Understanding Data Validation and Error Handling in the ETL Process
Accurate reporting is completely dependent on the data stored in data warehouse OWE and MDW tables; if incomplete or incorrect data resides in these tables, reporting and analysis can be flawed. Given the considerable dependence on data in EPM tables, all source data entering EPM must be validated.
Data validations are performed when you run ETL jobs. Because we want to ensure that complete, accurate data resides in the OWE and MDW tables, data validations are embedded in the jobs that load data from the OWS to the OWE and MDW. Therefore, data that passes the validation process is loaded into OWE and MDW target tables, while data that fails the validation process is redirected to separate error tables in the OWS. This ensures that flawed data never finds its way into the target OWE and MDW tables.
Error tables log the source values failing validation to aid correction of the data in the source system. There is an error table for each OWS driver table. OWS driver tables are those tables that contain the primary information for the target entity (for example customer ID).
Data Completeness Validation and Job Statistic Summary for Campus Solutions, FMS, and HCM Warehouses
A separate data completeness validation and job statistic capture is performed against the data being loaded into Campus Solutions, FMS, and HCM MDW tables (for example, validating that all records, fields, and content of each field is loaded, determining source row count versus target insert row count, and so forth). The validation and job statistic tracking is also performed in ETL jobs. The data is output to the PS_DAT_VAL_SMRY_TBL and PS_DATVAL_CTRL_TBL tables with prepackaged Oracle Business Intelligence (OBIEE) reports built on top of the tables.
See PeopleSoft EPM: Fusion Campus Solutions Intelligence for PeopleSoft.
Understanding the Data Validation Mechanism
The following graphic represents the data validation-error handling process in the PeopleSoft delivered J_DIM_PS_D_DET_BUDGET job:
Image: Data validation in the J_DIM_PS_D_DET_BUDGET job
This example illustrates the Data validation in the J_DIM_PS_D_DET_BUDGET job.
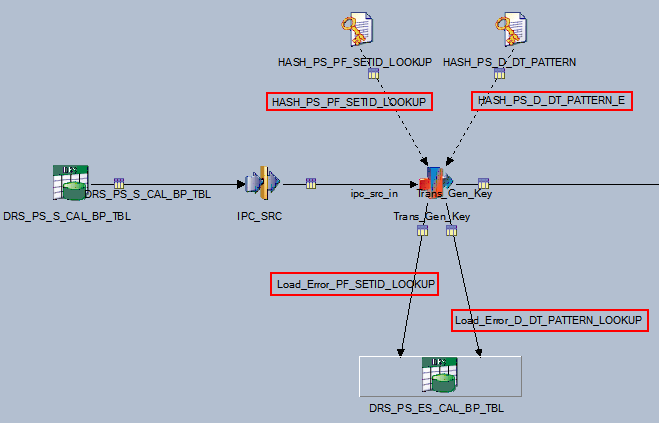
Note that two hashed file validations are performed on the source data: the HASH_PS_PF_SETID_LOOKUP (which validates SetID) and HASH_PS_D_DT_PATTERN (which validates pattern code). Any data failing validation of these lookups is sent to the OWS error table (DRS_PS_ES_CAL_BP_TBL) via the Load_Error_PF_SETID_LOOKUP and Load_Error_D_DT_PATTERN_LOOKUP.
A closer look at the stage variables in the Trans_Gen_Key transformer stage demonstrate how the data validation process works (open the stage, then click the Show/Hide Stage Variables button on Transformer toolbar):
Image: Trans_Gen_Key transformer stage variables
This example illustrates the Trans_Gen_Key transformer stage variables. .
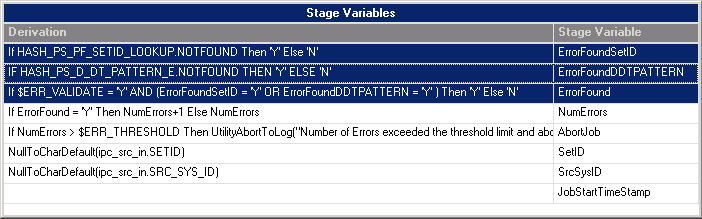
Note that the ErrorFoundSetID and ErrorFoundDDTPATTERN stage variable derivations are set to Y if the SETID lookup or pattern code validations fail.
Image: Stage variable properties
This example illustrates the Stage variable properties.
