By adding the STRATIFY expression to a record manipulator, you identify it as a Stratify Classification Server.
Before setting up your Stratify Classification Server, you need to create an Endeca Crawler pipeline.
A STRATIFY expression is required after the RETRIEVE_URL and text extraction expressions (either PARSE_DOC or CONVERTTOTEXT). The STRATIFY expression identifies a Stratify Classification Server that classifies the unstructured document associated with an Endeca record.
For the sake of pipeline clarity, Endeca recommends that you add the STRATIFY expression in its own record manipulator that follows the spider component. The recommended position of a record manipulator containing the STRATIFY expression is after the spider component and before the property mapper:
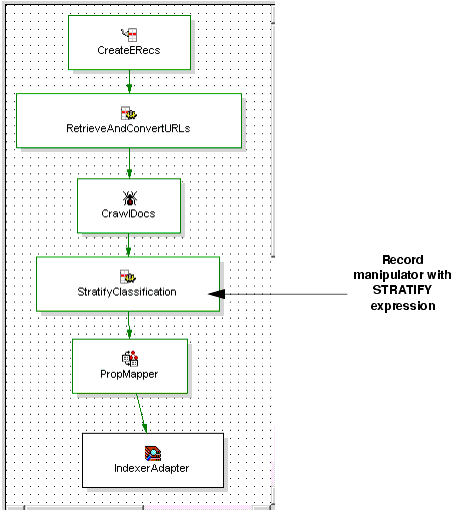
If you have more than one Stratify Classification Server in your environment, then you need one STRATIFY expression to specify the host, port, hierarchy ID, and other information for each server. Typically, a single taxonomy is published to a single Stratify Classification Server.
To add a STRATIFY expression to a record manipulator:
- In the Project tab of Developer Studio, double-click Pipeline Diagram.
- In the Pipeline Diagram editor, choose . The Record Manipulator editor displays.
- Click OK.
- Double-click the record manipulator.
-
Add the required STRATIFY expressions from the following list:
Expression Description STRATIFY_HOST The machine name or IP address of the Stratify Classification Server. STRATIFY_PORT The port on which the Stratify Classification Server listens for requests from Forge. HIERARCHY_ID The identifier of a Stratify classification model. IDENTIFIER_PROP_NAME The Endeca identifier for the record being processed. The default is Endeca.Identifier. BODY_PROP_NAME The property that the Stratify Classification Server examines to classify the document. The default property is Endeca.Document.Body.
You can provide either Endeca.Document.Body or Endeca.Document.Text. However, specifying Endeca.Document.Body provides better classification because Forge can send the document to the Stratify Classification Server as an attachment, and the Stratify Classification Server can use the attachment to determine structural information of the document that aids in classification. If you specify Endeca.Document.Text, Forge sends the converted text of the document without any of its structural information.
Note: It is not necessary to provide attribute values for the LABEL or URL attributes.To determine the VALUE of HIERARCHY_ID:
- Navigate to the working directory of the Stratify Classification Server that contains your classification model and taxonomy files. This directory is typically located at <Stratify Install Directory>\ClassificationServer\ClassificationServer\ClassificationServerWorkDir\Taxonomy-N, where N is the number of the directory that contains the classification model you want to use with your Endeca project. (Your environment may have multiple \Taxonomy-N directories each containing different classification model and taxonomy files).
- Note the number at the end of the of \Taxonomy-N directory. This number is the value of HIERARCHY_ID. For example, if the classification model you want to use is stored in ...\Taxonomy-2, then HIERARCHY_ID should have VALUE="2". If you published more than one taxonomy to your Stratify Classification Server, include a HIERARCHY_ID node for each taxonomy.
- If necessary, add additional STRATIFY expressions for each Stratify Classification Server in your environment.
