11g Release 1 (11.1.4)
Part Number E20386-04
Contents
Previous
Next
|
Oracle® Fusion
Applications Order Orchestration Implementation Guide 11g Release 1 (11.1.4) Part Number E20386-04 |
Contents |
Previous |
Next |
This chapter contains the following:
Oracle Fusion Distributed Order Orchestration Components: How They Work Together
Orchestration Lookups: Explained
Orchestration Profile Management: Points to Consider
Oracle Fusion Distributed Order Orchestration Extensible Flexfields: Explained
Oracle Fusion Distributed Order Orchestration Extensible Flexfield Uses: Explained
Oracle Fusion Distributed Order Orchestration Extensible Flexfield Setup: Explained
Manage Orchestration Source Systems
Collect Orchestration Reference and Transaction Data
The Oracle Fusion Distributed Order Orchestration architecture is situated between one or more order capture systems and one or more fulfillment systems. When a sales order enters Distributed Order Orchestration, the application components process the order, first by breaking it down into logical pieces that can be fulfilled, then assigning an appropriate set of sequential steps to fulfill the order, and, finally, calling services to carry out the steps. Throughout the process, Distributed Order Orchestration continues to communicate with the order capture and fulfillment systems to process changes and update information.
This figure shows the components that affect order processing. A sales order enters Distributed Order Orchestration from the order capture application. In Distributed Order Orchestration, the sales order proceeds through decomposition, orchestration, task layer services, and the external interface layer before proceeding to fulfillment systems. The following explanations fully describe the components within Distributed Order Orchestration.
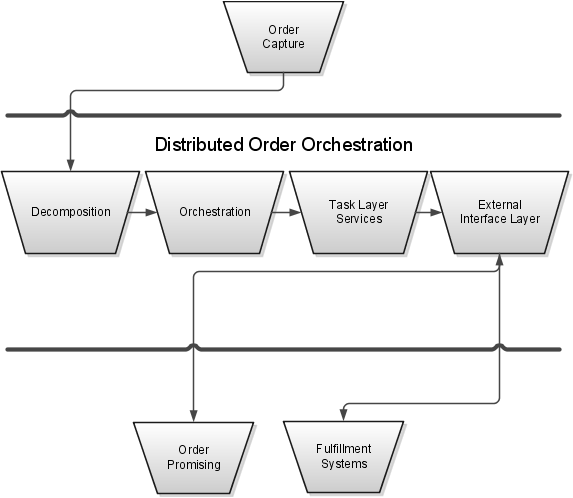
During decomposition, the application breaks down the sales order and uses defined product transformation rules to transform the sales order into an orchestration order. Then the fulfillment lines are grouped and assigned to designated orchestration processes with step-by-step fulfillment plans. An orchestration process is a predefined business process that coordinates the orchestration of physical goods and activities within a single order and automates order orchestration across fulfillment systems.
Orchestration is the automated sequence of fulfillment steps for processing an order. The orchestration process provides the sequence and other important information, such as forward and backward planning, how to compensate for changes, and which statuses to use.
During orchestration, task layer services are called to carry out the steps of the orchestration process.
Task layer services execute user-defined fulfillment process steps and manage fulfillment tasks. These services send information to downstream fulfillment systems and interpret the responses and updates from those systems. For example, task layer service Create Shipment request is invoked by a ship order process to send a shipment request to the shipping system.
The external interface layer manages the communication between Distributed Order Orchestration and external fulfillment systems. Its primary functions are routing the fulfillment request and transforming the data.
Oracle Fusion Distributed Order Orchestration provides lookups that you can use to optionally define values during processing. The majority of lookups are system-level, and they cannot be changed. You can make certain changes to user-level and extensible lookups.
Distributed Order Orchestration provides one user-level lookup: DOO_ACTIVITY_TYPE.
Users can:
Insert new codes.
Update the start date, end date, and enabled fields.
Delete codes.
Update tags.
The following extensible lookups are provided:
DOO_HLD_RELEASE_REASON
DOO_MSG_REQUEST_FUNCTION
DOO_RETURN_REASON
DOO_SUBSTITUTION_REASON
With extensible lookups, users can:
Insert new codes.
Update the start date, end date, enabled fields and tag, but only if the code is not seed data.
Delete codes, but only if the code is not seed data.
Users cannot:
Update the module.
Delete the lookup type.
Oracle Fusion Distributed Order Orchestration provides several product-specific profile values. Some control behavior in the Order Orchestration work area, while others control the receipt and transformation of sales orders into orchestration orders. Most have predefined values, so you do not need to configure them, unless your organization requires different profile values.
This profile option defines the value to use during any currency conversion in the Order Orchestration work area. The value is a conversion type. You can update the profile option at the site and user levels.
This profile option defines the currency used to display the amount in the Order Orchestration work area. The value is a currency. You can update the profile option at the site and user levels.
This profile option defines the default customer used to filter the summary of status data on the Overview page of the Order Orchestration work area and allows the user to view summary data only one customer at a time by removing the All option. No value is provided, by default. If you need to use it for performance reasons, then enter one of your customer IDs. You can update the profile option at the site level.
This profile option specifies whether to use the sales order number as the orchestration order number during sales order transformation. The default value is N. You can update the profile at the site and user levels.
This profile option specifies the number of seconds to wait after an action is taken to allow asynchronous services to complete before presenting a confirmation or warning message in the Order Orchestration work area. The default value is 5. You can update the profile option at the site level.
An extensible flexfield is similar to a descriptive flexfield in that it is an expandable data field that is divided into segments, where each segment is represented in the application database as a single column. Extensible flexfields support a one-to-many relationship between the entity and its extended attribute rows. Using extensible flexfields, you can add as many context-sensitive segments to a flexfield as you need. You can set up extensible flexfields for a fulfillment line or on other entities that support extensible flexfields. Extensible flexfields are useful primarily when you need to segregate attributes by task layer or capture multiple contexts to group them based on function.
You can use extensible flexfields for the following transactional entities on the orchestration order object.
Headers
Orchestration order lines
Fulfillment lines
Fulfillment line details
Price adjustments
Sales credits
Payments
Lot serial
Activities
Use extensible flexfields to send and receive additional information between Oracle Fusion Distributed Order Orchestration and integrated applications, write business rules, process changes, and display additional attributes on the Order Orchestration work area.
The sales order that Oracle Fusion Distributed Order Orchestration receives contains a predefined set of attributes. Your business process may require that you capture additional information or attributes on the sales order to use during order fulfillment. Distributed Order Orchestration uses extensible flexfields to receive the additional set of information or attributes that are captured on the sales order and use them during the fulfillment orchestration process.
The task layers use a specific fulfillment request object to initiate a fulfillment request in a downstream application. Using extensible flexfields, Distributed Order Orchestration can pass any additional information that you set up and capture on the orchestration order, beyond the predefined set of attributes, during implementation.
During the response to a fulfillment request, a fulfillment execution application can send various attributes that may have business value and which need to be seen either from the Order Orchestration work area or in the order capture application. This additional information also can be used in the next set of tasks, if that information is relevant to the set of tasks that follow this task. Using extensible flexfields, Distributed Order Orchestration can receive additional sets of attributes from the fulfillment execution applications.
You can use extensible flexfield attributes to write business rules for Distributed Order Orchestration. You can use extensible flexfield attributes to write rules for the following rules implementations:
Transformation rules
Pretransformation and posttransformation defaulting rules
Process assignment rules
External interface routing rules
You can use extensible flexfields during change management. You can designate an extensible flexfield as an order attribute that indicates that a change occurred. An extensible flexfield is interpreted as a single unit for change processing. Changes are not allowed from the Order Orchestration work area and are supported only through the services.
The Order Orchestration work area displays the following extensible flexfields.
Headers
Orchestration order lines
Fulfillment lines
Fulfillment line details
Activities
The extensible flexfield attributes are read-only. Users cannot edit them in the Order Orchestration work area.
To set up Oracle Fusion Distributed Order Orchestration extensible flexfields, you must define flexfields, deploy them, synchronize them with business rules, synchronize the SOA artifacts, and configure the enterprise business object.
The specific steps follow:
Run the Publish Extensible Flexfields Attributes process to create categories for the extensible flexfields.
Define categories, contexts, and associated segments along with value sets for each extensible flexfield that you want to enable through the Manage Extensible Flexfields setup.
Deploy the flexfield.
Run the Publish Extensible Flexfields Attributes process to synchronize the extensible flexfield attributes with Oracle Business Rules.
Execute the SOA composite UpdateSOAMDS for synchronizing the SOA artifacts.
Extend the enterprise business object.
Map the enterprise business object attributes with the extensible flexfield attributes.
Oracle Fusion Distributed Order Orchestration uses enterprise business objects to interact with external systems. An enterprise business object is made up of a business component, shared components, common components, reference components, common enterprise business objects, choice components, and attributes. These components are nested as required to create a sophisticated content model with varying cardinality from zero to one or unbounded. A custom element is defined in these component types and can be used to extend the properties of the component. The custom element then can be further mapped to extensible flexfield attributes in the interfaces.
The enterprise business objects are delivered as a set of XSD files. For every enterprise business object, a custom XSD file is provided in which all customer extensions are stored. Using customer extensions, you can include on the sales order additional attributes that your organization needs. For example, assume that you want to add DeliverToParty to the order header because the shipping system can honor this information. To integrate with the shipping system, you must extend the Sales Order enterprise business object. To add this new attribute at the header level, edit the following part of the CustomSalesOrderEBO.xsd schema definition:
<xsd:complexType name="CustomSalesOrderScheduleType"/>
After adding the attributes, this section of the schema definition looks like:
<xs:complexType name="CustomSalesOrderScheduleType">
<xs:sequence>
<xsd:element ref="corecom:DeliverToPartyReference" minOccurs="0">
</xsd:element>
</xs:sequence>
</xs:complexType>
The Sales Order enterprise business object is now ready to carry the custom attributes for DeliverToPartyReference. The custom attributes can be either from the common components library or can be new elements or attributes that are directly added if they did not exist in the common components library. Note that the extension of the underlying Sales Order enterprise business object also extends all enterprise business messages that reference the Sales Order enterprise business object. In the case of the Receive and Transform service that is used by the order capture application to submit an order, this is ProcessSalesOrderFulfillment.
The default transformations for the existing schemas may not be sufficient for some of your organization's specific business operations. You might want to add elements to the enterprise business object schemas as explained previously and then change transformation maps for the newly added elements to transfer the information from one application to the other.
At implementation time, the transformation maps that are associated with the external-facing interfaces must be modified to map the extensible flexfield attributes to the enterprise business object attributes.
Holds pause action on the business objects and services to which they are applied. In Oracle Fusion Distributed Order Orchestration, holds can come from an order capture system or the Order Orchestration work area. You define codes for use throughout Distributed Order Orchestration. The codes you define in Distributed Order Orchestration are for holds that originate in this application only. When you define hold codes, you indicate to which services the hold can be applied. You can also create a hold code that applies a hold to all services. Task layer services check to see whether any hold code is attached to the fulfillment line or order for one or more tasks in the orchestration process.
A hold that is applied in Distributed Order Orchestration can be released by the same application only, either by a user or by an orchestration process. A hold is applied by an orchestration process only when there is an existing hold request, either from the order capture application or from the Order Orchestration work area user. For example, an orchestration process is at the scheduling step when an order capture user sends a request to hold the shipping task. Distributed Order Orchestration stores the request until the orchestration process gets to the shipping step. At that point, the application searches for existing requests and applies them. When an orchestration process is canceled, associated holds are released automatically. Otherwise, the Order Orchestration user must release holds manually.
Only an order capture user can release a hold applied in the order capture application.
When a hold enters Distributed Order Orchestration from an order capture or order fulfillment application, it is transformed and becomes part of the orchestration order.
To populate the order orchestration and planning data repository, you collect data from external source systems, such as external fulfillment source systems and external order capture source systems, and from the Oracle Fusion source system. You manage which source systems are data collection source systems by defining collections parameters and enabling which source systems allow collections.
You manage two categories of source systems for data collections:
External source systems
The Oracle Fusion source system
The following figure illustrates data collections from three source systems. Two of the source systems are external source systems. One of the source systems is the Oracle Fusion source system.

Your business may have many external fulfillment and external order capture source systems. For each external source system from which you need to collect data to include in the order orchestration and planning data repository, define the data collection parameters, and enable the source system for collections. For the Version data collection parameter, the choices are Other or Oracle Fusion.
The order orchestration and order promising processes use data stored in the order orchestration and planning data repository. Some of the data that needs to be in the repository originates in the Oracle Fusion source system. To collect data from the Oracle Fusion source system, include the Oracle Fusion source system as a source system for data collection. Define the data collection parameters for the Oracle Fusion source system, and enable the source system for collections.
For each system from which you intend to collect data to populate the order orchestration and planning data repository, you define and maintain the source system data collection parameters.
For each source system, you complete the following for the data collection parameters:
Specify the time zone.
Specify the version, order orchestration type, and planning type.
Define the number of database connections, parallel workers, rows per processing batch, and cached data entries.
Enable collections allowed.
Enable data cross-referencing.
You must specify the time zone for the source system because the time stamps contained in collected data are converted from the time zone used in the source system to the time zone used for all data stored in the order orchestration and planning data repository. Using the same time zone for all data stored in the order orchestration and planning data repository facilitates correct results when calculations are performed using attributes that store dates. For example, if the source system uses the US Eastern time zone, but the order orchestration and planning data repository stores all data in the US Pacific time zone, then a supply with a due date and time of July 10th 04:00 PM in the source system is stored in the order orchestration and planning data repository with a due date of July 10th 01:00 PM.
You must define one, and only one, source system with the Version attribute equal to Oracle Fusion and the Order Orchestration Type attribute equal to Order Orchestration.
You may define many source systems with the Version attribute equal to Other. For the source systems with the Version attribute equal to Other, the Order Orchestration Type attribute can equal Fulfillment or Order Capture and the Planning Type attribute can equal Fulfillment. Any combination of these values is allowed to describe the purpose of the source system, but you must provide a value for at least one of these type parameters. These parameters do not impact the behavior of the collections process.
Note
Once you have saved a system with the Version attribute equal to Oracle Fusion, you cannot change the value for the Version attribute.
Note
You cannot change the version of a source system from Others to Fusion. You must delete the planning source system definition by scheduling the Delete Source Configuration and All Related Data process. The Delete Source Configuration and All Related Data process performs multiple steps. First the process deletes all data previously collected from the source system. After deleting the collected data, the process deletes the planning source system definition and collection parameters. After the Delete Source Configuration and All Related Data process completes, you must redefine the planning source system definition on the Manage Planning Source Systems page.