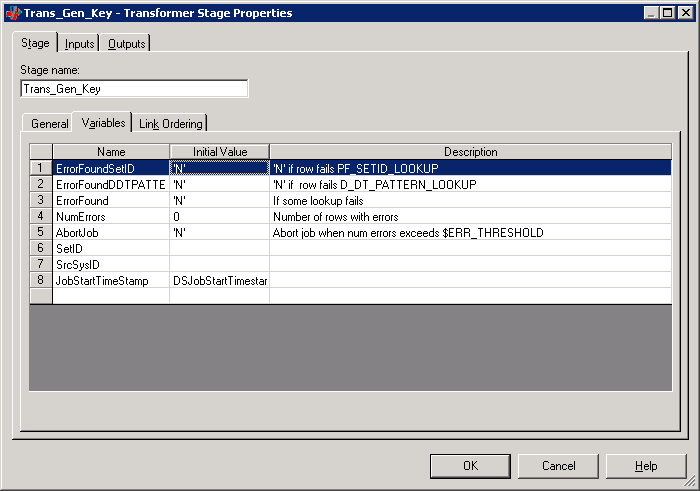
The value of the ErrorFound stage variable, however, depends on the values of the ErrorFoundSetID and ErrorFoundDDTPATTERN stage variables, as well as the value of the $ERR_VALIDATE parameter, which can be configured to Y or N. If the $ERR_VALIDATE parameter is set to Y, rows that fail validation are written to the error table. If the value is set to N, rows that fail validation still pass to the target table.
Also note the AbortJob stage variable derivation uses the $ERR_THRESHOLD parameter to limit the number of error records allowed in the job. If the number of error records exceed the value set for the $ERR_THRESHOLD parameter, the job automatically aborts. For example, if $ERR_THRESHOLD is set to 50, the job aborts if the number of records with errors exceeds 50. You can set the value of the $ERR_THRESHOLD parameter to meet your specific business requirements.
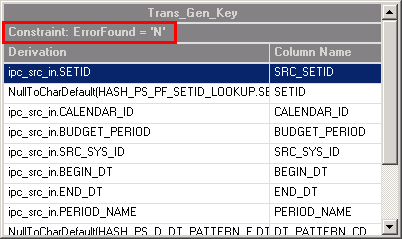
Using the SetID lookup validation as an example, if a record fails validation, a Y value is assigned to the ErrorFoundSetID stage variable. If the $ERR_VALIDATE parameter is also set to Y, the failed record is sent to the PS_ES_CAL_BP_TBL error table.
Image: Example constraint
This example illustrates the Example constraint.
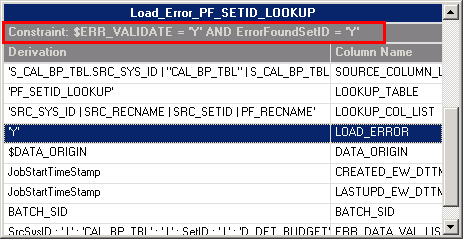
For records that pass validation, an N value is assigned to the ErrorFound stage variable and the records are sent to the target table.
Image: N value is assigned to the ErrorFound stage variable
N value is assigned to the ErrorFound stage variable
Disabling Data Validation
You can disable error validation in OWS jobs by configuring the value of the $ERR_VALIDATE parameter. By default the value is set to Y, which means that records failing validation are moved an error table. If you set the $ERR_VALIDATE value to N, records failing validation will still pass to the target table.
Understanding the Data Completeness Validation and Job Statistic Summary Mechanism
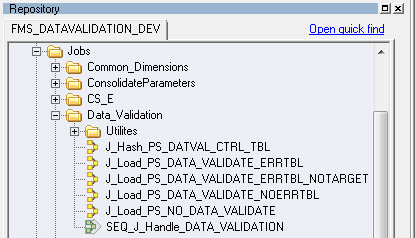
The ETL component of the new data validation feature can be found using the following navigation in the DataStage Designer repository window: Jobs, Data_Validation.
Image: Data_Validation jobs in the DataStage project tree
This example illustrates the the Data_Validation jobs in the DataStage project tree.
Data Validation - Job Summary Data
The ETL logic for the new data validation feature is contained in a reusable, common component called SEQ_J_Handle_DATA_VALIDATION, which is a sequencer job:
Image: SEQ_J_Handle_DATA_VALIDATION sequencer job
This example illustrates the SEQ_J_Handle_DATA_VALIDATION sequencer job.
