| Oracle® Health Sciences Translational Research Center User's Guide Release 3.0.2.1 E35681-09 |
|
|
PDF · Mobi · ePub |
| Oracle® Health Sciences Translational Research Center User's Guide Release 3.0.2.1 E35681-09 |
|
|
PDF · Mobi · ePub |
This chapter contains the following topics:
Note:
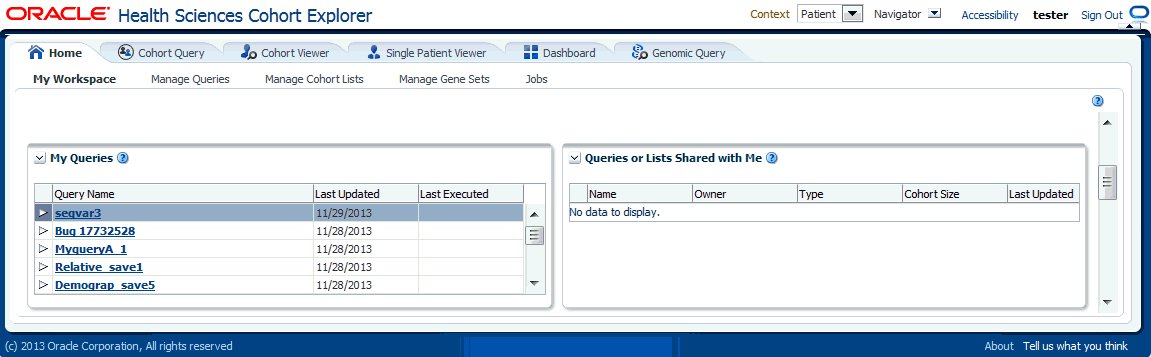
If the Oracle Health Sciences Cohort Explorer user runs into issues resulting in Internet Explorer 11 (IE 11) incompatibility, refer to the Oracle® Health Sciences Translational Research Center Installation Guide for upgrade patch instructions to resolve them.The My Workspace page is the default page for Oracle Health Sciences Cohort Explorer (CE) and Oracle Health Sciences Omics Data Bank (ODB) user. Depending on the license purchased, you may have access to most or all of the reports on this web page. With a standalone CE license, you can only view the Cohort Queries and Cohort Lists details. If an ODB license is also available, the My Gene Sets details are also displayed.
This lists the most recent saved cohort query, cohort list, and gene set, which provides the quick access to the recent work.
This lists the most recent saved patient cohort queries, sorted by the last updated date. Clicking the selected query will load it in the Cohort Query window.
This lists the most recently saved cohort lists sorted by the last updated date. Clicking the selected list will load it in the Cohort Viewer/Cohort List window.
The My Gene Sets report lists the most recently updated gene sets. Clicking the selected gene sets will load it in the Manage Gene Sets/Manage window.
This lists all queries and lists that are shared with you. Clicking the selected query will load it in the Cohort Query window. Clicking the selected list will load it in the Cohort Viewer/Cohort List window.