These parameters affect the usage of system resources. The table below defines what each parameter does and provides guidelines for setting it.
|
Parameter |
What the Parameter Does |
A Typical Value for the Parameter |
|---|---|---|
|
Number of Database Connections |
Defines the maximum number of database connections the source server can create during the collection process. This controls the throughput of data being extracted into the Source Java program. |
10 |
|
Number of Parallel Workers |
Defines the maximum number of parallel workers (Java threads) used to process the extracted data. The number here directly impacts the amount of CPU and memory used during a collection cycle. |
30 |
|
Number of Rows per Processing Batch |
Define the number of records to process at a time. The idea is to allow the framework to process data in byte-size chunks. A batch too small may cause extra overhead while a batch too big might peak out memory or network bandwidth. |
10,000 |
|
Cached Data Entries in Thousands |
During data collections, various lookup and auxiliary data are cached in the collection server to support validation. For example, currency rate may be cached in memory. This parameter controls the maximum number of lookup entries cached per lookup to prevent the server from occupying too much memory. |
10,000 |
Before enabling a source system for collections, ensure your definition of the other parameters are complete for the source system. Ensure you have defined values for all applicable attributes, and where applicable, you have enabled organizations for collections or for ATP Web services.
When you enable a source system for data cross-reference, the data collections from the source system perform additional processing steps to check for and to cross-reference data during data collections. You must enable cross-referencing for Order Capture source systems.
From the list of organizations for each source systems, you designate which organizations will have their data collected when a collections process collects data from the source system.
To determine which organizations to enable for collections, analyze the sourcing strategies for your company, the type of organization for each organization in the list, and any other business requirements that would determine whether system resources should be expended to collect data from that organization. If the data from that organization would never be used by order promising or order orchestration, no need to collect the data.
For example, consider a scenario where the list of organizations for a source system includes 20 manufacturing plants and 10 distribution centers. Because the business requirements specify that the movements of materials from the manufacturing plants to the distribution centers are to be controlled separately from order orchestration and order promising, there are no sourcing rules that include transferring from one of the manufacturing plants. For this scenario, you would only enable the 10 distribution centers for collections.
No. You cannot add additional source systems when managing source systems for data collections for the order orchestration and planning data repository.
Source systems must first be defined in the Trading Community Model. For the system to be listed as one of the systems from which to choose from when managing source systems, the definition of the system in the Trading Community Model must enable the system for order orchestration and planning.
You perform data collections to populate the order orchestration and planning data repository. The collected data is used by Oracle Fusion Distributed Order Orchestration and Oracle Fusion Global Order Promising.
The following figure illustrates that the order orchestration and planning data repository is populated with data from external source systems and from the Oracle Fusion source system when you perform data collections. Oracle Fusion Distributed Order Orchestration uses some reference data directly from the repository, but the Global Order Promising engine uses an in-memory copy of the data. After data collections are performed, you refresh the Global Order Promising data store with the most current data from the data repository and start the Global Order Promising server to load the data into main memory for the Global Order Promising engine to use. When Oracle Fusion Distributed Order Orchestration sends a scheduling request or a check availability request to Oracle Fusion Global Order Promising, the Global Order Promising engine uses the data stored in main memory to determine the response.

You perform data collections to populate the order orchestration and planning data repository with data from external source systems and from the Oracle Fusion source system.
Oracle Fusion Distributed Order Orchestration uses some reference data directly from the order orchestration and planning data repository. You must perform data collections for the order orchestration reference entities even if you are not using Oracle Fusion Global Order Promising.
Important
Before collecting data from an Oracle Fusion source system, you must define at least one organization for the source system. After you have defined at least one organization for the source system, you must update the organization list for the source system on the Manage Planning Source Systems page or Manage Orchestration Source Systems page, and enable at least one organization for collections. If there are no organizations enabled for collections when a collections process runs, the collections process will end with an error.
The Global Order Promising engine uses an in-memory copy of the data from the order orchestration and planning data repository. When Oracle Fusion Distributed Order Orchestration sends a scheduling request or a check availability request to Oracle Fusion Global Order Promising, the Global Order Promising engine uses the data stored in main memory to determine the response to send back to order orchestration. After a cycle of data collections is performed, you refresh the Global Order Promising data store with the most current data from the data repository and start the Global Order Promising server to load the data into main memory for the Global Order Promising engine to use.
The order orchestration and planning data repository provides a unified view of the data needed for order orchestration and order promising. You manage data collection processes to populate the data repository with data collected from external source systems and from the Oracle Fusion source system. You manage the data collection processes to collect the more dynamic, transaction data every few minutes and the more static, reference data on a daily, weekly, or even monthly schedule. The data collected into the data repository contains references to data managed in the Oracle Fusion Trading Community Model and to data managed in the Oracle Fusion Product Model. The data managed in these models is not collected into the order orchestration and planning data repository.
The following figure illustrates that the order orchestration and planning data repository is populated with data collected from external source systems and from the Oracle Fusion source system. The data repository does not contain data managed by the Oracle Fusion Trading Community Model and the Oracle Fusion Product Model. The data collected into the data repository references data managed in the models.

When you plan and implement your data collections, you determine which entities you collect from which source systems, the frequency of your collections from each source system, which data collection methods you will use to collect which entities from which source systems, and the sequences of your collections. Consider these categories of data when you plan your data collections:
Data collected for order promising
Data collected for order orchestration
Data not collected into the order orchestration and planning data repository
The following data is collected and stored to support order promising:
Existing supply including on-hand, purchase orders, and work orders
Capacity including supplier capacity and resource capacity
Related demands including work order demands and work order resource requirements
Planned supply including planned buy and make orders
Reference data including calendars, transit times, and routings
Important
After performing data collections, you must refresh the Order Promising engine to ensure it is using the data most recently collected.
The following data is collected and stored to support order orchestration:
Order capture and accounts receivable codes
Accounting terms and currencies
Tip
Use the Review Planning Collected Data page or the Review Order Orchestration Collected Data page to explore many of the entities and attributes collected for the order orchestration and planning data repository.
Data collected into the order orchestration and planning data repository includes attributes, such as customer codes, that refer to data not collected into the data repository. Most of the data references are to data in the Oracle Fusion Trading Community Model or in the Oracle Fusion Product Model. Some of the data references are to data outside the models, such as item organizations and inventory organizations. To manage data collections effectively, especially the sequences of your collections, you must consider the data dependencies created by references to data not collected into the data repository.
References to data in the Oracle Fusion Trading Community Model include references to the following:
Source systems
Geographies and zones
Customers
Customer sites
References to data in the Oracle Fusion Product Model include references to the following:
Items, item relationships, and item categories
Item organization assignments
Structures
When you collect data for the order orchestration and planning data repository, you specify which of the data collection entities to collect data for during each collection. When you plan your data collections, you plan which entities to collect from which source systems and how frequently to collect which entities. One of the factors you include in your planning considerations is the categorizations of each entity. One way entities are categorized is as reference entities or transaction entities. You typically collect transaction entities much more frequently than reference entities.
Another way entities are categorized is as source-specific entities or global entities. For global entities the order in which you collect from your source systems must be planned because the values collected from the last source system are the values that are stored in the data repository.
When you plan your data collections, you consider the following categorizations:
Source-specific entities
Global entities
Reference entities
Transaction entities
You also consider which entities can be collected from which types of source systems using which data collection methods as follows:
Entities you can collect from the Oracle Fusion source system and from external source systems
Entities you can collect only from external source systems
When you collect data for a source-specific entity, every record from every source system is stored in the order orchestration and planning data repository. The source system association is maintained during collections. The data stored in the data repository includes the source system from which the data was collected.
For example, you collect suppliers from source system A and source system B. Both source systems contain a record for the supplier named Hometown Supplies. Two different supplier records will be stored in the data repository for the supplier named Hometown Supplies. One record will be the Hometown Supplies supplier record associated with source system A and the second record will be the Hometown Supplies supplier record associated with source system B.
The majority of the data collections entities are source-specific entities.
When you collect data for a global entity, only one record for each instance of the global entity is stored in the order orchestration and planning data repository. Unlike source-specific entities, the source system association is not maintained during collections for global entities. The data stored in the data repository for global entities does not include the source system from which the data was collected. If the same instance of a global entity is collected from more than one source system, the data repository stores the values from the last collection.
For example, you collect units of measure (UOM) from three source systems and the following occurs:
During the collection of UOM from source system A, the Kilogram UOM is collected.
This is first time the Kilogram UOM is collected. The Kilogram record is created in the data repository.
During the collection of UOMs from source system B, there is no collected UOM with the value = Kilogram
Since there was no record for the Kilogram UOM in source system B, the Kilogram record is not changed.
During the collection of UOMs from source system C, the Kilogram UOM is also collected.
Since the collections from source system C include the Kilogram UOM, the Kilogram record in the data repository is updated to match the values from source system C.
The following entities are the global entities:
Order orchestration reference objects
Units of measure (UOM) and UOM conversions
Demand classes
Currency and currency conversion classes
Shipping methods
Tip
When you collect data for global entities from multiple source systems, you must consider that the last record collected for each occurrence of a global entity is the record stored in the order orchestration and planning data repository. Plan which source system you want to be the source system to determine the value for each global entity. The source system that you want to be the one to determine the value must be the source system that you collect from last.
Reference entities are entities that define codes and valid values that are then used regularly by other entities. Units of measure and demand classes are two examples of reference entities. Reference entities are typically static entities with infrequent changes or additions. Whether an entity is reference entity or a transaction entity does not impact how it is stored in the order orchestration and planning data repository.
You consider whether an entity is a reference entity or a transaction entity when determining which collection method to use to collect data for the entity. You typically use the staging tables upload method to collect data for reference entities from external source systems. You typically used the targeted collection method to collect data for reference entities from the Oracle Fusion source system unless the reference entity is one of the entities for which the targeted collection method is not possible.
Transaction entities are the entities in the data repository that store demand and supply data. Because the data for transaction entities changes frequently, you typically use the web services upload method to collect data for transaction entities from external source systems. You typically use the continuous collection method to collect data for transaction entities from the Oracle Fusion source system.
Many of the data collection entities can be collected from both types of sources systems. For the following entities you can use any of the collections methods:
Approved supplier lists
Calendars
Calendar associations
Interlocation shipping networks
Item costs
On hand
Organization parameters
Purchase orders and requisitions
Subinventories
Suppliers
Units of measure
For the following entities you can only use the Web service upload method to collect data from external source systems:
Currencies
Order orchestration reference objects
Shipping methods
Many of the data collection entities can be only collected from external sources systems. For these entities, you can use both methods for collecting data from external source systems. Remember to consider frequency of change and volume of data in your considerations of which methods to use to collect which entities. The following are the entities you can only collect from external sources systems:
Customer item relationships
Demand classes
Planned order supplies
Routings
Resources
Resource availability
Sourcing
Supplier capacities
Work-in-process supplies
Work-in-process component demands
Work-in-process resource requirements
To populate the order orchestration and planning data repository with data collected from external source systems, you use a combination of two data collection methods. The two methods are Web service uploads and staging tables uploads.
The following figure illustrates the two data collection methods, Web service uploads and staging tables uploads, used to collect data from external source systems. The figure illustrates that both methods require programs to be written to extract data from the external source systems. For Web service uploads, you load the data from the extracted data files directly into the order orchestration and planning data repository. Any records with errors or warnings are written to the data collections staging tables. For staging table uploads, you load the data from the extracted data files into the data collections staging tables, and then you use the Staging Tables Upload program to load the data from the staging tables into the data repository.

You determine which entities you collect from which source systems and at what frequency you need to collect the data for each entity. The data for different entities can be collected at different frequencies. For example, supplies and demands change frequently, so collect data for them frequently. Routings and resources, are more static, so collect data for them less frequently.
Which data collection method you use for which entity depends upon the frequency of data changes as follows:
Web service upload
Use for entities with frequent data changes.
Staging tables upload
Use for entities with more static data.
Use the Web service upload method for entities that change frequently, such as supply and demand entities. You determine the frequency of collections for each entity. For certain entities, you may implement Web services to run every few minutes. For other entities, you may implement Web services to run hourly.
To implement and manage your Web service uploads, you must design and develop the processes and procedures to extract the data in the format needed by the data collection web services. For more information regarding the data collection Web services, refer to the Oracle Enterprise Repository. For additional technical details, see Oracle Fusion Order Promising Data Collection Staging Tables and Web Service Reference, document ID 1362065.1, on My Oracle Support at https://support.oracle.com.
Use the staging tables upload method for entities that do not change frequently, such as routings and resources. You determine the frequency of collections for each entity. You may establish staging table upload procedures to run daily for some entities, weekly for some entities, and monthly for other entities.
To implement and manage your staging table uploads, you must develop the processes and procedures you use to extract data from an external source system. You use Oracle Data Interchange, or another data load method, to load the extracted data into the data collection staging tables. For additional technical details, such as the table and column descriptions for the data collection staging tables, see Oracle Fusion Order Promising Data Collection Staging Tables and Web Service Reference, document ID 1362065.1, on My Oracle Support at https://support.oracle.com.
For the final step of the staging tables upload method, you initiate the Load Data from Staging Tables process from the Manage Data Collection Processes page or via the Enterprise Scheduling Service.
To populate the order orchestration and planning data repository with data collected from the Oracle Fusion source system, you use a combination of two data collection methods: continuous collection and targeted collection. You typically use continuous collection for entities that change frequently and targeted collection for entities that are more static.
The following figure illustrates the two data collection methods, continuous collection and targeted collection, used in combination to collect data from the Oracle Fusion source system.

When you use the continuous collection method, you are only collecting incremental changes, and only for the entities you have included for continuous collection. Because continuous collection only collects incremental changes, you usually set up the continuous collection to run frequently, such as every five minutes.
Note
Prior to including an entity for continuous collection, you must have run at least one targeted collection for that entity.
When you collect data using the targeted collection method, you specify which entities to include in the targeted collection. For the included entities, the data in the data repository that was previously collected from the Oracle Fusion source system is deleted and replaced with the newly collected data. The data for the entities not included in the targeted collection is unchanged. You typically use the targeted collection method to collect data from entities that do not change frequently.
For your data collections from the Oracle Fusion source system, you use the Manage Planning Data Collection Processes page or the Manage Orchestration Data Collection Processes page. From these pages you perform the following:
Manage your continuous collections from the Oracle Fusion source system.
Manage your collections destination server.
Perform your targeted collections from the Oracle Fusion source system.
