The pipeline metaphor suggests all data moves downstream through a pipeline during processing. It is important to understand that although the term pipeline suggests that record processing occurs in a downstream order (a push scenario beginning with source data and ending with indexed Endeca records), Forge actually processes records by requesting records from upstream components (a pull scenario) to retrieve records as necessary.
Pipeline components, such as a record adapter, Perl manipulator, indexer adapter, spider, and so on, call backwards up a pipeline, either requesting a record one at a time using the next_record method, or requesting all records that match a key using the get_records method. Forge then returns the records downstream to the requesting component for processing.
When you write the EDF::Manipulator::next_record or EDF::Manipulator::get_records method for a Perl manipulator, you are defining how the Forge Execution Framework retrieves the records from the Perl manipulator and how the framework returns them to the downstream component.
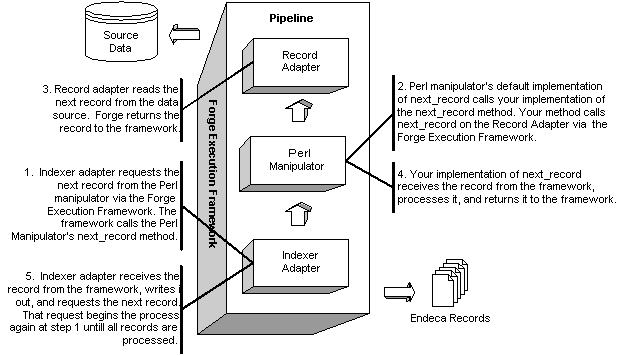
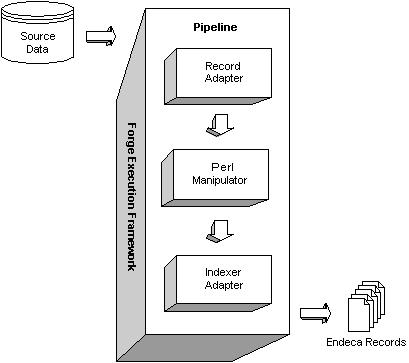
It's useful to contrast downstream record flow with upstream method calls in the diagrams below. The first diagram shows the conceptual explanation of downstream processing. Records flow from a source database through the pipeline, and Forge produces Endeca records as a result.
The second diagram shows each component in the pipeline calling next_record through the Forge Execution Framework to make upstream requests for records. The upstream requests are represented in steps 1, 2, and 3. The Forge Execution Framework returns the records to the requesting component. The downstream record flow is represented in steps 4 and 5.