| Oracle® Enterprise Manager Cloud Control Getting Started with Oracle Fusion Middleware Management 12c Release 2 (12.1.0.2) Part Number E24215-03 |
|
|
PDF · Mobi · ePub |
| Oracle® Enterprise Manager Cloud Control Getting Started with Oracle Fusion Middleware Management 12c Release 2 (12.1.0.2) Part Number E24215-03 |
|
|
PDF · Mobi · ePub |
The Enterprise Manager Application Dependency and Performance (ADP) capabilities automatically select performance metrics and track contextual relationships for various applications. The methodology focuses on other important activities to allow you to setup and maintain an effective application performance monitoring environment.
These activities include the following:
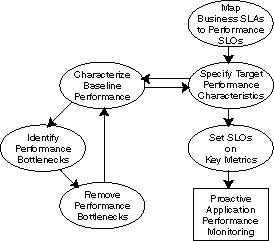
This methodology describes a series of steps for users to establish and maintain a proactive application performance monitoring environment leveraging the Enterprise Manager Application Dependency and Performance capabilities. Figure 24-1 illustrates these steps in a sequential order.
Map business Service Level Agreements (SLAs) to performance Service Level Objectives (SLOs).
The process of using agreed business SLAs to determine the value of performance SLOs.
Specify target performance characteristics.
Specify the ideal application performance characteristics using performance SLOs identified in step 1.
Characterize baseline performance.
Identify performance bottlenecks.
Remove performance bottlenecks.
Steps 3, 4, and 5 should be grouped together to form a process of incremental performance improvement. Iterations of this process may be required to improve the application performance to meet the performance target as specified in step 2.
Set SLOs on key metrics.
Once application performance reaches the targeted goal, you need to set performance SLOs on key metrics to establish a proactive monitoring environment. This environment provides you with warnings when key performance metrics start to report abnormalities. These warnings enable you to proactively solve potential problems before they begin to impact business.
This chapter explains the following activities in more detail:
The ADP methodology activities include the following:
To successfully setup a proactive application performance monitoring environment, the first step is to map a set of business objectives to a set of performance thresholds for you to monitor. These business objectives are often referred to as business service level agreements (SLAs). These business SLAs provide the basic application performance requirements at a high level. As such, mapping these high level SLAs to low level performance thresholds is often a very difficult activity to do well.
Using tools that only measure performance at technology levels (EJB, JSP, servlet, portlet, SQL calls, and so on) to perform this type of activity continues to be very difficult as the correlations between low-level metrics and high-level objectives are often fuzzy at best. Consequently, the mapping activity is considered by many as an art rather than a science.
By measuring performance at both technology and functional levels, Enterprise Manager makes this mapping activity significantly less complicated. Since functional metrics measure performance for high level constructs such as business processes or portal desktops, mapping business SLAs directly to performance SLOs (Service Level Objectives) is straightforward.
Defining the target performance characteristics for the monitored applications is the next step after mapping business SLAs to performance SLOs. Since these SLOs represent absolute minimal performance requirements for these applications, using these violation thresholds as target performance characteristics makes little sense. Instead, you need to define what performance range is acceptable for normal operation and when to send out cautionary alerts for abnormal activities.
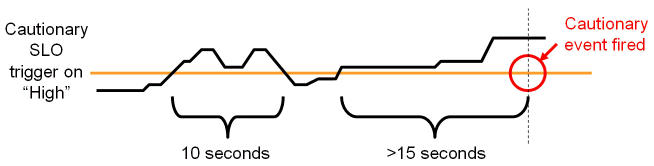
For some applications, it may be sufficient to just specify a set of cautionary performance thresholds. Application performance monitoring tools, such as ADP, will send out cautionary alerts if these thresholds have been breached. Since these thresholds are cautionary, it may be acceptable to have a few violations before an alert is sent out. By defining the minimal violation duration, you can minimize the number of duplicate alerts generated. Figure 24-2 illustrates this concept.
In Figure 24-2, the minimal violation duration is defined to be 15 seconds. So if the cautionary state does not persist for more than 15 seconds, no cautionary alert would be fired.