For your data collections from external source systems, most of the management of your Web services uploads and staging tables uploads is performed external to the Oracle Fusion application pages. If you choose to perform staging tables uploads, you initiate the Perform Data Load process from the Manage Planning Data Collection Processes page, from the Manage Orchestration Data Collection Processes page, or from the Oracle Fusion Enterprise Scheduler.
To enable continuous collections, you must set up the publish data processes for the Oracle Fusion source system. The publish process performs the incremental data collections from the Oracle Fusion source system. You can start, stop, and pause the publish process. To review statistics regarding the publish process, view process statistics from the Actions menu on the Continuous Collection - Publish tab on the Manage Planning Data Collection Processes page or the Manage Orchestration Data Collection Processes page.
Note
Because continuous collections only collects net changes, you must perform at least one targeted collection for an entity before you include the entity for continuous collections.
You define the publish process parameters to determine the frequency and scope of the continuous collections publish process.
You define the frequency and scope of continuous collections by specifying the following:
Process Parameters
Process Entities
You determine how frequently the continuous collections publish process executes by specifying the frequency in minutes. The continuous collections publish process will publish incremental changes based on the frequency that was defined when the publish process was last started.
You determine which organizations will be included in the set of organizations for which data is collected by specifying an organization collection group. You can leave it blank if you want data collected from all organizations.
You determine which entities are collected during the continuous collections cycles by selecting which entities you want included in the collections. The continuous collections publish process collects incremental changes for the business entities that were included when the publish process was last started.
The collections destination server is applicable to all four data collection methods. For the continuous collections method the collections server is the subscriber to the continuous collections publish process. From the Actions menu on the Collections Destination Server tab you can access a daily statistic report with statistics regarding each of the collection methods. You also can access a data collections summary report.
The collection parameters are initially set to what was defined for the Oracle Fusion system when your planning source systems or order orchestration source systems were initially managed. You can fine tune the parameters for your data collections.
The data collection parameters affect the usage of system resources. This table define what each parameter does and provides guidelines for setting it.
|
Parameter |
What the Parameter Does |
A Typical Value for the Parameter |
|---|---|---|
|
Number of Database Connections |
Defines the maximum number of database connections the source server can create during the collection process. This controls the throughput of data being extracted into the Source Java program. |
10 |
|
Number of Parallel Workers |
Defines the maximum number of parallel workers (Java threads) used to process the extracted data. The number here directly impacts the amount of central processing units and memory used during a collection cycle. |
30 |
|
Cached Data Entries in Thousands |
During data collections, various lookup and auxiliary data are cached in the collection server to support validation. For example, currency rate may be cached in memory. This parameter controls the maximum number of lookup entries cached per lookup to prevent the server from occupying too much memory. |
10,000 |
When you collect data from multiple source systems, you often collect a variety of values for the same instance of an entity. You cross-reference data during data collections to store a single, agreed value in the order orchestration and planning data repository for each instance of an entity.
The following information explains why you might need to cross-reference your data during data collections, and what you need to do to implement cross-referencing:
Cross-reference example
Cross-reference implementation
The following table provides an example of why you might need to cross-reference your data during data collections. In the example, the Kilogram unit of measure is collected from two source systems. The source systems use a different value to represent kilogram. You decide to store kg for the value for Kilogram in the order orchestration and planning repository.
|
Source System |
Collections Entity |
Source Value |
Target Value |
|---|---|---|---|
|
System A |
Unit of measure |
kilogram |
kg |
|
System B |
Unit of measure |
k.g. |
kg |
To implement cross-referencing, you must complete the following actions:
Decide which business object to enable for cross-referencing.
For each object, work with business analyst to decide which values to map to which other values.
Use the Oracle Fusion Middleware Domain Value Map user interface to upload mappings to the corresponding domain value map.
On the Manage Planning Data Collection Processes page, enable the corresponding entity for cross-referencing.
Determine an ongoing procedure for adding new values into the domain value map.
The continuous collection data collection method is partially supported for item costs. Item costs are collected in the next incremental collection cycle for previously existing items when one or more item organization attributes in addition to item cost have changed.
When a new item is defined, the item cost for the new item is not collected in the next incremental collection cycle. If an existing item is not changed other than an update to the item cost, the item cost change is not picked up in the next incremental collection cycle.
Tip
If items are added frequently, item costs are changed frequently, or both, then targeted collection of item costs should be routinely performed, perhaps once a day.
To use the staging tables upload method, you must load the data you extract from your external source systems into the staging tables. You can use Oracle Data Integrator to load the extracted data into the staging tables.
If you have installed Oracle Data Integrator (ODI), and configured ODI for use by Oracle Fusion applications, you can load data to the staging tables by scheduling the Perform Data Load to Staging Tables process, PerformOdiSatagingLoad. To use this process, you must perform these steps and understand these details:
Steps to use the Perform Data Load to Staging Tables process
Steps to manually prepare and update the required dat files
Details regarding the Perform Data Load to Staging Tables process
Steps to verify execution status after starting the Perform Data Load to Staging Tables process
Details regarding verifying the Perform Data Load to Staging Tables process execution status
List of interface ODI scenarios run for each business entity
The Perform Data Load to Staging Tables process invokes an ODI data load. To use this process, follow these steps:
Create a data file for each business entity for which you are extracting data from your external source system. The file type for the data files must be dat. Use the sample dat files provided on My Oracle Support as templates. The data in the files you create must conform to the exact formats provided in the sample files.
To obtain the sample dat files, see Oracle Fusion Order Promising Data Collections Sample ODI Data Files, document ID 1361518.1, on My Oracle Support https://support.oracle.com.
You can open the sample dat files in a spreadsheet tool to review the sample data. The sample data shows the minimum required fields for an entity.
Place the dat files in the host where the Supply Chain Management (SCM) ODI agent is installed. The dat files must be placed at this specific location: /tmp/ODI_IN.
The path for this location is configured for the SCM ODI Agent. The SCM ODI Agent is an ODI software agent that services ODI related client requests. More information about this agent can be found in the ODI product documentation.
After ODI is installed, you must use the ODI console to refresh the variables C_LAST_UPDATED_BY and C_CREATED_BY.
Schedule the Perform Data Load to Staging Tables, PerformOdiStagingLoad, process.
You can develop data extract programs to extract data from your external source systems and store the extracted data into the required dat files in the required format. To manually add data to the dat files, follow these steps:
Open the applicable dat file in a spreadsheet tool. When you open the file, you will be prompted to specify the delimiter.
Use the tilde character, ~ , for the delimiter.
Add any data records you want to upload to the staging tables into the spreadsheet. Data for date type columns must be in the DD-MON-YY date format.
Save the worksheet from the spreadsheet tool into a text file.
Use a text editor and replace spaces between columns with the tilde character.
Verify that every line terminates with a CR and LF (ASCII 000A & 000D respectively.)
Upload the dat file to the /tmp/ODI_IN directory where the SCM ODI agent is running. The location is seeded in the ODI topology. Upload (FTP) the dat file in binary mode only.
Review the file in vi after the FTP upload to detect junk characters and, if any, remove them.
The Perform Data Load to Staging Tables process invokes the ODI scenario MASTER_PACKAGE that internally invokes all four projects defined in ODI for collections. Each of these four projects invokes various interfaces. Data is loaded from flat files to staging tables for all the business objects enabled for Oracle Fusion 11.1.2.0.0 through Oracle Data Integrator.
The following are specific details for the process:
Process Name: PerformOdiStagingLoad
Process Display Name: Perform Data Load to Staging Tables
Process Description: Collects planning data from flat files and loads to staging tables using Oracle Data Integrator.
ODI Project Name: SCM_BulkImport
ODI scenario Name: MASTER_PACKAGE
SCM Scheduler: SCM_ESS_ODI_SCHEDULER
Agent URL: your_host_name:your_port_no/oracleodiagent (substitute your host name and your port number)
To verify the execution status after starting the Perform Data Load to Staging Tables process, perform these steps:
The Perform Data Load to Staging Tables process does not log messages to the scheduled processes side. To check for a log message, query the Request_History table using this select statement:
Select * from fusion_ora_ess.request_history where requestid= <request_id>;
Check the Status column for the overall execution status of the job and the Error_Warning_Detail column for a detailed error message, if any.
Check the ODI scenario execution status details in the ODI operator window. The scenario names are listed in the table in the List of Interface ODI Scenarios Run for Each Business Entity section of this document.
If log directories are accessible, check the following ODI logs for specific information on ODI scenario execution path:
/slot/emsYOUR_SLOT_NUMBER/appmgr/WLS/user_projects/domains/wls_appYOUR_SLOT_NUMBER/servers/YOUR_ODI_SERVER_NAME/logs
Diagnostic: for any errors in execution
Server: for all the logs specific to ODI console
Agent: for scenario entry and exit and for session ID
When verifying the Perform Data Load to Staging Table process, remember the following:
No logs will be written at the scheduled processes side. Also, the session id for ODI scenario cannot be found at the scheduled processes side.
When viewing the process status on the Scheduled Processes page, a Success status does not mean that all the data got into the staging tables successfully. The Success status only indicates that the scenario is launched successfully. Scenario status must be checked from ODI logs.
You cannot determine the refresh_number generated by ODI for the current process run from the Scheduled Processes page. To obtain the refresh number, you must use this query to query the msc_coll_cycle_status table and check for the ODI collection_channel:
Select * from msc_coll_cycle_status order by refresh_number desc;
One or more interface ODI scenarios are run for each business entity. Each interface scenario maps to one entity. If any interface Scenario fails in ODI, that entity data is not collected to the staging tables. This table lists the business entities and the interface ODI scenarios run within each business entity.
|
Business Entity |
Interface ODI Scenarios |
|---|---|
|
Work-in-Process Requirements |
WIP_COMP_DEMANDS _SCEN WIP_OP_RESOURCE_SCEN |
|
Calendars |
CALENDAR_SCEN CALENDAR_WORKDAYS_SCEN CALENDARDATES_SCEN CALENDAR_EXCEPTIONS_SCEN CALENDARSHIFTS_SCEN CALENDAR_PERIODSTARTDAYS_SCEN CALENDAR_WEEKSTARTDAY_SCEN CALENDAR_ASSIGNMENTS_SCEN |
|
Demand Classes |
DEMAND_CLASS_SCEN |
|
Global Supplier Capacities |
GLOBAL_SUP_CAPACITIES_SCEN |
|
Interorganization Shipment Methods |
SHIPMENT_METHODS_SCEN |
|
Item Cost |
ITEM_COST_SCEN |
|
Item Substitutes |
ITEM_SUBSTITUTES_SCEN |
|
Item Suppliers (Approved Supplier List) |
ITEM_SUPPLIERS_SCEN |
|
On Hand |
ONHAND_SCEN |
|
Organizations |
ORGANIZATIONS_SCEN |
|
Purchase Orders and Requisitions |
SUPPLY_INTRANSIT_SCEN PO_IN_RECEIVING_SCEN PO_SCEN PR_SCEN |
|
Planned Order Supplies |
PLANNEDORDERSUP_SCEN |
|
Resources |
RESOURCES_SCEN RESOURCE_CHANGE_SCEN RESOURCE_SHIFTS_SCEN RESOURCE_AVAILABILITY_SCEN |
|
Routings |
ROUTING_OPERATION_RESOURCES_SCEN ROUTINGS_SCEN ROUTING_OPERATIONS_SCEN |
|
Sourcing Rules |
SOURCING_ASSIGNMENTS_SCEN SOURCING_RULES_SCEN SOURCING_ASSIGNMENTSETS_SCEN SOURCING_RECEIPT_ORGS_SCEN SOURCING_SOURCE_ORGS_SCEN |
|
Subinventories |
SUB_INVENTORIES_SCEN |
|
Trading Partners |
TRADING_PARTNERS_SCEN TRADING_PARTNER_SITES_SCEN |
|
Units of Measure |
UOM_SCEN UOM_CONVERSION_SCEN UOM_CLASS_CONVERSION_SCEN |
|
Work Order Supplies |
WORKORDER_SUPPLY_SCEN |
To perform a data load from the data collection staging tables, you invoke the Perform Data Load from Staging Tables process. When you invoke the process, you provide values for the parameters used by the process
When you perform an upload from the staging tables, you specify values for a set of parameters for the Perform Data Load from Staging Tables process including specifying Yes or No for each of the entities you can load. For the parameters that are not just entities to select, the table below explains the name of each parameter, the options for the parameter values, and the effect of each option.
|
Parameter Name |
Parameter Options and Option Effects |
|---|---|
|
Source System |
Select from a list of source systems. |
|
Collection Type |
|
|
Group Identifier |
Leave blank or select from the list of collection cycle identifiers. Leave blank to load all staging table data for the selected collection entities. Select a specific collection cycle identifier to load data for that collection cycle only. |
|
Regenerate Calendar Dates |
|
|
Regenerate Resource Availability |
|
The parameters presented for the Perform Data Load from Staging Tables process also include a yes-or-no parameter for each of the entities you can collect using the staging tables upload method. If you select yes for all of the entities, the data collections will be performed in the sequence necessary to avoid errors caused by data references from one entity being loaded to another entity being loaded.
Important
If you do not select yes for all of the entities, you need to plan your load sequences to avoid errors that could occur because one of the entities being loaded is referring to data in another entity not yet loaded. For more information, see the articles regarding order promising or data collections on My Oracle Support at https://support.oracle.com.
The collection cycle identifier is a unique number that identifies a specific data collection cycle, or occurrence. One cycle of a data collection covers the time required to collect the set of entities specified to be collected for a specific data collection method. The collection cycle identifier is then used in statistics regarding data collections, such as the Data Collection Summary report. The collection cycle identifier is also used for a parameter in various processes related to data collections, such as the Purge Staging Tables process and the Perform Data Load process.
This topic explains the population of the collection cycle identifier when you use collecting data from external source systems as follows:
Web Service Uploads and the Collection Cycle Identifier
Staging Tables Uploads and the Collection Cycle Identifier
When you use the Web service upload data collection method, a collection cycle identifier is included as part of the collected data. You can then use the collection cycle identifier to review statistics regarding the Web service collections, or to search for error and warning records written to the data collection staging tables.
If you use the Oracle Data Integrator tool to load your extracted data into the data collections staging tables, a collection cycle identifier is created for each load session. Each record loaded into the staging table during the load session will include the collection cycle identifier for that session.
If you populate the data collection staging tables using a method other than the Oracle Data Integrator tool, you must follow these steps to populate the collection cycle identifier.
