This topic describes the offline processing that the Endeca Information Transformation Layer components perform to create Agraph partitions.
For a full explanation about how Data Foundry processing works for a single Dgraph implementation, see the Endeca Forge Guide.
To summarize, the Information Transformation Layer architecture to process source data for a single partition, running in a single MDEX Engine, looks like this:

In an Agraph implementation, the Information Transformation Layer processing is very similar. However, multiple Information Transformation Layer components (namely Dgidx and Agidx) run in parallel to process each partition’s data. The architecture to process an Agraph implementation with three partitions looks like this:
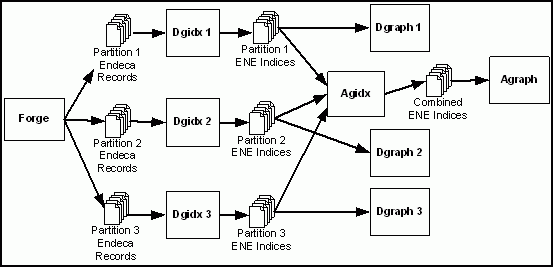
- Forge reads in the source data. (Assume Forge has access to source data as shown in the diagram with a single MDEX Engine.)
data as shown in the diagram with a single MDEX Engine.)
Forge enables parallel processing by producing Endeca records in any number of partitions. You specify the number of partitions in the Agraph tab of the Indexer adapter or the Update adapter.
The Data Foundry starts a Dgidx process for each partition that Forge created. The Dgidx processes can run on one or multiple machines, depending on the desired allocation of computation resources.
Each Dgidx process creates a set of MDEX Engine indices for its corresponding partition.
After all the Dgidx processes complete, the Agidx program runs to create an index specific to the Agraph. This index contains information about each partition’s indices.
Each MDEX Engine (Dgraph) starts and loads the index for its corresponding partition.
After all Dgraphs start, the Agraph starts and loads its index, which contains information about each child index of the Dgraph.
