| Oracle® Enterprise Manager Cloud Control Getting Started with Oracle Fusion Middleware Management 12c Release 2 (12.1.0.2) Part Number E24215-03 |
|
|
PDF · Mobi · ePub |
| Oracle® Enterprise Manager Cloud Control Getting Started with Oracle Fusion Middleware Management 12c Release 2 (12.1.0.2) Part Number E24215-03 |
|
|
PDF · Mobi · ePub |
After you have discovered the Coherence target and enabled the Management Pack Access, you can start monitoring the health and performance of the cluster. You can monitor the entire cluster or drill down to the various entities of the cluster like nodes, caches, services, connection managers, and connections.
This chapter contains the following sections:
At the cluster level, you can view the Home page for the cluster, view the performance of all nodes, caches, and connections in the cluster, and change configuration for the different entities in the cluster.
You can get a global view of the cluster from the Home page by following these steps:
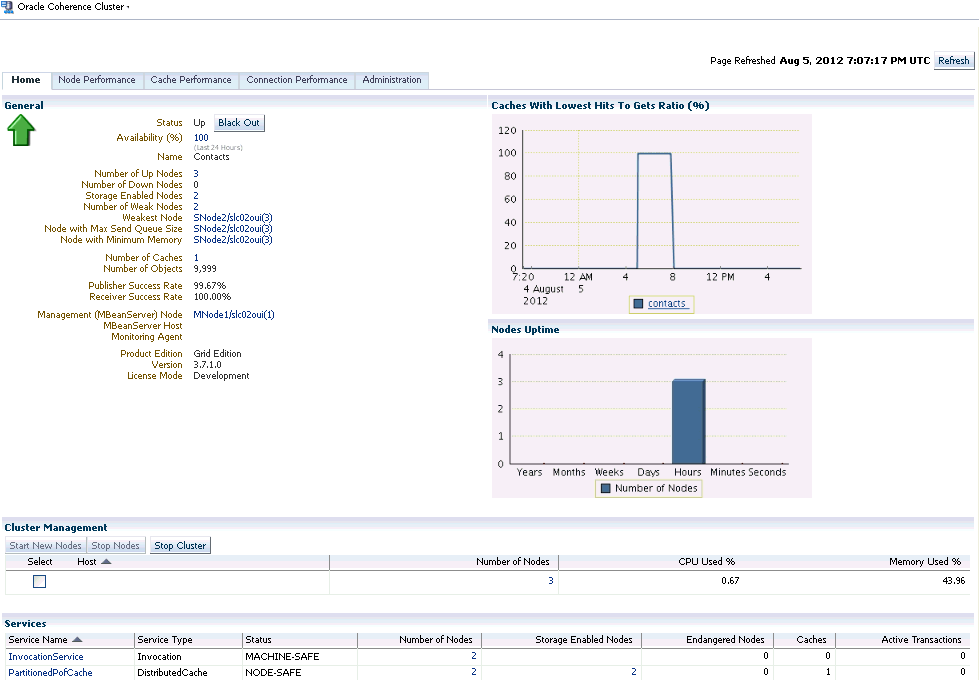
From the Targets menu, select Middleware, then click on a Coherence Cluster target. The Coherence Cluster Home page is displayed.
This page contains the following sections:
General
Graphs
Cluster Management
Service
Applications
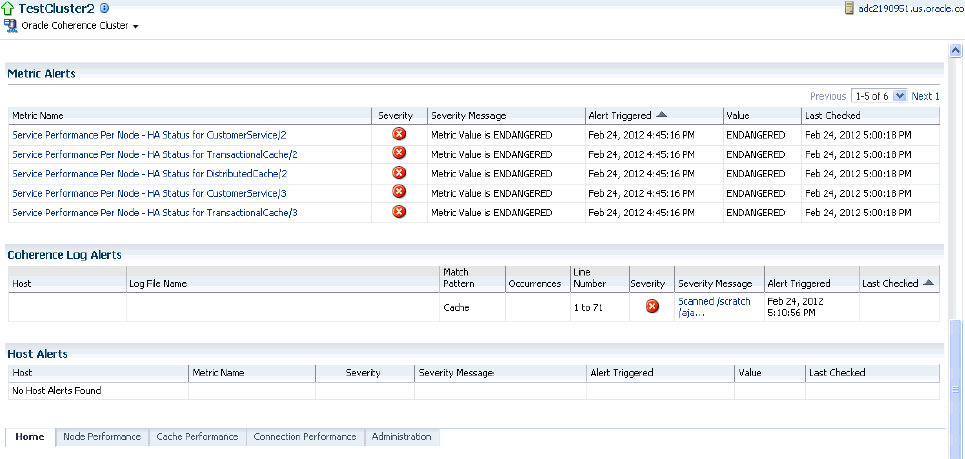
Metric and Host Alerts
This section contains the following details:
Name and status of the cluster.
Availability%: This is really the availability of the cluster management node over the last 24 hours.
Number of Up Nodes: The number of nodes that are Up. Click on the link to drill down to the Selected Nodes Performance page.
Number of Down Nodes: The number of nodes that are Down. Click on the link to drill down to the Down Nodes page.
Storage Enabled Nodes: Indicates the number of nodes that are storage enabled.
Number of Weak Nodes: The number of nodes that are weak and have communication and performance issues. Click on the link to drill down to the Node Performance page.
Weakest Node: The weakest node in the cluster. Click on the link to drill down to the Node Home page.
Node with Max Queue Size: Indicates the node with the maximum queue size value in the cluster.
Node with Minimum Memory: Indicates the node with the minimum available memory in the cluster.
Number of Caches and Objects: The number of caches in the cluster and the number of objects stored in all caches in the cluster. Click on the Number of Caches link to drill down to the Cache Performance page.
Publisher and Receiver Success Rates: The Publisher and Receiver success rate for this cluster node since the node statistics were last reset.
Management Bean Server Node: This is the management node that contains the Coherence MBeanServer. Click on the link to drill down to the Node Home page.
Monitoring Agent: The Oracle Management Agent monitoring the cluster.
MBean Server Host: The host on which the management node is running. If the node on the MBean Server Host is not accessible, the monitoring capability of the entire cluster will be affected. To avoid this, we recommend that at least two management nodes are running on the cluster. If a management node departs from the cluster, you must update the host and port target properties to point to the host with the running management node.
License Mode: The license mode that this cluster is using. Possible values are Evaluation, Development or Production.
Product Edition: The product edition that this cluster is running on. Possible values are: Standard Edition (SE), Enterprise Edition (EE), Grid Edition (GE).
Version: The Coherence version.
