2 SQL Developer: Migrating Third-Party Databases
Migration is the process of copying the schema objects and data from a source third-party (non-Oracle) database, such as MySQL, Microsoft SQL Server, Sybase Adaptive Server, Microsoft Access, or IBM DB2 (UDB), to an Oracle database. You can perform the migration in an efficient, largely automated way.
Thus, you have two options for working with third-party databases in SQL Developer:
-
Creating database connections so that you can view schema objects and data in these databases
-
Migrating these databases to Oracle, to take advantage of the full range of Oracle Database features and capabilities
This chapter contains the following major sections:
Section 2.1, "Migration: Basic Options and Steps"
Section 2.2, "Migration: Background Information and Guidelines"
Section 2.3, "SQL Developer User Interface for Migration"
Section 2.4, "Command-Line Interface for Migration"
2.1 Migration: Basic Options and Steps
To migrate all or part of a third-party database to Oracle, you have the following basic options:
However, before you perform any migration actions, you may want to prepare by setting any appropriate Migration user preferences (such as date and timestamp masks and Is Quoted Identifier On?) and by reading relevant topics in Section 2.2, "Migration: Background Information and Guidelines".
After you migrate by using the wizard or by copying tables to Oracle, verify that the results are what you expected.
For a description of the user interface for database migrations, see Section 2.3, "SQL Developer User Interface for Migration".
2.1.1 Migrating Using the Migration Wizard
The Migration wizard provides convenient, comprehensive guidance through the actions that can be involved in database migration (capturing the source database, converting it to Oracle format, generating DDL to perform the conversion, and so on). This is the recommended approach when performing a migration: you can resolve issues during these phases, and you can then inspect or modify objects to suit your needs.
The migration wizard is invoked in a variety of contexts, such as when you right-click a third-party database connection and select Migrate to Oracle or when you click Tools, then Migration, then Migrate. Sometimes the wizard is invoked at a page other than the first step.
On all pages except the last, enabling Proceed to Summary Page causes Next to go to the Summary page.
The Repository page of the wizard requires that you specify the database connection for the migration repository to be used.
The migration repository is a collection of schema objects that SQL Developer uses to manage metadata for migrations. If you do not already have a migration repository and a database connection to the repository, create them as follows:
-
Create an Oracle user named MIGRATIONS with default tablespace USERS and temporary tablespace TEMP; and grant it at least the RESOURCE role and the CREATE SESSION and CREATE VIEW privileges. (For multischema migrations, you must grant the RESOURCE role with the ADMIN option; and you must also grant this user the CREATE ROLE, CREATE USER, and ALTER ANY TRIGGER privileges, all with the ADMIN option.)
-
Create a database connection named Migration_Repository that connects to the MIGRATIONS user.
-
Right-click the Migration_Repository connection, and select Migration Repository, then Associate Migration Repository to create the repository.
If you do not already have a database connection to the third-party database to be migrated, create one. (For migrations other than from Microsoft Access, you should set the third party JDBC driver preference before creating the connection.) For example, create a database connection named Sales_Sybase to a Sybase database named sales.
Connection: The database connection to the migration repository to be used.
Truncate: If this option is enabled, the repository is cleared (all data from previous migrations is removed) before any data for the current migration is created.
The Project page of the wizard specifies the migration project for this migration. A migration project is a container for migration objects.
Name: Name to be associated with this migration project.
Description: Optional descriptive comments about the project.
Output Directory: The directory or folder in which all scripts generated by the migration wizard will be placed. Enter a path or click Choose to select the location.
The Source Database page of the wizard specifies the third-party database to be migrated.
Mode: Online causes the migration to be performed by SQL Developer when you have completed the necessary information in the wizard; Offline causes SQL Developer to perform the migration using a file (the Offline Capture Source File) that you specify.
Connection (Online mode): The database connection to the third-party database to be migrated. To add a connection to the list, click the Add (+) icon; to edit the selected connection, click the Edit (pencil) icon.
Available Source Platforms (Online mode) List of third-party databases that you can migrate. If the desired platform is not listed, you probably need the appropriate JDBC driver, which you can get by clicking Help, then Check for Updates, or by clicking the Add Platform link and adding the necessary entry on the Database: Third Party JDBC Drivers preferences page.
Offline Capture Source File (Offline mode): The .ocp file (or .xml file for a Microsoft Access migration). This is a file that you previously created by clicking Tools, then Migration, then Create Database Capture Scripts.
The Capture page of the wizard lets you specify the database or databases (of the platform that you specified) to be migrated. Select the desired items under Available Databases, and use the arrow icons to move them individually or collectively to Selected Databases.
The Convert page of the wizard lets you examine and modify, for each data type in the course database, the Oracle Database data type to which columns of that source type will be converted in the migrated database. For each source data type entry, the possible Oracle Data Type values reflect the valid possible mappings (which might be only one).
Add New Rule: Lets you specify mappings for other source data types.
Edit Rule: Lets you modify the mapping for the selected source data type.
Advanced Options: Displays the Migration: Identifier Options preferences page.
The Target Database page of the wizard specifies the Oracle database to which the third-party database or databases will be migrated.
Mode: Online causes the migration to be performed by SQL Developer when you have completed the necessary information in the wizard; Offline causes SQL Developer to generate scripts after you have completed the necessary information in the wizard, and you must later run those scripts to perform the migration.
Connection: The database connection to the Oracle Database user into whose schema the third-party database or databases are to be migrated. To add a connection to the list, click the Add (+) icon; to edit the selected connection, click the Edit (pencil) icon.
Generated Script Directory: The directory or folder in which migration script files will be generated (derived based on your previous entry for the project Output Directory).
Drop Target Objects: If this option is enabled, any existing database objects in the target schema are deleted before the migration is performed (thus ensuring that the migration will be into an empty schema).
Advanced Options: Displays the Migration: Generation Options preferences page.
The Move Data page of the wizard lets you specify options for moving table data as part of the migration. Moving the table data is independent of migrating the table definitions (metadata) Note that if you do not want to move the table data, you can specify the mode as Offline and then simply not run the scripts for moving the data.
Mode: Online causes the table data to be moved by SQL Developer when you have completed the necessary information in the wizard; Offline causes SQL Developer to generate scripts after you have completed the necessary information in the wizard, and you must later run those scripts if you want to move the data. (Online moves are convenient for moving small data sets; offline moves are useful for moving large volumes of data.)
Connections for online data move: The Source and Target connections for the third-party and Oracle connections, respectively. To add a connection to either list, click the Add (+) icon; to edit the selected connection, click the Edit (pencil) icon.
Truncate Data: If this option is enabled, any existing data in a target (Oracle) table that has the same name as the source table is deleted before the data is moved. If this option is not enabled, any data from a source table with the same name as the corresponding target (Oracle) table is appended to any existing data in the target table.
The Summary page of the wizard provides a summary of your specifications for the project, repository, and actions, in an expandable tree format. If you want to make any changes, go back to the relevant wizard page.
To perform the migrat6ion actions that you have specified, click Finish.
2.1.2 Copying Selected Tables to Oracle
To copy one or more tables from a third-party database to an Oracle database, you can select the third-party tables and use the Copy to Oracle feature. With this approach, you do not need to create or use a migration repository, or to capture and convert objects.
Note that this approach does not perform a complete migration. It only lets you copy the table, and optionally the table data, from the third-party database to an Oracle database. It does not migrate or re-create primary and foreign key definitions and most constraints. (Any UNIQUE constraints or default values are not preserved in the copy. NOT NULL constraints are preserved in most cases, but not for Microsoft Access tables.) The approach also does not consider any non-table objects, such as procedures.
In addition, this approach supports autoincrement columns only if the INCREMENT BY value is 1, and if the sequence starts at 1 or is adjusted to MAX VAL + 1 at the first call to the trigger.
If these restrictions are acceptable, this approach is fast and convenient. For example, many Microsoft Access database owners only need the basic table definitions and the data copied to an Oracle database, after which they can add keys and constraints in the Oracle database using SQL Developer.