This section contains the following topic:
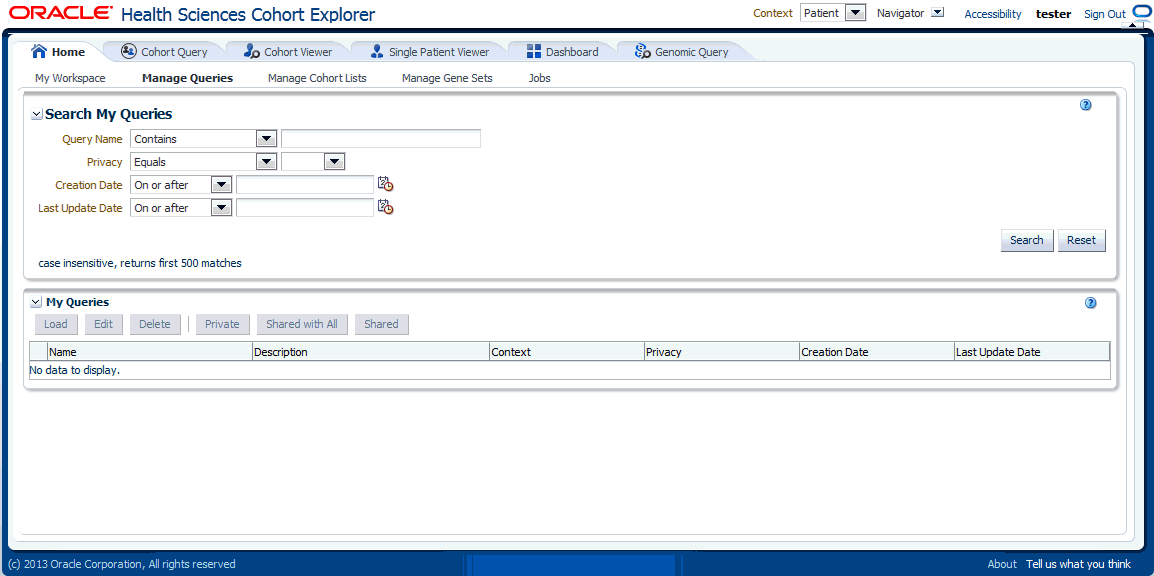
This section lists all the saved queries that you have access. You can filter the queries based on the search criteria given in the Search My Queries section. The query list displayed is irrespective of patient or subject context. You can load a query into the Cohort Query screen, edit a query, and delete a query.
If a shared query is selected, a list of users and groups is displayed in the table with whom it is shared.
While loading a query, if any criteria are already present in the Cohort Query section, it prompts you to append to the existing criteria or to clear and load the query. In case of different context, it prompts you to switch to the other context and load.
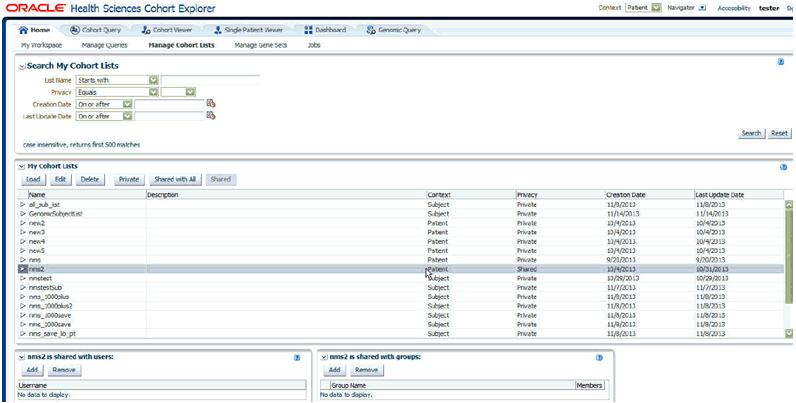
This section displays all the patient or subject lists that you created. You can filter the lists based on the search criteria given in the Search My Cohort Lists section. The list is irrespective of patient or subject context, as the context is shown as one of the columns. You can load a list into the Cohort List screen, edit a list, and delete a list.
If a shared list is selected, a list of users and groups will be shown below the table with whom it is shared.
While loading a list, if any list is already present in the Cohort List section, it prompts you to clear and load the list. In case of different context, it prompts you to switch to the other context and load.
Gene Set is intended to be used as a way to collect genes into groupings or lists. Frequently, there will be a list of genes you work with regularly. A set of such genes might be as small as a couple of genes or large, consisting of hundreds of genes. Often you may keep several such sets, each characterizing a group of genes with particular attributes, for example, transcription factors, genes involved in some regulation mechanism, genes that have been implicated to contribute to a particular characteristic and so on. The concept of Gene Set lets you group genes into convenient collections for reuse.
The Create New or Edit gene sets is a web interface that helps you group genes as a set. You can elect to group a few genes for quick search retrieval or for use in a cohort query. For example, if you have a set of 10 genes that you plan to work with or always search for results based on genes from within this particular array of 10, you can create a new Gene Set to collect these 10 genes into one group. A gene can be part of many different Gene Sets. Furthermore, you can create many different gene sets, each gene set with a different combinations of genes.
Note:
There are no restrictions regarding which genes can be included in any particular Gene Set. You may choose to mix genes from multiple species, or reference versions as the system does not enforce any such constraints.