Graphs indicating the health of the cluster are displayed here. The following graphs are displayed:
Nodes Uptime: This graph displays groups of nodes according to their uptime. The Node Uptime is calculated as the difference between the Current Time and the Node Timestamp. Nodes that have an uptime of less than a minute are displayed in the seconds bar, nodes with an uptime of less than a hour are displayed in the minutes bar and so on.
Caches with Lowest Hits to Gets Ratio: This graph shows caches (up to a maximum of 5) that have lowest Hits to Gets ratio. Click on the cache name in the legend section to drill down in to the Cache Details page to further investigate the reasons for the low hits to gets ratio.
Note:
The data in the General and Graphs section will be refreshed after one collection interval.In this section, you can start and stop one or more nodes, or stop a cluster.
Prerequisites
To perform Cluster Management operations, you must ensure that:
The hosts on which the nodes are going to be started or stopped must be monitored targets in Enterprise Manager.
The Coherence nodes are started with -Dtangosol.coherence.machine and -Doracle.coherence.machine Java options and the names match the host names monitored by Enterprise Manager.
The Coherence nodes are started with -Doracle.coherence.startscript and -Doracle.coherence.home Java options.
The oracle.coherence.startscript option specifies the absolute path to the start script needed to bring up a Coherence node. All customizations needed for starting this node should be in this script. The oracle.coherence.home option specifies the absolute path to the location in which the coherence folder is present which is $INSTALL_DIR/coherence. This folder contains Coherence binaries and libraries.
Preferred Credentials have been setup for all hosts on which Cluster Management operations are to be performed.
You can do the following:
Start New Nodes: You can start one or more nodes based on an existing node. The new node will have the same configuration as the existing node.
Stop Nodes: You can stop all the nodes on a specific host.
Stop Cluster: You can stop an entire cluster if all the hosts are managed by Enterprise Manager Cloud Control.
Note:
You can set up a corrective action to start departed Coherence Nodes automatically. When a node departs, this corrective action is launched, and the new node is automatically started on the same host on which the node was previously running.oracle.coherence.startscript: The absolute path to the start script needed to bring up a Coherence node. All customizations needed for starting this node should be in this script.
oracle.coherence.home: The absolute path to the location in which the coherence folder is present which is $INSTALL_DIR/coherence. This folder contains Coherence binaries and libraries.
This section shows all the services in the cluster. You can view the type of service, status of the service (Machine-Safe, Node-Safe, and Endangered), the number of nodes supporting the service, storage enabled nodes, endangered nodes, and active transactions.
This section shows the applications that use this Coherence cluster to cache their HTTPSession Objects. You can view details of the Local Cache, Overflow Cache, and Servlet Context Cache.
This section lists the alerts from various entities in the cluster such as services, connections and connection managers, along with their severity and the date on which the alert was triggered. The alerts are generated based on the thresholds defined in the Metrics Collection file. To configure these threshold values, select the Monitoring menu option from the Oracle Coherence Cluster and select the Metric and Collection Settings submenu. Refer to the Enterprise Manager Online Help for detailed information on the parameters displayed in the screen.
From the Cluster Home page, you can several other operations such as:
Viewing The Performance Summary: From the Oracle Coherence Cluster menu, select Monitoring, then select Performance Summary. You can view the performance of the cluster on this page.
Metric and Collection Settings: From the Oracle Coherence Cluster menu, select Monitoring, then select Metric and Collection Settings. You can set up corrective actions to add nodes and caches as Enterprise Manager targets.
Refreshing Cluster: From the Oracle Coherence Cluster menu, select Refresh Cluster. You can refresh a cluster to synchronize Coherence targets in Enterprise Manager with a running cluster.
Coherence Node Provisioning: From the Oracle Coherence Cluster menu, select Coherence Node Provisioning. You can deploy a Coherence node across multiple targets in a farm. See Oracle Enterprise Manager Lifecycle Management Administrator's Guide for more details on Coherence Node Provisioning.
Last Collected Configuration: From the Oracle Coherence Cluster menu, select Configuration, then select Last Collected. You can view the latest or saved configuration data for the Coherence cluster.
Topology: From the Oracle Coherence Cluster menu, select Configuration, then select Topology. The Configuration Topology Viewer provides a visual layout of the Coherence deployment.
JVM Diagnostics: From the Oracle Coherence Cluster menu, select JVM Diagnostics to view the JVM Pool Performance Diagnostics page.
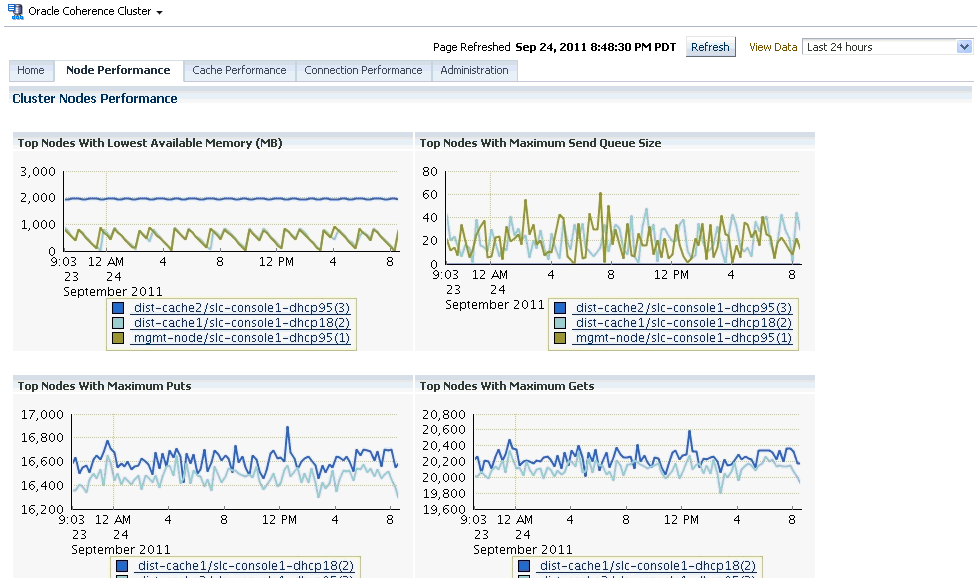
This page displays the node related performance over a specified period of time. Click the Node Performance tab to view this page.
This page displays the performance of all the nodes in the cluster over a specified period of time. You can see charts showing upto 5 top nodes with lowest available memory, maximum send queue size, maximum puts, and maximum gets. By default, you can see the average performance metrics for the last 24 hours in all the Performance pages. To view the real time charts, select one of the Real Time options in the View Data drop-down list in any of Performance pages. Using the View Data options, you can also view the average performance metrics for the last 7 or 31 days.The Node Performance page tab shows the performance of all nodes in this cluster. If you click on a link that shows multiple nodes like weak nodes, storage nodes, etc., the performance of the selected nodes will be displayed on this page. You can toggle between the two modes to see the performance of the selected nodes or all the nodes.
