加が止まると予測されますが、実際には空きJVMヒープ・サイズは減り始めます。以前に取得した情報(ロードの急な増加がないなど)とこの情報を組み合せると、メモリー・リークの可能性が高いという結論を得られます。
このメモリーの異常な消費により、JVM合計ヒープ・サイズが事前定義された最大値に到達しました。このメモリー・リークが、仮想メモリー・ページング・アクティビティの増加を招き、それに応じてCPU使用率が減少したとも考えられます。このCPU使用率の減少は、JDBC接続を含め、このマシンで稼働中のすべてのコンポーネントのレスポンス時間に影響します。
メモリー・リーク
リソース不足が次第に引き起こされ、最終的にはアプリケーション・パフォーマンスに影響を及ぼすようなWebLogic JVMのメモリー・リークを特定することができました。この問題をさらに診断するには、JVMのメモリー使用方法を理解するための詳細レベルのメモリー・プロファイリング・ツールが必要です。
Oracle Methodologyのこの手順では、重要なシステム・メトリックを先見的に監視することによって、サーバーのハング(応答なし)、サーバーのクラッシュ、クラスタのハングなど突発的な障害を回避できます。このような突発的な障害につながる兆候を認識する機能は、WebLogicインフラストラクチャのサービス品質を維持するために欠かせません。
WebLogicの重要なシステム・メトリックのしきい値とアクションは事前に設定できます。表40-2にWebLogicプラットフォームの重要なシステム・メトリックの一覧を示します。
表40-2 WebLogicの重要なシステム・メトリックのリスト
| 重要なシステム・メトリック | 監視する理由 |
|---|---|
|
ExecuteQueueアイドル・スレッド数 |
ExecuteQueueスレッドの不足は、多くの場合アプリケーション・サーバー・ハング(応答なし)の前に発生します。深刻なケースでは、アプリケーション・サーバーでExecuteQueueスレッドが不足するとすべての操作が停止することもあります。 |
|
ExecuteQueue保留リクエスト数 |
ExecuteQueueの保留リクエスト数の一定ペースでの増加も、サーバー・ハングの前に発生します。このメトリックは、ExecuteQueueアイドル・スレッド数メトリックとは反比例の関係にあります。 |
|
JVM合計ヒープ・サイズ |
このメトリックを監視する理由は2つあります。
|
|
JVM空きヒープ・サイズ |
JVM空きヒープ・サイズが少しずつ減少する場合は、メモリー・リークまたはアプリケーション・サーバーの構成の問題のいずれかを示しています。ヒープ不足のJVMは、ガベージ・コレクタとJVMがそれぞれクリーンアップとオブジェクト作成の実行のためにリソースを競合することから、不安定になってパフォーマンスが低下します。 |
|
オープン・セッション数 |
オープン・セッション数が0まで減少し、一定期間0のままである場合、調査が必要です。このパターンは多くの場合、ネットワークまたはロード・バランシングの問題を示します。 |
|
アプリケーション呼出し数 |
アプリケーション呼出し数が0まで減少し、一定期間0のままである場合、調査が必要です。このパターンは多くの場合、ネットワークまたはロード・バランシングの問題を示しますが、サーバー・ハングの症状でもあります。 |
このようなWebLogicの重要なシステム・メトリックを理解した上で、SLOしきい値を設定し、適切なレスポンスを割り当てることが、先見的な監視の確立に不可欠です。この例では、ADPでSLOとアクションを構成します。
最初のタスクは、使用可能なExecuteQueueが減ってきたときに適切なユーザーがアラートを受け取れるように、警告と違反のSLOをExecuteQueueアイドル・スレッド数メトリックに設定することです。SLOを構成するには、実行キューのメトリックを右クリックして、「サービス・レベル目標値の構成」を選択します。この例では、ExecuteQueueのアイドル・スレッドについて次のSLOを作成します。
表40-3 ExecuteQueueのアイドル・スレッドのSLO
| SLO名 | メトリック | しきい値のタイプ | しきい値 | トリガー値 |
|---|---|---|---|---|
|
ExecuteQueueアイドル・スレッド(低) |
Metric.J2EE.Dispatcher.IdleThreads |
警告 |
3 |
低 |
|
ExecuteQueueアイドル・スレッドの消失 |
Metric.J2EE.Dispatcher.IdleThreads |
違反 |
0 |
低 |
SLOトリガーを「低」に設定すると、現在の測定がしきい値に到達し、前回の測定がしきい値よりも高い場合にADPでアラートが起動されます。
たとえば、事前に定義したSLOに対して次のアクションを作成します。