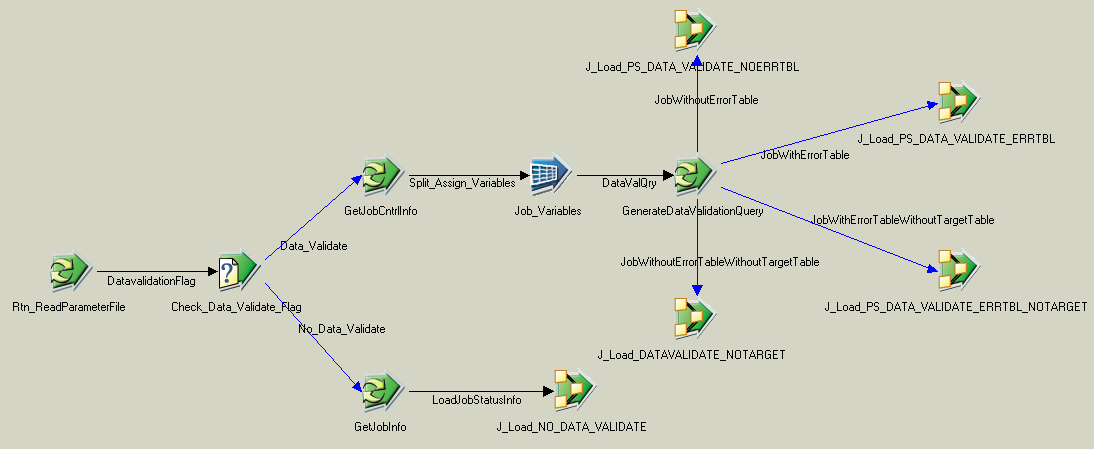
Since the logic is reusable, the sequencer job is incorporated into all the existing sequencer jobs that load the MDW. Also, because the logic is contained within a sequencer job, there is no need to modify existing server jobs to implement the logic.
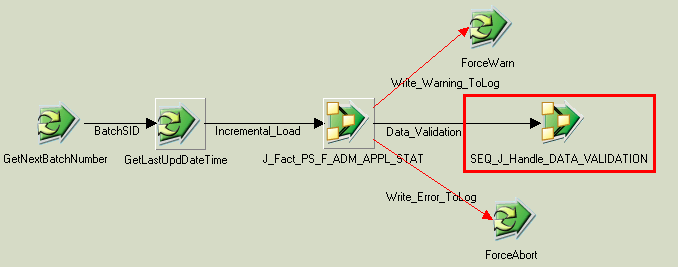
Here is the SEQ_J_Handle_DATA_VALIDATION sequencer job incorporated into an existing sequencer job for the Campus Solutions Warehouse, SEQ_J_Fact_PS_F_ADM_APPL_STAT:
Image: SEQ_J_Fact_PS_F_ADM_APPL_STAT sequencer job with the data validation component
SEQ_J_Fact_PS_F_ADM_APPL_STAT sequencer job with the data validation component.
Note: If you have customized your ETL jobs, you can implement the new data validation component simply by attaching it to the associated sequencer job.
The SEQ_J_Handle_DATA_VALIDATION sequencer job consists of the following server jobs:
J_Load_PS_DATA_VALIDATE_ERRTBL
J_Load_PS_DATA_VALIDATE_NOERRTBL
J_Load_DATAVALIDATE_NOTARGET
J_Load_PS_DATA_VALIDATE_ERRTBL_NOTARGET
A closer look at these server jobs shows that they load the Data Validation Summary (PS_DAT_VAL_SMRY_TBL) table:
Image: J_Load_PS_DATA_VALIDATE_NOERRTBL
J_Load_PS_DATA_VALIDATE_NOERRTBL

The Data Validation Summary (PS_DAT_VAL_SMRY_TBL) table consolidates all your job run statistic and error data, and is used as the foundation for the delivered data validation OBIEE reports (which are discussed in the PeopleSoft EPM Fusion Campus Solutions Intelligence for PeopleSoft documentation).
The following graphic and table provide a more detailed look at the columns included in the Data Validation Summary (PS_DAT_VAL_SMRY_TBL) table:
Image: PS_DAT_VAL_SMRY_TBL
This example illustrates the PS_DAT_VAL_SMRY_TBL.