For other applications, it is necessary to define both a high and low performance thresholds. Having both thresholds would effectively define a normal range of operation for these applications. With ADP, both high and low triggers can be set for any SLO.
With a set of clearly defined target performance characteristics, you are able to determine how much performance tuning is needed to achieve the ideal performance range. You will also have a set of cautionary performance thresholds to enable a proactive application performance monitoring environment to be established.
The activities explained in this section should be grouped together as a single performance improvement process. This process would start with characterizing the baseline performance of our application, move on to identifying performance bottlenecks, and finish with removing performance bottlenecks. We would continue to perform these activities in iterations until the performance of our application meets the target characteristics.
Once the specification of the target performance characteristics is completed, the next activity is to capture the performance baseline for our application. The performance baseline will be compared with the set of target performance characteristics to determine if further performance improvement is needed. If so, you will improve application performance iteratively through the next two steps until the performance meets the target characteristics.
To identify performance bottlenecks, you must first isolate performance abnormalities in your performance baseline. Once you isolate a performance abnormality, you need to determine if this issue is a localized occurrence or a systematic problem. By using monitoring and diagnostic tools available to you, you can perform the analysis needed to identify the cause of the performance bottleneck.
Once these performance bottlenecks are identified, you need to determine how to remove them. The strategies for bottleneck removal vary by cause. A few examples follow:
If the cause of the bottleneck is an application defect, the strategy would involve the application development team.
If the bottleneck is caused by a configuration problem, you would request assistance from system administrators.
If the bottleneck is in the application server or framework, you would seek help from those vendors.
The following is a list of possible bottleneck removal activities:
Change application code to fix defects
Modify environment setting to fix configuration problem
Install patches to fix software defects
Replace defective hardware
Upgrade network infrastructure
Add computing resources
Remove resource hogging programs
Tune back-end connectivity and response time
As you can see from the list, the Remove Performance Bottlenecks activity varies widely by cause. Correctly and quickly finding the appropriate groups to help resolve performance bottlenecks is the key for success for this activity. Once the performance bottleneck removal is completed, you must redo the Characterize Baseline Performance activity to confirm the fix implemented indeed improved performance.
In addition to setting application specific performance thresholds, it is also important to set performance thresholds on key system metrics and on some selective component metrics. Setting these thresholds will help you establish an early warning system and alert you to smaller issues before they manifest into big production problems.
Setting SLOs on key system metrics involves some basic understanding of how the system behaves under load. If the system becomes unstable or performs poorly when it runs out of free JDBC connections or idle ExecuteQueue threads, these system metrics should be monitored.
To determine which system metrics to monitor, it is critical to figure out the correlations between overall system performance and specific system metrics. You would use this information to decide which of the system metrics to monitor. Once appropriate system metrics are identified, you will then determine the performance range for normal operation and figure out the cautionary as well as violation thresholds.
While it is fairly straightforward to determine which system metrics to monitor and what system metric performance thresholds to set, setting SLOs on key component metrics is significantly more difficult. In theory, you can assume performance degradation at the component level would negatively impact application level performance. However, this assumption may not accurately reflect reality.
To predict application performance by monitoring component level performance metrics, there must be a very strong correlation between the performance of a specific component and that of the application. Sometimes, a drop in performance in one component is compensated by a jump in performance in another. These performance changes in opposite directions at the component level would essentially result in little change at the application level. Therefore, you must be careful not to draw conclusions by monitoring the performance of a few components unless there are strong correlations.
The last task to perform is to associate various actions and responses for various threshold violations. Once these associations are completed, you can begin to use your proactive application performance monitoring environment.
One of the primary reasons companies purchase solutions to establish proactive application performance monitoring is the demand to meet business SLAs. Business SLAs for enterprise applications are a set of service level expectations defined by internal or external customers. In most cases, these business SLAs are defined at such a high level, they are not useful for setting thresholds in application performance monitoring tools.
As a result, the process of mapping business SLAs to performance SLOs is extremely important for companies to meet the service requirements set forth by their customers. Since Enterprise Manager monitors performance at both functional and technology levels, it is easy to perform this mapping exercise.
In this section, our example explains how to use the Enterprise Manager Application Dependency and Performance features to determine the proper performance threshold values for a set of business SLAs.