To copy selected tables, follow these steps:
-
Create and open a database connection for the third-party database. (For migrations other than from Microsoft Access, you should set the third party JDBC driver preference before creating the connection.)
For example, create a database connection named Sales_Access to a Microsoft Access database named sales.mdb, and connect to it.
-
In the Connections navigator, expand the display of Tables for the third-party database connection, and select the table or tables to be migrated.
To select multiple tables, use the standard method for individual and range selections (using the Ctrl and Shift keys) as appropriate.
-
Right-click and select Copy to Oracle.
-
In the Choose Database for Copy to Oracle dialog box, select the appropriate entries:
Destination Database Name: Database connection to use for copying the selected tables into the Oracle database. (Only Oracle Database connections are shown for selection.)
Include Data: If this option is enabled, any data in the table in the third-party database is copied to the new table after it is created in the Oracle database. If this option is not enabled, the table is created in the Oracle database but no data is copied.
If Table Exists: Specifies what happens if a table with the same name as the one to be copied already exists in the destination Oracle database: Indicate Error generates an error and does not perform the copy; Append adds the rows from the copied table to the destination Oracle table; Replace replaces the data in the destination Oracle table with the rows from the copied table. Note that if the two tables with the same name do not have the same column definitions and if Include Data is specified, the data may or may not be copied, depending on whether the source and destination column data types are compatible.
-
To perform the copy operation, click Apply.
If a table with the same name as the one to be copied already exists in the destination Oracle database, then:
-
If the two tables do not have the same column definitions, the copy is not performed.
-
If the two tables have the same column definitions and if Include Data was specified, the data is appended (that is, the rows from the table to be copied are inserted into the existing Oracle table).
2.2 Migration: Background Information and Guidelines
The following topics provide background information and guidelines that are helpful in planning for a database migration:
-
Section 2.2.3, "Before You Start Migrating: General Information"
-
Section 2.2.4, "Before You Start Migrating: Source-Specific Information"
-
Section 2.2.6, "Creating and Customizing the Converted Model"
-
Section 2.2.7, "Generating the DDL for the Oracle Schema Objects"
2.2.1 Overview of Migration
An Oracle database provides you with better scalability, reliability, increased performance, and better security than third-party databases. For this reason, organizations migrate from their current database, such as Microsoft SQL Server, Sybase Adaptive Server, Microsoft Access, or IBM DB2, to an Oracle database. Although database migration can be complicated, SQL Developer enables you to simplify the process of migrating a third-party database to an Oracle database.
SQL Developer captures information from the source database and displays it in the captured model, which is a representation of the structure of the source database. This representation is stored in a migration repository, which is a collection of schema objects that SQL Developer uses to store migration information.
The information in the repository is used to generate the converted model, which is a representation of the structure of the destination database as it will be implemented in the Oracle database. You can then use the information in the captured model and the converted model to compare database objects, identify conflicts with Oracle reserved words, and manage the migration progress. When you are ready to migrate, you generate the Oracle schema objects, and then migrate the data.
SQL Developer contains logic to extract data from the data dictionary of the source database, create the captured model, and convert the captured model to the converted model.
Using SQL Developer to migrate a third-party database to an Oracle database provides the following benefits:
-
Reduces the effort and risks involved in a migration project
-
Enables you to migrate an entire third-party database, including triggers and stored procedures
-
Enables you to see and compare the captured model and converted model and to customize each if you wish, so that you can control how much automation there is in the migration process
-
Provides feedback about the migration through reports
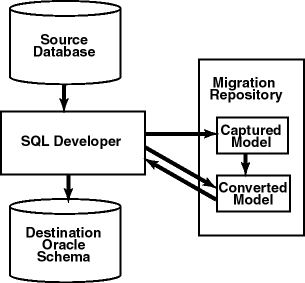
2.2.1.1 How Migration Works
The components of SQL Developer work together to migrate a third-party database to an Oracle database. Figure 2-1, "SQL Developer Migration Architecture" shows how SQL Developer reads the information from the source database and creates the Oracle database schema objects. SQL Developer uses the information stored in the migration repository to migrate to the Oracle schema. You can make changes to the captured model or the converted model, or both, before migrating. The information in the converted model is used to complete the migration, that is, to generate the database objects in the destination Oracle schema.
2.2.1.2 Migration Implemented as SQL Developer Extensions
Migration support is implemented in SQL Developer as a set of extensions. If you want, you can disable migration support or support for migrating individual third-party databases.
To view the installed extensions, and to enable or disable individual extensions, click Tools, then Preferences, then Extensions. Note that SQL Developer ships which all extensions and third-party database "plugins" available at the time of release, so to begin migrations other than for Microsoft Access, only the third-party drivers need be installed.
2.2.2 Preparing a Migration Plan
This topic describes the process of how to create a migration plan. It identifies the sections to include in the migration plan, describes how to determine what to include for each section, and explains how to avoid the risks involved in a migration project. This information includes:
2.2.2.1 Task 1: Determining the Requirements of the Migration Project
In this task, you identify which databases you want to migrate and applications that access that database. You also evaluate the business requirements and define testing criteria.
To determine the requirements of the migration project:
-
Define the scope of the project.
There are several choices you must make about the third-party database and applications that access that database in order to define the scope of the migration project. To obtain a list of migration issues and dependencies, you should consider the following
-
What third-party databases are you migrating?
-
What is the version of the third-party database?
-
What is the character set of the third-party database?
-
-
What source applications are affected by migrating the third-party database to an Oracle database?
-
What is the third-party application language?
-
What version of the application language are you using?
In the scope of the project, you should have identified the applications you must migrate. Ensure that you have included all the necessary applications that are affected by migrating the database
-
-
What types of connectivity issues are involved in migrating to an Oracle database?
-
Do you use connectivity software to connect the applications to the third-party database? Do you need to modify the connectivity software to connect the applications to the Oracle database?
-
What version of the connectivity software do you use? Can you use this same version to connect to the Oracle database?
-
-
Are you planning to rewrite the applications or modify the applications to work with an Oracle database?
-
-
Use Table 2-1 to determine whether you have a complex or simple source database environment. Identify the requirements based on the specific scenario.
If the migration project is a simple scenario, you may not have to complete all possible migration tasks. You make decisions based on your specific environment. For example, if you have a complex scenario, you may require extra testing based on the complexity of the application accessing the database.
Table 2-1 Complex and Simple Scenarios
Complex Scenario Simple Scenario Involves more than one of the following:
-
Large database (greater than 25 GB)
-
Data warehouse
-
Large applications (more than 100 forms, reports, and batch jobs)
-
Database used by multiple lines of business
-
Distributed deployment
-
Large user base (more than 100)
-
High availability requirement (such as a 24 X 7 X 365 environment)
Involves the following:
-
Small database (less than 25 GB)
-
Simple online transaction processing (OLTP)
-
Small application (less than 100 forms, reports, and batch jobs)
-
Database used by one department
-
Centralized deployment
-
Small user base (less than 100)
-
Average availability (business hours)
-
-
Determine whether the destination database requires additional hardware and rewriting of backup schedules.
-
Define testing and acceptance criteria.
Define tests to measure the accuracy of the migration. You then use the acceptance criteria to determine whether the migration was successful. The tests that you develop from the requirements should also measure stability, evaluate performance, and test the applications. You must decide how much testing is necessary before you can deploy the Oracle database and applications into a production environment.
-
Create a requirements document with a list of requirements for the migration project.
The requirements document should have clearly defined tasks and number each specific requirement, breaking these into sub-requirements where necessary.
2.2.2.2 Task 2: Estimating Workload
In this task, you use SQL Developer to make calculated decisions on the amount of work that can be automated and how much is manual.
To estimate the workload:
-
Capture the captured model, create the converted model, and migrate to the destination database.
You can analyze the source database through the captured model and a preview of the destination database through the converted model. After you have captured the source database, analyze the captured data contained in the captured model and the converted model. Ensure the content and structure of the migration repository is correct and determine how much time the entire process takes.
-
Use the Migration Log pane to evaluate the capture and migration process, categorize the total number of database objects, and identify the number of objects that can be converted and migrated automatically.