表40-4 SLOのアクション
| SLO名 | アクション名 | アクション・タイプ |
|---|---|---|
|
ExecuteQueueアイドル・スレッド(低) |
ExecuteQueueアイドル・スレッド(低)イベントをサーバー・ログに入力 |
ログ |
|
ExecuteQueueアイドル・スレッドの消失 |
ExecuteQueueアイドル・スレッドの消失アラートを電子メール送信 |
電子メール |
|
ExecuteQueueアイドル・スレッドの消失 |
ExecuteQueueアイドル・スレッドの消失SNMPトラップをHP Overviewに送信 |
SNMP |
|
ExecuteQueueアイドル・スレッドの消失 |
ExecuteQueueアイドル・スレッドの消失イベントをサーバー・ログに入力 |
ログ |
このようにSLOとアクションを構成することで、突発的なイベントが発生する前にExecuteQueueのリソース不足を検出できる先見的な監視環境が整いました。このアプローチを使用して、WebLogicの他の重要なシステム・メトリックについても先見的な監視を確立します。
Oracleの推奨設定を次に示します。
表40-5 ExecuteQueue保留リクエスト
| SLO名 | メトリック | しきい値のタイプ | しきい値 | トリガー値 |
|---|---|---|---|---|
|
ExecuteQueue保留リクエスト数の警告 |
Metric.J2EE.Dispatcher.PendingRequests |
警告 |
5 ~ 10脚注 1 |
高 |
|
ExecuteQueue保留リクエスト数の違反 |
Metric.J2EE.Dispatcher.PendingRequests |
違反 |
10 ~ 20 |
高 |
脚注 1 これらのSLOのしきい値は環境によって異なります。使用するしきい値を決めるのは繰返しプロセスです。ユーザーは、最初の手順として、自らのWebLogic環境のパフォーマンス特性の情報を集める必要があります。この情報に基づいてユーザーはSLOを設定できます。ユーザーがWebLogic環境のパフォーマンスの改善を続けるときは、これらのしきい値を再評価し、必要に応じて変更する必要があります。
SLOトリガーを「高」に設定すると、現在の測定がしきい値と等しくなったときにADPでアラートがトリガーされます。
表40-6 JVM合計ヒープ・サイズ
| SLO名 | メトリック | しきい値のタイプ | しきい値 | トリガー値 |
|---|---|---|---|---|
|
JVMヒープが最大値に増加 |
Metric.J2EE.JVM.HeapSizeCurrent |
警告 |
512MB脚注 1 |
高 |
|
JVMヒープが0に減少 |
Metric.J2EE.JVM.HeapSizeCurrent |
違反 |
0MB |
低 |
脚注 1 このSLOのしきい値は環境によって異なります。ユーザーは、WebLogic構成ファイルに指定されている最大ヒープ・サイズにこの値を設定できます。
表40-7 JVM空きヒープ・サイズ
| SLO名 | メトリック | しきい値のタイプ | しきい値 | トリガー値 |
|---|---|---|---|---|
|
JVM空きヒープ(低)の警告 |
Metric.J2EE.JVM.HeapFreeCurrent |
警告 |
72MB |
低 |
|
JVM空きヒープ(低)の違反 |
Metric.J2EE.JVM.HeapFreeCurrent |
違反 |
24MB |
低 |
表40-8 オープン・セッション数
| SLO名 | メトリック | しきい値のタイプ | しきい値 | トリガー値 |
|---|---|---|---|---|
|
5分間システムにユーザー・セッションなし |
Metric.J2EE.WebApplication.OpenSessionCurrentCount |
警告 |
0脚注 1 |
低 |
脚注 1 この例では、このSLOの測定ウィンドウは5分間です。測定ウィンドウを5分間にすると、条件が5分以上持続したときのみADPによりアラートが起動されます。
表40-9 アプリケーション呼出し数
| SLO名 | メトリック | しきい値のタイプ | しきい値 | トリガー値 |
|---|---|---|---|---|
|
5分間システムにアプリケーション呼出しなし |
Metric.J2EE.Servlet.InvocationTotalCount |
警告 |
0 |
低 |
これらのSLOと対応するアクションを設定すると、WebLogicデプロイメントの先見的な監視環境が確立されます。この先見的な監視アプローチにより、突発的な障害につながる問題を、システムのパフォーマンスと可用性に影響が及ぶ前に特定できます。