In the example, we were given the following high-level business SLAs:
Table 24-1 Example - Guidelines for Business SLAs
| Business SLA | SLA Requirement |
|---|---|
|
Fast customer self-service portal. |
On average, pages in customer self-service portal should load within 2 seconds. This SLA must be fulfilled 99% of the time. |
|
Customer service representative portal must be as fast as mainframe system. |
All pages in customer service rep. portal must load within 6 seconds. This SLA must be fulfilled 99.9% of the time. |
|
Fast to schedule a service call. |
On average, scheduling a service call should take less than 30 seconds. This SLA must be fulfilled 99.99% of the time. |
Let's map the first business SLA to a performance SLO. This SLA requirement states that the average response time for customer self-service portal (desktop) should be less than 2 seconds. In Enterprise Manager, we would set a high-level performance SLO at the desktop. Using the hierarchy in the ADP UI, you would select the customer desktop and right-click to set the SLO.
Because ADP monitors performance at both functional and technology levels, you can directly translate business SLAs to SLOs on functional metrics. In our example, it is the response time for portal desktop customer. For our example, we would proceed to set a violation SLO and a warning SLO.
We can calculate how often violations occur to figure out whether or not our current system is able to meet the SLA requirement 99% of the time. With Enterprise Manager, we can see whether there are any obvious violations. If there are any violations or close calls, we should confirm by examining actual data. If we have data for at least 24 hours, we would use the export capability within Enterprise Manager Application Dependency and Performance to prepare raw data for this calculation.
For the other two business SLAs, we would set performance SLOs on the appropriate metrics.
Also known as performance base-lining, characterize baseline performance involves a set of activities to capture the baseline performance of a system under specific level of load. For example, you can measure the baseline performance of a portal application deployed to a WebLogic cluster.
For example, you can display the performance data during the first four hours of a load test. The number of active sessions grows at a steady pace for the first ninety minutes. Eventually, the number of active sessions stays at approximately seven hundred as the number of new and expiring sessions reach an equilibrium.
Visualize the portal performance following a typical pattern of slow performance initially and gradually reaching a steady state. The initial slow performance is expected as the application server load components into memory and populates data into its caching mechanism. The performance improves gradually and reaches a steady state after approximately thirty minutes. The performance pattern during this initial thirty-minute period can be characterized as startup performance during increasing load. After thirty minutes, performance of the portal application stabilizes.
Enterprise Manager's ability to quickly establish an application performance monitoring environment allows you to carry out characterize baseline performance painlessly. Because Enterprise Manager is able to monitor at cluster level as well as at individual server level, it can characterize performance for the entire cluster or individual servers.
By verifying that a less loaded server has lower resource utilization and faster performance, you can draw the following observations about the performance characteristics of a portal application running on this environment:
Since Server A's resource utilization is near maximum, we can use the load on that server as the maximum limit for individual servers. We can calculate individual server maximum load limit by using the load metric provided by the Enterprise Manager Application Dependency and Performance features.
We should examine the load balancing algorithm and the configuration of the load balancer.
Comparing load and resource usage of two servers in a cluster confirms resource usage is inversely correlated to the load.
Note:
This is a very basic performance characterization of an individual server. Performance of a multi-server cluster cannot be calculated by multiplying performance characteristics of individual servers because of the overhead involved with a clustered configuration. True cluster level performance must be measured with application performance monitoring tools like Enterprise Manager.Enterprise Manager can also be used to quickly identify performance bottlenecks in QA, staging, and production settings. You can use the hierarchical model within the Enterprise Manager Application Dependency and Performance feature to identify an application performance bottleneck. Furthermore, you can use Enterprise Manager to track down an application performance problem caused by resource starvation.
Since the performance problem seems to affect all components in the same way, we should suspect there is some type of performance degradation at the system level. To view system level performance data, we would look under the Resources hierarchy. Performance metrics under the Resources hierarchy provides the raw data for us to perform correlation analysis. This type of analysis is needed to determine whether resource starvation is the cause of the performance slowdown.
Graphs can reveal some interesting patterns.
