|
|

|

|

|

|
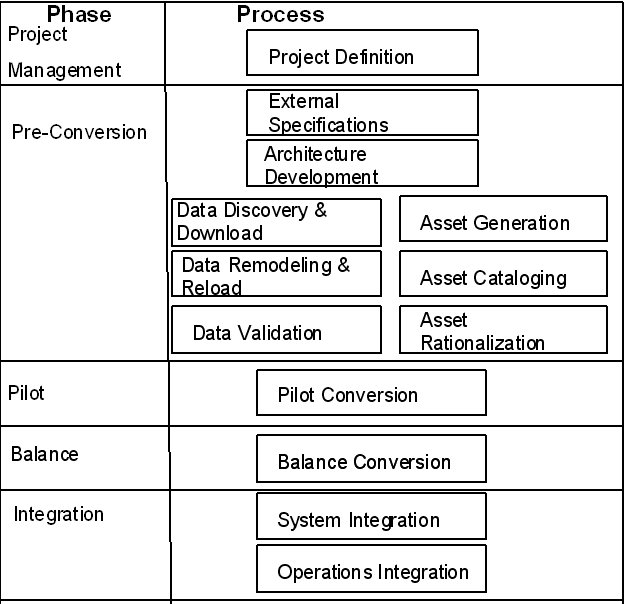
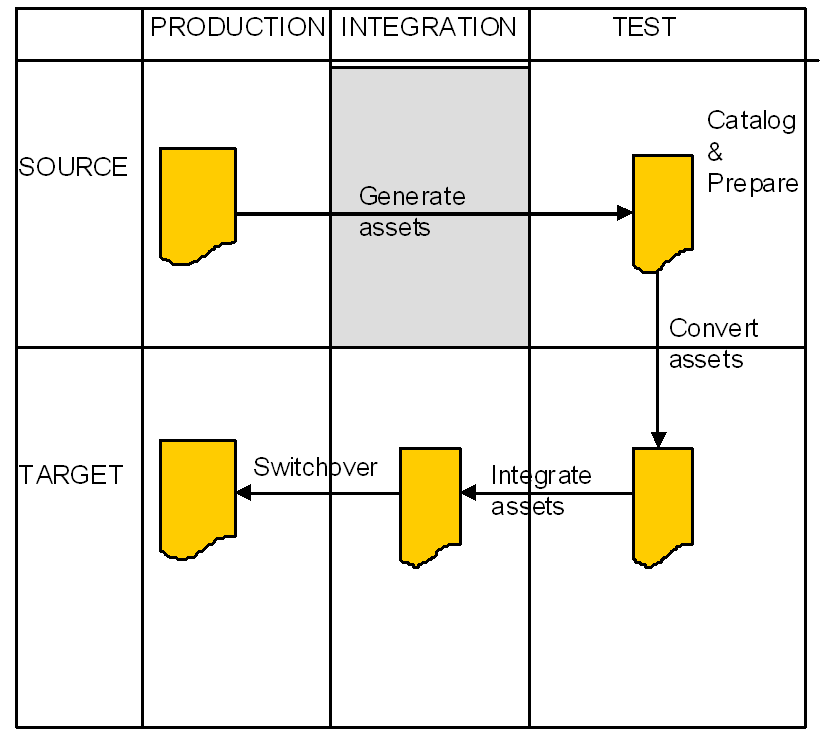
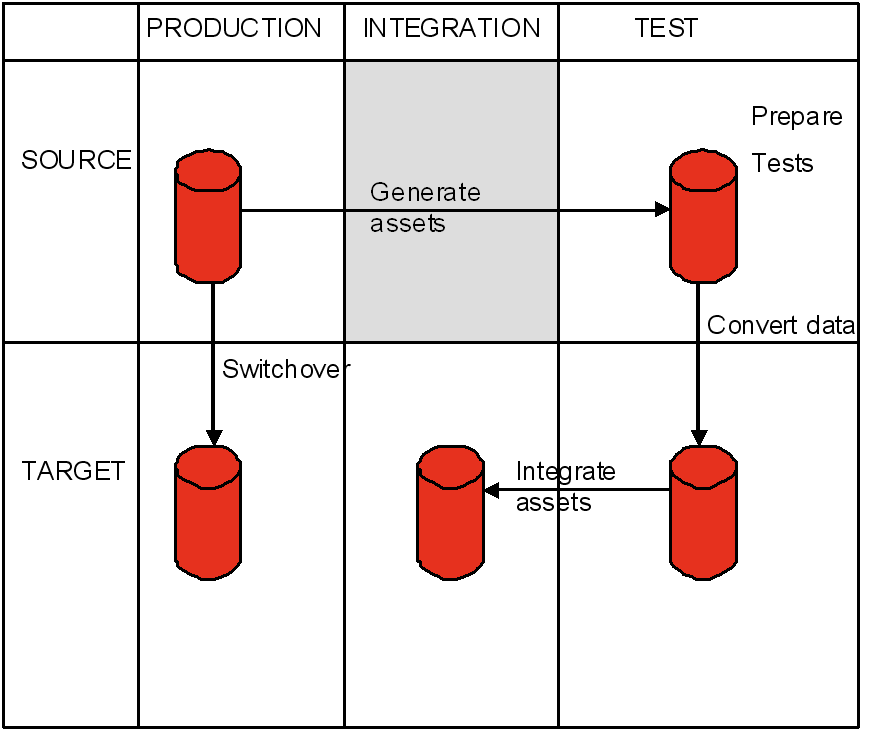
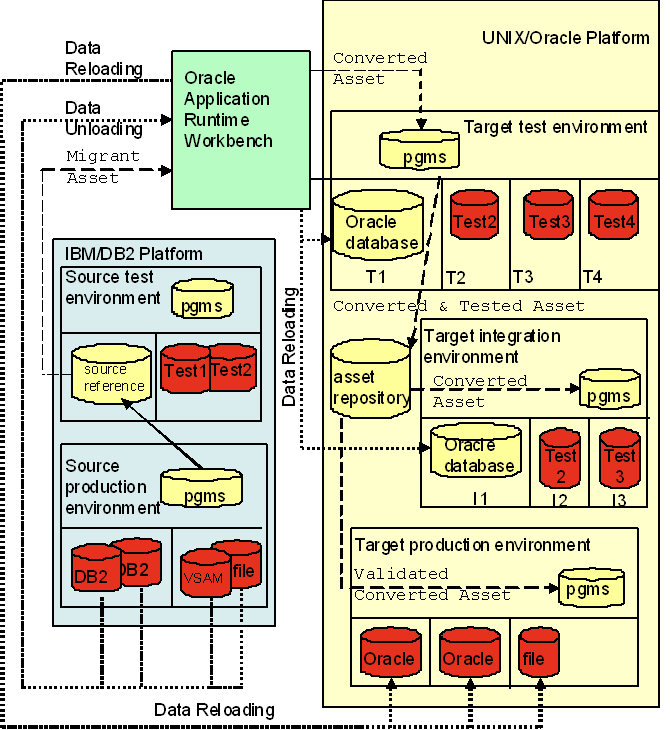
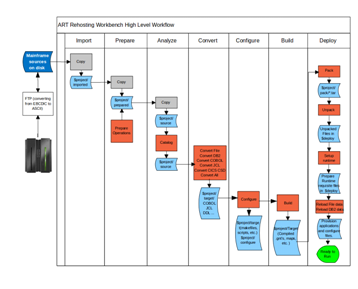
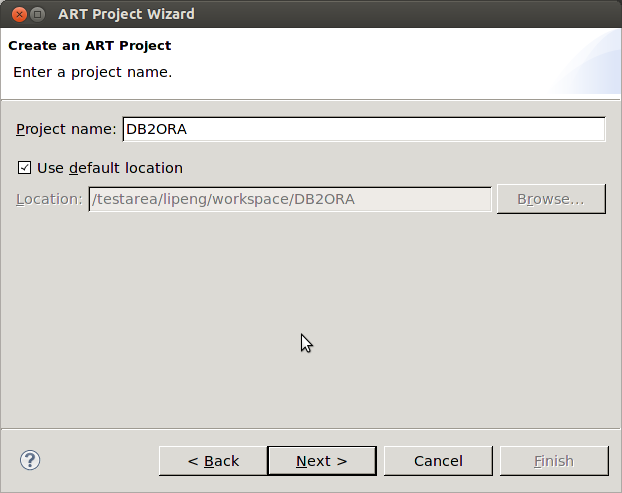
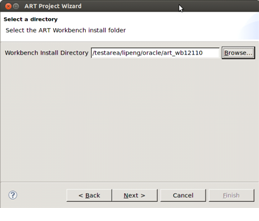
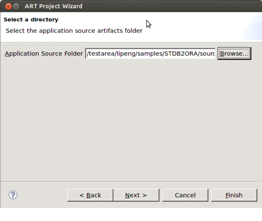
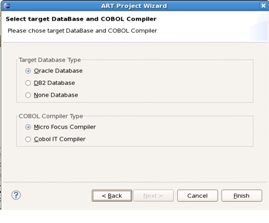
There are five clearly distinct environments necessary to carry-out a rehosting project. These include two source (pre-migration) environments and three target (post-migration) environments as described below: