3 Communications In a Cluster
This chapter introduces how clusters in WebLogic Server 10.3.6 implement two key features: load balancing and failover. It provide information that helps architects and administrators configure a cluster that meets the needs of a particular Web application.
This chapter includes the following sections:
WebLogic Server Communication In a Cluster
WebLogic Server instances in a cluster communicate with one another using two basic network technologies:
-
IP sockets, which are the conduits for peer-to-peer communication between clustered server instances.
-
IP unicast or multicast, which server instances use to broadcast availability of services and heartbeats that indicate continued availability.
When creating a new cluster, Oracle recommends that you use unicast for messaging within a cluster.
Note:
When creating a cluster, the default cluster messaging mode is unicast.If you encounter problems with updating JNDI trees for a cluster with unicast messaging, you might want to consider switching to multicast messaging mode.
Oracle fully supports both UDP multicast-based and TCP unicast-based clustering in WebLogic Server. Beginning in WebLogic Server 10.0, unicast-based clustering has been made the default, primarily because it simplifies out of the box cluster configuration.
For WebLogic Server versions 9.2 and earlier, you must use multicast for communications between clusters.
The way in which WebLogic Server uses IP multicast or unicast and socket communication affects the way you configure your cluster.
Using IP Multicast for Backward Compatibility
IP multicast is a simple broadcast technology that enables multiple applications to "subscribe" to a given IP address and port number and listen for messages.
IP multicast broadcasts messages to applications, but it does not guarantee that messages are actually received. If an application's local multicast buffer is full, new multicast messages cannot be written to the buffer and the application is not notified when messages are "dropped." Because of this limitation, WebLogic Server instances allow for the possibility that they may occasionally miss messages that were broadcast over IP multicast.
Note:
A multicast address is an IP address in the range from 224.0.0.0 to 239.255.255.255. The default multicast value used by WebLogic Server is 239.192.0.0. You should not use any multicast address within the range x.0.0.1.WebLogic Server uses IP multicast for all one-to-many communications among server instances in a cluster. This communication includes:
-
Cluster-wide JNDI updates—Each WebLogic Server instance in a cluster uses multicast to announce the availability of clustered objects that are deployed or removed locally. Each server instance in the cluster monitors these announcements and updates its local JNDI tree to reflect current deployments of clustered objects. For more details, see Cluster-Wide JNDI Naming Service.
-
Cluster heartbeats—Each WebLogic Server instance in a cluster uses multicast to broadcast regular "heartbeat" messages that advertise its availability. By monitoring heartbeat messages, server instances in a cluster determine when a server instance has failed. (Clustered server instances also monitor IP sockets as a more immediate method of determining when a server instance has failed.)
-
Clusters with many nodes—Multicast communication is the option of choice for clusters with many nodes.
Multicast and Cluster Configuration
Because multicast communications control critical functions related to detecting failures and maintaining the cluster-wide JNDI tree (described in Cluster-Wide JNDI Naming Service) it is important that neither the cluster configuration nor the network topology interfere with multicast communications. The sections that follow provide guidelines for avoiding problems with multicast communication in a cluster.
If Your Cluster Spans Multiple Subnets In a WAN
In many deployments, clustered server instances reside within a single subnet, ensuring multicast messages are reliably transmitted. However, you may want to distribute a WebLogic Server cluster across multiple subnets in a Wide Area Network (WAN) to increase redundancy, or to distribute clustered server instances over a larger geographical area.
If you choose to distribute a cluster over a WAN (or across multiple subnets), plan and configure your network topology to ensure that multicast messages are reliably transmitted to all server instances in the cluster. Specifically, your network must meet the following requirements:
-
Full support of IP multicast packet propagation. In other words, all routers and other tunneling technologies must be configured to propagate multicast messages to clustered server instances.
-
Network latency low enough to ensure that most multicast messages reach their final destination in 200 to 300 milliseconds.
-
Multicast Time-To-Live (TTL) value for the cluster high enough to ensure that routers do not discard multicast packets before they reach their final destination. For instructions on setting the Multicast TTL parameter, see Configure Multicast Time-To-Live (TTL).
Note:
Distributing a WebLogic Server cluster over a WAN may require network facilities in addition to the multicast requirements described above. For example, you may want to configure load balancing hardware to ensure that client requests are directed to server instances in the most efficient manner (to avoid unnecessary network hops).