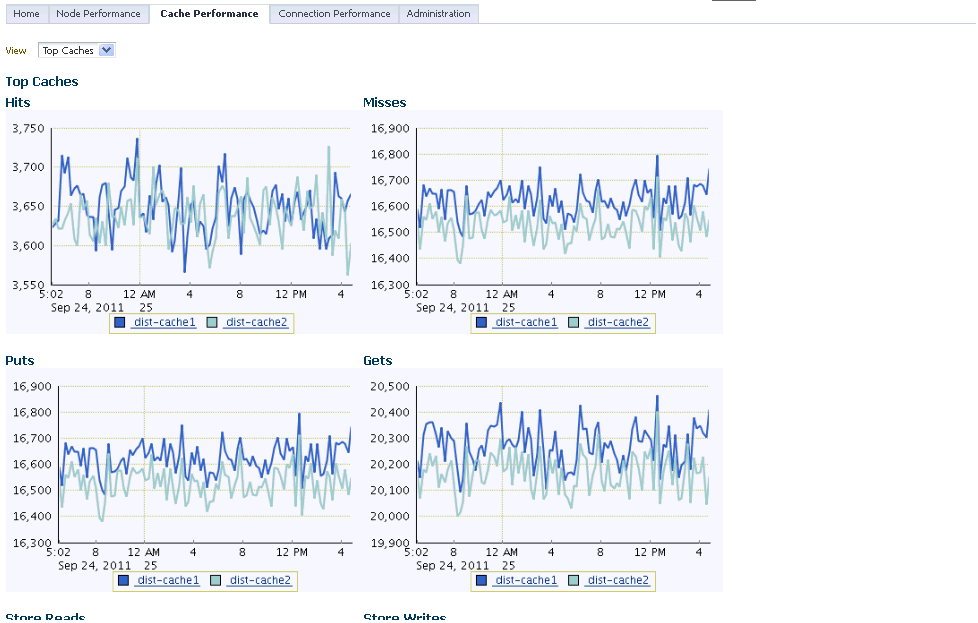
This page displays the cache related performance over a specified period of time. You can view the performance of the top caches or all the caches.
Select the All Caches option from the drop-down list to view the performance of all the caches in the cluster. If you select the All Caches option, you can see the total and average metric values over the selected period of time.
This page shows the performance of all connection managers and connections in the cluster. The following Connection Manager graphs are displayed:
Top Connection Managers with Most Bytes Sent since the connection manager was last started.
Top Connection Managers with Most Bytes Received since the connection manager was last started.
A table with the list of Connection Managers is displayed with the following details:
Connection Manager: This is the name of the connection manager. It indicates the Service Name and the Node ID where the Service Name is the name of the service used by this Connection Manager. Click on the link to drill down to the Connection Manager Home page.
Service: The name of the service. Click on the link to drill down to the Service Home page.
Node ID: An ID is automatically assigned to any node that is part of the cluster.
Bytes Sent: The number of bytes sent per minute.
Bytes Received: The number of bytes received per minute.
Outgoing Buffer Pool Capacity: The maximum size of the outgoing buffer pool.
Outgoing Byte Backlog: The number of outgoing bytes in the backlog.
The following Connection related graphs are displayed:
Top Connections with Most Bytes Sent since the connection was last started.
Top Connections with Most Bytes Received since the connection was last started.
A table with the list of connections is displayed. Click on the link to drill down to the Details page.
Remote Client: The host on which this connection exists.
Up Since: The date and time from which this connection is running.
Connection Manager: This is the name of the connection manager. Click on the link to drill down to the Connection Manager Home page.
Service: The name of the service. Click on the link to drill down to the Service Home page.
Node ID: An ID is automatically assigned to any node that is part of the cluster.
Bytes Sent: The number of bytes sent per minute.
Bytes Received: The number of bytes received per minute.
Connection Time: The connection time in minutes.
Outgoing Message Backlog: The number of outgoing messages in the backlog.
Outgoing Byte Backlog: The number of outgoing bytes in the backlog.
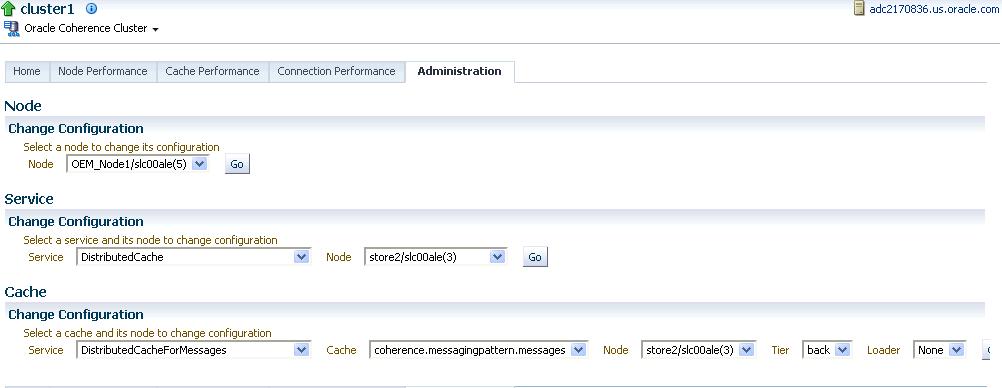
This page allows you to change the configuration of nodes, caches, and services.
On this page, you can select an entity (node, cache, or service) for which the configuration needs to be modified and click Go. The Change Configuration page is displayed. Enter the new values and click Update to save the values and return to the Coherence Cluster Administration page.
From the cluster level pages, you can click on any hyperlink and drill down to the detailed home pages of each entity in the cluster. Hyperlinks from one entity allow you to go to another entity. For example, you can view all the nodes of a cache in the Cache Detailed page, identify the node that is not contributing well for this cache, click on the node hyperlink and drill down to the Node Detailed page for further investigation.
Viewing The Performance Summary: From the Oracle Coherence Node or Oracle Coherence Cache menu, select Monitoring, then select Performance Summary. You can view the performance of the node or cache on this page.
Metric and Collection Settings: From the Oracle Coherence Node or Oracle Coherence Cache menu, select Monitoring, then select Metric and Collection Settings.
Last Collected Configuration: From the Oracle Coherence Node or Oracle Coherence Cache menu, select Configuration, then select Last Collected. You can view the latest or saved configuration data for the Coherence cluster.
Topology: From the Oracle Coherence Node or Oracle Coherence Cache menu, select Configuration, then select Topology. The Configuration Topology Viewer provides a visual layout of the relationship of the Coherence cluster with other targets.