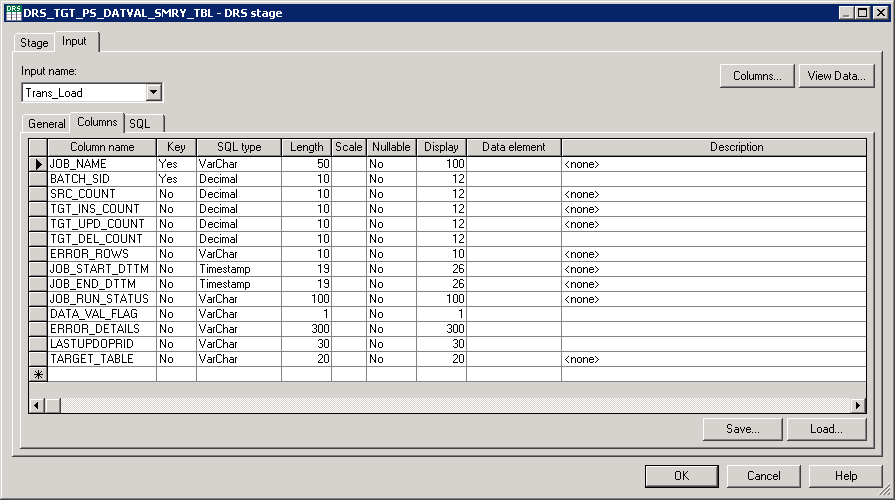
|
Column |
Description |
|---|---|
|
JOB_NAME |
Populated with the server job name for each job run. This is a composite Primary Key. |
|
BATCH_SID |
Contains the BATCH_SID for the corresponding job run. This is a composite Primary Key. |
|
SRC_COUNT |
Contains the row count from the source that was extracted by the job. |
|
TGT_INS_COUNT |
Contains the row count for rows inserted into the target table by the job. |
|
TGT_UPD_COUNT |
Contains the row count for rows updated in the target table by the job. |
|
TGT_DEL_COUNT |
Contains the row count for rows deleted from the target table by the job. |
|
ERROR_ROWS |
Contains the count of unique rows from the source that failed to load the target due to lookup validation failure. Will default to '-' when:
|
|
JOB_START_DTTM |
Contains the server job start time. This will be the LASTUPD_EW_DTTM in the target tables. |
|
JOB_END_DTTM |
Contains the server job end time. |
|
JOB_RUN_STATUS |
Contains the run status of a job and whether the data has been loaded into the target completely. Job run status values are:
Note: Even if data validation is disabled for a job, job run status is still captured so that you can use the delivered Job Run Statistics OBIEE report to monitor job status. |
|
DATA_VAL_FLAG |
Flag indicating whether the data validation flag is enabled or disabled for the server job. |
|
ERROR_DETAILS |
Contains the error table names and total count of rows loaded into each error table. When no rows are loaded into error table it will be defaulted to "-" |
|
LASTUPDOPRID |
Contains the DataStage user information who triggered or ran the job. |
|
TARGET_TABLE |
Contains the target table name to which data was loaded. |
Data Validation - Job Statistic Data
The SEQ_J_Handle_DATA_VALIDATION sequencer job also includes a mechanism to capture job statistic data. Note that within the sequencer job is the routine GetJobCntrlInfo:
Image: GetJobCntrlInfo routine in the SEQ_J_Handle_DATA_VALIDATION sequencer job
This example illustrates the GetJobCntrlInfo routine in the SEQ_J_Handle_DATA_VALIDATION sequencer job.
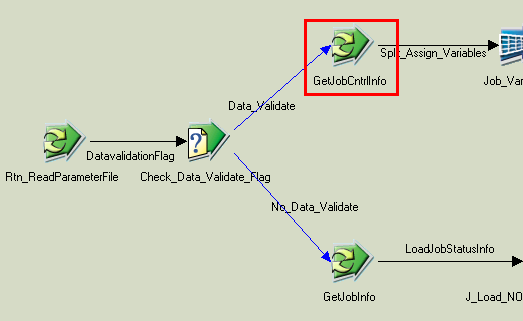
The GetJobCntrlInfo routine retrieves job information (such as error table and exception flag) from the Data Validation Control (HASH_PS_DATVAL_CTRL_TBL) hashed file:
Image: GetJobCntrlInfo routine detail
This example illustrates the GetJobCntrlInfo routine detail.