Firewalls Can Break Multicast Communication
Although it may be possible to tunnel multicast traffic through a firewall, this practice is not recommended for WebLogic Server clusters. Treat each WebLogic Server cluster as a logical unit that provides one or more distinct services to clients of a Web application. Do not split this logical unit between different security zones. Furthermore, any technologies that potentially delay or interrupt IP traffic can disrupt a WebLogic Server cluster by generating false failures due to missed heartbeats.
Do Not Share the Cluster Multicast Address with Other Applications
Although multiple WebLogic Server clusters can share a single IP multicast address and port, other applications should not broadcast or subscribe to the multicast address and port used by your cluster or clusters. That is, if the machine or machines that host your cluster also host other applications that use multicast communications, make sure that those applications use a different multicast address and port than the cluster does.
Sharing the cluster multicast address with other applications forces clustered server instances to process unnecessary messages, introducing overhead. Sharing a multicast address may also overload the IP multicast buffer and delay transmission of WebLogic Server heartbeat messages. Such delays can result in a WebLogic Server instance being marked as failed, simply because its heartbeat messages were not received in a timely manner.
For these reasons, assign a dedicated multicast address for use by WebLogic Server clusters, and ensure that the address can support the broadcast traffic of all clusters that use the address.
If Multicast Storms Occur
If server instances in a cluster do not process incoming messages on a timely basis, increased network traffic, including negative acknowledgement (NAK) messages and heartbeat re-transmissions, can result. The repeated transmission of multicast packets on a network is referred to as a multicast storm, and can stress the network and attached stations, potentially causing end-stations to hang or fail. Increasing the size of the multicast buffers can improve the rate at which announcements are transmitted and received, and prevent multicast storms. See Configure Multicast Buffer Size.
One-to-Many Communication Using Unicast
WebLogic Server provides an alternative to using multicast to handle cluster messaging and communications. Unicast configuration is much easier because it does not require cross network configuration that multicast requires. Additionally, it reduces potential network errors that can occur from multicast address conflicts.
Unicast Configuration
Unicast is configured using ClusterMBean.isUnicastBasedClusterMessagingEnabled(). The default value of this parameter is false. Changes made to this MBean are not dynamic. You must restart your cluster for changes to take effect.
To define a specific channel for unicast communications, you can use the setNetworkChannelForUnicastMessaging(String NetworkChannelName). When unicast is enabled, servers will attempt to use the value defined in this MBean for communications between clusters. If the unicast channel is not explicitly defined, the default network channel is used.
When configuring WebLogic Server clusters for unicast communications, if the servers are running on different machines, you must explicitly specify their listen addresses or DNS names.
Considerations When Using Unicast
The following considerations apply when using unicast to handle cluster communications:
-
All members of a cluster must use the same message type. Mixing between multicast and unicast messaging is not allowed.
-
You must use multicast if you need to support previous versions of WebLogic Server within your cluster.
-
Individual cluster members cannot override the cluster messaging type.
-
The entire cluster must be shutdown and restarted to message modes.
-
JMS topics configured for multicasting can access WebLogic clusters configured for unicast because a JMS topic publishes messages on its own multicast address that is independent of the cluster address. However, the following considerations apply:
-
The router hardware configurations that allow unicast clusters may not allow JMS multicast subscribers to work.
-
JMS multicast subscribers need to be in a network hardware configuration that allows multicast accessibility.
For more details, see "Using Multicasting with WebLogic JMS" in Programming JMS for Oracle WebLogic Server.
-
Peer-to-Peer Communication Using IP Sockets
IP sockets provide a simple, high-performance mechanism for transferring messages and data between two applications. Clustered WebLogic Server instances use IP sockets for:
-
Accessing non-clustered objects deployed to another clustered server instance on a different machine.
-
Replicating HTTP session states and stateful session EJB states between a primary and secondary server instance.
-
Accessing clustered objects that reside on a remote server instance. (This generally occurs only in a multi-tier cluster architecture, such as the one described in Recommended Multi-Tier Architecture.)
Note:
The use of IP sockets in WebLogic Server extends beyond the cluster scenario—all RMI communication takes place using sockets, for example, when a remote Java client application accesses a remote object.
Proper socket configuration is crucial to the performance of a WebLogic Server cluster. Two factors determine the efficiency of socket communications in WebLogic Server:
-
Whether the server instance host system uses a native or a pure-Java socket reader implementation.
-
For systems that use pure-Java socket readers, whether the server instance is configured to use enough socket reader threads.