The migration log provides information about the actions that have occurred and record any warnings and errors. They identify the changes that have been made to the converted model so that you can evaluate if you should make changes to the applications that access the destination database.
-
Evaluate and categorize the issues that occurred. The migration log can help by providing information about:
-
Tables that did not load when you captured the source database
-
Stored procedures, views, and triggers that did not parse when you created the converted model
-
Syntax that requires manual intervention
-
Database objects that were not created successfully when you migrated the destination database
-
Data that did not migrate successfully when you migrated the destination database
-
-
For each error or warning in the migration log, evaluate the following:
-
Number of times an issue occurred
-
Time required to fix the issues, in person-hours
-
Number of resources required to fix the issue
After you have solved a complex problem, it should be easier and quicker to resolve the next time you have the same problem.
-
2.2.2.3 Task 3: Analyzing Operational Requirements
In this task, you analyze the operational requirements, as follows:
-
Evaluate the operational considerations in migrating the source database to a destination database. Consider the following questions:
Note:
If the scope of the migration project is a complex scenario as defined in Table 2-1, Oracle recommends that you answer all of these questions. If you have a simple scenario, determine the answers to the most appropriate questions.-
What backup and recovery changes do you require?
-
What downtime is required during the migration?
-
Have you met the performance requirements?
-
Are you changing the operational time window?
-
What effect does the downtime have on the business?
-
What training requirements or additional staff considerations are required?
-
Is it necessary to have the third-party and the Oracle database running simultaneously?
-
-
For each task, determine the resources and time required to complete.
-
Create an initial project plan.
Use the information that you have gathered during the requirements and planning stage to develop an initial project plan.
2.2.2.4 Task 4: Analyzing the Application
In this task, you identify the users of the applications that run on the source database, what hardware it requires, what the application does, and how it interfaces with the source database. You also analyze the method the application uses to connect to the database and identify necessary modifications.
Note:
If the migration project is a complex scenario as defined in Table 2-1, Oracle recommends that you consider all of the following items. If you have a simple scenario, consider the most relevant items.To analyze the application:
-
Determine whether changes to the application are required to make them run effectively on the destination database.
-
If changes are required to the application, determine whether it is more efficient to rewrite or modify the applications.
If you are rewriting the application to use the Oracle database, consider the following:
-
Create the necessary project documentation to rewrite the application. For example, you need a design specification and requirements documentation.
-
Rewrite the application according to the specification.
-
Test the application works against the Oracle database.
If you are modifying the application to use the Oracle database, consider the following:
-
Identify the number of connections to the database that are in the application and modify these connections to use the Oracle database.
You may need to change the connection information to use an ODBC or JDBC connection.
-
Identify the embedded SQL statements that you need to change in the application before you can test it against the Oracle database.
-
Test the application using the Oracle database.
-
-
Allocate time and resource to address each issue associated with rewriting or modifying the application.
-
Update the general requirements document for the project that you created in Task 1.
2.2.2.5 Task 5: Planning the Migration Project
In this task, you evaluate the unknown variables that the migration project may contain, such as the difference in the technologies of the source database and the destination database. During the planning stage, you:
-
Estimate the budget constraints of the project
-
Gather information to produce a migration plan
-
Estimate how much time the migration project should take
-
Calculate how many resources are required to complete and test the migration
To plan a migration project:
-
Define a list of tasks required to successfully complete the migration project requirements of Task 1.
-
Categorize the list of tasks required to complete the migration project.
You should group these tasks according to your business. This allows you to schedule and assign resources more accurately.
-
Update and finalize the migration project plan based on the information that you have obtained from Task 3 and Task 4.
-
Make sure the migration project plan meets the requirements of the migration project.
The migration plan should include a project description, resources allocated, training requirements, migration deliverable, general requirements, environment analysis, risk analysis, application evaluation, and project schedule.
2.2.3 Before You Start Migrating: General Information
You may need to perform certain tasks before you start migrating a third-party database to an Oracle database. See the following for more information:
-
Section 2.2.3.1, "Creating a Database User for the Migration Repository"
-
Section 2.2.3.2, "Requirements for Creating the Destination Oracle Objects"
See also any information specific to the source database that you will be migrating, as explained in Section 2.2.4.
Note:
SQL Developer does not migrate grant information from the source database. The Oracle DBA must adjust (as appropriate) user, login, and grant specifications after the migration.Note:
Oracle recommends that you make a complete backup of the source database before starting the migration. For more information about backing up the source database, see the documentation for that type of database.If possible, begin the migration using a development or test environment, not a production database.
2.2.3.1 Creating a Database User for the Migration Repository
SQL Developer requires a migration repository to migrate a third-party database to an Oracle database. To use an Oracle database for the migration repository, you must have access to that database using a database user account. Oracle recommends that you use a specific user account for migrations, For example, you may want to create a user named MIGRATIONS, create a database connection to that user, and use that connection for the migration repository; and if you wish, you can later delete the MIGRATIONS user to remove all traces of the migration from the database.
When you create a user for migrations, specify the tablespace information as in the following example, instead of using the defaults for tablespaces:
CREATE USER migrations IDENTIFIED BY <password>
DEFAULT TABLESPACE users TEMPORARY TABLESPACE temp,
Do not use a standard account (for example, SYSTEM) for migration.
When SQL Developer creates a migration repository, it creates many schema objects that are intended only for its own use. For example, it creates tables, views, indexes, packages, and triggers, many with names starting with MD_ and MIGR. You should not directly modify these objects or any data stored in them.
2.2.3.2 Requirements for Creating the Destination Oracle Objects
The user associated with the Oracle database connection used to perform the migration (that is, to run the script containing the generated DDL statements) must have the following roles and privileges:
Note:
You must grant these privileges directly to a user account. Granting the privileges to a role, which is subsequently granted to a user account, does not suffice. You cannot migrate a database as the userSYS.CONNECT WITH ADMIN OPTION RESOURCE WITH ADMIN OPTION
ALTER ANY ROLE ALTER ANY SEQUENCE ALTER ANY TABLE ALTER TABLESPACE ALTER ANY TRIGGER COMMENT ANY TABLE CREATE ANY SEQUENCE CREATE ANY TABLE CREATE ANY TRIGGER CREATE VIEW WITH ADMIN OPTION CREATE PUBLIC SYNONYM WITH ADMIN OPTION CREATE ROLE CREATE USER DROP ANY SEQUENCE DROP ANY TABLE DROP ANY TRIGGER DROP USER DROP ANY ROLE GRANT ANY ROLE INSERT ANY TABLE SELECT ANY TABLE UPDATE ANY TABLE
For example, you can create a user called migrations with the minimum required privileges required to migrate a database by using the following commands:
CREATE USER migrations IDENTIFIED BY password
DEFAULT TABLESPACE users TEMPORARY TABLESPACE temp;
GRANT CONNECT, RESOURCE, CREATE VIEW, CREATE PUBLIC SYNONYM TO
migrations WITH ADMIN OPTION;
GRANT ALTER ANY ROLE, ALTER ANY SEQUENCE, ALTER ANY TABLE, ALTER TABLESPACE,
ALTER ANY TRIGGER, COMMENT ANY TABLE, CREATE ANY SEQUENCE, CREATE ANY TABLE,
CREATE ANY TRIGGER, CREATE ROLE, CREATE TABLESPACE, CREATE USER, DROP ANY
SEQUENCE, DROP ANY TABLE, DROP ANY TRIGGER, DROP TABLESPACE, DROP USER, DROP ANY
ROLE, GRANT ANY ROLE, INSERT ANY TABLE, SELECT ANY TABLE, UPDATE ANY TABLE TO
migrations;
After you have created the converted model and done first DDL generation done for the new database, it will be clear from the scripts which privileges will be required for your situation.
2.2.4 Before You Start Migrating: Source-Specific Information
Depending on the third-party database that you are migrating to an Oracle database, you may have to configure connection information and install drivers. For more information about specific third-party database requirements, see the following:
2.2.4.1 Before Migrating From IBM DB2
To configure an IBM DB2 database for migration:
-
Ensure that the source database is accessible by the IBM DB2 database user that is used by SQL Developer for the source connection. This user must be able to see any objects to be captured in the IBM DB2 database; objects that the user cannot see are not captured. For example, if the user can execute a stored procedure but does not have sufficient privileges to see the source code, the stored procedure cannot be captured.