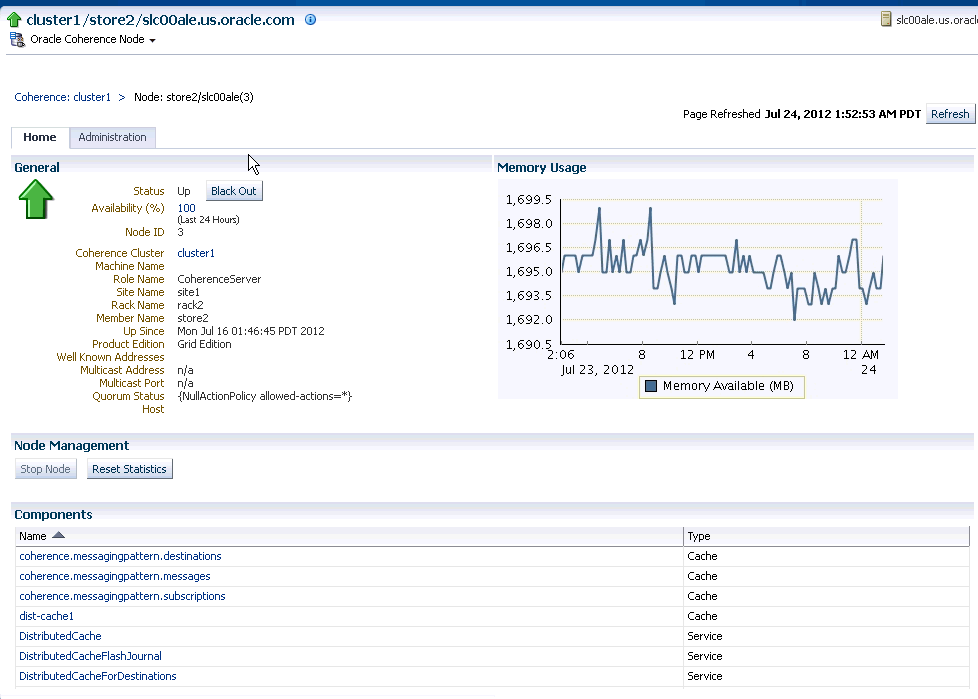
This page shows the details and controls of a specific selected node in the Coherence cluster.
This page contains the following sections:
General
Node ID: When a node becomes part of a cluster, an ID is automatically assigned to the node. This ID can be a new number or the number that was assigned to a Departed Node.
Machine Name: The name of the machine on which the node is running.
Note: You must set the machine name property when a node is started. To set the machine name, set the -Dtangosol.coherence.machine=HOST_NAME flag in the start coherence script. The HOST_NAME is the complete name of the machine on which the node is running. This allows you to associate the machine name with the Host Details page. See the Coherence documentation for more details on setting this flag.
Role Name: The role could be storage/data, application/process, proxy or management node.
Site Name: This indicates the location of the coherence node.
Rack Name: Name of the rack where the machine is located.
Member Name: The unique name assigned to the Member.
Process Name: Indicates the name of the process on which the node is hosted.
Up Since: The date and time from this node has been up and running.
Product Edition: The product edition this Member is running. Possible values are: Standard Edition (SE), Enterprise Edition (EE), Grid Edition (GE).
Well Known Addresses: If cluster communication has been set to WKA (well known address), the host name and port number are displayed.
Multicast Port / Address: The IP address and port number of the Multicast Socket used for group communication.
Quorum Status: The current Quorum state.
Host: Click on the host name to drill down to the Host Home page.
Memory Usage: The maximum memory and the available memory on this node are displayed as line graphs.
Node Management: In this section, you can click Stop Node to stop this node and click Reset Statistics to reset all the statistics for this node. See Prerequisites in Cluster Management.
Components: The list of components and the type of each component in the cluster are displayed here. Click on the link to drill down to the Component Home page.
Metric Alerts: This table shows a list of all the metric alerts specific to this node.
Host Alerts: This table shows a list of alerts from the host on which this node is running.
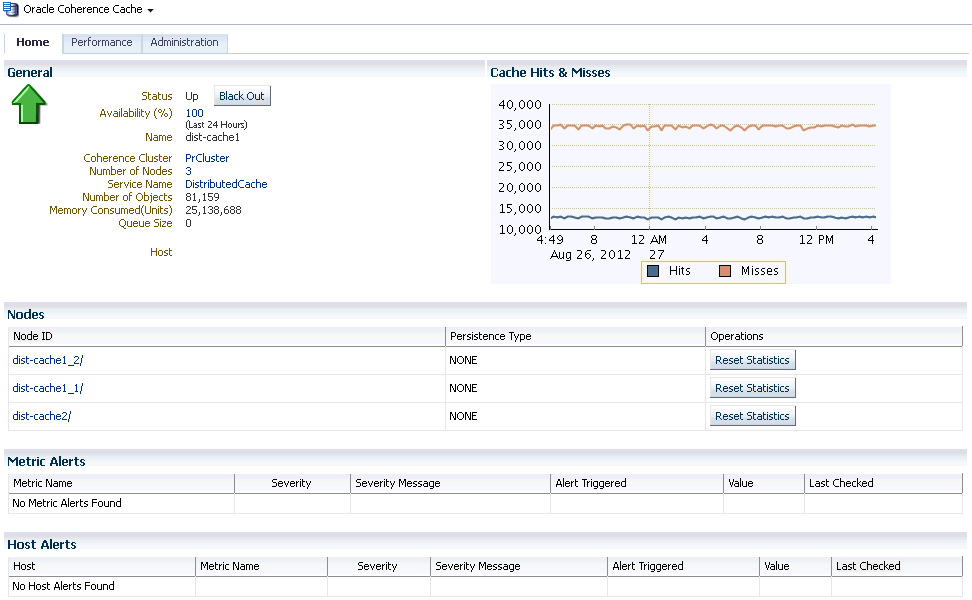
This page shows the details of the specific selected cache in the Coherence cluster.
This page contains the following sections:
General
Status: Indicates the status of the cache.
Availability: The percentage of time that the management agent was able to communicate with the cache. Click the percentage link to view the availability details for the past 24 hours.
Name: The unique name assigned to the cache.
Coherence Cluster: The name of the cluster. Click on the link to drill down to the Cluster Home page.
Number of Nodes: The number of nodes on which the cache is running. Click on the link to drill down to the Node Home page.
Service Name: The name of the service used by this cache.
Number of Objects: Shows the number of objects in the cache.
Memory Consumed: The amount of memory used by the cache in units.
Queue Size: The size of the write-behind queue size. Applicable only for WRITE-BEHIND persistence type.