Gene Sets currently are Private only and cannot be shared among users.
Gene Set names are not case- sensitive.
The limit for cut-and-paste option is 512 characters when genes are compared using Contains or Starts With option.
The file size limit for 'upload file' option is less than 5MB when genes are matched using Equals. When using Contains or Starts With option, the list of genes cannot be longer than 512 characters.
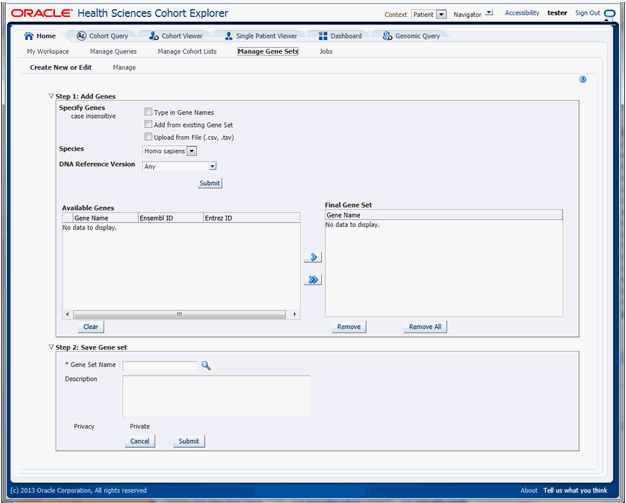
The Create New or Edit Gene Set screen is used for the following:
Creating a new Gene Set or
Editing an existing Gene Set
From this area, you can choose to:
Search for genes to be included in the gene set in ODB by using their Ensembl or HUGO names. You can enter multiple gene names separated by space, comma or semicolon. Additionally, you must specify the species and DNA version that a given gene is linked to. Once you click Submit, the matching genes appear on the left hand side pane. To add a gene to the Gene Set, use the arrow button to move the gene from the left panel to the right hand side.
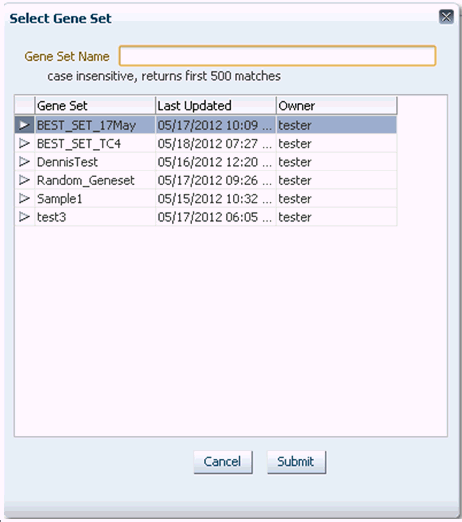
Search for genes based on an existing Gene Set. First, select the Gene Set to add genes from, then click Submit. The genes from the existing Gene Set appear in the left hand side panel.
Upload genes from a file. Select a text file from your desktop where the genes are delimited by comma, space or tab. Then click Submit and the genes that match genes in ODB will be loaded into left hand side panel.
You can select to move all genes from the left hand side panel to the right hand side panel. The genes in right hand side panel are those that will comprise a gene set.
Once you are satisfied with the selection of genes, you can either preserve the selection as a new Genet Set or save over an existing one. You can give the Gene Set a name and Description, and click Submit. The system saves the new Gene Set and a confirmation box appears.
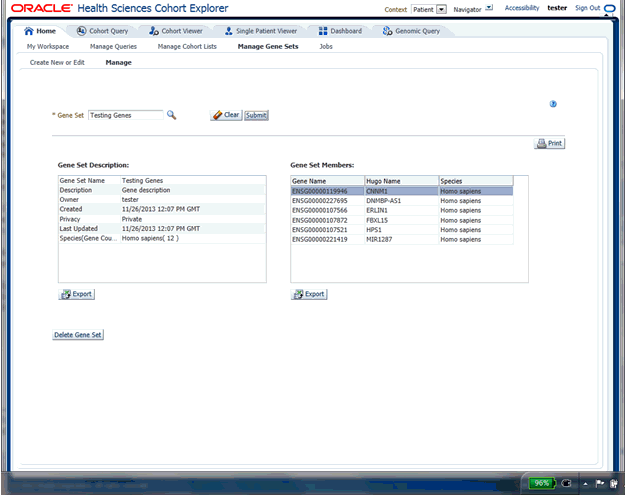
The Manage Gene Sets screen enables you to view the individual genes (members) included in a given Gene Set as well as the set's metadata. You can select a specific Gene Set to view by using its name and click Submit to view the Gene Set's detailed information.
Each Gene Set's metadata includes the name, description given by the user, owner of the gene set, privacy setting (currently all gene sets are Private only), the creation and update dates and summary of how many genes are in a gene set.
You can also export or print any of the Gene Set's data.
Finally, you can delete a Gene Set using the Delete button. A confirmation box appears to ensure you are performing the proper action.
Note:
Any Gene Set deletion is a soft-delete. A soft delete means that the actual Gene Set record is still in the database, but it can only be restored with the help of a System Administrator.Currently, jobs are scheduled only for Genomic Data Export. To schedule a job, navigate to Genomic Data Export screen under the Cohort Viewer tab.
Note:
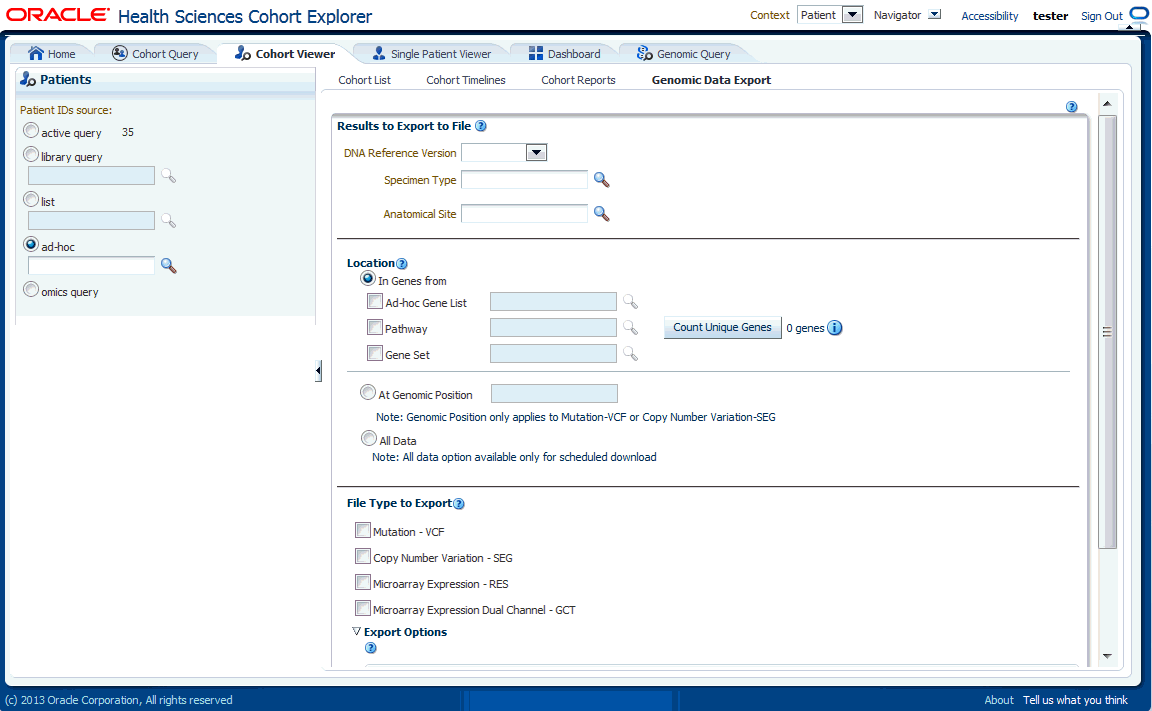
Any job executed prior to applying TRC 3.0.2 will have its status changed back to 'Scheduled'.The following screen demonstrates how to create and schedule the job.
To create and schedule a job, perform the following steps:
Select the patient IDs source from one of the following options:
active query
library query
list
ad-hoc
Omics query
Select the DNA reference version.