-
Ensure that you can connect to the IBM DB2 database from the system where you have installed SQL Developer.
-
Ensure that you have downloaded the
db2jcc.jaranddb2jcc_license_cu.jarfiles from IBM. -
In SQL Developer, do the following:
-
Click Tools, then Preferences, then Database, then Third Party JDBC Drivers.
-
Click Add Entry.
-
Select the
db2jcc.jarfile. -
Click OK.
-
Repeat steps b through d for the
db2jcc_license_cu.jarfile.
-
2.2.4.2 Before Migrating From Microsoft SQL Server or Sybase Adaptive Server
To configure a Microsoft SQL Server or Sybase Adaptive Server database for migration:
-
Ensure that the source database is accessible by the Microsoft SQL Server or Sybase Adaptive Server user that is used by SQL Developer for the source connection. This user must be able to see any objects to be captured in the Microsoft SQL Server or Sybase Adaptive Server database; objects that the user cannot see are not captured. For example, if the user can execute a stored procedure but does not have sufficient privileges to see the source code, the stored procedure cannot be captured.
-
Ensure that you can connect to the Microsoft SQL Server or Sybase Adaptive Server database from the system where you have installed SQL Developer.
-
Ensure that you have downloaded the JTDS JDBC driver from
http://jtds.sourceforge.net/. -
In SQL Developer, if you have not already installed the JTDS driver using Check for Updates (on the Help menu), do the following:
-
Click Tools, then Preferences, then Database, then Third Party JDBC Drivers.
-
Click Add Entry.
-
Select the jar file for the JTDS driver you downloaded from
http://jtds.sourceforge.net/. -
Click OK.
-
-
In SQL Developer, click Tools, then Preferences, then Migration: Identifier Options, and ensure that the setting is correct for the Is Quoted Identifier On option (that is, that the setting reflects the database to be migrated).
If this option is enabled, quotation marks (double-quotes) can be used to refer to identifiers; if this option is not enabled, quotation marks identify string literals. As an example of the difference in behavior, consider the following T-SQL code:
select col1, "col 2" "column_alias" from tablex "table_alias"
If the Is Quoted Identifier On option is enabled (checked), the following PL/SQL code is generated:
SELECT col1, col_2 "column_alias" FROM tablex "table_alias";If the Is Quoted Identifier On option is disabled (not checked), the following PL/SQL code is generated:
SELECT col1, 'col 2' "column_alias" FROM tablex "table_alias";
2.2.4.3 Before Migrating From Microsoft Access
To configure a Microsoft Access database for migration:
-
Make backup copies of the database file or files.
-
Ensure that the necessary software (Microsoft Access, perhaps other components) is installed on the same system as SQL Developer.
-
Ensure that the Admin user has at least Read Design and Read Data permissions on the MSysObjects, MSysQueries, and MSysRelationships system tables, as explained in the information about the Access tab in the Create/Edit/Select Database Connection dialog box.
-
If security is enabled, you should turn it off by copying the contents of the secured database into a new database, as follows:
SQL Developer does not support the migration of Microsoft Access databases that have security enabled. By default, SQL Developer uses the name of the Microsoft Access MDB file as the user name for the destination Oracle user. If you create an Oracle user in this way, the password is ORACLE.
-
From the File menu in Microsoft Access, select New Database.
-
Select the Blank Database icon, then click OK.
-
In the File New Database option, type a name for the database, then click Create.
-
From the File menu within the new database, select Get External Data, then select Import.
-
Select the secured Microsoft Access database that you want to import, then click Import.
-
From the Import Objects dialog, click Options.
-
Select the Relationships and Definition and Data options.
-
From the Tables tab, choose Select All.
-
Click OK.
All Microsoft Access objects are copied over to the new Microsoft Access database, except for the security settings.
-
-
If the application contains linked tables to other Microsoft Access databases, refresh these links by opening the application in Microsoft Access and performing the following:
From the Tools menu in Microsoft Access 97, select Add Ins, then select Linked Table Manager.
From the Tools menu in Microsoft Access 2000, select Database Utilities, then select Linked Table Manager.
-
Ensure that the Microsoft Access database is not a replica database, but a master database.
When you use the Exporter for Microsoft Access to export, an error message is displayed if the database is a replica. SQL Developer does not support the migration of a replica database.
-
From the Tools menu within Microsoft Access, select Database, then select Compact Database to compact the Microsoft Access database files.
-
Ensure that the Microsoft Access database file is accessible from the system where you have installed SQL Developer.
-
Use the Oracle Universal Installer to verify that you have the Oracle ODBC driver installed. If you need to install the driver, it is available on the Oracle Database Server or Database Client CD. You can also download the Oracle ODBC driver from the Oracle Technology Network (OTN) website:
http://www.oracle.com/technetwork/developer-tools/visual-studio/downloads/
Install the Oracle ODBC driver into an Oracle home directory that contains the Oracle Net Services. You can obtain the Oracle Net Services from the Oracle Client or Oracle Database CD. You install Oracle Net Services to obtain the Net Configuration Assistant and Net Manager. These allow you to create a net configuration in the
tnsnames.orafile.Note:
For more information about installing the networking products needed to connect to an Oracle database, see the installation guide for your Oracle Database release.
2.2.4.3.1 Creating Microsoft Access XML Files
To prepare for capturing a Microsoft Access database, the Exporter for Microsoft Access tool must be run, either automatically or manually, as explained in Section 2.2.5, "Capturing the Source Database". This tool is packaged as a Microsoft Access MDE file and it allows you to export the Microsoft Access MDB file to an XML file.
Note:
Do not modify any of the files created by the Exporter tool.Each Microsoft Access database that you selected is exported to an XML file. The exporter tool currently does not support creating XML files from secured or replica databases.
2.2.4.4 Before Migrating From MySQL
To configure a MySQL database for migration, install MySQLConnector/J release 3.1.12 or 5.0.4 on the system where you have installed SQL Developer and set the appropriate SQL Developer preference. Follow these steps:
-
Ensure that you can connect to the MySQL database from the system where you have installed SQL Developer.
-
Ensure that you have downloaded the MySQLConnector/J API from the MySQL website at
http://www.mysql.com/. -
In SQL Developer, if you have not already installed the MySQL JDBC driver using Check for Updates (on the Help menu), do the following:
-
Click Tools, then Preferences, then Database, then Third Party JDBC Drivers.
-
Click Add Entry.
-
Select the jar file for the MySQL driver you downloaded from
http://www.mysql.com/. -
Click OK.
-
-
Ensure that the source database is accessible by the MySQL user that is used by SQL Developer for the source connection. This user must be able to see any objects to be captured in the MySQL database; objects that the user cannot see are not captured. For example, if the user can execute a stored procedure but does not have sufficient privileges to see the source code, the stored procedure cannot be captured.
2.2.4.5 Before Migrating From Teradata
Note that for the current release of SQL Developer, the following Teradata objects will not be migrated to Oracle: procedures, functions, triggers, views, macros, and BTEQ scripts.
To configure a Teradata database for migration:
-
Ensure that the source database is accessible by the Teradata database user that is used by SQL Developer for the source connection. This user must be able to see any objects to be captured in the Teradata database; objects that the user cannot see are not captured.
-
Ensure that you can connect to the Teradata database from the system where you have installed SQL Developer.
-
Ensure that you have downloaded the
tdgssconfig.jarandterajdbc4.jarfiles from Teradata. -
In SQL Developer, do the following:
-
Click Tools, then Preferences, then Database, then Third Party JDBC Drivers.
-
Click Add Entry.
-
Select the
tdgssconfig.jarfile. -
Click OK.
-
Repeat steps b through d for the
terajdbc4.jarfile.
-
2.2.5 Capturing the Source Database
Before migrating a third-party database, you must extract information from the database. This information is a representation of the structure of the source database, and it is called the captured model. The process of extracting the information from the database is called capturing the source database.
The capture can be done online or offline:
-
Online capture is done in a convenient guided sequence, during the Migrating Using the Migration Wizard process.
-
Offline capture involves creating a script that you run later, as explained in Section 2.2.5.1, "Offline Capture". You can use offline capture with IBM DB2, MySQL, Microsoft SQL Server databases, and Sybase Adaptive Server.
After capturing the source database, you can view the source database information in the captured model in SQL Developer. If necessary, you can modify the captured model and change data type mappings.
Note:
Oracle recommends that you do not change the default data type mappings unless you are an experienced Oracle database administrator.2.2.5.1 Offline Capture
To perform an offline capture of an IBM DB2, MySQL, Microsoft SQL Server, or Sybase Adaptive Server database, you create a set of offline capture scripts, run these scripts outside SQL Developer to create the script output (a dump of the third party metadata tables), and load the script output (the .ocp file containing the converted model) using SQL Developer.
-
To create the script file (a Windows .bat file or a Linux or UNIX .sh file) and related files, click Tools, then Migration, then Create Database Capture Scripts.
When this operation completes, you are notified that several files (.bat, .sql, .ocp) have been created, one of which is the controlling script. You must run the controlling script (outside SQL Developer) to populate the object capture properties (.ocp) file with information about the converted model.
-
To load the converted model from the object capture properties (.ocp) file generated by the offline capture controlling script, click Tools, then Migration, then Third Party Database Offline Capture, then Load Database Capture Script Output.
2.2.5.1.1 IBM DB2 Offline Capture Notes
Script files and the db2_x.ocp file are generated in the target folder. The main script is startDump.xxx, which you must execute to produce the schema dump. The script files prompt you for the database name, user name, and password, and they use this information to connect to the local DB2 database. The scripts generate the schema dump for database objects within object-specific folders.
To capture the schema information in offline file format, use a command in the following format (with the db2 executable in the run path):
db2 -x +o -r <file name> <schema query>
To export the schema data in offline file format, use a command in the following format (with the db2 executable in the run path):
-
For DB2 version 9 data export:
db2 export to <file name> of DEL modified by lobsinsepfiles coldel"#" timestampformat=\"YYYY/MM/DD HH.mm.ss\" datesiso nochardel <select query>
-
For DB2 version 8 data export:
db2 export to <file name> of DEL modified by coldel"#" timestampformat=\"YYYY/MM/DD HH.mm.ss\" datesiso nochardel <select query>
DB2 version 9 supports LOB data in separate files, which is better for migrating large data sizes. With version 8, to support large LOB data, you must modify the oracle ctl file command and db2 command in unload_script.bat or unload_script.sh.
The table data is exported to files with names in the format <catalog>.<schema>.<table>.dat. The format of file is as follows: data1#<COL_DEL> #data2#<COL_DEL>…<ROW_DEL> where COL_DEL and ROW_DEL come from migration offline preference settings.
Before you execute the DB2 data dump script, you must log in by entering a command in the following format:
db2 connect to <catalog> user <user name> using <password>
You can then execute the script using the logged connection session.
2.2.6 Creating and Customizing the Converted Model
After you capture a third-party database, the next step is to convert it, creating the converted model. The converted model is a representation of the structure of the destination database. SQL Developer creates the converted model using the information from the captured model.
By default, all procedures, functions, triggers, and views are copied to the converted model during translation and translated to Oracle PL/SQL. However, if translation fails for any of the objects, those objects appear in the converted model but their original SQL code remains unchanged. Objects that remain in their original SQL code will not be used when the generation scripts are created. Therefore, to have any such objects migrated, you must either fix the problem in the original SQL code before generating the script or edit the generated script to replace the original SQL code with valid PL/SQL code.
The conversion of the captured model to a converted model is done as part of Migrating Using the Migration Wizard. You can specify or accept the defaults for data mappings.
The following topic describes how to modify the converted model, if this becomes necessary:
2.2.6.1 Correcting Errors in the Converted Model
If error messages with the prefix Parse Exception are listed in the migration log, manual intervention is required to resolve the issues. To complete the converted model:
-
Note the converted model schema object that failed.
-
Select that schema object in the converted model.
-
Copy the schema objects DDL and paste it into the translation scratch editor (displayed by clicking Migration, then Translation Scratch Editor).
-
Inspect the properties on the schema object in the translation scratch editor for possible causes of the error.
-
Modify a property of the schema object in the translation scratch editor.
For example, you might comment out one line of a stored procedure.
-
Translate using the appropriate translator.
-
If the error appears again, repeat steps 2 to 6.
-
If the error cannot be resolved in this way, it is best to modify the object manually in the converted model.
2.2.7 Generating the DDL for the Oracle Schema Objects
To generate the DDL statements to create the Oracle schema objects, you must already have captured the captured model and created the converted model. After you generate the DDL, you can run the DDL statements to cause the objects to be created in the Oracle database. At this point, the database schema is migrated to Oracle.
After you generate and run the DDL statements to migrate the schema objects, you can migrate the data from the original source database, as explained in Section 2.2.8.
2.2.8 Migrating the Data
The Migration Wizard lets you choose whether to migrate (move) any existing data from the source database to the Oracle database. If you choose to migrate the data:
-
If you are performing migration in online mode, you can perform the data migration in online or offline mode.
-
If you are performing the migration in offline mode, the data migration is included in the generated files.
Online data moves are suitable for small data sets, whereas offline data moves are useful for moving large volumes of data.
2.2.8.1 Transferring the Data Offline
To transfer the data offline, you generate and use scripts to copy data from the source database to the destination database. During this process you must:
-
Use SQL Developer to generate the data unload scripts for the source database and corresponding data load scripts for the destination database.
-
Run the data unload scripts to create data files from the source database using the appropriate procedure for your source database:
-
Creating Data Files From Microsoft SQL Server or Sybase Adaptive Server
-
For IBM DB2, see the chapter about offline data loading in Oracle SQL Developer Supplementary Information for IBM DB2 Migrations.
-
For Teradata, perform the offline data move using BTEQ and SQL*Loader.
-
-
Run the data load scripts using SQL*Loader to populate the destination database with the data from these data files as described in Section 2.2.8.1.4.
2.2.8.1.1 Creating Data Files From Microsoft SQL Server or Sybase Adaptive Server
To create data files from a Microsoft SQL Server or Sybase Adaptive Server database:
-
Copy the contents of the directory where SQL Developer generated the data unload scripts onto the computer where the source database is installed.
-
Edit the BCP extract script to include the name of the source database server.
-
On Windows, edit the
unload_script.batscript to alter the bcp lines to include the appropriate variables.
The following shows a line from a sample
unload_script.batscript:bcp "AdventureWorks.dbo.AWBuildVersion" out "[AdventureWorks].[dbo].[AWBuildVersion].dat" -q -c -t "<EOFD>" -r "<EORD>" -U<Username> -P<Password> -S<ServerName>
-
-
Run the BCP extract script.
-
On Windows, enter:
prompt> unload_script.bat
This script creates the data files in the current directory.
-
-
Copy the data files and scripts, if necessary, to the target Oracle database system, or to a system that has access to the target Oracle database and has SQL*Loader (Oracle Client) installed.
2.2.8.1.2 Creating Data Files From Microsoft Access
To create data files from a Microsoft Access database, use the Exporter for Microsoft Access tool.
Note:
For information about how to create data files from a Microsoft Access database, see online help for the exporter tool.2.2.8.1.3 Creating Data Files From MySQL
To create data files from a MySQL database:
-
Copy the contents of the directory where SQL Developer generated the data unload scripts, if necessary, onto the system where the source database is installed or a system that has access to the source database and has the mysqldump tool installed.
-
Edit the
unload_scriptscript to include the correct host, user name, password, and destination directory for the data files.-
On Windows, edit the
unload_script.batscript. -
On Linux or UNIX, edit the
unload_script.shscript.