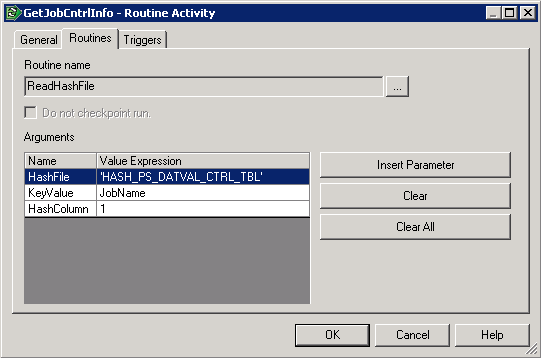
The job information in the hashed file is also used by the server jobs that load the Data Validation Summary (PS_DAT_VAL_SMRY_TBL) table.
The Data Validation Control (PS_DATVAL_CTRL_TBL) table stores job statistic data for each OWS to MDW job run, such as source count, target count, error count, and error table list. The table is delivered prepopulated with the necessary data for the ETL jobs that perform data validation.
Note: If you have customized your ETL Jobs, you must manually update/insert data for the customized job in the PS_DATVAL_CTRL_TBL table and then run the J_Hash_PS_DATVAL_CTRL_TBL server job to update the related hashed file. See the following topic on how to perform these tasks.
The following graphic and table provide a more detailed look at the columns included in the Data Validation Control (PS_DATVAL_CTRL_TBL) table:
Image: PS_DATVAL_CTRL_TBL
This example illustrates the PS_DATVAL_CTRL_TBL.
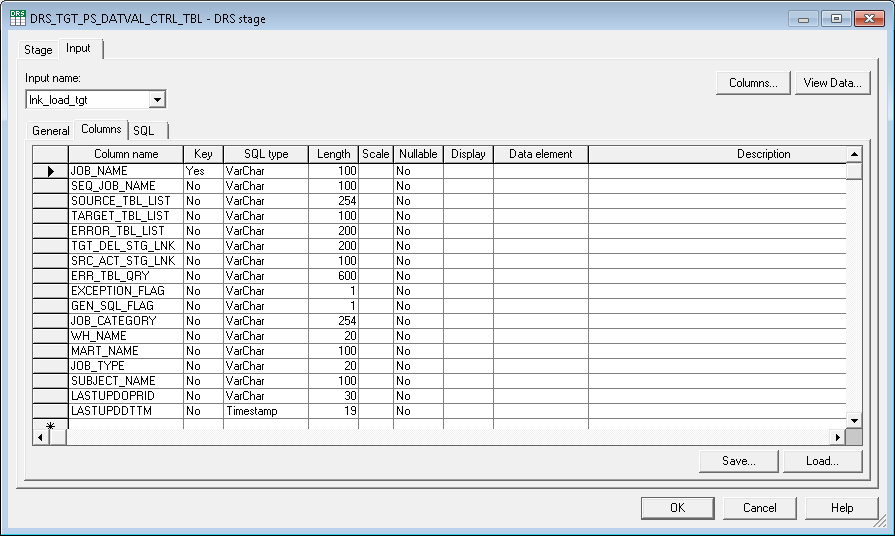
|
Column |
Description |
|---|---|
|
JOB_NAME |
Populated with the server job name that loads the OWS and MDW table. This is a primary key in this table. |
|
SEQ_JOB_NAME |
Populated with the Sequencer Name of the server job. |
|
SOURCE_TBL_LIST |
Contains the list of source table names used in the job. |
|
TARGET_TBL_LIST |
Contains the list of target target table names used in the job. This column may also contain parameter names when the target table is parameterized. |
|
ERROR_TBL_LIST |
Contains the list of error tables populated in the job. |
|
TGT_DEL_STG_LNK |
Identifies the active stage that precedes the DRS stage that performs a delete on target table, which is used to retrieve the target deleted row count. |
|
SRC_ACT_STG_LNK |
Identifies the active stage that succeeds the source DRS stage, which is used to retrieve the source row count. |
|
ERR_TBL_QRY |
Contains the error table query that is used to fetch the count of unique errors rows that failed to load the target. |
|
EXCEPTION_FLAG |
Contains 'Y' for jobs when source row count might not tally with the sum of target and error row counts (due to functional or job design). Otherwise, contains 'N.' |
|
GEN_SQL_FLAG |
Contains 'Y' if DRS stage uses generated sql query. Otherwise, contains 'N' if DRS stage uses user-defined SQL query. |
|
JOB_CATEGORY |
Contains the category (folder) information in the DataStage Project Repository for the job. |
|
WH_NAME |
Contains the EPM Warehouse name related to the job. The data validation component uses this value to select the appropriate parameter file at runtime. |
|
MART_NAME |
Contains the data mart name that corresponds to the parent EPM Warehouse, for the job run. |
|
JOB_TYPE |
Contains the job type information for the job. Job type values include:
|
|
SUBJECT_NAME |
Contains the functional area that corresponds to the parent data mart, for the job. |
|
LASTUPDOPRID |
Contains the user information associated with the insert or update actions, for a given job. |
|
LASTUPDDTTM |
Contains the timestamp when data was last modified. |
Another data validation-job statistic table, the Data Validation Job Error (PS_DATVAL_JOB_ERR) table, is populated from the PS_DATVAL_CTRL_TBL by an in-house ETL job not delivered with DataStage metadata.