Select the location for the gene from the following options:
Ad-hoc Gene List
Pathway
Gene Set
Select one of the following file formats to export:
Mutation-VCF
Copy Number Variation-SEG
Microarray Expression-RES
Microarray Expression Dual Channel-GCT
Select the Schedule export option. This prompts for the job name and description.
Click Submit. The job ID is created.
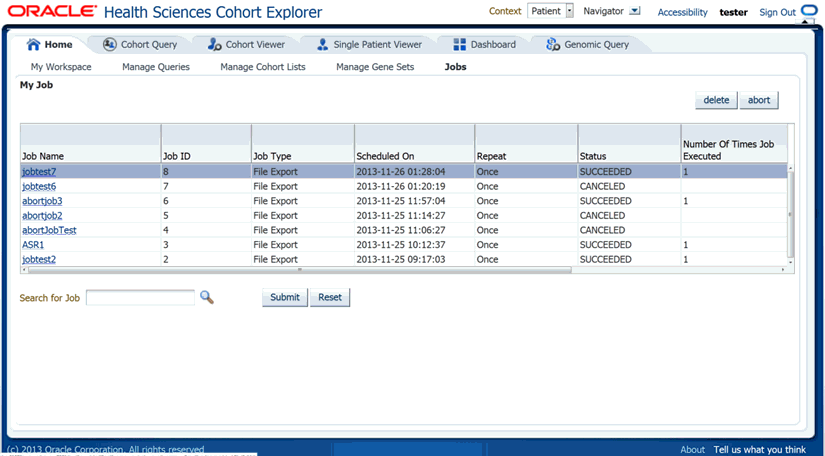
To view the information of this job and its progress, navigate to My Workspace, and click the Jobs tab.
Only the authorized user can see the job lists. The following table describes the columns and buttons in the My Job page.
Table 3-1 Columns and Buttons in My Jobs Page
| Column Name | Description |
|---|---|
|
Job name |
Job name specified when scheduling the job. |
|
Job ID |
Job ID generated while scheduling the job. |
|
Job type |
Only File Export job type is supported. |
|
Scheduled on |
Date and time on which the job is scheduled. The format is yyyy-MM-dd HH:mm:ss. |
|
Repeat |
You can schedule the job to run only once or recurrent. |
|
Status |
You can set the status to succeeded, failed, or canceled. |
|
No. of times job executed |
Count of how many times the job is run. |
|
First execution started |
Date and time when the job is scheduled to run. The format is yyyy-MM-dd HH:mm:ss. |
|
Last execution successfully completed |
Date and time when the job is last executed. The format is yyyy-MM-dd HH:mm:ss. |
|
Search |
You can search job by name or job ID. |
|
Reset |
You can reset your search criteria. |
|
Delete |
You can delete a job. A confirmation box appears to make sure you are performing the proper action. This is a soft delete, which means the job is still in the database but only the delete flag set to Y. |
|
Abort |
You can abort a job before it runs. You can also abort a queued or scheduled job but cannot abort a succeeded or canceled job. |
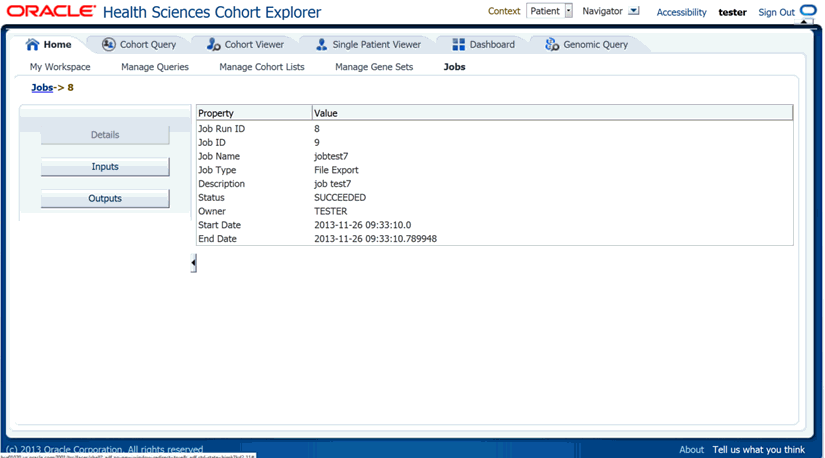
This section provides complete information of a job.
