
| STA User Interface Guide, v1.0.2 |
| E28380-03 |

|

|

|

|
For example, you can use pivot tables to look at the health of drives, not just by library location, but also by drive type, firmware level, and many other attributes. The following table, from the Drives – Analysis screen, shows the number of occurrences of each drive health indicator (ACTION, MONITOR, etc.), aggregated by drive manufacturer, library, and library complex.
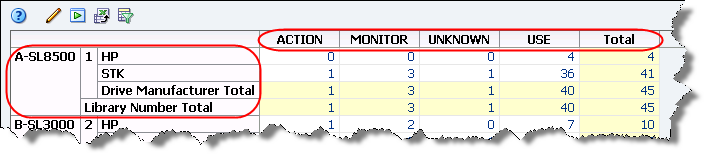
The aggregate counts in each pivot table cell are active links. These links provide access to additional details about the items included in the count. See “Aggregate Count Links” for details.
See “Pivot Table Layout Tasks” for details on how you can modify their display.
|
|
|
|
|

|
| Copyright © 2012 Oracle and/or its affiliates. All rights reserved. | Legal Notices |