Groupid is to be populated in column refresh_number of each data collections staging table. In one cycle of loading data into the staging tables, the column should be populated with same value. Get the group id value as follows:
SELECT ....NEXTVAL FROM DUAL;
After a cycle loading data into the data collections staging tables, insert a row as follows into table msc_cycle_status for that cycle as follows:
INSERT INTO MSC_COLL_CYCLE_STATUS
(INSTANCE_CODE, INSTANCE_ID, REFRESH_NUMBER, PROC_PHASE, STATUS, COLLECTION_CHANNEL, COLLECTION_MODE, CREATED_BY, CREATION_DATE, LAST_UPDATED_BY, LAST_UPDATE_DATE)
SELECT a.instance_code, a.instance_id, :b1, 'DONE', 'NORMAL',
'LOAD_INTERFACE', 'OTHER', 'USER', SYSTIMESTAMP, USER, SYSTIMESTAMP
FROM msc_apps_instances a
WHERE a.instance_code= :b2 ;
:b1 is instance_code for which data is loaded
:b2 is the groupid value populated in column refresh_number in all interface tables for this cycle
When you collect calendars and net resource availability from external source systems, you decide whether to collect patterns or individual dates. Order promising requires individual calendar dates and individual resource availability dates to be stored in the order orchestration and planning data repository. If you collect calendar patterns or resource shift patterns, you must invoke processes to populate the order orchestration and planning data repository with the individual dates used by order promising.
You invoke the necessary processes by specifying the applicable parameters when you run data collections. The processes generate the individual dates by using the collected patterns as input. The processes then populate the order orchestration and planning data repository with the individual calendar dates and the individual resource availability dates.
When you collect calendars from external source systems, you decide whether to collect calendar patterns or individual calendar dates. Both methods for collecting data from external source systems, Web service upload and staging tables upload, include choosing whether individual calendar dates must be generated as follows:
The Web service to upload to calendars includes a parameter to run the Generate Calendar Dates process.
You control whether the process will run. If the parameter is set to yes, then after the Web service upload completes, the process will be launched to generate and store individual calendar dates.
The parameters for the Perform Data Load from Staging Tables process also include a parameter to run the Generate Calendar Dates process.
You control whether the process will run. If the parameter is set to yes, then after the load from staging tables completes, the process will be launched to generate and store individual calendar dates.
In both scenarios, calendar data is not available while the Generate Calendar Dates process is running.
When you collect calendars from the Oracle Fusion system, the Generate Calendar Dates process is run automatically.
Restriction
Only calendar strings that are exactly equal to seven days are allowed. Calendar strings with lengths other than seven are not collected. Only calendars with Cycle = 7 should be used.
When you collect net resource availability from external source systems, you decide whether to collect resource shift patterns or individual resource availability dates. Both methods for collecting data from external source systems, Web service upload and staging tables upload, include specifying whether individual resource availability dates must be generated as follows:
The Web service to upload to net resource availability includes a parameter to run the Generate Resource Availability process.
You control whether the process will run. If the parameter is set to Yes, then after the Web service upload completes, the process will be launched to generate and store individual resource availability dates.
The parameters for the Perform Data Load from Staging Tables process also include a parameter to run the Generate Resource Availability process.
You control whether the process will run. If the parameter is set to Yes, then after the load from staging tables completes, the process will be launched to generate and store individual resource availability dates.
In both scenarios, new resource availability data is not available while the Generate Resource Availability process is running.
You cannot collect net resource availability from the Oracle Fusion source system.
To perform a targeted data collection from the Oracle Fusion system, you use the Perform Data Collection process. When you invoke the process, you provide values for the parameters used by the process.
When you perform a targeted collection, you specify the Oracle Fusion source system to be collected from and the organization collection group to collect for. When you invoke the process, the parameters also include each of the fourteen entities you can collect from the Oracle Fusion source system with yes or no for the parameter options. The table below explains the other two parameters.
|
Parameter Name |
Parameter Options |
|---|---|
|
Source System |
The source system presented for selection is determined by what system has been defined as the Oracle Fusion source system when the manage source systems task was performed. |
|
Organization Collection Group |
The organization collection groups presented for selection are determined by what organization groups were defined when the manage source systems task was performed for the selected source system. |
The parameters presented also include a yes-or-no parameter for each of the entities you can collect. If you select yes for all of the entities, the data collections will be performed in the sequence necessary to avoid errors caused by data references from one entity being loaded to another entity being loaded.
Important
If you do not select yes for all of your entities, you need to plan your load sequences to avoid errors that could occur because one of the entities being loaded is referring to data in another entity not yet loaded. For more information, see the articles regarding order promising or data collections on My Oracle Support at https://support.oracle.com.
When you perform a targeted collection from the Oracle Fusion source system, you use an organization collection group to contain the collections processing to only the organizations with data that is needed for the order orchestration and planning data repository. Organization collection groups limit targeted collections from the Oracle Fusion source system to a specific set of organizations.
You perform the following actions for organization collection groups:
Define an organization collection group.
Use an organization collection group.
You define organization groups when managing source systems for the source system where the version equals Oracle Fusion. For each organization in the organization list for the Oracle Fusion source system, you can specify an organization group. You can specify the same organization group for many organizations.
You use an organization collection group when you perform a targeted collection from the Oracle Fusion source system and you want to contain the collections processing to a specific set of organizations. You specify which organization group to collect data from by selecting from the list of organization groups defined for the Oracle Fusion source system. Data will only be collected from the organizations in the organization group you specified.
For example, if only certain distribution centers in your Oracle Fusion source system are to be considered for shipments to your customers by the order promising and order orchestration processes, you could create a DC123 organization group and assign the applicable distribution centers to the DC123 organization group when managing source systems. When you perform a targeted collection for the Oracle Fusion source system, you could select DC123 for the organization collection group.
When you manage the data collection processes, you use the Process Statistics report and the Data Collection Summary report to routinely monitor your collections. When error records are reported, you query the data staging tables for further details regarding the error records. You can also review most of your collected data using the review collected data pages.
The following information sources are available for you to monitor data collections:
Process Statistics report
Data Collection Summary report
Review collected data pages
Staging table queries
You view the Process Statistics report to monitor summary of statistic for the daily collections activity for each of your source systems. This report is available on the Actions menu when managing data collection processes for either the continuous collection publish process or the collections destination server. The day starts at 00:00 based on the time zone of the collection server.
For the Oracle Fusion source system, statistics are provided for both the continuous collection and the targeted collection data collection methods. For each external source system, statistics are provided for the Web service upload and for the staging tables upload data collection methods. The following statistics are provided in the Process Statistics report:
Number of collection cycles for the current day
Average cycle time in seconds
Average number of records
Average number of data errors
Note
The process statistics provide summary information, and are not intended for detailed analysis of the collections steps. Use the Oracle Enterprise Scheduler Service log files for detailed analysis.
You view the Data Collection Summary report to monitor statistics regarding the data collection cycles for each of your source systems. The summary report shows last the results of the last 20 cycles of all collection types. This report is available on the Action menu when managing data collection processes for the collections destination server.
The Data Collection Summary report provides information for each source system. If a source system was not subject to a data collection cycle for the period covered by the summary, an entry in the report states that there are no cycles in the cycle history for that source system. For each source system that was subject to a data collection cycle for the period covered by the summary, the following information is provided for each data collection method and collected entity value combination:
The data collection method
The collection cycle number
The entity collected and, for that entity, the number of records collected, the number of records with data errors, and collection duration
Time started
Time ended
You can review most of your collected data by using the Review Planning Collected Data page or the Review Order Orchestration Collected Data page. Both pages include a list of entities from which you select to specify the entity for which you want to review collected data. The list of entities is the same on both pages. Most of the entities listed on the review collected data pages are identical to the entities you select from when you run collections, but there are a few differences.
Some of the entities on the list of entities you select from when you review collected data are a combination or a decomposition of the entities you select from when you run collections. For example, the Currencies data collection entity is decomposed into the Currencies entity and the Currency Conversions entity on the review collected data pages. For another example, the Supplies entity on the review collected data pages is a combination of data collection entities including the On Hand entity and the Purchase Orders and Requisitions entity.
A few of the data collection entities cannot be reviewed from the review collected data pages. The data collection entities that are not available for review on the review collected data pages are Resources, Resource Availability, Routings, Work-in-Process Resource Requirements, and Customer Item Relationships.
If errors or warnings have been encountered during data collections, you can submit queries against the staging tables to examine the applicable records. For more information regarding the staging tables and staging table columns, see the articles regarding order promising or data collections on My Oracle Support at https://support.oracle.com.
When you are collecting data from external source systems, the data collection processes perform many data validation checks. If the data validations fail with errors or warnings, the steps taken by the data collection processes vary slightly depending upon whether the Web service upload data collection method or the staging tables upload data collection method is used.
In both cases, records where errors are found are not loaded into the order orchestration and planning data repository. Instead records are loaded into, or remain in, the applicable staging tables with an appropriate error message. Records where only warnings are found are loaded to the data repository, and records are loaded into, or remain in, the applicable staging tables with an appropriate warning message.
The handling of errors and warnings encountered when the data collection processes validate data during collections from external source systems depends upon which data collection method is used, Web service upload or staging tables upload.
When you are running data collections using the Web services method, the following error and warning handling steps occur:
Errors: Records are loaded to the applicable staging tables instead of the data repository and are marked with the appropriate error message.
A record with an error due to mandatory missing mandatory fields, such as organization or supplier or item, is first marked as retry. After several unsuccessful retry attempts, the record will be marked as error.
Warnings: Records are loaded into the data repository and into the applicable staging tables with the appropriate warning message.
When you are running data collections using the staging tables upload method, the following error and warning handling steps occur:
Errors: Records remain in the staging tables without being loaded to the data repository and are marked with the appropriate error message.
A record with an error due to mandatory missing mandatory fields, such as organization or supplier or item, is first marked as retry. After several unsuccessful retry attempts, the record will be marked as error.
Warnings: Records are loaded into the data repository and remain in the staging tables with the appropriate warning message.
When a Planned Order Supplies record is collected, many validations occur for which an error is recorded if the validation fails.
For example, the supplier name is validated against the suppliers data in the order orchestration and planning data repository. If the supplier name is not found, the validation fails with an error condition, and the following steps occur:
The Planned Order Supplies record is not loaded into the data repository.
The Planned Order Supplies record is loaded into the applicable staging table, or remains in the applicable staging table, with an error message stating invalid supplier or invalid supplier site.
When a Planned Order Supplies record is collected, many validations occur for which a warning is recorded if the validation fails.
For example, the Firm-Planned-Type value in the record is validated to verify that the value is either 1 for firm or 2 for not firm. If the validation fails, the failure is handled as a warning, and the following steps occur:
The Planned Order Supplies record is loaded into the data repository with the Firm-Planned-Type value defaulted to 2 for not firm.
The Planned Order Supplies record is also loaded into the applicable staging table, or remains in the applicable staging table, with a warning message stating invalid firm planned type.
You use the Purge Data Repository Tables process to delete all collected data from the order orchestration and planning data repository that was collected from a specific source system. You use the Purge Staging Tables process to remove data that you no longer need in the data collections staging tables.
You use the Purge Data Repository process to delete all data for a source system from the order orchestration and planning data repository. The process enables you to delete data for a specific source system. You typically use the Purge Data Repository process when one of your source systems becomes obsolete, or when you decide to do a complete data refresh for a set of collection entities.
The Purge Data Repository process has only two parameters, both of which are mandatory. This table explains the two parameters.
|
Parameter Name |
Parameter Options |
|---|---|
|
Source System |
Select a source system for the list of source systems. All data for the selected system will be deleted from the data repository. |
|
Purge Global Entities |
Yes or No If you select yes, in addition to the applicable data being deleted for the source-specific entities, all data from global entities will also be deleted. If you select no, data will be deleted from the source-specific entities only. |
You use the Purge Staging Tables process to delete data from the data collection staging tables.
The following table explains the parameters you specify when you run the Purge Staging Tables process. In addition to the five parameters explained below, you specify yes or no for each of the twenty-five data collection entities.
|
Parameter Name |
Parameter Options |
|---|---|
|
Source System |
Select a source system for the list of source systems. Data will be deleted for this source system only. |
|
Record Type |
The record type specifies which type of records to purge as follows:
|
|
Collection Cycle ID |
Specify a value for the collection cycle identifier to purge data for a specific collection cycle only, or leave blank. |
|
From Date Collected |
Specify a date to purge data from that date only, or leave blank. |
|
To Date Collected |
Specify a date to purge data up to that date only, or leave blank. |
One of the objects in the set of objects used by the orchestration processes to determine the meaning and descriptions for names or codes, such as payment terms names, freight-on-board codes, and mode-of-transport codes.
The sales order data passed to the orchestration processes contains the names or codes, but the processes need to display the meanings or descriptions. The data to determine the meanings or descriptions for the names or codes must be collected into the order orchestration and planning data repository.
For example, sales order information is passed to the Order Orchestration processes containing a freight-on-board code equal to 65, and the order orchestration and planning data repository contains a record with freight-on-board code equal to 65. The processes use the matching codes to determine that the freight-on-board code meaning is equal to Origin, and the description is equal to Vendors responsibility.
Tip
For the full list of order orchestration reference objects, review collected data for the order orchestration reference objects, and view the list of values for the Lookup Type field.
Oracle Fusion Distributed Order Orchestration automates order orchestration across fulfillment systems using highly adaptable, flexible business processes. The following setups are required for orchestration:
Task type: Mechanism used to group fulfillment tasks together. Each task type contains a selection of services that communicate with a specific type of fulfillment system, for example, a billing system.
Orchestration process definition: Business process required to fulfill a fulfillment line. It includes the sequence of task layer service calls, as well as planning details, change management parameters, and status conditions.
Change logic: Set of rules that control how changes to booked orders are handled by the orchestration process.
Process planning: Schedule that shows the completion date of each task and of the orchestration process itself.
Jeopardy threshold and priority: Mechanism for indicating late-running tasks at runtime.
Statuses and status conditions: Indicators of the statuses of order and process objects, including task, orchestration process, fulfillment line, orchestration order line, and orchestration order. Status conditions are the rules that determine when any of these order and process objects reaches a particular status.
The external interface layer is the functional component within Oracle Fusion Distributed Order Orchestration that manages the communication between Distributed Order Orchestration and external fulfillment systems. Its primary functions are routing the fulfillment request and transforming the data.
The external interface layer enables loose coupling between Distributed Order Orchestration and fulfillment systems:
Abstracts external systems from the orchestration process definition to minimize changes when adding new order capture or fulfillment systems.
Provides an extensible, SOA-enabled framework for flexible integration to external applications.
Provides a complete, open, and integrated solution that lowers total cost of ownership.
When the setup is done, Distributed Order Orchestration can connect to any fulfillment system.
