A Java manipulator must be configured for the term extraction class.
A Java manipulator component uses one or more Java modules to manipulate source records as part of Forge's data processing. You can use multiple Java manipulators in the pipeline.
- Extracts terms (noun phrases) from source records.
- Filters out unwanted terms (based on the exclude list).
- Calculates per-record scores for the terms.
- Performs corpus-level filtering, which determines how informative a term is in respect to the other records in the corpus.
The configuration attributes of a Java manipulator are described below.
Creating the Java manipulator
You use Developer Studio to create and configure a Java manipulator.
- From the Pipeline Diagram in Developer Studio, click New.
- Select Java Manipulator. The New Java Manipulator editor is displayed.
- In the Name field, enter a name. The name must be unique among the pipeline components.
- Fill in the appropriate fields on the General, Sources, and Pass Throughs tabs. See the following sections for details on these tabs.
- Optionally, you can use the Comment tab to enter description or other comment about this component.
- Click Ok.
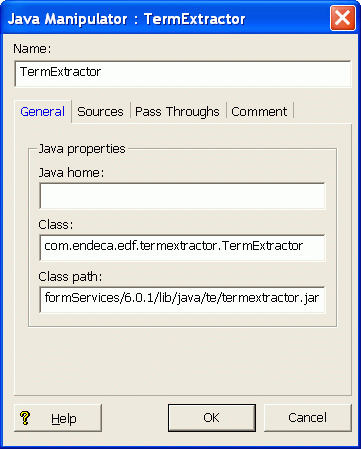
Configuring the General tab
- Java
home. Optional. Specifies the location of the Java runtime engine
(JRE). If this attribute is not specified, Forge tries to obtain the location
by using the following sequence:
- The argument to the Forge --javaHome flag.
- The ENDECA_ROOT/j2sdk directory, which is installed as part of the Endeca Platform Services package.
- The JAVA_HOME environment variable.
- Class.
Mandatory. Specifies the name of the Java class that will be used by this Java
manipulator. Use this class for term extraction:
com.endeca.edf.termextractor.TermExtractor
- Class
path. Mandatory. Specifies the absolute or relative path to the JAR
file that contains the class specified by the Class attribute. The JAR file
must contain the class and all other classes it depends on. The following
example points to the location of the
termextractor.jar (which contains the
TermExtractor class):
/endeca/PlatformServices/6.0.3/lib/java/te/termextractor.jar
The following is an example of the General tab:
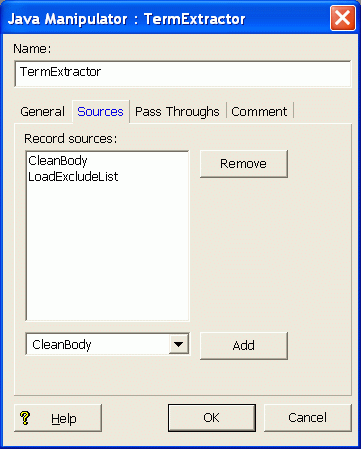
Configuring the Sources tab
Use the Sources tab to specify which other component in the pipeline is providing records to this Java manipulator. You can specify multiple record sources.
In the following example, the CleanBody record manipulator is considered to be the record data source while the LoadExcludeList source is the exclude list.
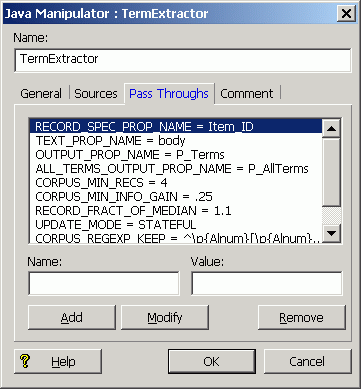
Configuring the Pass Throughs tab
The Pass Throughs tab is used to send configuration-specific information to the Java classes being executed by the Java manipulator. Descriptions of the pass-through name/value pairs for the Java classes are provided in the "Configuration Guidelines for Term Extraction" section.
- In the Java Manipulator editor, click the Pass Throughs tab
- In the Name field, enter the name of the pass-through.
- In the Value field, enter the value for the named pass-through.
- Click Add.
- Repeat steps 2-4 as necessary.
- Click Ok.
The following is an example of a populated Pass Throughs tab: