Multidimensional Warehouse (MDW)
The Multidimensional Warehouse is the third data structure in EPM.
Image: Multidimensional Warehouse (MDW)
The following graphic illustrates the MDW component of the EPM architecture and the target tables that are present in the MDW.
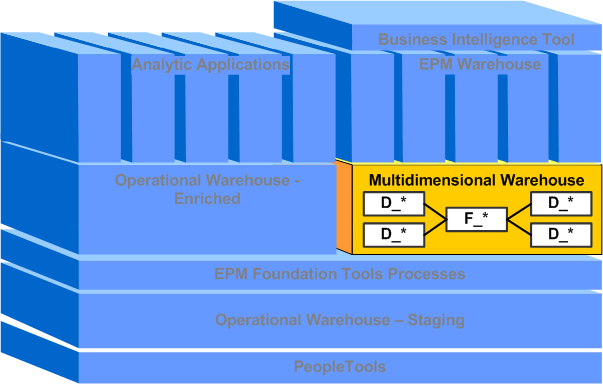
The MDW stores dimensionalized data that is grouped into one or more business processes, better known as a dimensional schema, used for business intelligence and ad hoc reporting. The data is stored in a star schema (a fact table associated with a series of dimension tables) and generally contains data loaded from the OWS.
The star schema arrangement depends entirely on primary key and foreign key relationships. A primary key is a column (or columns) in a dimension table whose values uniquely identify each row in the table. Primary keys enforce entity integrity by uniquely identifying entity instances. A foreign key is a column or columns in a fact table whose values match the primary key values of a given dimension table. This way references can be made between a fact and dimension table. Foreign keys enforce referential integrity by completing an association between two entities.
Note: MDW dimensions use a surrogate key, a unique key generated from production keys by the ETL process. The surrogate key is not derived from any data in the EPM database and acts as the primary key in a MDW dimension. See the next topic for more information on surrogate keys in the MDW.
Image: Dimensional Model Example
The following graphic provides an example of a star schema and its primary and foreign key relationships:
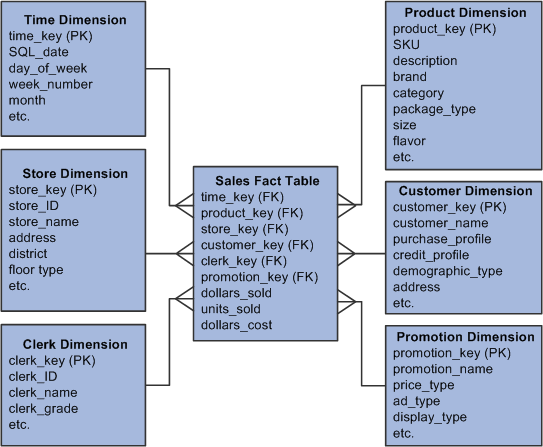
Although data loaded into the MDW is primarily derived from the OWS, there are exceptions to this rule. Profitability and Global Consolidations data for the Financial Management Solutions (FMS) Warehouse is loaded into the MDW from the OWE.
External survey data for the HCM Warehouse is loaded into the MDW from the OWE.
Online Marketing data is loaded into the MDW directly from the source system, and bypasses the Operational Warehouse entirely.
Surrogate Keys
Surrogate keys provide a means of defining unique keys whose values, with the exception of the Time and Calendar dimensions, are anonymous—that is, the value of a surrogate key has no significance to the application using it and is strictly an artificial value. The system uses surrogate keys specifically as a means of joining structures. To speed up query access, the MDW resolves PeopleSoft-specific programming constructs, such as SetIDs and effective dates and replaces them with surrogate IDs as key columns. Surrogate keys have no relationship to the business or production key. Surrogate keys are present in dimension tables as the primary key and in fact tables as foreign keys to dimensions. However, the dimension record retains the business key as an alternate-key attribute. Surrogate keys are four-byte integers and their size does not change even when production key changes in size.
Although surrogate keys usually do not have any "intelligence," that is, their value has no meaning, in certain situations, such as the Gregorian Calendar and Time dimensions, intelligent surrogate keys are used. These intelligent keys enable the ETL process to run more quickly by providing the option of avoiding a lookup on corresponding dimensions.
Surrogate key fields usually have the suffix _SID (Surrogate ID).
Surrogate Keys and the ETL Process
Surrogate keys are generated from production keys using the DataStage routine KeyMgtNextValueConcurent(), which receives an input parameter and a name identifying the sequence. The surrogate key can be unique per single dimension target (D) or unique across the whole (W) multidimensional warehouse. This process is enabled by the environment parameter named SID_UNIQUENESS. The value for this parameter is provided at run time. If the value is D, then this routine is called with a dimension job name for which a surrogate key must be assigned and it returns the next available number. If not, the routine is called with EPM as the sequence identifier.
You do not have to take any action to create surrogate keys; they are generated during the ETL process within the aforementioned DataStage routine. The DataStage routine retrieves the next surrogate key value and assigns it to the surrogate key that it is currently creating. When the ETL process copies a dimension row from the source system into the MDW, the ETL process performs a lookup on the dimension table. If the dimension row (with same business keys) does not exist in the dimension table, the process inserts a row with a new surrogate key value. If the dimension row already exists in the dimension table, the process updates the existing row with the incoming row value. When the ETL process copies a fact row from the source system into the MDW, for each dimension key in the fact row, the system performs a lookup on the dimension table and retrieves the corresponding surrogate key value. This surrogate key is the foreign key value in the fact row in the MDW. If the system does not locate a dimension value in the fact row in the dimension table, that is a data exception and an error results.
Surrogate Key Benefits
Surrogate keys provide benefits such as:
The ability to easily and structurally conform a dimension when being sourced from multiple systems.
Disassociation from operational system changes.
Because surrogate key generation is controlled by the warehouse, it is not influenced by operational system changes.
The ability to handle unspecified or missing key values.
A graceful mechanism to handle changes in history.
Multiple versions of a dimension can be maintained with different surrogate (primary) keys, yet with the same business (identifying) key.
Performance enhancement of queries, because a surrogate key is a single column numeric key, thus the joins using surrogate keys are faster than ones using multi-column business keys.
Audit Fields
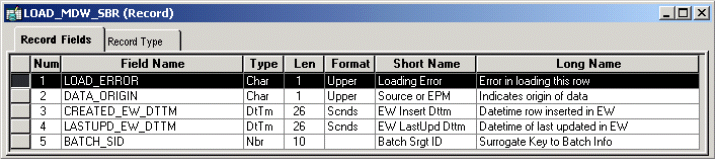
Audit fields track extract, transform, and load (ETL) loading information, such as when the row was loaded or last modified or the batch in which the row was loaded. This information is included in a subrecord. The subrecord added to MDW tables is called LOAD_MDW_SBR. Subrecords are always added at the end of a record; no fields exist after this subrecord in any table.
Image: LOAD_MDW_SBR record example
The following example shows a typical LOAD_MDW_SBR subrecord.
Data Aggregation
Tables in the MDW contain source data at the same granularity as the source system. Required data aggregation is carried out at run time by the business intelligence tool. This allows for better control of aggregation strategies by the business intelligence tool, because aggregation requirements vary from customer to customer.
MDW Dimension Tables
Dimensions are sets of related attributes that you use to group or constrain detailed information that you measure in your data mart. Dimensions are usually text (in character data type), relatively static, and often hierarchical.
Dimension tables contain surrogate keys as the primary key and are a single column key containing only the surrogate key column. Surrogate keys usually have _SID (surrogate ID) appended to the field name. Dimension tables retain source system business key fields as non-key attribute columns in the dimension table. However, these are not used for joins with fact tables. For example, in the Customer dimension, the original business key field CUST_ID is retained, if it exists in the source table, but is no longer included in the key. The SetID is also retained, if it exists in the source table, as a nonkey attribute; the value contained in the SetID is the same as in the source system.