Some setup is required to use the template task layer. Some of these setup activities are mandatory because processing cannot occur without the setup information. Other setup activities are optional and will depend on the desired behavior of the services that are associated with the new task type that you are creating. You may set up as many different uses of the template task layer as you need.
The following setup steps are mandatory:
Create a custom task type.
Assign status codes to the task type.
Create the connector.
Register the connector Web service.
Use the task type in orchestration process definitions.
Create a custom task type on the Manage Task Types page. When you create a custom task type, two services are created, one that corresponds to the Create (outbound) operation code and the other that corresponds to the Inbound operation code. You can specify names for these two services, and you can add services that correspond to the other available operation codes (Cancel, Change, Get Status, Apply Hold, and Release Hold). Create at least one task for each new task type.
Assign status codes to each custom task type. A few system status codes are defaulted, for example, Canceled, Change Pending, Cancel and Pending. The status codes that are associated with each task type also control the values for exit criteria for wait steps that use this task type and for the value of the next expected task status in the orchestration process step definition. You can create new status codes, or you can assign existing status codes to the new custom task type.
Create the connector that integrates Distributed Order Orchestration with the fulfillment system that will perform the tasks and services of the new task type.
Register the Web service that is required for integration to the fulfillment system that will perform the tasks and services of the new task type.
You use the new task type and the tasks and services within it by building them into an orchestration process definition, just as you would with the predefined task types, tasks and services. Because splits are allowed for these services, the services may be used only in one branch that is then defined as the single branch that allows services that can be split.
Some setup is required to use the template task layer. Some of these setup activities are mandatory because processing cannot occur without the setup information. Other setup activities are optional and will depend on the desired behavior of the services that are associated with the new task type that you are creating. You may set up as many different uses of the template task layer as you need.
The following setups are optional:
Preprocessing service: You can add preprocessing logic to the actions built into the template task layer service. Your organization might want to add preprocessing logic that defaults data onto the outbound request or validates it.
Postprocessing service: You can add postprocessing logic to the actions that are built into the template task layer service. Your organization might want to add postprocessing logic that defaults logic onto the inbound request, validates the inbound request, or interprets any attributes or messages that are returned by the fulfillment system that might indicate the need for split processing.
Change management: If you want change management processing for orchestration process steps that use one of these task types, then specify the attributes for the task type on the Manage Order Attributes That Identify Change pages. You also need to be sure there are Update and Cancel services and their associated connectors.
Define hold codes: If you want to apply holds to the new services, then create hold codes for them. Hold All applies to the new services, as well as to the existing ones.
Define jeopardy thresholds: If you want to compute specific jeopardy scores on the new custom tasks, then define jeopardy thresholds for them.
Define processing constraints: If you know of some circumstances under which a new custom task should not be called, then define processing constraints to control the behavior.
Define preprocessing validation of mandatory attributes: You may want to use processing constraints to declare which attributes in the outbound request payload are mandatory.
Define postprocessing validation of mandatory attributes: You may want to use processing constraints to declare which attributes in the inbound response payload are mandatory.
Define data set used as part of outbound request: By default, the template task layer uses a complete data structure to communicate Oracle Fusion Distributed Order Orchestration attributes between GetValidFLineData, the preprocessing service, and the external interface layer routing rules. You can trim the data set to a functionally appropriate size to make processing more efficient.
Register error messages: If your external fulfillment systems send Distributed Order Orchestration error messages that you want to process and display in the Distributed Order Orchestration messaging framework, then you must register these messages.
A sales representative may add attachments while creating a sales order. An attachment might be a document with requirements for manufacturing, a memo for price negotiation, or a URL for product assembling instructions, to name just a few possibilities. Oracle Fusion Distributed Order Orchestration accepts the attachments as part of the sales order. You can view attachments in the Order Orchestration work area and subsequently send them to the necessary fulfillment system. Attachments cannot be sent from the fulfillment system to Distributed Order Orchestration or from Distributed Order Orchestration to an order capture system.
Sales order attachments can be transmitted from the order capture system to Oracle Fusion Distributed Order Orchestration and from Distributed Order Orchestration to fulfillment systems. To enable transmission of sales order attachments to Distributed Order Orchestration, you must collect the document category during orchestration data collection. To enable transmission from Distributed Order Orchestration, you must invoke the AttachmentsAM public service. Use this service to select and send attachments to the designated fulfillment system, based on the type of the fulfillment request and the category of the attachment.
Web services are used to integrate fulfillment applications with Oracle Fusion Distributed Order Orchestration. Distributed Order Orchestration has a Web service broker that routes requests from the fulfillment task layer to one or more fulfillment systems and vice versa. The following explains how Web services are set up.
Create the connector.
Deploy the connector.
Register the connector.
Create external interface routing rules.
Define an XSLT transformation file to transform the Distributed Order Orchestration fulfilment task message to a Web service-specific message. You can use the Oracle JDeveloper mapper tool or any other tool of choice. Similarly, define the XSLT transformation file to transform the response from the Web service to a message specific to Distributed Order Orchestration.
Make a copy of the connector template, and replace the XSLT transformation files with the files you created for the connector.
Register the connector on the Manage Web Services page. You must create the source system, so that it is available for selection from this page.
Create external interface routing rules on the Manage External Interface Routing Rules page. These are the business rules that determine to which fulfillment system requests are routed.
The user credential key is a user and password combination created in the credential stores, or Oracle Wallet Manager. This key provides for secure authenticated communication between Oracle Fusion Distributed Order Orchestration and fulfillment systems. You must create a user credential key to integrate Oracle Fusion Distributed Order Orchestration with external services.
Follow the instructions for adding a key to a credential map in the Oracle Fusion Middleware Security Guide 11g Release 1 (11.1.1). You must have the administration privilege and administrator role. In the Select Map list, select oracle.wsm.security. Enter the key, user name, and password from the service that is being integrated with Oracle Fusion Distributed Order Orchestration. Register the user credential key on the Manage Web Service Details page of Distributed Order Orchestration.
To invoke external Web services from Oracle Fusion Distributed Order Orchestration, you must ensure that the user credential is valid in the target system and the security certificate to encrypt and decrypt messages.
Obtain a user credential key, and add it to the invoking server's identity store.
A user credential is a user name and password defined in the target system and is used for authenticating incoming requests. This means that the consumer of the service must pass in these credentials as part of the request.
Ask the service provider for the user credentials to be used when invoking their service. The IT administrator must add the user credentials provided by the service provider to the service consumer's server and provide a reference, which is called a CSF-KEY.
Register the external system in the Manage Source System Entities flow. For each service hosted on the external system that you plan to interact with, register the service on the Manage Web Service Details page. Provide a name (Connector Name) for the service, the physical location (URL) of the service; and the CSF-KEY pointing to the user credential that will be used when interacting with the external service. This key applies to all services offered by the target system.
Oracle recommends that you configure servers that are running external Web services that must be invoked to advertise the security certificate in the WSDL. The default setting in Oracle WebLogic Server is to advertise the security certificates. Check whether your servers support this feature; if so, then enable the feature.
If you cannot set up the server this way, then use the keystore recipient alias. Ask the service provider for the security certificate. An IT administrator imports the target server security certificate into the invoking server and provides a reference, which is called a keystore recipient alias. Add this alias to the external service entry that was created when you specified the user credential. Register this keystore recipient alias on the Manage Web Service Details page against the records created for that system. This key applies to all services offered by the target system.
If the other options do not work, then configure the target servers to use the Oracle security certificate. Import this certificate into your target servers. No setup is required on the invoking server for the security certificate.
Use external interface routing rules to determine to which fulfillment system a fulfillment request must be routed. You can use order, fulfillment line, and process definition attributes to select the fulfillment system connectors. The rules are executed in Oracle Business Rules engine.
Use these scenarios to understand how to use external interface routing rules.
You want orchestration orders that are ready to be shipped to go to the shipping fulfillment system. You write an external interface routing rule that requires that if the task type code of an orchestration order is Shipment, then route the request to the ABCShippingSystem connector.
Your company has two invoicing systems. When it is time to send out an invoice, you want Widget Company always to be invoiced by system ABC. You write an external interface routing rule that requires that if the customer is Widget Company and the task type code is Invoice, then route the request to ABCInvoicingSystem.
An orchestration process is a process flow that approximates your organization's fulfillment process. An orchestration process contains a sequence of steps that takes a fulfillment line through the fulfillment process. An orchestration process contains the instructions for how to process an order, such as which steps and services to use, step dependencies, conditional branching, lead-time information, how to handle change orders, which status values to use, and more. You define orchestration processes according to your organization's needs. You create rules, so that at run time the appropriate orchestration process is automatically created and assigned to the new fulfillment lines.
If you want to use the ShipOrderGenericProcess and ReturnOrderGenericProcess predefined orchestration processes, then you must generate them and deploy them; it is not necessary to release them.
Orchestration process definitions include the sequence of task layer service calls, as well as planning details, change management parameters, and status conditions. Use the following examples to understand how you can use orchestration process definitions to model your business processes.
You are an order administrator at a company that sells widgets. You list the logical steps that are required to fulfill an order. Then you create an orchestration process that mirrors your business process.
The first steps are:
Step 1: Plant Acknowledgement
Step 2: Assemble
Step 3: Wait for Assemble COMPLETE
Step 4: Ship
Step 5: Wait for SHIPPED
(Statuses are represented in all uppercase letters.)
Your company requires that a representative call the customer when an invoice exceeds $100,000. You continue creating the orchestration process by adding a conditional step (which is not a task layer service call):
Step 6: Conditional node where the orchestration process branches
Afterwards, the steps continue as follows:
Step 7: Call Customer
Step 8: Wait for Call Customer COMPLETE
Step 9: Send High Value Invoice
Step 10: Wait for High Value Invoice BILLED
Otherwise, the steps are:
Step 7: Invoice
Step 8: Wait for BILLED
A merge node ends the branch.
You are an order administrator at a company that sells carpet. Your company has established lead times that enable representatives to monitor the fulfillment process and determine when orders will be fulfilled.
Schedule: 2 days
Reservation: 1 day
Shipment: 6 days
Invoice: 2 days
You create an orchestration process that contains this information by adding the default lead time to each orchestration process step. When a step is delayed, a background process automatically triggers replanning and expected completion dates are reset.
You are an order administrator at a company that sells carpet. You have an important customer who requires that you notify the receiving clerk one day before the carpet is shipped. You create an orchestration process for this customer's orders. You use the Carpet Process orchestration process class, which contains the statuses: SHIPPED, RESERVED, READY TO SHIP, SHIPPED, INVOICED. On the Orchestration Process Status tab, you create status conditions for the orchestration process for the special customer, such as: If the status of the CreateShipment step is PRESHIP READY, then use the READY TO SHIP status to represent the status of the orchestration process. Now, the order manager can see in the Order Orchestration work area when the orchestration process status is READY TO SHIP.
A task type is a grouping of services that perform fulfillment tasks. Task types represent common business functions that are required to process an order from its receipt from the order capture application to its execution in the fulfillment application. The following task types are provided by default: Schedule, Reservation, Shipment, Activity, Invoice, Return. You can create additional task types by using the Custom and Activity task types. Task types are made up of services and tasks. Service refers to an internal Web service that communicates with the task layer. A task is a representation of the services of a task type. Tasks and services are the building blocks of an orchestration process.
Seeded task types are read-only. You cannot delete task types. You can change the names of task types you create, but it is not recommended.
You can edit the service names of the Activity and Custom task types. You can add services from the pool of available services, but you cannot edit or delete services for custom task types.
Use tasks to represent the services that belong to a task type. For example, you can define a Ship Goods task to represent services from the Shipment task type. When one of the Shipment services is running, Ship Goods appears in the Order Orchestration work area, regardless of whether the Create Shipment or Update Shipment service is called; the services do not appear in the Order Orchestration work area. You can define several tasks for a task type to represent your real-world user tasks, such as ShipGoods or ShipWidgets. Both tasks and services appear in the orchestration process definition.
Task type management is the registration of internal service references for the task layer.
During fulfillment of an order, changes can originate from a variety of sources, such as from the customer through the order capture application or by the order manager in the Order Orchestration work area. Oracle Fusion Distributed Order Orchestration processes changes automatically, but you can influence some aspects of change processing through some of the setup options.
Change processing occurs according to certain settings. The following parameters are set at the orchestration process level:
Order attributes that identify change: Attributes that, when changed, require compensation of the orchestration process. Changes to certain attributes do not always require compensation of the orchestration process. For example, an addition of a suite number to a customer's address might not require adjustments to the orchestration process. You can refine how a change is processed for one of these attributes through compensation patterns for orchestration process steps.
Processing constraints: Rules that control attempted changes to an order, for example, what can be changed, when, and by whom. Changes that are forbidden by processing constraints are disallowed, and an error message appears.
Change mode: Setting that determines how frequently state snapshots are taken during an orchestration process. Snapshots are compared during compensation of the orchestration process. For example, if you select Simple, then only the beginning and end states are compared. If you select None, then all changes to the orchestration process are rejected.
Cost of change rule: Rule that specifies the costs to the business due to a requested change.
The following parameters are set at the orchestration process step level:
Hold on wait: Directs the runtime engine to request a hold in an external system for a wait service task.
Use dynamic attributes: Indicates whether the product-specific dynamic attributes need to be considered for change.
Use flexfield attributes: Indicates whether flexfield attributes need to be considered for change.
Compensation pattern: Rule that specifies the adjustments to make when an order is changed. For example, if Distributed Order Orchestration receives a change order with a new warehouse for the Create Shipment step, then Distributed Order Orchestration runs the Cancel service and Create service again. If a compensation pattern is not designated for a process step, then the default compensation pattern is used, which is to run the Update service (or the Cancel and Create services).
When a change order is received from an order capture system, Distributed Order Orchestration performs a lookup to determine whether the order key has been received before. Distributed Order Orchestration sends a request to the fulfillment system that is responsible for the task that was running when the change order was received. The request has several components: Hold current processing, designate whether a change can be accepted, and send the current status.
Change orders are decomposed and orchestrated in the same manner as new orders. If rules were set up for special processing of change orders, then the rules are applied at this time.
Distributed Order Orchestration checks for header-level processing constraints that prevent change processing. If change processing is allowed, then the delta service is called. The delta service checks the attributes that indicate whether the change must be compensated. If the change requires compensation, then compensation begins after line-level attributes are checked.
Distributed Order Orchestration checks line-level processing constraints. If constraints are violated for even one fulfillment line, then the entire change order is rejected.