Cache Hits and Misses: This graph displays the total cache hits and misses per minute.
Nodes: This section lists all the nodes supporting this cache.
Node ID: The ID number assigned to the node. Click on the link to drill down to the Node Home page.
Persistence Type: The persistence type for this cache. Possible values include: NONE, READ-ONLY, WRITE-THROUGH, WRITE-BEHIND.
Metric Alerts: This table shows a list of all the metric alerts specific to this cache.
Host Alerts: This table shows a list of alerts from the host on which this cache is running.
Push Replication Tables: If a push replication enabled cache is present in your cluster, you can see the Publisher and Subscriber tables.
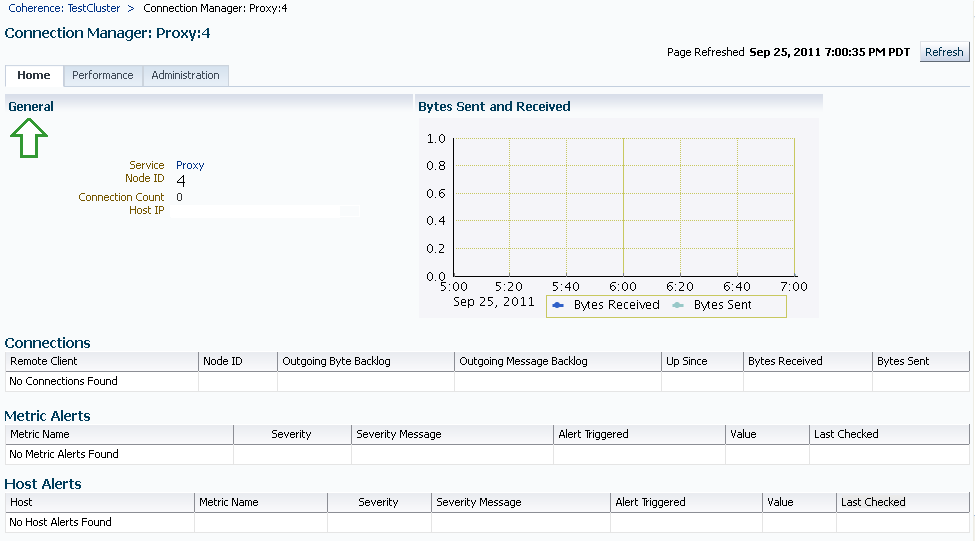
Use this page to view the details and controls of a Connection Manager instance in the Coherence cluster.
This page contains the following sections:
General
Service Name: The unique name assigned to the service.
Node ID: An ID is automatically assigned to any node that is part of the cluster. This can be a new number or a number that belongs to a Departed node.
Connection Count: The number of connections associated with the connection manager instance.
Host IP: The IP address of the host machine.
Refresh Time: The date and time on which the connection manager instance was last refreshed.
Bytes Sent and Received: This graph displays the number of bytes that were sent and received per minute. Click on the graph to drill down to the Bytes Sent Metric page.
Connections
Remote Client: A unique hexadecimal number assigned to each connection.
Service Name: The unique name assigned to the service.
Node ID: An ID is automatically assigned to any node that is part of the cluster. This can be a new number or a number that belongs to a Departed node.
Outgoing Byte Backlog: The number of outgoing bytes in the backlog.
Outgoing Message Backlog: The number of outgoing messages in the backlog.
Up Since: The date and time from which the connection manager instance is up.
Bytes Received: The number of bytes received per minute.
Bytes Sent: The number of bytes sent per minute.
Metric Alerts: This table shows a list of all the metric alerts specific to this connection manager.
Host Alerts: This table shows a list of alerts from the host on which this connection manager instance is running.
Entity level performance pages give detailed views of the performance of this particular entity. For caches performance pages, there are two views - Charts and Metrics. You can select the option from the View drop-down list.
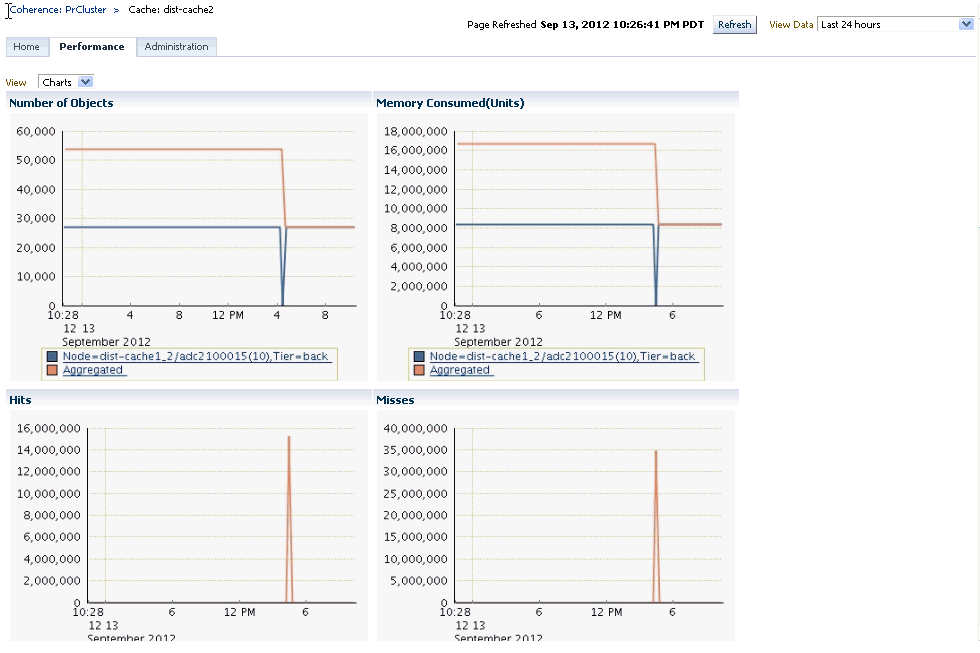
This page displays the performance of a specific cache over a specific period of time. You can view charts showing the number of cache hits, misses, store reads, and store writes. You can also see the aggregated totals and average metric values over the selected period of time.
The following graphs are displayed:
Number of Objects: This graph shows the number of objects in the cache.
Memory Consumed (Units): This graph shows the amount of memory consumed by the cache per minute.
Hits: This graph shows the number of cache hits per minute.
Misses: This graph shows the number of cache misses per minute.
Puts: This graph shows the total number of put() operations per minute.
Gets: This graph shows the total number of get() operations per minute.
Store Reads: This graph shows the total number of load operations per minute.
Store Writes: This graph shows the total number of store and erase operations per minute.
Published Batches (per min)
Replicated Entries
Publishing Failures (per min)
Metrics: Select the Metrics option in the View By drop-down list to view the totals and averages for the cache.