If a dimension is SetID-based, the MDW table contains the source SetID and the performance (PF) SetID, which is named SETID.
If a dimension contains a description text, a related language table is often defined for this dimension. The ETL process populates this table if a customer requires multilanguage processing. The key for this table is the surrogate key ID, plus the language code field, LANGUAGE_CD, which contains the code for the additional language.
Note: You can find more information about multilanguage processing for the multidimensional warehouse in your EPM Warehouse specific documentation (for example, the PeopleSoft EPM: Campus Solutions Warehouse).
Shared Dimensions
Dimensions such as Account, Customer, Department, or Person are examples of shared dimensions. Shared dimensions are either exactly the same—including key structure—or an exact subset of another dimension; that is, shared dimensions are structurally identical every place in which they are used. Shared dimensions are used across all EPM warehouse products, such as the Campus Solutions Warehouse and the Financial Management Solutions Warehouse.
When using a shared dimension, the system consistently interprets attributes; hence rollups across data marts are possible and consistent. When a warehouse is provided data from multiple sources, a shared dimension is typically (but not always) built from multiple source structures.
Image: EPM conformed dimension
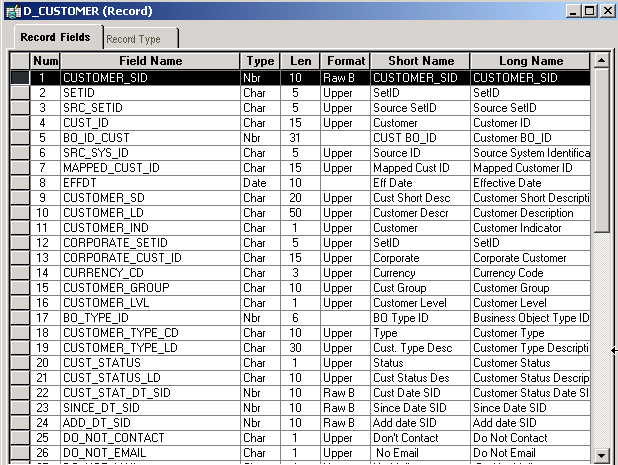
MDW Dimension Table Naming Convention
MDW dimension tables use the following naming convention: D_[table name].
MDW Fact Tables
MDW fact tables (F_*) contain numeric performance measurement data—such as quantity, sales, and revenue—that is used to build a data warehouse and its related reports. Facts help to quantify a company's activities. A fact is a typically an additive business performance measurement. That is, you can usually perform arithmetic functions on facts.
In a star schema, a fact table is the central table, each element of which is a foreign key derived from a dimension table. Dimension tables have a surrogate ID column that is the primary key of that dimension. A fact table may use these dimension surrogate IDs as foreign keys to the dimension table. In the dimensional model example graphic presented previously, the Sales fact table contains six foreign keys, each one matching a dimension surrounding the fact table.
Periodic Snapshot Fact Tables
Periodic Snapshots provide a view of the cumulative performance of the business at regular, predictable time intervals. Unlike a transaction fact table that loads a row of data for each event occurrence, the periodic snapshot fact table captures the event at the interval of a day, week, or month, and another capture at the interval of the next period, and so on. These periodic snapshots are stacked consecutively into the fact table. The periodic snapshot fact table often is the only place to easily retrieve a regular, predictable, trend view of the key business performance metrics.
Accumulating Fact Tables
Accumulating snapshots represent an indeterminate time span, covering the complete life of a transaction or discrete product. Accumulating snapshots almost always have multiple date stamps, representing the predictable major events or phases that take place during the course of a lifetime. Since many of these dates are not known when the fact row is first loaded, we must use surrogate date keys to handle undefined dates.
MDW Fact Table Naming Convention
MDW fact tables use the following naming convention: F_[table name].