Pure-Java Versus Native Socket Reader Implementations
Although the pure-Java implementation of socket reader threads is a reliable and portable method of peer-to-peer communication, it does not provide the best performance for heavy-duty socket usage in a WebLogic Server cluster. With pure-Java socket readers, threads must actively poll all opened sockets to determine if they contain data to read. In other words, socket reader threads are always "busy" polling sockets, even if the sockets have no data to read. This unnecessary overhead can reduce performance.
The performance issue is magnified when a server instance has more open sockets than it has socket reader threads—each reader thread must poll more than one open socket. When the socket reader encounters an inactive socket, it waits for a timeout before servicing another. During this timeout period, an active socket may go unread while the socket reader polls inactive sockets, as shown in Figure 3-1.
Figure 3-1 Pure-Java Socket Reader Threads Poll Inactive Sockets
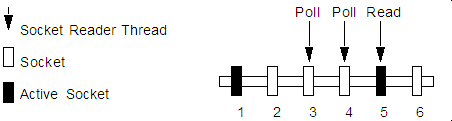
Description of "Figure 3-1 Pure-Java Socket Reader Threads Poll Inactive Sockets"
For best socket performance, configure the WebLogic Server host machine to use the native socket reader implementation for your operating system, rather than the pure-Java implementation. Native socket readers use far more efficient techniques to determine if there is data to read on a socket. With a native socket reader implementation, reader threads do not need to poll inactive sockets—they service only active sockets, and they are immediately notified (via an interrupt) when a given socket becomes active.
Note:
Applets cannot use native socket reader implementations, and therefore have limited efficiency in socket communication.For instructions on how to configure the WebLogic Server host machine to use the native socket reader implementation for your operating system, see Configure Native IP Sockets Readers on Machines that Host Server Instances.
Configuring Reader Threads for Java Socket Implementation
If you do use the pure-Java socket reader implementation, you can still improve the performance of socket communication by configuring the proper number of socket reader threads for each server instance. For best performance, the number of socket reader threads in WebLogic Server should equal the potential maximum number of opened sockets. This configuration avoids the situation in which a reader thread must service multiple sockets, and ensures that socket data is read immediately.
To determine the proper number of reader threads for server instances in your cluster, see the following section, Determining Potential Socket Usage.
For instructions on how to configure socket reader threads, see Set the Number of Reader Threads on Machines that Host Server Instances.
Determining Potential Socket Usage
Each WebLogic Server instance can potentially open a socket for every other server instance in the cluster. However, the actual maximum number of sockets used at a given time depends on the configuration of your cluster. In practice, clustered systems generally do not open a socket for every other server instance, because objects are deployed homogeneously—to each server instance in the cluster.
If your cluster uses in-memory HTTP session state replication, and you deploy objects homogeneously, each server instance potentially opens a maximum of only two sockets, as shown in Figure 3-2.
Figure 3-2 Homogeneous Deployment Minimizes Socket Requirements
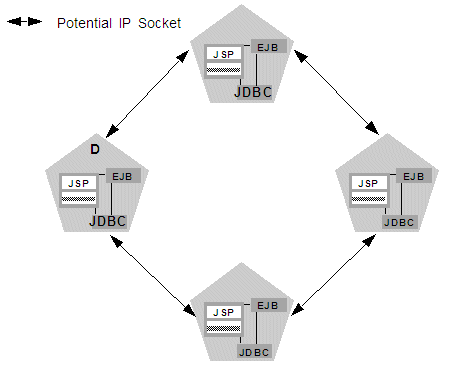
Description of "Figure 3-2 Homogeneous Deployment Minimizes Socket Requirements"
The two sockets in this example are used to replicate HTTP session states between primary and secondary server instances. Sockets are not required for accessing clustered objects, due to the collocation optimizations that WebLogic Server uses to access those objects. (These optimizations are described in Optimization for Collocated Objects.) In this configuration, the default socket reader thread configuration is sufficient.
Deployment of "pinned" services—services that are active on only one server instance at a time—can increase socket usage, because server instances may need to open additional sockets to access the pinned object. (This potential can only be released if a remote server instance actually accesses the pinned object.) Figure 3-3 shows the potential effect of deploying a non-clustered RMI object to Server A.
Figure 3-3 Non-Clustered Objects Increase Potential Socket Requirements
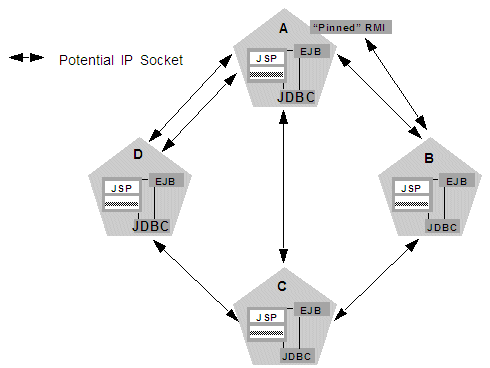
Description of "Figure 3-3 Non-Clustered Objects Increase Potential Socket Requirements"
In this example, each server instance can potentially open a maximum of three sockets at a given time, to accommodate HTTP session state replication and to access the pinned RMI object on Server A.