The following shows a line from a sample
unload_script.batscript:mysqldump -h localhost -u <USERNAME> -p<PASSWORD> -T <DESTINATION_PATH> --fields-terminated-by="<EOFD>" --fields-escaped-by="" --lines-terminated-by="<EORD>" "CarrierDb" "CarrierPlanTb"
Edit this line to include the correct values for USERNAME, PASSWORD, and DESTINATION PATH. Do not include the angle brackets in the edited version of this file.
In this command line,
localhostindicates a loopback connection, which is required by the -T option. (See the mysqldump documentation for more information.) -
-
Run the script.
-
On Windows, enter:
prompt> unload_script.bat
-
On Linux or UNIX, enter:
prompt> chmod 755 unload_script.sh prompt> sh ./unload_script.sh
This script creates the data files in the current directory.
-
-
Copy the data files and scripts, if necessary, to the target Oracle database system, or to a system that has access to the target Oracle database and has SQL*Loader (Oracle Client) installed.
2.2.8.1.4 Populating the Destination Database Using the Data Files
To populate the destination database using the data files, you run the data load scripts using SQL*Loader:
-
Navigate to the directory where you created the data unload scripts.
-
Edit the
oracle_ctl.bat(Windows systems) ororactl_ctl.sh(Linux or UNIX systems) file, to provide the appropriate user name and password strings. -
Run the SQL Load script.
-
On Windows, enter:
prompt> oracle_ctl.bat
-
On Linux or UNIX, enter:
prompt> ./oracle_ctl.sh
-
For Microsoft SQL Server and Sybase migrations, if you are inserting into BLOB fields with SQL*Loader, you will receive the following error:
SQL*Loader-309: No SQL string allowed as part of LARGEOBJECT field specification
To handle situations indicated by this error, you can use either one of the following options:
-
Enable the Generate Stored Procedure for Migrate Blobs Offline SQL Developer preference (see Migration: Generation Options).
-
Use the following Workaround.
The workaround is to load the data (which is in hex format) into an additional CLOB field and then convert the CLOB to a BLOB through a PL/SQL procedure.
The only way to export binary data properly through the Microsoft SQL Server or Sybase Adaptive Server BCP is to export it in a hexadecimal (hex) format; however, to get the hex values into Oracle, save them in a CLOB (holds text) column, and then convert the hex values to binary values and insert them into the BLOB column. The problem here is that the HEXTORAW function in Oracle only converts a maximum of 2000 hex pairs. Consequently, write your own procedure that will convert (piece by piece) your hex data to binary. (In the following steps and examples, modify the START.SQL and FINISH.SQL to reflect your environment.
The following shows the code for two scripts, start.sql and finish.sql, that implement this workaround. Read the comments in the code, and modify any SQL statements as needed to reflect your environment and your needs.
Note:
After you runstart.sql and before you run finish.sql, run BCP; and before you run BCP, change the relevant line in the .ctl file from:
<blob_column> CHAR(2000000) "HEXTORAW (:<blob_column>)"
to:
<blob_column>_CLOB CHAR(2000000)
-- START.SQL -- Modify this for your environment. -- This should be executed in the user schema in Oracle that contains the table. -- DESCRIPTION: -- ALTERS THE OFFENDING TABLE SO THAT THE DATA MOVE CAN BE EXECUTED -- DISABLES TRIGGERS, INDEXES AND SEQUENCES ON THE OFFENDING TABLE -- 1) Add an extra column to hold the hex string; alter table <tablename> add (<blob_column>_CLOB CLOB); -- 2) Allow the BLOB column to accept NULLS alter table <tablename> MODIFY <blob_column> NULL; -- 3) Disable triggers and sequences on <tablename> alter trigger <triggername> disable; alter table <tablename> drop primary key cascade; drop index <indexname>; -- 4) Allow the table to use the tablespace alter table <tablename> move lob (<blob_column>) store as (tablespace lob_tablespace); alter table <tablename> move lob (<blob_column>_clob) store as (tablespace lob_tablespace); COMMIT; -- END OF FILE -- FINISH.SQL -- Modify this for your enironment. -- This should be executed in the table schema in Oracle. -- DESCRIPTION: -- MOVES THE DATA FROM CLOB TO BLOB -- MODIFIES THE TABLE BACK TO ITS ORIGINAL SPEC (without a clob) -- THEN ENABLES THE SEQUENCES, TRIGGERS AND INDEXES AGAIN -- Currently we have the hex values saved as -- text in the <blob_column>_CLOB column -- And we have NULL in all rows for the <blob_column> column. -- We have to get BLOB locators for each row in the BLOB column -- put empty blobs in the blob column UPDATE <tablename> SET <blob_column>=EMPTY_BLOB(); COMMIT; -- create the following procedure in your table schema CREATE OR REPLACE PROCEDURE CLOBTOBLOB AS inputLength NUMBER; -- size of input CLOB offSet NUMBER := 1; pieceMaxSize NUMBER := 2000; -- the max size of each peice piece VARCHAR2(2000); -- these pieces will make up the entire CLOB currentPlace NUMBER := 1; -- this is where were up to in the CLOB blobLoc BLOB; -- blob locator in the table clobLoc CLOB; -- clob locator pointsthis is the value from the dat file -- THIS HAS TO BE CHANGED FOR SPECIFIC CUSTOMER TABLE -- AND COLUMN NAMES CURSOR cur IS SELECT <blob_column>_clob clob_column , <blob_column> blob_column FROM /*table*/<tablename> FOR UPDATE; cur_rec cur%ROWTYPE; BEGIN OPEN cur; FETCH cur INTO cur_rec; WHILE cur%FOUND LOOP --RETRIVE THE clobLoc and blobLoc clobLoc := cur_rec.clob_column; blobLoc := cur_rec.blob_column; currentPlace := 1; -- reset evertime -- find the lenght of the clob inputLength := DBMS_LOB.getLength(clobLoc); -- loop through each peice LOOP -- get the next piece and add it to the clob piece := DBMS_LOB.subStr(clobLoc,pieceMaxSize,currentPlace); -- append this piece to the BLOB DBMS_LOB.WRITEAPPEND(blobLoc, LENGTH(piece)/2, HEXTORAW(piece)); currentPlace := currentPlace + pieceMaxSize ; EXIT WHEN inputLength < currentplace; END LOOP; FETCH cur INTO cur_rec; END LOOP; END CLOBtoBLOB; / -- now run the procedure -- It will update the blob column with the correct binary representation -- of the clob column EXEC CLOBtoBLOB; -- drop the extra clob cloumn alter table <tablename> drop column <blob_column>_clob; -- 2) apply the constraint we removed during the data load alter table <tablename> MODIFY FILEBINARY NOT NULL; -- Now re enable the triggers, indexes and primary keys alter trigger <triggername> enable; ALTER TABLE <tablename> ADD ( CONSTRAINT <pkname> PRIMARY KEY ( <column>) ) ; CREATE INDEX <index_name> ON <tablename>( <column> ); COMMIT; -- END OF FILE
2.2.9 Making Queries Case Insensitive
With several third-party databases, it is common for queries to be case insensitive. For example, in such cases the following queries return the same results:
SELECT * FROM orders WHERE sales_rep = 'Oracle'; SELECT * FROM orders WHERE sales_rep = 'oracle'; SELECT * FROM orders WHERE sales_rep = 'OrAcLe';
If you want queries to be case insensitive for a user in the Oracle database, you can create an AFTER LOGON ON DATABASE trigger, in which you set, for that database user, the NLS_SORT session parameter to an Oracle sort name with _CI (for "case insensitive") appended.
The following example causes queries for user SMITH to use the German sort order and to be case insensitive:
CREATE OR REPLACE TRIGGER set_sort_order AFTER LOGON ON DATABASE
DECLARE
username VARCHAR2(30);
BEGIN
username:=SYS_CONTEXT('USERENV','SESSION_USER');
IF username LIKE 'SMITH' then
execute immediate 'alter session set NLS_COMP=LINGUISTIC';
execute immediate 'alter session set NLS_SORT=GERMAN_CI';
END IF;
END;
2.2.10 Testing the Oracle Database
During the testing phase, you test the application and Oracle database to make sure that the:
-
Migrated data is complete and accurate
-
Applications function in the same way as the source database
-
Oracle database produces the same results as the source database
-
Applications and Oracle database meet the operational and performance requirements
You may already have a collection of unit tests and system tests from the original application that you can use to test the Oracle database. You should run these tests in the same way that you ran tests against the source database. However, regardless of added features, you should ensure that the application connects to the Oracle database and that the SQL statements it issues produces the correct results.