Totals / Averages: The aggregated total and average values across all nodes and per node total / average values for the cache during the selected period are displayed.
Hits: The number of successful fetches of the cached objects per minute.
Misses: The number of failed fetches of the cached objects per minute.
Puts: The number of addition of objects to a cache per minute.
Gets: The number of retrieval of objects from a cache per minute.
Prunes: The number of prune operations on the cache per minute. A prune operation occurs every time the cache reaches its high watermark.
Store Reads: The number of reads from a data store per minute.
Store Writes: The number of writes to a data store per minute.
Number of Objects: The number of objects in the cache.
Memory Consumed (Units): The amount of memory used by the cache in units.
Average Time (ms): The average execution time for each operation (hits, misses, puts, gets, store reads, and store writes) are displayed. The values since the last collection divided by the time taken by the operations are displayed. For example, if there are 100 Hits and these 100 Hits took 20 milliseconds since last collection, this value is calculated as 100/20 = 5.
Storage Manager
Events Dispatched: The total number of events dispatched by the Storage Manager per minute.
Eviction Count: The number of evictions from the backing map managed by this Storage Manager caused by entries expiry or insert operations that would make the underlying backing map to reach its configured size limit.
Insert Count: The number of inserts into the backing map managed by this Storage Manager. In addition to standard inserts caused by put and invoke operations or synthetic inserts caused by get operations with read-through backing map topology, this counter is incremented when distribution transfers move resources into the underlying backing map and is decremented when distribution transfers move data out.
Remove Count: The number of removes from the backing map managed by this Storage Manager caused by operations such as clear, remove or invoke.
Listener Filter Count: The number of listener filters.
Listener Key Count: The number of listener keys.
Listener Registrations: The number of listener registrations.
Locks Granted: The number of locks granted.
Locks Pending: The number of locks pending.
This page displays the performance of the selected connection manager over a specified period of time. The following graphs are displayed:
Bytes Sent: This graph shows the number of bytes sent since the connection manager was last started.
Bytes Received: This graph shows the number of bytes received since the connection manager was last started.
Performance:
The average performance over the selected period is displayed.
Outgoing Byte Backlog: The number of outgoing bytes in the backlog.
Outgoing Message Backlog: The number of outgoing messages in the backlog.
Incoming Buffer Pool Capacity: The maximum size of incoming buffer pool.
Incoming Buffer Pool Size: The currently used value of the incoming buffer pool.
Outgoing Buffer Pool Capacity: The maximum size of the outgoing buffer pool.
Outgoing Buffer Pool Size: The currently used value of the outgoing buffer pool.
Bytes Received: The number of bytes received per minute.
Bytes Sent: The number of bytes sent per minute.
This page displays the performance of the specific connection over a specified period of time. The following graphs are displayed:
Bytes Sent: This graph shows the number of bytes sent within the specified period.
Bytes Received: This graph shows the number of bytes received within the specified period.
Performance
Remote Address: The IP address of the remote machine from which the bytes are being received.
Remote Port: The port number of the remote machine from which the bytes are being received.
Up Since: The date and time from which the connection has been up and running.
Bytes Received: The number of bytes received per minute.
Bytes Sent: The number of bytes sent per minute.
Total Messages Received: The total number of messages received per minute.
Total Messages Sent: The total number of messages sent per minute.
This page displays the performance of the selected service over a specific period of time. The Request Average Duration and the Request Max Duration charts are displayed. You can also see the average metric values over the selected period of time.
Enterprise Manager can monitor log files for the occurrence of user specified patterns to check for abnormal conditions. Matching patterns are specified as regular expressions. Log files are periodically scanned for occurrence of one or more patterns and an alert is raised when the pattern occurs during a given scan.
You can set up each Coherence node to log all messages into a log file on the host on which the node is running. You must use a specific naming pattern in the log file name to ensure that it is monitored. To configure the log file monitoring criteria, follow these steps:
From the Targets menu, select Middleware, then click on a Coherence node target.
Navigate to the Administration page of the node for which the Log file alerts need to be configured.
Click the Log Alert Setup link. The Metric and Policy Settings page of the host on which the Coherence node is running is displayed.
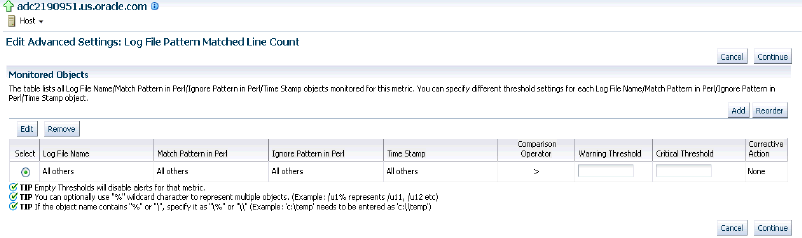
Select Metric with Thresholds in the View drop-down box and search for the Log File Pattern Matched Line Count metric.
Click the pencil icon in this row to navigate to the Edit Advanced Settings: Log File Pattern Matched Line Count page.
Click Add to add a row to the Monitored Objects table.
In the Log File Name field, specify the name in the format <coherence_cluster_target_name>_<Node_name>_<....any other optional names>.log. All node log file names must follow this format.
Specify the pattern to be matched for or ignored in the Match Pattern in Perl and Ignore Pattern in Perl fields. Lines matching the ignore pattern will be ignored first, then lines matching specified match patterns will result in one record being uploaded to the repository for each pattern.
Enter the Critical and Warning thresholds for this metric and click Continue. You will return to the Metrics and Collection Settings page. Click OK to update the metric.
Any alerts generated will be displayed in the Coherence Log Alerts section in the Cluster Home page.
The Cache Data Management feature allows you to define indexes and perform queries against currently cached data that meets a specified set of criteria.
Note:
This feature is available to users with Administration privileges only if the Cache Data Management MBean has been registered in the Coherence JMX management node.To perform cache data management operations, navigate to the Cache target Administration page and click Go in the Cache Data Management section. In the Cache Data Management page, you can select an operation and a query to perform a data management operation on the cache. You can perform the following operations:
Add Indexes: To create an index, select the Add Index option in the Operation field. In the Value Extractor List field, specify a comma separated list of expressions that identify the index, and enter the Host Credentials. The Value Extractor is used to extract an attribute from a given object for indexing.
Remove Indexes: To remove an index, select the Remove Index option in the Operation field and specify the Value Extractor List that identifies the index. Specify the Host Credentials and click Execute to remove the index from the cache.
Export: You can export the queried data onto a file. Select a query from the Query section or click Create to create a new query. Select the Export option in the Operation field and enter the absolute path to the file. This file can be saved on the host machine on which the management node is running.