Note:
Additional sockets may also be required for servlet clusters in a multi-tier cluster architecture, as described in Configuration Notes for Multi-Tier Architecture.Client Communication via Sockets
Clients of a cluster use the Java implementation of socket reader threads.
WebLogic Server allows you to configure server affinity load balancing algorithms that reduce the number of IP sockets opened by a Java client application. A client accessing multiple objects on a server instance will use a single socket. If an object fails, the client will failover to a server instance to which it already has an open socket, if possible. In older version of WebLogic Server, under some circumstances, a client might open a socket to each server instance in a cluster.
For best performance, configure enough socket reader threads in the Java Virtual Machine (JVM) that runs the client. For instructions, see Set the Number of Reader Threads on Client Machines.
Cluster-Wide JNDI Naming Service
Clients of a non-clustered WebLogic Server server instance access objects and services by using a JNDI-compliant naming service. The JNDI naming service contains a list of the public services that the server instance offers, organized in a tree structure. A WebLogic Server instance offers a new service by binding into the JNDI tree a name that represents the service. Clients obtain the service by connecting to the server instance and looking up the bound name of the service.
Server instances in a cluster utilize a cluster-wide JNDI tree. A cluster-wide JNDI tree is similar to a single server instance JNDI tree, insofar as the tree contains a list of available services. In addition to storing the names of local services, however, the cluster-wide JNDI tree stores the services offered by clustered objects (EJBs and RMI classes) from other server instances in the cluster.
Each WebLogic Server instance in a cluster creates and maintains a local copy of the logical cluster-wide JNDI tree. The follow sections describe how the cluster-wide JNDI tree is maintained, and how to avoid naming conflicts that can occur in a clustered environment.
Caution:
Do not use the cluster-wide JNDI tree as a persistence or caching mechanism for application data. Although WebLogic Server replicates a clustered server instance's JNDI entries to other server instances in the cluster, those entries are removed from the cluster if the original instance fails. Also, storing large objects within the JNDI tree can overload multicast or unicast traffic and interfere with the normal operation of a cluster.How WebLogic Server Creates the Cluster-Wide JNDI Tree
Each WebLogic Server in a cluster builds and maintains its own local copy of the cluster-wide JNDI tree, which lists the services offered by all members of the cluster. Creation of a cluster-wide JNDI tree begins with the local JNDI tree bindings of each server instance. As a server instance boots (or as new services are dynamically deployed to a running server instance), the server instance first binds the implementations of those services to the local JNDI tree. The implementation is bound into the JNDI tree only if no other service of the same name exists.
Note:
When you start a Managed Server in a cluster, the server instance identifies other running server instances in the cluster by listening for heartbeats, after a warm-up period specified by theMemberWarmupTimeoutSeconds parameter in ClusterMBean. The default warm-up period is 30 seconds.Once the server instance successfully binds a service into the local JNDI tree, additional steps are performed for clustered objects that use replica-aware stubs. After binding the clustered object's implementation into the local JNDI tree, the server instance sends the object's stub to other members of the cluster. Other members of the cluster monitor the multicast or unicast address to detect when remote server instances offer new services.
Figure 3-4 shows a snapshot of the JNDI binding process.
Figure 3-4 Server A Binds an Object in its JNDI Tree, then Unicasts Object Availability
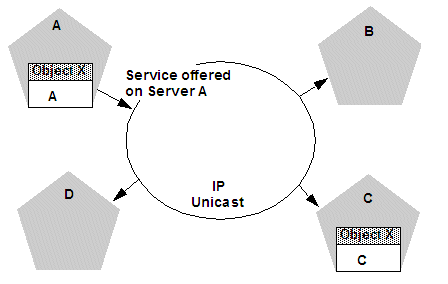
Description of "Figure 3-4 Server A Binds an Object in its JNDI Tree, then Unicasts Object Availability "
In the previous figure, Server A has successfully bound an implementation of clustered Object X into its local JNDI tree. Because Object X is clustered, it offers this service to all other members of the cluster. Server C is still in the process of binding an implementation of Object X.