Note:
The tests that you run against the application vary depending on the scope of the application. Oracle recommends that you thoroughly test each SQL statement that is changed in the application. You should also test the system to make sure that the application functions the same way as in the third-party database.See also the following:
2.2.10.1 Testing Methodology
Many constraints shape the style and amount of testing that you perform on a database. Testing can contain one or all of the following:
-
Simple data validation
-
Full life cycle of testing addressing individual unit tests
-
System and acceptance testing
You should follow a strategy for testing that suits your organization and circumstances. Your strategy should define the process by which you test the migrated application and Oracle database. A typical test method is the V-model, which is a staged approach where each feature of the database creation is mirrored with a testing phase.
Figure 2-2, "V-model with a Database Migration" shows an example of the V-model with a database migration scenario:
Figure 2-2 V-model with a Database Migration
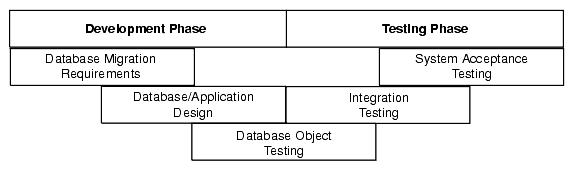
Description of "Figure 2-2 V-model with a Database Migration"
There are several types of tests that you use during the migration process. During the testing stage, you go through several cycles of testing to enhance the quality of the database. The test cases you use should make sure that any issues encountered in a previous version of the Oracle database are not introduced again.
For example, if you have to make changes to the migrated schema based on test results, you may need to create a new version of the Oracle database schema. In practice, you use SQL Developer to create a base-line Oracle schema at the start of testing, and then edit this schema as you progress with testing.
Note:
Oracle recommends that you track issues that you find during a testing cycle in an issue tracking system. Track these issues against the version of the database or application that you are testing.2.2.10.2 Testing the Oracle Database
Use the test cases to verify that the Oracle database provides the same business logic results as the source database.
Note:
Oracle recommends that you define completion criteria so that you can determine the success of the migration.This procedure explains one way of testing the migrated database. Other methods are available and may be more appropriate to your business requirements.
To test the Oracle database:
-
Create a controlled version of the migrated database.
Oracle recommends that you keep the database migration scripts in a source control system.
-
Design a set of test cases that you can use to test the Oracle database from unit to system level. The test cases should:
-
Ensure the following:
-
All the users in the source database have migrated successfully
-
Privileges and grants for users are correct
-
Tables have the correct structure, defaults are functioning correctly, and errors did not occur during mapping or generation
-
-
Validate that the data migrated successfully by doing the following:
-
Comparing the number of rows in the Oracle database with those in the source database
-
Calculating the sum of numerical columns in the Oracle database and compare with those in the source database
-
-
Ensure that the following applies to constraints:
-
You cannot enter duplicate primary keys
-
Foreign keys prevent you from entering inconsistent data
-
Check constraints prevent you from entering invalid data
-
-
Check that indexes and sequences are created successfully.
-
Ensure that views migrated successfully by doing the following:
-
Comparing the number of rows in the Oracle database with those in the source database
-
Calculating the sum of numerical columns in the Oracle database and compare with those in the source database
-
-
Ensure that triggers, procedures, and functions are migrated successfully. Check that the correct values are returned for triggers and functions.
-
-
Run the test cases against the migrated database.
-
Create a report that evaluates the test case results.
These reports allow you to evaluate the data to qualify the errors, file problem reports, and provide a customer with a controlled version of the database.
-
If the tests pass, go to step 7.
If all tests in the test cases pass or contain acceptable errors, the test passes. If acceptable errors occur, document them in an error report that you can use for audit purposes.
-
If the test cases fail:
-
Identify the cause of the error.
-
Identify the test cases needed to check the errors.
-
Log an issue on the controlled version of the migrated database code in the problem report.
-
Add the test case and a description of the problem to the incident tracking system of your organization, which could be a spreadsheet or bug reporting system. Aside from the test case, the incident log should include the following:
-
Provide a clear, concise description of the incident encountered
-
Provide a complete description of the environment, such as platform and source control version
-
Attach the output of the test, if useful
-
Indicate the frequency and predictability of the incident
-
Provide a sequence of events leading to the incident
-
Describe the effect on the current test, diagnostic steps taken, and results noted
-
Describe the persistent after effect, if any
-
-
Attempt to fix the errors.
-
Return to step 1.
-
-
Identify acceptance tests that you can use to make sure the Oracle database is an acceptable quality level.
2.2.10.2.1 Guidelines for Creating Tests
You may already have a collection of unit tests and system tests from the original application that you can use to test the Oracle database. However, if you do not have any unit or system tests, you need to create them. When creating test cases, use the following guidelines:
-
Plan, specify, and execute the test cases, recording the results of the tests.
The amount of testing you perform is proportional to the time and resources that are available for the migration project. Typically, the testing phase in a migration project can take anywhere from 40% to 60% of the effort for the entire project.
-
Identify the components that you are testing, the approach to the test design and the test completion criteria.
-
Define each test case so that it is reproducible.
A test that is not reproducible is not acceptable for issue tracking or for an audit process.
-
Divide the source database into functions and procedures and create a test case for each function or procedure. In the test case, state what you are going to test, define the testing criteria, and describe the expected results.
-
Record the expected result of each test case.
-
Verify that the actual results meet the expected results for each test.
-
Define test cases that produce negative results as well as those that you expect a positive result.
2.2.10.2.2 Example of a Unit Test Case
The following displays a sample unit test plan for Windows:
Name Jane Harrison
Module Table Test Emp
Date test completed 23 May 2007
Coverage log file location mwb\database\TableTestEmp
Description This unit test tests that the emp table was migrated successfully.
Reviewed by John Smith
| Task ID | Task Description | Expected Result | Verified (Yes/No) |
|---|---|---|---|
| 1 | Run the following on the source database for each table:
select count(*) from emp Run the following on the destination database for each table: select count(*) from emp |
On the source database, the count(*) produces a number. In this case, the number is the number of rows in each table.
On the destination database, the count(*) number corresponds to the number of rows in the new Oracle table. |
Yes
The number of rows in each table is the same in the source and destination databases. |
| 2 | Run the following on the source database for each table:
select sum(salary) from emp Run the following on the destination database for each table: select sum(salary) from emp |
On the source database, sum(salary) produces a check sum for the sum of the data in each table.
On the destination database, sum(salary) corresponds to the sum of the salary in the emp table. |
Yes
The sum for each table is the same in the source and destination databases. |
2.2.11 Deploying the Oracle Database
Deploying the migrated and tested Oracle database within a business environment can be difficult. Therefore, you may need to consider different rollout strategies depending on your environment. Several rollout strategies are identified for you, but you may use another approach if that is recommended by your organization.
During the deployment phase, you move the destination database from a development to a production environment. A group separate from the migration and testing team, may perform the deployment phase, such as the in-house IT department.
Deployment involves the following:
2.2.11.1 Choosing a Rollout Strategy
The strategy that you use for migrating a third-party database to an Oracle database must take into consideration the users and the type of business that may be affected during the transition period. For example, you may use the Big Bang approach because you do not have enough systems to run the source database and Oracle database simultaneously. Otherwise, you may want to use the Phased approach to make sure that the system is operating in the user environment correctly before it is released to the general user population. You can use one of the following approaches.
2.2.11.1.1 Phased Approach
Using the Phased approach, you migrate groups of users at different times. You may decide to migrate a department or a subset of the complete user-base. The users that you select should represent a cross-section of the complete user-base. This approach allows you to profile users as you introduce them to the Oracle database. You can reconfigure the system so that only selected users are affected by the migration and unscheduled outages only affect a small percentage of the user population. This approach may affect the work of the users you migrated. However, because the number of users is limited, support services are not overloaded with issues.