Import: You can import queried data from a file. This file should be present on the host machine on which the management node is running. Select the Import option in the operation field and enter the absolute path to the file.
Insert: Select the Insert option in the Operation field and specify an unique (key value) pair. This key value pair will be inserted into the cache and can be provided from:
UI Table on this Page: Select the Type of Keys and Type of Values and the Host Credentials.
Text File on Management Host: If the queries are stored in a text file, select this option and specify the location of the file.
Database Table: If the queries are stored in a database table, specify the Database URL, Credentials, the SQL Query Statement and Properties.
Purge: Select Purge from the Operation drop-down list. Data matching the selected query will be deleted from the cache
View: Select View from the Operation drop-down list and specify the number of key-value pairs to be displayed on each page. Data matching the criteria will be displayed.
Update: Select Update from the Operation drop-down list. Specify the credentials for the host. Select a query from the Query table or create a new query to update the data in the cache.
View Explain Plan: Select View Explain Plan from the Operation drop down list. Select a query that is to be evaluated from the Query table. See View Explain page for details.
View Trace: Select View Trace from the Operation drop down list. Select a query that is to be evaluated from the Query table. See View Trace page for details.
A query explain record provides the estimated cost of evaluating a filter as part of a query operation. The cost takes into account whether or not an index can be used by a filter. The cost evaluation is used to determine the order in which filters are applied when a query is performed. Filters that use an index have the lowest cost and get applied first.The View Explain Plan option allows you to estimate the cost of evaluating a filter as part of a query operation. When you select this option, a query record containing details of each step in the query is displayed. After viewing the details, click Execute to perform the selected operation or Return to return to the previous page.
The View Trace option allows you to view the actual cost of evaluating a filter as part of a query operation. When you select this option, a query is executed in the cluster and a query record containing details of each step in the query is displayed. After viewing the details, click Execute to perform the selected operation or click Return to return to the previous page.
HTTPSession Objects for one or more Java EE applications deployed on Application Servers can be cached in the Coherence cluster. These HTTP sessions are cleaned by the Session Reaper and the associated memory is freed up. The Session Reaper is responsible for destroying any sessions that are no longer used, which is determined when the session has timed out. It is configured to scan the entire set of sessions over a certain period of time, called the reaping cycle. The Session Reaper scans for sessions that have expired, and when it finds expired sessions it cleans them up.
To view the reap session metrics, click the Application link in the Applications table in the Cluster Home page. The following reap session metrics and graphs are displayed in the Application Home page.
Reap Duration: This graph shows the average reap duration in minutes.
Reaped Sessions: This graph shows the average number of reaped sessions in a reap cycle.
Reaped Sessions (24 Hour Averages): This table shows the average reap session data over the last 24 hours. The following details are displayed:
Module Name: The name of the Coherence cluster on which the HTTP sessions have been cached.
Node ID: When a node becomes part of a cluster, an ID is automatically assigned to the node. Click on the link to drill down to the Node Home page.
Average Reap Duration: The average reap duration since the statistics were last reset.
Average Reaped Sessions: The average number of reap sessions since the statistics were last reset.
Total Reaped Sessions: The total number of expired sessions that have been reaped since the statistics were last reset.
The Push Replication Pattern provides extensible, flexible, high-performance, highly available, and scalable infrastructure to support the replication of EntryOperations occurring in one Coherence Cluster to one or more globally distributed Coherence clusters. The Push Replication Pattern advocates that:
Operations (such as insert, update and delete) occurring on data in one Site should be pushed using one or more Publishers to an associated device.
A Publisher is responsible for optimistically replicating operations (in the order in which the said Operations originally occurred) on or with the associated device.
If a device is unavailable for some reason, the operations to be replicated using the associated Publisher will be queued and executed (in the original order) at a later point in time.
Implementation of the Push Replication Pattern additionally advocates that:
The data on which operations occur are standard Coherence cache entries.
Operations replicated include inserts, updates, and deletes of cache entries. This includes NamedCache put and remove, as well as updates that are artifacts of invoking AbstractProcessor.
The operations that are enqueued for replication are called EntryOperations. They contain key and value pairs of updated cache entries in Binary form.
A Site is a Coherence Cluster.
A Site may act as both a sender of Operations and receiver of Operations. That is, multi-way multi-site push replication is permitted.
A Device may be any of the following; a local cluster, a remote cluster, a file system, a database, an i/o stream, a logging system etc.
After the EntryOperations are captured, they are sent to the messaging layer, for distribution to the Subscribers. The Publishers then publish the currently queued EntryOperations.
The Publisher and Subscriber tables lists all the publishers and subscribers and displays the data used by them. You can Suspend, Drain, or Resume publishing operations on a specific Publisher.
Transactional caches are specialized distributed caches that provide transactional guarantees. Transactional caches are required whenever performing a transaction using the Transaction Framework API. Transactional caches cannot interoperate with non-transactional caches.
The CacheMBean managed resource provides attributes and operations for all caches, including transactional caches. Many of the MBeans attributes are not applicable to transactional cache; invoking such attributes simply returns a -1 value. A cluster node may have zero or more instances of cache managed beans for transactional caches. The object name uses the form:
type=Cache, service=service name, name=cache name, nodeId=cluster node's id
The following list describes the CacheMBean attributes that are supported for transactional caches.
AverageGetMillis: The average number of milliseconds per get() invocation.
AveragePutMillis: The average number of milliseconds per put() invocation since the cache statistics were last reset.
HighUnits: The limit of the cache size measured in units. The cache will prune itself automatically once it reaches its maximum unit level. This is often referred to as the high water mark of the cache.
Size: The number of entries in the current data set.
TotalGets: The total number of get() operations since the cache statistics were last reset.
TotalGetsMillis: The total number of milliseconds spent on get() operations since the cache statistics were last reset.
TotalPuts: The total number of put() operations since the cache statistics were last reset.
TotalPutsMillis: The total number of milliseconds spent on put() operations since the cache statistics were last reset.
JVM Diagnostics allows administrators to identify the root cause of performance problems in the production environment without having to reproduce them in the test or development environment. JVM Diagnostics is a part of WLS Management Pack EE.
You can drill down to a Coherence node's JVM to identify the method or thread that is causing a delay. This feature allows you to trace live threads, identify resource contention related to locks, and trace the Java session to the database.
You can view the JVM Diagnostics data if the JVM Diagnostics Manager and JVM Diagnostics Agent have been deployed on the host machine on which the OMS running. You can deploy the JVM Diagnostics Manager and JVM Diagnostics Agent on:
Standalone Coherence
CoherenceWeb
To setup JVM Diagnostics on each Coherence node you need to download the JVM Diagnostics Agent. For more details, see Oracle Enterprise Manager Cloud Control Advanced Installation and Configuration Guide.