The Data Validation Job Error table is used in Error Table OBIEE reports and contains specific error table information and corresponding source table information for each job. The Data Validation Job Error table is populated from the PS_DATVAL_CTRL_TBL by an in-house ETL job not delivered with DataStage metadata.
The following graphic and table provide a more detailed look at the columns included in the Data Validation Job Error (PS_DATVAL_JOB_ERR) table:
Image: PS_DATVAL_JOB_ERR
This example illustrates the PS_DATVAL_JOB_ERR.
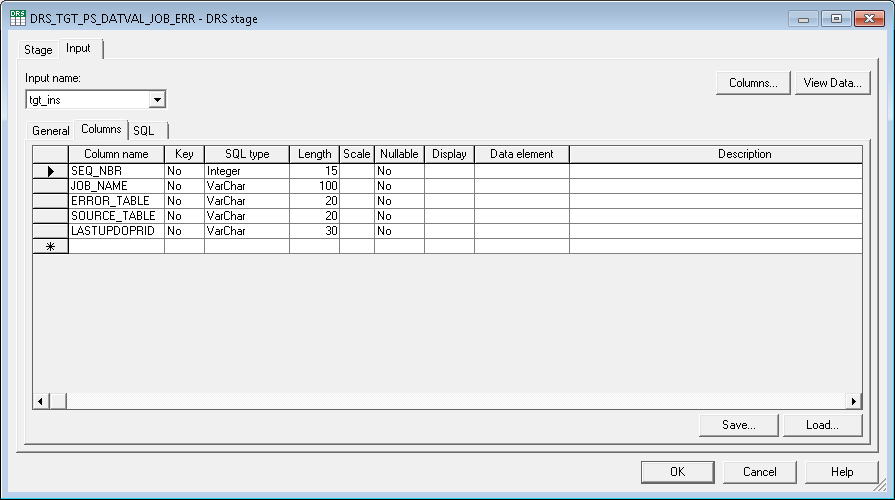
|
Column |
Description |
|---|---|
|
SEQ_NBR |
Contains the unique sequence number for each error table. |
|
JOB_NAME |
Populated with the server job name for each job run. |
|
ERROR_TABLE |
Contains the error table name related to the job. |
|
SOURCE_TABLE |
Contains the name of the source table used with a corresponding error table. |
|
LASTUPDOPRID |
Contains the user information associated with the insert or update actions, for a given job. |
Enabling or Disabling the Data Completion Validation Feature
The Data Validation and Error Reporting feature is designed as optional, and you can enable it or disable it for each staging job using the delivered parameter files. For example, you can access the HCM_DATA_VALIDATION_SETUP parameter file and change the DATA_VALIDATION value from 'N' (do not perform data validation) to 'Y' (perform data validation) for each job:
Image: Campus Solutions Warehouse Data Validation parameter file
This example illustrates the Campus Solutions Warehouse Data Validation parameter file.
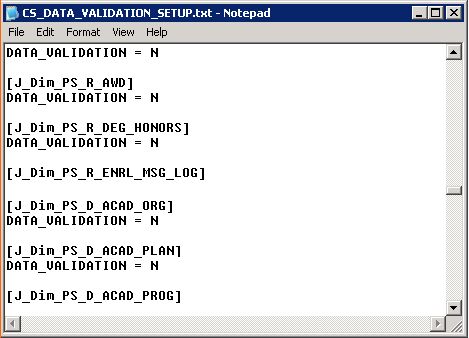
PeopleSoft delivers a separate parameter file for each EPM Warehouse and for Global/Common dimension jobs:
CS_DATA_VALIDATION_SETUP.txt
FMS_DATA_VALIDATION_SETUP.txt
HCM_DATA_VALIDATION_SETUP.txt
GLOBAL_DATA_VALIDATION_SETUP.txt
Implementing the Data Completeness Validation Feature for Customized Jobs
PeopleSoft provides the DDL Scripts and related data files for the Data Completeness Validation setup tables, but if you have created new jobs or customized delivered jobs, you must perform the following steps to implement the Data Completion Validation feature:
Populate the PS_DATVAL_CTRL_TBL.