When an action on the Order Orchestration work area requires change processing, all the above actions occur except decomposition. After the changes are identified by the delta service, Distributed Order Orchestration analyzes and compensates the process, step-by-step, analyzing the state of each step to determine what processing changes are needed to incorporate the changes to the order. To determine the steps to compensate, Distributed Order Orchestration uses the process step state snapshots taken at each task layer service invocation while the orchestration process was running.
The process delta service identifies all orchestration process steps that are associated with delta attributes. You can opt for the default behavior (context-based undo or update) or specify a business rule that determines the appropriate action as the compensation pattern for each process step. Distributed Order Orchestration evaluates the compensation pattern identified for the step to identify what processing to run in a change scenario. Compensation patterns include undo, redo, update, cancel, and none. The default compensation sequence is first in, first out, based on the orchestration process sequence. If the entire order is canceled, then a last in, first out sequence is used. After the compensating services are completed, processing continues using the original orchestration process specification or the appropriate orchestration process dictated by the changes is started. Expected dates are replanned, unless the entire order is canceled. At this point, change processing is completed.
Order attributes that identify change are attributes that, when changed by the order capture application or Order Orchestration work area user, require compensation of an orchestration process step. A change to any one of these attributes requires compensation of a step if the attribute is assigned to the task type associated with the step. For example, if the quantity of a sales order is increased, then additional supply must be scheduled and shipped. The Schedule and Shipment steps of the orchestration process are affected because the quantity is an attribute assigned to those task types.
Select an attribute from the list of entities: Fulfillment line, orchestration order line, or orchestration order. Selection of this attribute means that at run time, when a change order is received, the application searches for this attribute on the entity that you associated it with to determine whether it is was changed on the change order. For example, if you select Scheduled Ship Date on the orchestration order line, then when a change order is received, the application compares the Scheduled Ship Date attribute on the line of the change order with the Scheduled Ship Date attribute of the most recent version of the orchestration order line.
By default, the application searches for a set of attributes, which are indicated by selected check boxes. You cannot deselect them; you can only add more attributes.
If you want flexfield attributes or dynamic attributes associated with specific products to be considered for change, then select Use Flexfield Attributes and Use Dynamic Attributes on the orchestration process definition. You cannot select these attributes individually.
The task type selection defines the attributes that will be used to evaluate whether a step using that task type requires compensation. Attributes are predefined for predefined task types, but additional attributes can be added. When you add a new task type, no attributes are defaulted. The task is not evaluated to determine compensation requirements unless you set up these attributes first.
Click Add All to add attributes to all existing task types.
Status denotes the progress of an order from beginning to completion. The status of an orchestration order is determined by the status of its fulfilment lines, orchestration processes, and tasks. Status values appear in the Order Orchestration work area, where order managers can use them to quickly understand the progress of an orchestration order or its components.
You create a list of all the statuses that can be used in Oracle Fusion Distributed Order Orchestration. For each status code, you create a display name, which is how the status will appear in the Order Orchestration work area. Then, using the list of defined statuses, create a separate list of statuses that an administrator is allowed to use for each of the following: Fulfillment lines, task types, and orchestration processes. When administrators create status conditions for orchestration processes, they can choose from these status values only. You must define the status values in the Manage Status Values page to make them available for selection when creating status conditions.
During processing of a fulfillment line, the tasks of the assigned orchestration process are fulfilled step by step. You can determine the status that will be assigned to a fulfillment line at each stage of the process. For example, you can indicate that if a Schedule Carpet Installation task has a status of Pending Scheduling, then the fulfillment line status will be Unscheduled.
You can designate the statuses that represent a fulfillment line when you define an orchestration process. These statuses are used to represent the status of the fulfillment line throughout the application. You create a status rule set that lists a sequence of the statuses that will be attained during the orchestration process and the conditions under which they are assigned to the fulfillment line. For example, you could designate the status Scheduled to be used for the fulfillment line when the Schedule Carpet task reaches a status of Completed.
At run time, the application evaluates each of the status conditions sequentially. The true condition with the highest sequence number determines the status of the fulfillment line.
When an orchestration process splits, two or more instances of the same task result. Split priority is a ranking that is used to evaluate multiple instances of a task that splits. The ranking determines which task status represents the status of the orchestration process. A lower number corresponds to a higher rank. The status with the lower number is used to represent the status of the orchestration process.
For example, an orchestration process splits and results in two instances of the Schedule task. One Schedule task has a status of complete, and the other has a status of pending. Because pending has a split priority of two and complete has a split priority of three, pending is used to represent the status of the orchestration process.
An orchestration order can have one or more orchestration order lines, each in its own status. The status of the orchestration order is based on the orchestration order lines that are mapped to it
The following table shows how the orchestration order status is determined, given the statuses of the associated orchestration order lines.
|
Orchestration Order Line Statuses |
Orchestration Order Status |
|---|---|
|
All orchestration order lines are completed. |
Closed |
|
All orchestration order lines are not completed. |
Open |
|
Some, but not all, orchestration order lines are completed. |
Partial |
|
All orchestration order lines are canceled. |
Canceled |
|
Some orchestration order lines are canceled. |
Ignore canceled orchestration order lines, and determine status based on the open orchestration order lines. |
For example, if no orchestration order lines are completed, then the orchestration order status is open.
An orchestration order line can have one or more fulfillment lines, each with its own status. The status of the orchestration order line is based on the fulfillment lines that are mapped to it.
The following table shows how the orchestration order line status is determined, given the statuses of the associated fulfillment lines.
|
Fulfillment Line Statuses |
Orchestration Order Line Status |
|---|---|
|
All fulfillment lines are completed. |
Closed |
|
All fulfillment lines are not completed. |
Open |
|
Some, but not all, fulfillment lines are completed. |
Partial |
|
All fulfillment lines are canceled. |
Canceled |
|
Some fulfillment lines are canceled. |
Ignore canceled fulfillment lines, and determine status based on the open fulfillment lines. |
Jeopardy priority indicates the level of risk associated with the delay of a task of an orchestration process. It appears in the Order Orchestration work area as Low, Medium, and High.
Create a jeopardy priority by mapping a jeopardy score range to one of the three severity levels. For example, you could map the jeopardy priority Low to a minimum jeopardy score of 0 and a maximum jeopardy score of 100. Jeopardy priorities are provided by default. You can change the values in the ranges to meet your business needs. You cannot delete or add priorities, or change jeopardy priority names; only Low, Medium, and High are available.
Jeopardy score is a numerical ranking associated with a delay in the completion of a task of an orchestration process. Jeopardy score indicates how severe a delay is deemed. The jeopardy score is mapped to jeopardy priorities of Low, Medium, and High, which appear in the Order Orchestration work area. The indicator provides a quick visual cue to order managers, so that they can take appropriate action to mitigate a delay.
You determine jeopardy score when you create jeopardy thresholds.
Jeopardy score is assigned to tasks based on jeopardy thresholds. When a task is delayed, the difference between the required completion date and the planned completion date is calculated. Then the application searches for a threshold that applies to the most number of entities of the task. It searches for a threshold in the following order:
Combination of all four elements: Process name, process version, task name, and task type.
Process name, process version, and task name.
Process name and task name.
Process name, process version, and task type.
Process name and task type.
Task name.
Process name and process version.
Process name.
For task type.
For null keys.
The application searches for a threshold that applies to all four entities of the task: Task type, task name, process name, and process version. If a threshold for that combination is not found, then the application searches for a threshold that applies to the process name, process version, and task name of the task, and so on. After an appropriate threshold is located, the score dictated by the threshold is assigned to the task.
The jeopardy priority that appears in the Order Orchestration work area maps back to the task with the highest jeopardy score. In other words, if multiple tasks are in jeopardy within an orchestration process, then the highest jeopardy score is used to represent the jeopardy of the orchestration process. For example, in an orchestration process called Carpet Processing, insufficient supply in the warehouse causes several tasks to be delayed, including the Deliver Carpet task and the Invoice Carpet task. A three-day delay to the Deliver Carpet task maps to a jeopardy score of 100 and a jeopardy priority of Medium; a three-day delay to the Invoice Carpet task carries a jeopardy score of 200 and a jeopardy priority of High. Two hundred is the higher score, so this task's jeopardy score is used to represent the jeopardy of the Carpet Processing orchestration process. In the Order Orchestration work area, this orchestration process displays a jeopardy priority of High.
Fulfillment tasks have predefined status codes. You can choose to display different status codes from the predefined ones by mapping the predefined status codes to your preferred status codes. The status codes that you change them to appear in the Order Orchestration work area and in other status management areas, as well, such as the Status Conditions tab of an orchestration process definition.
Jeopardy thresholds are used to monitor and measure orchestration processes. Jeopardy thresholds are ranges of time that a task is delayed. You define a set of ranges for each task of an orchestration process and then assign a score that indicates the severity of the delay. These setups are used to create indicators that appear on the Order Orchestration work area. These indicators help order managers to quickly see the severity of a delay, enabling them to take appropriate action.
When an orchestration process is assigned to an orchestration order, the process is planned taking into account the lead time of steps in the orchestration process and certain key dates from the sales order, such as required completion date. Each task of the process has a planned start and completion date. When a task of the orchestration process is delayed, the whole process is replanned. When a task in the process is expected to be completed after the required completion date of the task, a jeopardy score is automatically assigned to each task based on the jeopardy thresholds you define.
You can define jeopardy thresholds for any combination of the following:
Task type
Task name
Process name
Process version
You are not required to choose any of the above options. If you leave them at their default setting of All, then the jeopardy threshold applies to all tasks.
If you want to apply the threshold to a task or orchestration process, then orchestration processes, tasks, and task types must be defined so that you can select them when creating jeopardy thresholds.
Orchestration process definitions contain the information that is used to create an orchestration process at run time. When defining an orchestration process, your choices affect how a fulfillment line is processed to completion.
Oracle Fusion Distributed Order Orchestration provides the following predefined orchestration processes:
Ship order
Return order
The Ship Order orchestration process contains the following sequential tasks:
Schedule
Reservation
Shipment
Invoice
The Return Order orchestration process contains the following sequential tasks:
Return Receipt
Invoice
Before you define an orchestration process, perform the following prerequisite tasks:
Execute mandatory tasks in Functional Setup Manager.
Define any additional task types and their associated tasks and services.
Define any additional status codes and how they will be used for task types, fulfillment lines, and orchestration processes.
Define any subprocesses that will be used in the process to be defined.
Define status catalogs that will be used for status conditions. Define the catalogs in Oracle Fusion Product Model, Oracle Fusion Product and Catalog Management, or Oracle Fusion Product Hub.
The header contains basic information that applies to the entire orchestration process. During step definition, you will determine the information that applies to individual steps.
Orchestration process class: This value is required. It is a set of statuses that can be used for this orchestration process.
Change mode: When a change order enters the system, the delta service analyzes the state of each step to determine what processing changes are needed. After this analysis, compensation occurs on the necessary steps. Your selection determines how often snapshots of the orchestration process are taken.
None: Snapshot of the orchestration process is not taken, and change is not allowed.
Simple: Snapshot is taken when orchestration process starts and at step where change order is received.
Advanced: Snapshots are taken at each orchestration process step.
Caution
If you used the Functional Setup Manager migration tool to port test instance data to a production environment, then do not change the process name in either instance. Changing the name could prevent references to other data in the orchestration process from being updated.
An orchestration process class is a set of statuses that can be used for an orchestration process. Use orchestration process classes to simplify orchestration process definition. You can assign the complete set of statuses to any number of orchestration process definitions without having to list the statuses one by one. You do not have to use all the status values in the orchestration process class.
When an orchestration process class is assigned to an orchestration process, you can use the only the statuses in that class. The status values that are defined in the orchestration process class are only for the statuses at the orchestration process level, not for the tasks or fulfillment lines.
Your organization might need for different fulfillment lines within the same orchestration process to have different status progressions. For example, a model with shippable fulfillment lines and nonshippable fulfillment lines may require different statuses for each type of fulfillment line. A status catalog provides a means to group like items, so that they can achieve the same statuses at the same time. Status catalogs are defined in Oracle Fusion Product Model.
Cost of change is a numerical value that represents the impact of a change to an orchestration process. Cost could be the monetary cost to a company or the difficulty associated with the change. This value is calculated and returned to the order capture application, so that the customer service representative can understand how costly it is to make the customer's requested change. The cost of change value can be requested by the order capture application before a change order is submitted to determine whether it should be submitted. Cost of change is calculated also after compensation of a change order is completed. Cost of change is most often used in a postfactor analysis to change practices or processes, or in a business-to-business negotiation.
You assign the cost of change to the orchestration process using a business rule. When the order capture application requests a cost of change determination, the value is calculated and returned, but it is not stored. If you choose not to use cost of change values, then zero is the value used to calculate the cost of change when a change order is submitted.
This example demonstrates how to create a cost of change rule for an orchestration process, so that order managers are aware of how costly to the company certain changes are. The order administrator of a flooring company wants a few rules that indicate the cost to the company if a change is requested when the fulfillment line is at a certain status. The cost of change is low if the fulfillment line is in Scheduled status, and it is much higher if the fulfillment line is in Shipped status.
Note
The following is an example of a simple rule, which is well suited for rules for an orchestration process with a single line. If you want to write a rule for an orchestration process that has multiple lines, then use advanced mode rules. For more information, see Oracle Fusion Middleware User's Guide for Oracle Business Rules.
Create If and Then statements for the following rules:
If the fulfillment line status value is Shipped, then the cost of change is 50.
If the fulfillment line status value is Scheduled, then the cost of change is 5.
Create the If statement: If the fulfillment line status value is Shipped.
Create the Then statement: Then the cost of change is 50.
Create the If statement: If the DOO Fulfillment Line status value is Scheduled.
Create the Then statement: Then the cost of change is 5.
This example demonstrates how to create a line selection rule that determines which lines to process for a particular step in a case where not all lines should be processed by that step. The order administrator of a company that sells DVRs wants an orchestration process that handles orders for this equipment. The orchestration order is broken into several fulfillment lines for each of the following: DVR, remote control, instruction manual, and extended warranty. The extended warranty is a contract purchased online, but it is not a shippable item. Therefore, it should not be sent to the fulfillment system during the Shipment task.
Note
The following is an example of a simple rule, which is well suited for rules for an orchestration process with a single line. If you want to write a rule for an orchestration process that has multiple lines, then use advanced mode rules. For more information, see Oracle Fusion Middleware User's Guide for Oracle Business Rules.
Create the rule while defining the SetUpShipment step. To create the rule, you must construct If and Then statements.
Create the If statement: If the item is shippable.
Create the Then statement: Then select the fulfillment line.