To view the job details, click the Jobs tab and click Details.
The following table describes job details.
| Column Name | Description |
|---|---|
|
Job run ID |
Job instance ID generated when job is scheduled. |
|
Job ID |
Job ID generated while scheduling the job. |
|
Job name |
Name of the job. |
|
Job type |
Only File Export job type is supported. |
|
Description |
Description of the job. |
|
Status |
Status of the job (succeeded, failed, or canceled). |
|
Owner |
User who created the job. |
|
Start date |
Date and time the job is scheduled to run. The format is yyyy-MM-dd HH:mm:ss. |
|
End date |
Date and time when the job is last executed. The format is yyyy-MM-dd HH:mm:ss. |
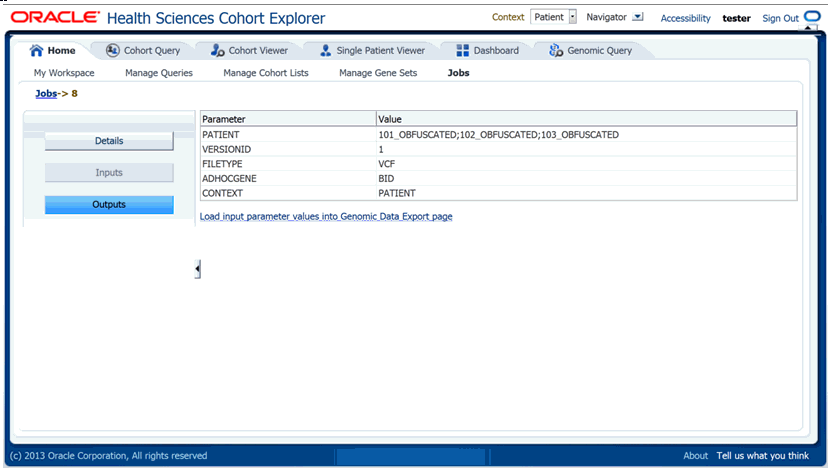
This section provides the details of parameters provided when scheduling a job.
To view the details of the job created, click the Jobs tab and click Inputs.
The Load input parameter values into Genomic Data Export page link directs you to the genomic data screen with these values loaded.
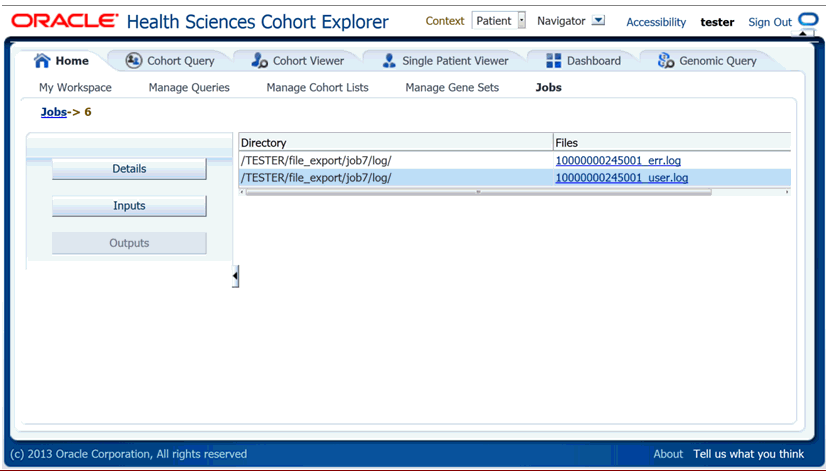
This section shows the result files of a job. The following files are generated:
Error log file - contains the log file of the application if any exception or error occurred while running the job.
User log file - contains the log file, which shows the error occurred while generating the export files.
Admin log file - is for DB administrator.
You can download error and user log files but cannot download the admin log file.
Note:
When you try to export a file that does not have any Patients or Subjects linked to the specimen, an empty file is generated in Schedule mode.
|
Copyright © 2013, 2015, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|