For each customized job, you must populate this table using an SQL INSERT statement. Use the following table as a guide to populating the PS_DATVAL_CTRL_TBL fields:
Column
Description
JOB_NAME
Populate this field with the server job that loads the OWS and MDW table.
SEQ_JOB_NAME
Populate this field with the Sequencer job that triggers the customized job.
SOURCE_TBL_LIST
Populate this field with source tables used in the customized job.
Use commas to separate multiple table names.
TARGET_TBL_LIST
Populate this field with target tables used in the customized job.
If target table name is a job parameter, use this sample format:
#TargetTable#(PS_FF_STDNT_ENRL/PS_TF_STDNT_ENRL), where TargetTable is the Job Parameter
ERROR_TBL_LIST
Populate this field with error tables used in the customized job.
TGT_DEL_STG_LNK
Populate this field with the active stage name that precedes the DRS stage that performs a delete on the target table.
If the active stage contains more than one output link, the link name should also be specified using this format:
<active_stage_name>@<link_name> where link_name is the link connecting to the Delete DRS stage and active_stage_name is the transformer name.
For example:
"PS_R_STDNT_ATTR_split@IPC_Del_Out*-" is value for this field in J_Dim_PS_R_STDNT_ATTR job
SRC_ACT_STG_LNK
For CRC staging jobs, populate this field with the active stage name and link name that writes to the Delta hash file. Use the following format:
<active_stage_name>@<link_name> where link_name is the link that updates the delta hash file in the CRC job.
For non CRC staging jobs, populate this field with the active stage name that follows the source DRS stage in the customized job.
ERR_TBL_QRY
Populate this field with the error table query that is used to fetch the count of unique errors rows that failed to load the target.
For customized jobs having one error table, use the following query syntax:
SELECT DISTINCT <BUSINESS KEYS of source table> FROM #$ERROR_TBL_SCHEMA#<ERROR TABLE NAME>Sample: SELECT DISTINCT SRC_SYS_ID,EFFSEQ,EFFDT,EMPL_RCD,EMPLID FROM #$ERROR_TBL_SCHEMA#PS_E_JOB
This field is defaulted to "-" for customized jobs with more than one error table.
EXCEPTION_FLAG
Set this flag to "Y" for customized jobs with more than one error table.
Set this flag to "Y" for customized jobs that include multiple source tables with parent/chid relationships and the error data is captured only at parent table level.
GEN_SQL_FLAG
Set this flag to “Y” for customized jobs that use generated SQL in the Source DRS stage.
Set this flag to “N” when the source DRS stage includes user-defined SQL.
JOB_CATEGORY
Populate this field with the category (folder) name where the job is placed within the DataStage Project Repository.
WH_NAME
Populate this field with the EPM Warehouse name related to the customized job.
MART_NAME
Populate this field with the data mart name that corresponds to the customized job.
JOB_TYPE
Populate this field with the job type information for the customized job. Job type values include:
STAGING
DIMENSION
FACT
SUBJECT_NAME
Populate this field with the functional area that corresponds to the customized job.
LASTUPDOPRID
Populate this field with the user ID associated with the insert or update actions for the customized job.
LASTUPDDTTM
Populate this field with the current timestamp representing when data was last modified for the customized job.