Use branching to create a sequence of steps that are executed only under certain conditions. A branch contains one or more steps. For example, your company sells laptop computers. If a customer buys a service agreement with the laptop computer, then you create an asset, so that the computer can be tracked. If a service agreement is not purchased, then the customer is invoiced without creating an asset.
The following figure shows an orchestration process flow that models this scenario. Each step contains the step number, task name, and task type. This example includes the ManageAssets custom task type. The conditional node indicates that an orchestration process is about to branch. The first step of the branch contains the condition. If the condition is met, then the application executes the steps on the branch that includes the Create Asset and Wait for Asset steps. Otherwise, the other branch is executed, and an invoice is created without creating an asset.
You do not need to set an Otherwise condition in the orchestration process definition if you have only one branch. When the orchestration process artifacts are generated, an empty default branch is added.
This example demonstrates how to create a branching condition that determines whether to branch from the parent process to execute a branch. In this scenario, the order administrator of a flooring company wants an orchestration process for carpet orders. The company has a policy stipulating that a representative call a customer before sending an invoice over $50,000.00.
Note
The following is an example of a simple rule, which is well suited for rules for an orchestration process with a single line. If you want to write a rule for an orchestration process that has multiple lines, then use advanced mode rules. For more information, see Oracle Fusion Middleware User's Guide for Oracle Business Rules.
Create a rule on the invoicing step of the orchestration process definition. To create the rule, you must construct If and Then statements.
Create the If statement: If invoice is greater than $50,000.00
Create the Then statement: Then execute the branch.
This example assumes that an orchestration process is created that contains the steps necessary to carry out the fulfillment of a customer's order for carpet. This example begins with a Call Customer step. Ensure that the Call Customer step is the step after the conditional step.
Create the If statement: If invoice (price) is greater than $50,000.00.
Create the Then statement: Then execute the branch.
Lead time is the expected amount of time needed to complete a step. It is used to plan the orchestration process and predict expected completion dates. When real completion dates are available, they are used instead of the estimates in the orchestration process definition. The planned orchestration process appears in the Gantt chart in the Order Orchestration work area. Lead time is also used during jeopardy calculation where jeopardy is determined by considering the number of days past lead time a step is taking.
This example demonstrates how to create a lead-time rule that determines lead time for a step based on a set of conditions. The order administrator of a flooring company wants an orchestration process that handles carpet orders. The lead time for shipping the carpet is two days if the inventory organization is Houston and four days for any other inventory organization.
Note
Often, if you write a rule for an orchestration process that has multiple lines, then you should use advanced mode rules. In the following example, however, all the lines are being treated the same way, so an advanced mode rule is not required.
In this example, you create the rule while defining the Shipment step Create Shipment. Ensure that the unit of measure is days. You must create two rules, one for when the inventory organization ID is Houston, and the other for an inventory organization ID with any other value.
Note
The Shipment task has a wait step, where a lead time can be defined, too. The lead time for the task is the sum of the lead times defined for each of the steps within the task. In this example, lead time is defined only on the Create Shipment step.
Create the If statement for the first rule: If inventory organization ID is 1234440.
Create the Then statement for the first rule: Then the lead time is equal to 2.
Create the If statement for the second rule: If inventory organization ID isn't 1234440.
Create the Then statement for the second rule: Then the lead time is equal to 4.
In the same window, repeat the steps above to create a rule for the following If and Then statements. Start by clicking the New Rule icon. Substitute "isn't" for "is" in the first statement, and substitute 4 for 2 in the second statement.
You can create customized processes to manage each stage of order processing after the order is released from the order capture system. These orchestration processes include automated planning. Process planning sets user expectation of completion date of each step, task, and the orchestration process itself.
If you select Replan Instantly for an orchestration process, then the planning engine is called and the data is refreshed after each step is completed. For performance reasons, you might not want automatic replanning of some processes, especially where the step definition sequence is long or complex. Consider using this option for orchestration processes that are for high priority customer orders, or with jeopardy thresholds of less than a day. If you do not select Replan Instantly, then the planning data is refreshed during its normal, scheduled replan.
The following attributes affect step-specific planning:
Planning Default Branch: Identifies the default path for planning. This attribute is used only if the orchestration process has conditional branches.
Fulfillment Completion Step: Identifies the step at which the customer considers the lines fulfilled. This attribute is used in planning calculations to satisfy the customer request date. It is not necessarily the last step in the process definition. The chronological last step may not be last step that the customer cares about. The orchestration process is planned with the customer request date as the completion date for the step identified in the process as the last step.
Default Lead Time/Lead Time UOM: Lead time is the expected duration for a given unit of work to be completed. If a lead-time expression is not defined for a step, then the default lead time is used.
Lead-Time Expression: Define lead times using Oracle Business Rules. This method provides flexibility when defining complex lead-time expressions.
When an order enters Oracle Fusion Distributed Order Orchestration it is transformed into fulfillment lines. Then orchestration processes are created and assigned to the fulfillment lines. The orchestration process is first planned when the orchestration process is created. Planning is based on the requested date of the sales order. The requested date becomes the required completion date for the last step (step identified by the Last Fulfillment Completion Step indicator and not the chronological last step) of the orchestration process. The application then calculates the planned dates for each step and task, starting from the first chronological step, using the lead time you define. The schedule appears in the Order Orchestration work area.
The orchestration process is replanned every time an update is received from the fulfilment system. You can control when process planning occurs by scheduling a regular planning update for the frequency you want using a scheduled process.
This example demonstrates how to create a compensation pattern that determines what adjustments to make for a processing task in response to a requested change. The order administrator of a flooring company wants a rule that indicates that if the requested ship date is 11/20/2010, then cancel and redo the ShipGoods task.
Note
The following is an example of a simple rule, which is well suited for rules for an orchestration process with a single line. If you want to write a rule for an orchestration process that has multiple lines, then use advanced mode rules. For more information, see Oracle Fusion Middleware User's Guide for Oracle Business Rules.
To create the rule, you must construct If and Then statements.
Create the If statement: If the RequestShipDate is 11/20/2010.
Create the Then statement: Then redo the ShipGoods task.
Create the If statement: If the RequestShipDate is 11/20/2010.
Create the Then statement: Then redo the ShipGoods task.
When you define an orchestration process, you must select an orchestration process class, which provides a defined set of statuses for any orchestration process to which it is applied. Use orchestration process-specific statuses to apply different sets of statuses and rule logic for different items to show the progression of the process. For example, you could have a set of statuses and rule logic for orchestration processes for textbooks for customers that are colleges and a different set of statuses and rule logic for orchestration processes for textbooks for customers that are primary schools.
If you choose not to customize the status condition for an orchestration process, then the default statuses are used. If you customized the name of the default status, then the status appears in the application.
The orchestration process class is a set of status codes. When you select a process class in the header, the status codes from that class are available for selection when you create the status conditions. These are the status codes that will represent the status of the orchestration process and will be seen throughout the application. The status code is also used for grouping orchestration processes by status to enable order managers to quickly identify orchestration processes that are in the same status.
You can set up rules that govern under what conditions a status is assigned to an orchestration process. For example, you could create a rule that says if the status of the Schedule task is Not Started, then assign the orchestration process the status Unscheduled. You must designate a status or set of statuses to indicate that a task is complete. You can only select from those that were defined to mark a task complete.
During processing of an orchestration order, the tasks of the assigned orchestration process are fulfilled step by step. A default set of sequential statuses is provided for the fulfillment tasks, but you can also create your own fulfillment task statuses and sequences for an orchestration process. You must determine the status that will be assigned to an orchestration process at each stage of the process. For example, if a Schedule Carpet task has a status of Unsourced, what status should the orchestration process have?
You can designate the statuses that represent an orchestration process when you define the orchestration process. These statuses are used to represent the status of the orchestration process throughout the application. You can select a preset group of orchestration process statuses by selecting an orchestration process class. You can create rules that govern how statuses are attained during the orchestration process and the conditions under which they are assigned to the orchestration process task.
If rules are created, then at run time the application evaluates each of the statements sequentially. The true condition with the highest sequence number determines the status of the orchestration process.
When a fulfillment line splits, the resulting fulfillment lines have duplicate tasks. At some point, the tasks could have different statuses. For example, the Schedule task for fulfillment line A1 is in status Not Scheduled, and the Schedule task for fulfillment line A2 is Scheduled. In this case, the application searches for the split priority of the task statuses. The status with the higher split priority (lower number) becomes the status of the orchestration process.
This example demonstrates how to create status conditions for an orchestration process. A company that sells flooring needs an orchestration process that reflects the steps required to fulfill such orders. The orchestration process definition must designate how to reflect the status of the orchestration process at any point in time. The status of the orchestration process is based on the status of the tasks. This example shows how to create the conditions that designate the status of the orchestration process.
When you create an orchestration process status condition, you must decide which orchestration process class to use and which statuses you want to reflect the status of the orchestration process. An orchestration process class is a set of statuses that can be used for an orchestration process.
This example assumes that an administrator has created an orchestration process class called Carpet Class on the Manage Status Values page.
This example shows you how to create one orchestration process status condition. Repeat these steps for all the status conditions you need. You are not required to use all the statuses in the orchestration process class.
When you create an orchestration process definition, you can opt to define status conditions for certain types of fulfillment lines that can be processed by the orchestration process. Use fulfillment line-specific status conditions to apply different sets of statuses and rule logic for different items. For example, you could have one set of status conditions for textbooks and another set for paperback books.
If you choose not to create status conditions for a fulfillment line, then the status conditions with the status rule set that is assigned to the default category dictates the status progression.
Your organization might need for different fulfillment lines within the same orchestration process to have different status progressions. For example, a model with shippable fulfillment lines and nonshippable fulfillment lines may require different statuses for each type of fulfillment line. A status catalog provides a means to group like items, so that they can achieve the same statuses at the same time. Status catalogs are defined in Oracle Fusion Product Model.
You can select a status catalog when you create an orchestration process definition. Status catalogs that meet the following criteria are available for selection:
An item exists in only one category within a catalog.
A category contains items or subcategories but not both.
A catalog is controlled at the master level only, not at the organization level.
You can use catalogs and categories in multiple orchestration process definitions. Use a category to ensure that the same set of status conditions is applied to specific sets of fulfillment lines. The same status conditions are applied to all fulfillment lines that have the item that belongs to that category.
Whether or not you use status catalogs, you can use status rule sets to apply a set of sequential statuses to the fulfillment line that is processed by the orchestration process. A status rule set is a set of rules that govern the conditions under which status values are assigned to fulfillment lines. When you create a status rule set, you determine the status that will be assigned to a fulfillment line at each stage of the process. For example, if an item has a status of Unsourced, then the fulfillment line will have the status Unscheduled. A status rule set streamlines administration by enabling you to use a rule set with any number of fulfillment lines, rather than by entering separate rules for each fulfillment line. You can also apply the same logic to multiple categories.
In the case where a parent and a child category refer to different status rule sets, the child takes priority. This allows you to define an All category to handle all items in one definition, as well as to add an additional subcategory for a subset of products that needs to use a different status rule set.
During order processing, the application assigns an overall status to each orchestration order. This status is determined by assigning the orchestration order the status of the fulfillment line that has progressed the furthest in the order life cycle. To determine the fulfillment line status, the application evaluates each of the status conditions of the fulfillment line sequentially. The true condition with the highest sequence number determines the status of the fulfillment line.
Caution
If you used the Functional Setup Manager migration tool to port test instance data to a production environment, then do not change the status rule set name in either instance. Changing the name could prevent references to other data in the orchestration process from being updated.
This example demonstrates how to create status conditions for a fulfillment line with several items that require different statuses. A flooring company is setting up orchestration processes to handle orders for different types of flooring. The same orchestration process could be used for multiple types of flooring, but the administrator wants to define statuses for each type of flooring separately because they require slightly different statuses. This example demonstrates how to select the status catalog and create the status conditions for a single category of items within an orchestration process.
When you create an orchestration process, you need to decide whether you want different fulfillment lines that get assigned to the process to have different statuses as they progress through fulfillment. If so, you must determine how to group the fulfillment lines using catalogs and categories.
The Flooring catalog has the following categories: Carpet, Tile, Hardwood. You select the category for Carpet. You create a status rule set with conditions that will yield the following statuses: Not Scheduled, Scheduled, Awaiting Shipment, Shipped, Billed.
This example assumes that an administrator has created fulfillment line status values on the Manage Status Values page. This example also assumes a Flooring catalog was created in Oracle Fusion Product Model.
This example shows you how to create one fulfillment line status condition. Repeat these steps for all the status conditions you need.
After you finish creating or updating an orchestration process definition, you must release it and then deploy it on an instance of Oracle Fusion Distributed Order Orchestration. Deploying the orchestration process makes it available for use by the application.
If you want to use the ShipOrderGenericProcess and ReturnOrderGenericProcess predefined orchestration processes, then you must generate them and deploy them; it is not necessary to release them.
After your orchestration process is defined, you must take the following steps to deploy it:
Release the orchestration process definition.
Download the orchestration process definition.
Modify the SOA configuration plan.
Deploy the JAR file using the modified configuration plan.
Do not modify orchestration process definitions outside of the Manage Orchestration Process Definition pages.
When an orchestration process is released it is automatically validated. After you release the orchestration process definition, batch-level validations are performed to ensure that the orchestration process was constructed correctly. If any errors are generated during validation, the release process stops and an error icon appears next to the orchestration process name. The list of errors is retained until the next time the batch validation runs. If the orchestration process is valid, then release of the process continues. An orchestration process is valid if no error messages are generated; warning messages may be associated with a valid process. After validation is complete, the orchestration process definition becomes read-only. At this point, the orchestration process is given Released status, and the BPEL artifacts needed to deploy and run the orchestration process are created and stored.
After you release an orchestration process definition, you deploy the downloaded artifacts to the server. Use Oracle Fusion Setup Manager to export the artifacts. Oracle Fusion Middleware is used to deploy artifacts.
On the Manage Orchestration Process Definitions page, select the orchestration process that you want to deploy.
Click the Edit icon.
In the Download Generated Process window, click Download.
Save the archive file that appears to a local directory.
Open the archive file in a local directory.
The JAR file is located in a Deploy folder within a folder bearing the name of the orchestration process that you downloaded.
Modify the SOA configuration plan, replacing the host names and ports with your organization's Distributed Order Orchestration ADF server and port and Distributed Order Orchestration (Supply Chain Management) SOA server and port. Use the external-facing URLs of the servers. The configuration plan enables you to define the URL and property values to use in different environments. During process deployment, the configuration plan is used to search the SOA project for values that must be replaced to adapt the project to the next target environment.