You can use the Performance Summary page to monitor the performance of the cluster, a node, or a cache. From the Oracle Coherence Cluster (Node or Cache) menu, select Monitoring, then select Performance Summary.
A set of default performance charts that shows the values of specific performance metrics over time are displayed. You can customize these charts to help you isolate potential performance issues. You can also view a series of regions specific to the cluster, node, or cache target. For more details, see the Performance Summary Online Help.
The Configuration Topology Viewer provides a visual layout of the relationship of the Coherence target with other targets. From the Oracle Coherence Cluster (Node or Cache) menu, select Configuration, then select Topology. A topology graph for the Coherence target is displayed. You can determine the source of its health problem and its impact on other targets. You can also view the members of the cluster and its relationships. For more details, see the Configuration Topology Viewer Online Help.
If you cannot collect metric data for any of the Coherence targets, check the following to ensure that the steps involved in discovering the target have been followed correctly.
Make sure that the management node has been successfully started and the host on which the management node is running is accessible from the Agent host.
Specify the appropriate User Name and Password if password authentication is enabled.
If you are not using SSL to start the management node, make sure that you have started the JVM using the com.sun.management.jmxremote.ssl=false option.
If you did not use the bulk operation MBean JAR to start the management node, you must leave the Bulk Operations Mbean field blank during discovery.
In this section, you can see some sample code snippets that show you how to use the JVM Diagnostics to start a management node or a storage enabled node.
You must ensure that:
The Management Agent has been deployed on every machine on which the Coherence node is running.
Garbage Collection has been enabled on the nodes.
Heap utilization on the node does not exceed 70%.
The Discover Corrective Action must be set up on the new nodes and caches.
The caches must be preconfigured on the node to ensure that Enterprise Manager can easily establish associations during discovery.
Reusable monitoring templates that can be applied on multiple targets must have been created.
The node has been refreshed after it has been restarted. To refresh the node, from the Coherence Cluster menu, select Configuration, then select Last Collected. In the Latest Configuration page, from the Actions menu, select Refresh to refresh the node.
Example 17-1 Starting a Management Node
JVMD_HOST=<Host_Where_JVMD_Manager_Is_Running> JVMD_PORT=<Port_of_the_JVMD_Manager> JVMD_POOL=Contacts JAM_PARAMS=" jamagent.jamrun jamconshost=$JVMD_HOST jamconsport=$JVMD_PORT jampool=$JVMD_POOL" CP=$CP:<path_where_JAMAgent_is_copied>/jamagent.war: <OEM_Agent_Home>/plugins/oracle.sysman.emas.agent.plugin_ 12.1.0.3.0/archives/coherence/coherenceEMIntg.jar: <OEM_Agent_Home>/plugins/oracle.sysman.emas.agent.plugin_ 12.1.0.3.0/archives/coherence/bulkoperationsmbean.jar CACHE_CONFIG=$CONFIG_DIR/$CACHE_CONFIG_FILE_NAME POF_CONFIG=$CONFIG_DIR/$POF_CONFIG_FILE_NAME COH_OPTS="$COH_OPTS -cp $CP" COH_OPTS="$COH_OPTS -Dtangosol.coherence.cacheconfig=$CACHE_CONFIG" COH_OPTS="$COH_OPTS -Dtangosol.pof.config=$POF_CONFIG" # using non-default port to prevent accidentally joining other clusters COH_OPTS="$COH_OPTS -Dtangosol.coherence.clusterport=<open_port>" $JAVA_HOME/bin/java $COH_OPTS -Dtangosol.coherence.management.remote=true -Dcom.sun.management.jmxremote.authenticate=false -Dtangosol.coherence.management=all -Dcom.sun.management.jmxremote.ssl=false -Dtangosol.coherence.cluster=Contacts -Dtangosol.coherence.member=MNode1 -Dtangosol.coherence.site=MSite -Dtangosol.coherence.rack=MRack -Dtangosol.coherence.machine=<FullyQualifiedHostName_of_localhost> -Doracle.coherence.machine=<FullyQualifiedHostName_of_localhost> -Dcom.sun.management.jmxremote.port=<OpenTCP_Port> -Dtangosol.coherence.distributed.localstorage=false -Doracle.coherence.jamjvmid=Contacts/MNode1 -server -Xms2048m -Xmx2048m $JAM_PARAMS jamjvmid=Contacts/MNode1 oracle.sysman.integration.coherence.EMIntegrationServer $*
where:
The string specified in the JVMD_POOL and -Dtangosol.coherence.cluster should match. This is used to correlate the Coherence Cluster target and the JVM Pool.
The Dtangosol.coherence.member name must be unique. This name is required for JVM Diagnostics integration.
The JVM Diagnostics integration parameters are:
-Doracle.coherence.jamjvmid - <JVM_pool_name>/<member_name>
Jamjvmid - <JVM_pool_name>/<member_name>
Example 17-2 Starting a Storage Node
JVMD_HOST=<Host_Where_JVMD_Manager_Is_Running> JVMD_PORT=<Port_of_the_JVMD_Manager> JVMD_POOL=Contacts JAM_PARAMS=" jamagent.jamrun jamconshost=$JVMD_HOST jamconsport=$JVMD_PORT jampool=$JVMD_POOL" CP=$CP:<path_where_JAMAgent_is_copied>/jamagent.war CACHE_CONFIG=$CONFIG_DIR/$CACHE_CONFIG_FILE_NAME POF_CONFIG=$CONFIG_DIR/$POF_CONFIG_FILE_NAME COH_OPTS="$COH_OPTS -cp $CP" COH_OPTS="$COH_OPTS -Dtangosol.coherence.cacheconfig=$CACHE_CONFIG" COH_OPTS="$COH_OPTS -Dtangosol.pof.config=$POF_CONFIG" # using non-default port to prevent accidentally joining other clusters COH_OPTS="$COH_OPTS -Dtangosol.coherence.clusterport=<cluster_port>" $JAVA_HOME/bin/java $COH_OPTS -Dtangosol.coherence.cluster=Contacts -Dtangosol.coherence.member=SNode1 -Dtangosol.coherence.management.remote=true -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dtangosol.coherence.machine=<FullyQualifiedHostName_of_localhost> -Doracle.coherence.machine=<FullyQualifiedHostName_of_localhost> -Dtangosol.coherence.log.level=5 -Dtangosol.coherence.log=<path_log_file> -Doracle.coherence.jamjvmid=Contacts/SNode1 -server -Xms2048m -Xmx2048m $JAM_PARAMS jamjvmid=Contacts/SNode1 com.tangosol.net.DefaultCacheServer $*
|
Copyright © 2011, 2012, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|