Endeca components and Stratify components communicate closely during record processing to classify each unstructured source document. The process is outlined below:
A record manipulator using a STRATIFY expression interacts with a Stratify Classification Server to classify each record as it is processed through the pipeline. A simplified summary of the interaction is as follows: Forge crawls unstructured source documents, hands them off to Stratify to classify them, and then Forge appends classification properties to the record for the corresponding source document. You map the Stratify properties to a dimension created from the Stratify taxonomy.
- URLs flow from the spider to the record adapter (a record adapter that uses the Document format).
- Documents flow to the indexer adapter and get turned into Endeca records.
- The Stratify taxonomy is published to the Stratify Classification Server, exported from the Taxonomy Manager as XML, and transformed in the pipeline as a dimension. Strictly speaking, this step is not part of the record processing flow. This step must be performed only once before you run a baseline update.
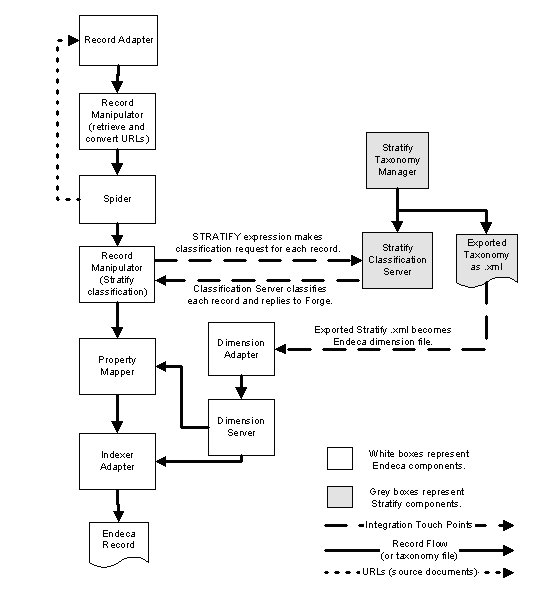
- The terminating component (indexer adapter) requests the next record from its record source (property mapper). At this point, none of the pipeline components between the indexer adapter and the record adapter has records to process yet.
- When the request for the next record reaches the record adapter, the record adapter asks the spider for the next URL it is to retrieve (the first iteration through the URL processing loop, the URL is the root URL configured on the Root URL tab of the Spider editor).
- Based on the URL that the spider provides, the record adapter creates a record containing the URL and a limited set of metadata.
- The created record then flows down to the first record manipulator where the following takes place:
- The document associated with the URL is fetched (using the RETRIEVE_URL expression).
- Content (searchable text) is extracted from the document using the CONVERTTOTEXT or PARSE_DOC expression. Any URLs in the document are also extracted for additional crawling.
- The record then moves to the spider where additional URLs from the document (those extracted in the record manipulator) are queued for crawling.
- The created record then flows down to the second record manipulator where the following takes place:
- The STRATIFY expression requests that the Stratify Classification Server classify each document. Forge sends the document as an attachment to a Stratify Classification Server.
- The Stratify Classification Server examines the document, including the document’s structure, and classifies it according to the classification model you developed in the Stratify Taxonomy Manager.
- The Stratify Classification Server then replies to Forge with a classification response that indicates what properties to append to the record.
- The property mapper performs source property to dimension and source property to Endeca property mapping.
- The indexer adapter receives the record and writes it out to disk.
The process repeats until there are no URLs in the URL queue maintained by the spider component.