<?xml version="1.0" encoding="UTF-8"?>
<SOAConfigPlan
xmlns:jca="http://platform.integration.oracle/blocks/adapter/fw/metadata"
xmlns:wsp="http://schemas.xmlsoap.org/ws/2004/09/policy"
xmlns:orawsp="http://schemas.oracle.com/ws/2006/01/policy"
xmlns="http://schemas.oracle.com/soa/configplan">
<composite name="*">
<import>
<searchReplace>
<search/>
<replace/>
</searchReplace>
</import>
<service name="client">
<binding type="ws">
<attribute name="port">
</attribute>
</binding>
</service>
<reference name="*">
<binding type="ws">
<attribute name="location">
<searchReplace>
<search>http://localhost_am:port</search>
<replace>http://actualDOOADFserver:port</replace>
</searchReplace>
<searchReplace>
<search>http://localhost_soa:port</search>
<replace>http://actualDOOSOAserver:port</replace>
</searchReplace>
</attribute>
</binding>
</reference>
</composite>
</SOAConfigPlan>
To deploy the JAR file, you can use any of the following: Oracle Enterprise Manager Fusion Middleware Control, ant command line tool, or Oracle WebLogic Scripting Tool. For more information about deploying SOA composite applications, see Oracle Fusion Middleware Administrator's Guide for Oracle SOA Suite and Oracle Business Process Management Suite.
After Oracle Fusion Distributed Order Orchestration creates an orchestration order, the application assigns orchestration processes to fulfillment lines based on process assignment rules. Process assignment rules are executed in the Oracle Business Rules engine. Process assignment rules are built based on orchestration groups and using orchestration order attributes.
You do not need to specify versions or effectivity dates in the process assignment rules because versions and effectivity dates are controlled at the orchestration process level.
A fulfillment line belongs to an orchestration group. Distributed Order Orchestration contains the following predefined orchestration groups: Shipment Set, Model/Kit, and Standard. Standard is used for standard items or finished items. All the fulfillment lines that belong to a shipment set or a model are assigned the same orchestration process.
Assign a process for each set of unique conditions. You can set up a default orchestration process for each orchestration group using the Otherwise construct.
Before you create process assignment rules, you must define orchestration processes or at least know the names you will give to orchestration processes. You will add the orchestration process names to bucket sets to make them available for selection when you create a process assignment rule.
Use these scenarios to understand how to use process assignment rules.
All orders for ceramic tile must undergo the same processing steps, so you write a process assignment rule that assigns the Tile Processing orchestration process to all orchestration order lines with tile as the product.
Customer A requires an extra inspection step for all its orders, so you write a process assignment rule that assigns the Customer A Process to all orchestration order lines that have Customer A in the orchestration order header.
Orders that are bound for countries outside your current location require different handling, such as completion of customs forms. You write a process assignment rule that assigns the International Orders orchestration process to all orchestration order lines that have a foreign country in the ship-to address in the header.
Each company has its own business rules, which must be applied during the orchestration process. The constraint framework allows for the implementation of those specific requirements. Processing constraints are rules that control attempted changes to an order: What can be changed, when, and by whom.
At runtime, processing constraints are checked on changes to orchestration orders, orchestration order lines, and fulfillment lines. Changes that are not permitted by processing constraints are not allowed. A message is returned indicating the reason the change is not permitted.
Processing constraints are used also to validate the required attributes for fulfillment requests.
Some processing constraints are predefined; you cannot change these processing constraints. If you want to make processing constraints more restrictive, then you must create new ones.
Consider using processing constraint in scenarios such as the following. In all of these scenarios, the change is submitted, but it is never processed because the processing constraint rejects it. A message is returned to the order capture application indicating that the change could not be made because of the processing constraint.
An orchestration process gets to the shipping stage. Then a change order is submitted against the orchestration order. The orchestration process is so far along that it is costly and impractical to make changes. To prevent this problem, you create a processing constraint that rejects any changes when an orchestration process is in the shipment step.
Your company has a policy that it does not deliver items to an address that does not have a ship-to contact. Sometimes sales orders that do not have a ship-to contact are submitted. To prevent this problem, you create a processing constraint that rejects sales orders that do not have the required information.
Your company allows customer service representatives to submit certain customer changes without approval from a manager. If the change order has a transaction value over $100, then the change must be submitted by a manager. You create a processing constraint that rejects changes orders with transaction values over $100 from anyone with the customer service representative role.
This example demonstrates how to create a processing constraint that prevents changes to any orchestration process that is in the shipping phase. An orchestration process gets to the shipping stage. Then a change order is submitted against the orchestration order. The orchestration process is so far along that it is costly and impractical to make changes. To prevent this problem, you create a processing constraint that rejects any changes when an orchestration process is in the SetUpShipment step.
Before you create a processing constraint, you must create a constraint entity, a validation rule set, and a record set.
This is the process of creating a process task entity so that it can be used later to create a processing constraint. This is the entity that will be constrained.
A validation rule set names a condition and defines the semantics of how to validate that condition for a processing constraint.
A record set is a group of records that are bound by common attribute values. You can define conditions and specify a record set to be validated for a given condition as defined by the validation template.
Now that you have created a constraint entity, validation rule set, and record set, you can create the processing constraint.
When sales orders enter Oracle Fusion Distributed Order Orchestration from disparate order capture applications, they must be transformed into business objects that can be processed by Distributed Order Orchestration. During this process, called decomposition, sales orders are deconstructed and then transformed into Distributed Order Orchestration business objects.
Business rules determine how sales orders are transformed. The following business rules are available: Pretransformation defaulting rules, product transformation rules, posttransformation defaulting rules, and process assignment rules.
Sales orders are transformed as follows:
The sales order is passed from the order capture application.
The connector service transforms the sales order from an external order capture system to a canonical business object called the sales order enterprise business object. The sales order enterprise business object structurally transforms the sales order from an external order capture system to an orchestration order in Distributed Order Orchestration. The Receive and Transform service, SalesOrderOrchestrationEBS, looks up the cross-reference values from the customer data hub, Oracle Fusion Trading Community Model, and Oracle Fusion Product Model to determine whether the sales order values must be transformed to common values to populate the sales order enterprise business object. Cross-referencing is required for static data such as country code and currency codes, as well as for dynamic data such as customers and products. The attributes come from different sources: Product Model, Trading Community Model, and the order orchestration and planning data repository. If the order capture and Distributed Order Orchestration systems use different domain values, then the connector service transforms the structure and values from the order capture system domain to the Distributed Order Orchestration domain. The Receive and Transform service is called in the default predefined process prior to storing the sales order.
The connector service calls the decomposition process composite enterprise business function through a decomposition enterprise service. The decomposition process composite is exposed as a WSDL that can be called as a service from the connector service through an enterprise business service.
The decomposition service calls the requested operation (create, delete, update, or cancel orchestration order).
The decomposition service accepts the sales order enterprise business message as input. The decomposition service returns a sales order enterprise business message as the output.
The product is transformed according to the business rules that you write.
The Assign and Launch service assigns orchestration processes to line items according to the business rules that you write.
Order capture services are used to communicate updates back to the order capture system. To receive updates, the order capture system must subscribe to the events.
The connector service transforms the sales order business object as understood by an order capture application to an enterprise business object. The connector service then calls the Receive and Transform service.
The connector transforms the structure and content of the sales order.
The connector service transforms the sales order from an external order capture system to a canonical business object called the sales order enterprise business object. The sales order enterprise business object structurally transformations the sales order from an external order capture system to an orchestration order in Oracle Fusion Distributed Order Orchestration. The decomposition service accepts a sales order enterprise business message as the input and returns a sales order enterprise business message as the output. You can create the connector according to your organization's requirements, using the sales order enterprise business object attributes that are used by Distributed Order Orchestration.
You must establish and maintain cross-references to relate business data between different integrated order capture and fulfillment systems and Oracle Fusion Distributed Order Orchestration.
Note the location of and other pertinent information about the following cross-references:
Customer cross-references
Item cross-references
Other cross-references
Customer cross-references are maintained in the Oracle Fusion Trading Community Model. You can use external customer hubs with Distributed Order Orchestration, but you must maintain cross-references in Trading Community Model also, so that Distributed Order Orchestration can resolve the Oracle Fusion customer values and vice versa. You can capture or set up customer cross-references in the Oracle Fusion customer model as part of the customer creation and update process.
During order processing, the order is created in the order capture system and sent to Distributed Order Orchestration, along with customer data. If the customer already exists in the Fusion customer master, then Distributed Order Orchestration uses a cross-reference to obtain the master customer record and the customer ID for the intended order fulfillment system. Then the decomposed order is sent, along with the customer ID and necessary attributes from the master.
Item cross-references are maintained in the Oracle Fusion Product Model. The cross-reference is established between the source system item and the item in the master product information repository, which is the Product Model. Two types of relationships are used for the cross-references: Source system item relationship, which captures the relationship between the source item and the Fusion item when a product hub is used; and a named item relationship, which is used to store the cross-reference between the source item and the Fusion item. This type of relationship is used when items are brought from disparate systems into a master product information repository. A hub is not used in the latter scenario.
The cross-references of all attributes, except customer and item attributes, are maintained in the order orchestration and product data repository. Use domain value maps for attributes from the order orchestration and planning data repository. Domain value maps are used during the collections process to map the values from one domain to another, which is useful when different domains represent the same data in different ways.
Set up product transformation to ensure that the products are converted properly when a sales order is transformed into an orchestration order.
Product transformation is executed using a combination of product relationships, product structures, transaction item attributes, and business rules. Product transformation setup consists of the following steps
Define items in Oracle Fusion Product Model.
Define rule bucket sets.
Set the bucket sets to the facts.
Create rules.
You must set up items and their structures and attributes in Product Model and then map them to fulfillment products.
Define products used for product transformation rules in the product master.
If you plan to base transformation rules on product structure, then define product structures.
If you plan to use attribute-based rules, then define transactional item attributes.
Define the relationship between sales product and fulfillment product.
Create bucket sets on the Managing Product Transformation Rules page. Bucket sets contain the options that are available for selection when creating rules. Smaller bucket sets are more likely to be reused.
Create product transformation rules on the Managing Product Transformation Rules page.
Use pretransformation defaulting rules to automatically populate specific attributes onto an orchestration order before product transformation. You can use the defaulted attribute value in the product transformation rules.
The master inventory organization automatically is defaulted to the orchestration order, so that it is available for product transformation rules.
Use these scenarios to understand how to use pretransformation defaulting rules.
Your company receives sales orders for widgets that have an attribute called Request Date. You want this attribute to appear on all fulfillment lines for widgets. You write a pretransformation defaulting rule that states that if the product is a widget then populate the Request Date attribute on the fulfillment line.
Your company receives sales orders for widgets. You want to write a product transformation rule that converts the widget size from centimeters to inches, but you must first populate the fulfillment line with the Size attribute. You write a pretransformation defaulting rule that says that if the product is a widget then populate the fulfillment line with the Size attribute.
During product transformation, a sales-oriented representation of the products on a sales order is transformed to a fulfillment-oriented representation of the products on an orchestration order. Product transformation is effected using a combination of product relationships, product structures, transactional item attributes, and business rules. You create transactional item attributes and product relationships and structures in Oracle Fusion Product Model. You write rules on the Manage Product Transformation Rules page in Distributed Order Orchestration.
The following types of product transformation are supported:
Attribute to attribute
Attribute to product
Product to attribute
Product to product
Context to attribute
Context to product
Use the following examples to understand the types of product transformation rules you can write.
Your US-based company receives sales orders from its office in Europe. The item size on the sales order line is expressed in centimeters, but you want it to appear in inches on the orchestration order line. You write an attribute-to-attribute transformation rule that transforms the transactional item attribute from the source order line to a different attribute on the orchestration order line.
Your company receives sales orders for MP3 players with various transactional item attributes, such as color and storage capacity. You want each combination of attributes to correspond to a product number, for example, an MP3 player of color silver and storage capacity of 8 megabytes would appear as MA980LL/A on the orchestration order line. You write an attribute-to-product transformation rule transforming the attributes to a product number.
Your company manufactures laptop computers. Some are shipped to domestic locations, and others are shipped to international locations. Each type of shipping has different requirements. You write a context-to-attribute transformation rule that transforms the region, or context, on the sales order line into a packing type attribute on the orchestration order line.
Your company receives sales orders for laptop computers from different geographical regions. The geographical region of the order determines which adapter is included with the product. You write a context-to-product transformation rule that transforms a single sales order to an orchestration order with two lines, one of which is reserved for the region-specific adapter:
Orchestration order line 1: laptop computer
Orchestration order line 2: 65-watt AC adapter
Your company receives sales orders for camcorders that come with several accessories: Lithium-ion battery, AC adapter, editing software, packing materials. You write a product-to-product transformation rule that creates five orchestration order lines:
Orchestration order line 1: camcorder
Orchestration order line 2: lithium-ion battery
Orchestration order line 3: AC adapter
Orchestration order line 4: editing software
Orchestration order line 5: packing materials
Sales orders contain attributes for width and height, but you want an attribute for area on the orchestration order. You write a product-to-attribute transformation rule that computes the value for area from the width and height transactional item attributes and places it on the orchestration order.
This example demonstrates how to create an advanced transformation rule. Transformation rules are used at runtime to determine the internal representation of a product on an order line based on the information in the source order. An advanced rule can be used to compare two or more lines in an order.
This example shows you how to create a rule in which two lines are compared. If the first fulfillment line requires that you add an item and the second fulfillment line requires that you delete the same item, then the two actions cancel out one another.
Create the If statement: If the change in fulfillment line 1 is Add.
Create the If statement: If the change in fulfillment line 2 is Delete.
Create the If statement: If the inventory item in fulfillment line 1 is the same as the inventory item in fulfillment line 2.
Create the If statement: If the fulfillment line ID of fulfillment line 1 is different from the fulfillment ID of fulfillment line 2.
Create the Then statement: Then retract fulfillment line 1 and fulfillment line 2.
Use posttransformation defaulting rules to automatically populate specific attributes onto an orchestration order based on the product transformation that is applied to the orchestration order. Use these scenarios to understand how to use posttransformation defaulting rules.
Your company receives orders for laptop computers. Your product transformation rule transforms the sales order into an orchestration order with two lines:
Orchestration order line 1: laptop computer
Orchestration order line 2: alternating current adapter
You write a posttransformation defaulting rule that populates orchestration order line 2 with a warehouse that is different from the warehouse for the laptop computer.
Your company receives orders from that have the requested date as follows: MM/DD/YYYY. Your staff finds it useful to also know the day of the week because delivery options might be limited or cost more on certain days. You write a posttransformation defaulting rule that populates the day of the week onto the new orchestration order.
|
Copyright © 2011-2012, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|