Other server instances in the cluster listening to the multicast or unicast address note that Server A offers a new service for clustered object, X. These server instances update their local JNDI trees to include the new service.
Updating the local JNDI bindings occurs in one of two ways:
-
If the clustered service is not yet bound in the local JNDI tree, the server instance binds a new replica-aware stub into the local tree that indicates the availability of Object X on Server A. Servers B and D would update their local JNDI trees in this manner, because the clustered object is not yet deployed on those server instances.
-
If the server instance already has a binding for the cluster-aware service, it updates its local JNDI tree to indicate that a replica of the service is also available on Server A. Server C would update its JNDI tree in this manner, because it will already have a binding for the clustered Object X.
In this manner, each server instance in the cluster creates its own copy of a cluster-wide JNDI tree. The same process would be used when Server C announces that Object X has been bound into its local JNDI tree. After all broadcast messages are received, each server instance in the cluster would have identical local JNDI trees that indicate the availability of the object on Servers A and C, as shown in Figure 3-5.
Figure 3-5 Each Server's JNDI Tree is the Same after Unicast Messages are Received
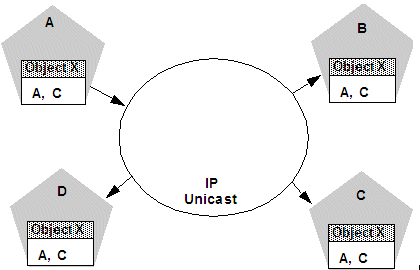
Description of "Figure 3-5 Each Server's JNDI Tree is the Same after Unicast Messages are Received"
Note:
In an actual cluster, Object X would be deployed homogeneously, and an implementation which can invoke the object would be available on all four server instances.How JNDI Naming Conflicts Occur
Simple JNDI naming conflicts occur when a server instance attempts to bind a non-clustered service that uses the same name as a non-clustered service already bound in the JNDI tree. Cluster-level JNDI conflicts occur when a server instance attempts to bind a clustered object that uses the name of a non-clustered object already bound in the JNDI tree.
WebLogic Server detects simple naming conflicts (of non-clustered services) when those services are bound to the local JNDI tree. Cluster-level JNDI conflicts may occur when new services are advertised over multicast or unicast. For example, if you deploy a pinned RMI object on one server instance in the cluster, you cannot deploy a replica-aware version of the same object on another server instance.
If two server instances in a cluster attempt to bind different clustered objects using the same name, both will succeed in binding the object locally. However, each server instance will refuse to bind the other server instance's replica-aware stub in to the JNDI tree, due to the JNDI naming conflict. A conflict of this type would remain until one of the two server instances was shut down, or until one of the server instances undeployed the clustered object. This same conflict could also occur if both server instances attempt to deploy a pinned object with the same name.
Deploy Homogeneously to Avoid Cluster-Level JNDI Conflicts
To avoid cluster-level JNDI conflicts, you must homogeneously deploy all replica-aware objects to all WebLogic Server instances in a cluster. Having unbalanced deployments across WebLogic Server instances increases the chance of JNDI naming conflicts during startup or redeployment. It can also lead to unbalanced processing loads in the cluster.
If you must pin specific RMI objects or EJBs to individual server instances, do not replicate the object's bindings across the cluster.
How WebLogic Server Updates the JNDI Tree
When a clustered object is removed (undeployed from a server instance), updates to the JNDI tree are handled similarly to the updates performed when new services are added. The server instance on which the service was undeployed broadcasts a message indicating that it no longer provides the service. Again, other server instances in the cluster that observe the multicast or unicast message update their local copies of the JNDI tree to indicate that the service is no longer available on the server instance that undeployed the object.
Once the client has obtained a replica-aware stub, the server instances in the cluster may continue adding and removing host servers for the clustered objects. As the information in the JNDI tree changes, the client's stub may also be updated. Subsequent RMI requests contain update information as necessary to ensure that the client stub remains up-to-date.
Client Interaction with the Cluster-Wide JNDI Tree
Clients that connect to a WebLogic Server cluster and look up a clustered object obtain a replica-aware stub for the object. This stub contains the list of available server instances that host implementations of the object. The stub also contains the load balancing logic for distributing the load among its host servers.
For more information about replica-aware stubs for EJBs and RMI classes, see Replication and Failover for EJBs and RMIs.
For a more detailed discussion of how WebLogic JNDI is implemented in a clustered environment and how to make your own objects available to JNDI clients, see "Using WebLogic JNDI in a Clustered Environment" in Programming JNDI for Oracle WebLogic Server