Here is a sample of SQL INSERT syntax:
INSERT INTO "PS_DATVAL_CTRL_TBL" ( JOB_NAME, SOURCE_TBL_LIST, TARGET_TBL_LIST, ERROR_TBL_LIST, TGT_DEL_STG_LNK, SRC_ACT_STG_LNK, ERR_TBL_QRY, EXCEPTION_FLAG, GEN_SQL_FLAG, WH_NAME, MART_NAME, SUBJECT_NAME, JOB_TYPE, JOB_CATEGORY, LASTUPDOPRID, LASTUPDDTTM, SEQ_JOB_NAME ) VALUES ( 'J_Fact_PS_F_KK_EXCEPTION','PS_KK_EXCPTN_TBL','PS_F_KK_EXCEPTION', 'PS_E_KK_EXCEPTION','Trans_Assign_Values8@Trans_Assign_Values8_out_DEL*-', 'IPC_SRC.IDENT1', 'SELECT DISTINCT SRC_SYS_ID,EXCPTN_TYPE,LEDGER_GROUP,KK_TRAN_LN,KK_TRAN_DT,KK_TRAN_ID FROM #$ERROR_TBL_SCHEMA#PS_E_KK_EXCEPTION', 'N','Y','FMS','GL_And_Profitability_Mart', 'Commitment_Control','FACT', 'Jobs\FMS_E\GL_And_Profitability_Mart\Commitment_Control\OWS_To_MDW\Facts\Base\Lo ad_Tables\Server', 'EPM',to_timestamp('01-JAN-53 12.00.00.000000000 AM','DD-MON-RR HH.MI.SS.FF AM'), 'SEQ_J_Fact_PS_F_KK_EXCEPTION' );Add an entry in Data Validation Parameter File.
For warehouse specific Jobs, add an entry in the corresponding parameter file. For example, customized jobs specific to Campus Solutions require an entry in the CS_DATA_VALIDATION_SETUP.txt and you could use the following format:
[J_Dim_PS_D_ACAD_CAR] DATA_VALIDATION = N
For Common Dimensions and Global Dimensions, add an entry in GLOBAL_DATA_VALIDATION_SETUP.txt.
To enable data load validation (capturing source, target and error row counts for each run), the DATA_VALIDATION flag should be set to ‘Y’.
Run J_Hash_PS_DATVAL_CTRL_TBL job.
Note: It is important that the information for a customized server job is accurately reflected in the PS_DATVAL_CTRL_TBL before running this job.
Attach the common component, SEQ_J_Handle_DATA_VALIDATION, sequencer job to the existing sequencer job that corresponds to the customized server job.
Copy the SEQ_J_Handle_DATA_VALIDATION component and paste it into the existing sequencer job that corresponds to the customized server job. Reestablish the links in the new job sequence, map the Job Name and BatchSID parameter in the Job Activity, and verify that hash file directory path, parameter file directory path, and the database related parameters are mapped correctly. Then compile the job.
When you complete these steps, the PS_DATVAL_SMRY_TBL captures job run statistics for each job run by the data validation component.
Populate the PS_DATVAL_JOB_ERR.
For each customized job, you must populate this table using an SQL INSERT statement. Use the following table as a guide to populating the PS_DATVAL_JOB_ERR fields:
Column
Description
SEQ_NBR
Populate this field with a unique sequence number for each error table.
To avoid overlapping SEQ_NBR, use higher SEQ_NBR (values greater than 999999).
JOB_NAME
Populate this field with the customized server job name.
ERROR_TABLE
Populate this field with the error table name used in the customized job.
SOURCE_TABLE
Populate this field with the name of the source table used with the corresponding error table.
LASTUPDOPRID
Populate this field with the user ID associated with the insert or update actions for the customized job.
Here is a sample of SQL INSERT syntax:
INSERT INTO "PS_DATVAL_JOB_ERR" (SEQ_NBR,JOB_NAME,ERROR_TABLE,SOURCE_TABLE,LASTUPDOPRID) VALUES (236,'J_Dim_PS_D_GM_SPONSOR','PS_E_GM_CUSTOMER','PS_GM_CUSTOMER','dsuser');
Populate PS_DATVAL_SRC_TBL.
For each customized job, you must populate this table using an SQL INSERT statement. Use the following table as a guide to populating the PS_DATVAL_SRC_TBL:
Column
Description
SEQ_NBR
Populate this field with a unique sequence number for each error table.
To avoid overlapping SEQ_NBR, use higher SEQ_NBR (values greater than 999999).
ERROR_TABLE
Populate this field with the error table name used in the customized job.
SOURCE_TABLE
Populate this field with the name of the source table used with the corresponding error table.
Here is a sample of SQL INSERT syntax:
INSERT INTO "PS_DATVAL_SRC_TBL" (SEQ_NBR,ERROR_TABLE,SOURCE_TABLE) VALUES (351,'PS_E_WA_COMP_PIN','PS_WA_COMP_PIN_MAP');