OS Agent Abnormalities
We noticed a sudden drop in CPU utilization and a sudden increase in disk utilization during the time period in question. This pattern indicates a large amount of virtual memory paging activities on this machine. Memory paging to disk is extremely expensive and slows down request processing as indicated by lowered CPU utilization. To understand why page is occurring, we will take a look at performance metrics on the JVM.
JVM Heap Size
We noticed that for the initial twelve hours of this example, both total JVM heap size and free JVM heap size grew at a steady pace. The growth of the total JVM heap size stopped at 512 MB - an expected behavior since we configured WebLogic to have a maximum heap size of 512 MB. While we expect the free JVM heap size to stop growing after total heap size reached 512 MB, the free JVM heap size actually starts to drop. Combining this information with some previously obtained information such as no sudden increase in load, we can conclude that there is a high likelihood of a memory leak.
This abnormal consumption of memory caused the total JVM heap to reach its pre-defined maximum. It is also very likely this memory leak caused the increase in virtual memory paging activities and corresponding reduction in CPU utilization. This reduction in CPU utilization impacts the response time for all components running in this machine including JDBC Connections.
Memory Leak
We were able to identify a memory leak in the WebLogic JVM gradually caused resource starvation and eventually impacts application performance. In order to further diagnose this problem, a deep-level memory profiling tool is required to understand memory usage of the JVM.
This step in the Oracle Methodology allows you to proactively monitor key system metrics to avoid catastrophic failures such as server hangs (non-responsive), server crashes, cluster hangs, and more. The ability to recognize signs leading up to these catastrophic failures is a must to maintain quality of service for your WebLogic infrastructure.
You can proactively set thresholds and actions for key WebLogic system metrics. Table 24-2 lists the key system metrics for the WebLogic Platform:
Table 24-2 List of Key System Metrics for WebLogic
| Key System Metric | Reason to Monitor |
|---|---|
|
ExecuteQueue Idle Thread Count |
Running out of ExecuteQueue threads is often a precursor to application server hangs (non-responsive). In some severe cases, when the application server runs out of ExecuteQueue threads, all of its operations would stop working. |
|
ExecuteQueue Pending Request Count |
A steady increase in the number of ExecuteQueue pending requests is also a precursor to server hangs. This metric is inversely correlated with the ExecuteQueue Idle Thread Count metric. |
|
Total JVM Heap Size |
There are two reasons to monitor this metric:
|
|
Free JVM Heap Size |
A steady decrease in the free JVM heap size is an indicator of either a memory leak or misconfigured application server. A JVM running out of heap will experience instability and performance degradation as garbage collector and JVM competes for resources to perform cleanup and object creation respectively. |
|
Open Sessions Count |
If open session count drops to 0 and remains at 0 for a period of time, some investigation is warranted. Often this pattern indicates a network or load balancing problem. |
|
Application Invocation Count |
If application invocation count drops to 0 and remains at 0 for a period of time, some investigation is warranted. While this pattern often indicates a network or load balancing problem, it could also be a symptom of a hanged server. |
Understanding these key WebLogic system metrics, setting the SLO thresholds and assigning appropriate responses are critical to establishing a proactive monitoring. In this example, we will configure SLOs and actions with ADP.
The first task is to set a cautionary and a violation SLO for ExecuteQueue Idle Thread Count metric so the appropriate person can be alerted when available ExecuteQueue is running low. To configure SLOs, right-click on the Execute Queues metric and select Configure service level objects. In this example, we will create the following SLOs for ExecuteQueue Idle Threads:
Table 24-3 SLOs for ExecuteQueue Idle Threads
| SLO Name | Metric | Threshold Type | Threshold Value | Trigger On |
|---|---|---|---|---|
|
Low ExecuteQueue Idle Threads |
Metric.J2EE.Dispatcher.IdleThreads |
Cautionary |
3 |
Low |
|
ExecuteQueue Idle Threads Exhaustion |
Metric.J2EE.Dispatcher.IdleThreads |
Violation |
0 |
Low |
When SLO trigger is set to Low, ADP will fire an alert when current measurement reaches the threshold value AND the previous measurement has a higher value than the threshold.
