This section describes how to create and configure a Term Discovery pipeline using Developer Studio.
The pipeline is used for baseline updates. For instructions on creating a pipeline for partial updates, see the "Partial Updates for Term Extraction" topic in Chapter 6.
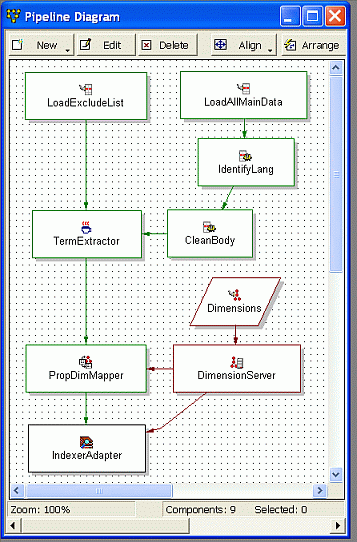
The goal of this section is to describe the pipeline components that are specific to Term Discovery, in particular, the Java manipulator. Therefore, components that are common to all pipelines (dimension server, property mapper, indexer adapter, and so on) are omitted for simplicity.
The pipeline for your specific implementation such as a record manipulator to pre-process records, and perhaps another one to post-process the records. For example, if you are crawling a Web site, you will probably include a record manipulator to strip the records of HTML code before the terms are extracted from the records.
- Create a record adapter to read the source records.
- Create a record adapter to read in the exclude list.
- Optionally, create other components to pre-process the incoming records.
- Create a Java manipulator to perform the term extraction process.
- Create a property mapper to map source properties to Endeca properties and dimensions.
- Create an indexer adapter. Because there is nothing unique about an indexer adapter for a Term Discovery pipeline, the process of creating this component is not described in this guide.
Here is how the sample Term Discovery pipeline looks in the Developer Studio Pipeline Diagram.