The Phased approach allows you to debug scalability issues as the number of migrated users increases. However, using this approach may mean that you must migrate data to and from legacy systems during the migration process. The application architecture must support a phased approach.
2.2.11.1.2 Big Bang Approach
Using the Big Bang approach, you migrate all of the users at the same time. This approach may cause schedule outages during the time you are removing the old system, migrating the data, deploying the Oracle system, and testing that the system is operating correctly. This approach relies on you testing the database on the same scale as the original database. It has the advantage of minimal data conversion and synchronization with the original database because that database is switched off. The disadvantage is that this approach can be labor intensive and disruptive to business activities due to the switch over period needed to install the Oracle database and perform the other migration project tasks.
2.2.11.1.3 Parallel Approach
Using the Parallel approach, you maintain both the source database and destination Oracle database simultaneously. To ensure that the application behaves the same way in the production environment for the source database and destination database, you enter data in both databases and analyze the data results. The advantage of this approach is if problems occur in the destination database, users can continue using the source database. The disadvantage of the Parallel approach is that running and maintaining both the source and the destination database may require more resources and hardware than other approaches.
2.2.11.2 Deploying the Destination Database
There are several ways to deploy the destination database. The following task is an example that you should use as a guideline for deploying the destination database.
Note:
If you have a complex scenario as defined in Table 2-1, Oracle recommends that you complete all of the deployment tasks. However, if you have a simple scenario, you should choose the deployment tasks appropriate to your organization.-
Configure the hardware, if necessary.
In a large scale or complex environment, you must design the disk layout to correspond with the database design. If you use redundant disks, align them in stripes that you can increase as the destination database evolves. You must install and configure the necessary disks, check the memory, and configure the system.
-
Make sure the operating system meets the parameters of the Oracle configuration.
Before installing any Oracle software, make sure that you have modified all system parameters. For more information about modifying system parameters, see the relevant installation guide for your platform, such as Solaris Operating System.
-
Install the Oracle software.
Aside from the Oracle software that allows you to create an Oracle database, you may need to install ancillary software to support the application, such as Extract Transformation and Load (ETL) Software for data warehousing.
-
Create the destination database from the source database and migrate the data to the Oracle database.
There are several ways of putting the destination database into production after testing it, such as:
-
Place the successfully tested database into production. The test system is now the production system.
-
Use Oracle Export to extract the destination database from the successfully tested database and use Oracle Import to create that database within the production environment.
-
Use the tested migration scripts to create the Oracle database and populate it with data using SQL*Loader.
-
-
Perform the final checks on the destination database and applications.
-
Place the destination database into production using one of the rollout strategies.
-
Perform a final audit by doing the following:
-
Audit the integrity of the data
-
Audit the validity of the processes, such as back-up and recovery
-
Obtain sign-off for the project, if necessary
-
2.3 SQL Developer User Interface for Migration
If you are performing database migration, you need to use some migration-specific features in addition to those described in Section 1.2, "SQL Developer User Interface". The user interface includes an additional navigator (Migration Projects), a Migration submenu under Tools, and many smaller changes throughout the interface. Figure 2-3, "Main Window for a Database Migration" shows the SQL Developer main window with objects reflecting the migration of a Microsoft Access application named sales.mdb. It also shows the Migration Submenu.

In this figure:
-
The Connections navigator shows two database connections:
sales_accessconnected to a Microsoft Access database named sales.mdb, andsales_oracleconnected to an Oracle user named SALES whose schema owns the migrated schema objects. Not shown is themigration_repositoryconnection (to a user named MIGRATION) used for the migration repository. -
The Migration Projects navigator shows one captured model, which was created using an XML file created by the exporter tool for Access applications. (If the source database is a type other than Microsoft Access, the procedure for creating the captured model is different: you can generate it directly from the source database connection.)
The Migration Projects navigator also shows one converted model, which is an Oracle representation of the source database. The converted model is created from the captured model, and the converted model is used to generate the schema objects that you can see using an Oracle database connection (
sales_oraclein this figure).
2.3.1 Migration Submenu
The Migration submenu contains options related to migrating third-party databases to Oracle. To display the Migration submenu, click Tools, then Migration.
Migrate: Displays a wizard for performing an efficient migration. The wizard displays steps and options relevant to your specified migration.
Repository Management: Enables you to create, delete, or truncate (remove all data from) a migration repository; select the current migration repository; and disconnect from the current migration repository (which deactivates the current repository but does not disconnect from the database).
Microsoft Access Exporter: Contains submenu items from which you specify the version of the exporter tool to use to create an XML file to be used for creating the captured model. You can also use the exporter tool to export table data. Specify the exporter tool version for the version of Access that is on your PC and that was used to create the .mdb file.
Create Database Capture Scripts specifies options for creating script files, including an offline capture properties (.ocp) file, which you can later load and run.
Translation Scratch Editor: Displays the translation scratch editor, which is explained in Section 2.3.5.
2.3.2 Other Menus: Migration Items
The View menu has the following item related to database migration:
-
Migration Projects: Displays the Migration Projects navigator, which includes any captured models and converted models in the currently selected migration repository.
2.3.3 Migration Preferences
The SQL Developer user preferences window (displayed by clicking Tools, then Preferences) contains a Migration pane with several related subpanes, and a Translation pane with a Translation Preferences subpane.
For information about these preferences, click Help in the pane, or see Section 1.18.11, "Migration".
2.3.4 Migration Log Panes
Migration Log: Contains errors, warnings, and informational messages relating to migration operations.
Logging Page: Contains an entry for each migrated-related operation.
Data Editor Log: Contains entries when data is being manipulated by SQL Developer. For example, the output of a Microsoft Excel import operation will be reported here as a series of INSERT statements.
2.3.5 Using the Translation Scratch Editor
You can use the translation scratch editor to enter third-party database SQL statements and have them translated to Oracle PL/SQL statements. You can specify translation from Microsoft SQL Server T-SQL to PL/SQL, from Sybase T-SQL to PL/SQL, or from Microsoft Access SQL to PL/SQL.
You can display the scratch editor by clicking Tools, then Migration, then Translation Scratch Editor. The scratch editor consists of two SQL Worksheet windows side by side, as shown in the following figure:
To translate a statement to its Oracle equivalent, select the type of translation, enter the third-party SQL statement or statements; select the specific translation from the Translator drop-down (for example, Access SQL to PL/SQL) and optionally the applicable schema from the Captured Schema drop-down; then click the Translate (>>) icon to display the generated PL/SQL statement or statements.
SQL keywords are automatically highlighted.
Note:
For a Microsoft SQL Server or Sybase Adaptive Server connection, the worksheet does not support running T-SQL statements. It only supports SELECT, CREATE, INSERT, UPDATE, DELETE, and DROP statements.The first time you save the contents of either worksheet window in the translation scratch editor, you are prompted for the file location and name. If you perform any subsequent Save operations (regardless of whether you have erased or changed the content of the window), the contents are saved to the same file. To save the contents to a different file, click File, then Save As.
For detailed information about the worksheet windows, see Section 1.7, "Using the SQL Worksheet".
2.4 Command-Line Interface for Migration
As an alternative to using the SQL Developer graphical interface for migration operations, you can use the migration batch file (Windows) or shell script (Linux) on the operating system command line. These files are located in the sqldeveloper\sqldeveloper\bin folder or sqldeveloper/sqldeveloper/bin directory under the location where you installed SQL Developer.
migration.bat or migration.sh accepts these commands: capture, convert, datamove, delcaptured, delconn, delconverted, driver, generate, guide, help, idmap, info, init, lscaptured, lsconn, lsconverted, mkconn, qm, runsql, and scan. For information about the syntax and options, start by running migration without any parameters at the system command prompt. For example:
C:\Program Files\sqldeveloper\sqldeveloper\bin>migration
You can use the -help option for information about one or more actions. For the most detailed information, including some examples, use the -help=guide option. For example:
C:\Program Files\sqldeveloper\sqldeveloper\bin>migration -help=guide