For example, we would create the following actions for the SLOs previously configured:
Table 24-4 Action for SLO
| SLO Name | Action Name | Action Type |
|---|---|---|
|
Low ExecuteQueue Idle Threads |
Enter Low ExecuteQueue Idle Threads event into server log |
Log |
|
ExecuteQueue Idle Threads Exhaustion |
Email ExecuteQueue Idle Threads Exhaustion alert |
|
|
ExecuteQueue Idle Threads Exhaustion |
Send ExecuteQueue Idle Threads Exhaustion SNMP trap to HP Overview |
SNMP |
|
ExecuteQueue Idle Threads Exhaustion |
Enter ExecuteQueue Idle Threads Exhaustion event into server log |
Log |
After configuring these SLOs and actions, we now have a proactive monitoring environment to detect ExecuteQueue resource starvation related problems before a catastrophic event occurs. We would use this approach to establish proactive monitoring for other key WebLogic system metrics.
The following is the Oracle recommendation:
Table 24-5 ExecuteQueue Pending Requests
| SLO Name | Metric | Threshold Type | Threshold Value | Trigger On |
|---|---|---|---|---|
|
ExecuteQueue Pending Request Warning |
Metric.J2EE.Dispatcher.PendingRequests |
Cautionary |
5 ~ 10Foot 1 |
High |
|
ExecuteQueue Pending Request Violation |
Metric.J2EE.Dispatcher.PendingRequests |
Violation |
10 ~ 20 |
High |
Footnote 1 Threshold values for these SLOs vary by environment. Figuring out what threshold values to use is an iterative process. Users should gather information about the performance characteristic of their WebLogic environment as the first step. Based on this information, users can set SLOs accordingly. As users continue to improve the performance of their WebLogic environment, they should re-evaluate these threshold values and change them as needed.
When SLO trigger is set to High, ADP will trigger an alert when current measurement hits the threshold value.
Table 24-6 Total JVM Heap Size
| SLO Name | Metric | Threshold Type | Threshold Value | Trigger On |
|---|---|---|---|---|
|
JVM Heap Reached Max |
Metric.J2EE.JVM.HeapSizeCurrent |
Cautionary |
512 MBFoot 1 |
High |
|
JVM Heap Reached 0 |
Metric.J2EE.JVM.HeapSizeCurrent |
Violation |
0 MB |
Low |
Footnote 1 Threshold value for this SLO varies by environment. Users would set this value to the maximum heap size specified in the WebLogic configuration file.
Table 24-7 Free JVM Heap Size
| SLO Name | Metric | Threshold Type | Threshold Value | Trigger On |
|---|---|---|---|---|
|
Low JVM Free Heap Warning |
Metric.J2EE.JVM.HeapFreeCurrent |
Cautionary |
72 MB |
Low |
|
Low JVM Free Heap Violation |
Metric.J2EE.JVM.HeapFreeCurrent |
Violation |
24 MB |
Low |
Table 24-8 Open Session Count
| SLO Name | Metric | Threshold Type | Threshold Value | Trigger On |
|---|---|---|---|---|
|
No user session in system for 5 minutes |
Metric.J2EE.WebApplication. OpenSessionCurrentCount |
Cautionary |
Low |
Footnote 1 In the example, this SLO would have a measurement window of 5 minutes. By setting the measurement window to 5 minutes, ADP will fire an alert only if this condition persists for at least 5 minutes.
Table 24-9 Application Invocation Count
| SLO Name | Metric | Threshold Type | Threshold Value | Trigger On |
|---|---|---|---|---|
|
No application invocation in system for 5 minutes |
Metric.J2EE.Servlet.InvocationTotalCount |
Cautionary |
0 |
Low |
Setting these SLOs and corresponding actions establishes a proactive monitoring environment for your WebLogic deployment. This proactive monitoring approach allows you to identify problems leading up to catastrophic problems before they impact your system's performance and availability.
The ADP Methodology is a critical aspect of your application performance management strategy. By following this methodology carefully, you will be able to use ADP to improve your ability to proactively monitor the performance and availability of your deployed applications and WebLogic infrastructure. ADP's automation reduces time, effort, and errors associated with manual processes. This allows ADP users to focus on other crucial activities such as the ones listed in the Oracle Methodology.
|
Copyright © 2011, 2012, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|