Understanding ETL Load Strategies in EPM
This topic provides an overview of ETL load strategies in EPM and discusses:
Incremental loading using the datetime stamp
Incremental loading using Cyclical Redundancy Check (CRC) logic
Incremental loading using the insert flag and lookup validations
Overview of ETL Load Strategies in EPM
PeopleSoft delivers ETL jobs that extract data from your source transaction system and load it into target OWE and MDW dimension and fact tables. These jobs employ an incremental load strategy, which uses built-in logic to identify and load only new or updated source records. The benefit of the incremental load process is increased efficiency and faster processing during the extract and load process.
There are three types of incremental load strategies employed in PeopleSoft ETL jobs:
Incremental loading using the datetime stamp
Incremental loading using Cyclical Redundancy Check (CRC) logic
Incremental loading using the insert flag and lookup validations
Note: If this is the first time you are populating your target warehouse tables with data, the incremental jobs recognize that you have no existing data in your tables and perform a complete extract of your source records. Subsequent runs of the incremental jobs will extract only new or changed records.
Incremental Loading with the DateTime Stamp
To ensure only new or changed records are extracted, EPM target tables associate a datetime stamp with each record. Please note that the datetime stamp may appear as DTTM or DT_TIMESTAMP, depending on the source from which the record originates.
When an incremental load job reads a table, it uses a built-in filter condition, [DTTM_Column] > [%DateTimeIn('#LastModifiedDateTime#')] for example, to determine whether any records in the table are new or changed since the last load. The last update date time is retrieved from the related hashed file using the GetLastUpdDateTime routine. If the retrieved date time is less than the current value in the DTTM column, the record will be updated in the EPM table. This process can be done quickly because the DTTM column is the only value being processed for each record.
Each time a new or updated record is loaded, the present date time stamp is recorded for the last update time stamp and is used as a basis for comparison the next time the incremental load job is run.
Note: If the last update time field is null for a record, the record is processed each time the job is executed.
Incremental Loading Using Cyclical Redundancy Check
Some source table records do not have a date timestamp column. When source table records lack a date time stamp, a cyclical redundancy check (CRC) must be performed to determine new or changed records. Unlike incremental loading that targets the DTTM column for each record, the CRC process must read the entire record for each record in the source table and generate a CRC value, which it uses to compare against the target warehouse record.
Incremental Loading Using the Insert Flag and Lookup Validations
To ensure only new or changed records are loaded to EPM target tables, some jobs use an insert flag in combination with lookup validations. The following example will illustrate this process.
In the job J_Fact_PS_F_KK_FS_RCVD, the Trans_Assign_Values transformation contains the processing logic used to load new or updated records to the target table:
Image: Trans_Assign_Values transformation
This example illustrates the Trans_Assign_Values transformation.
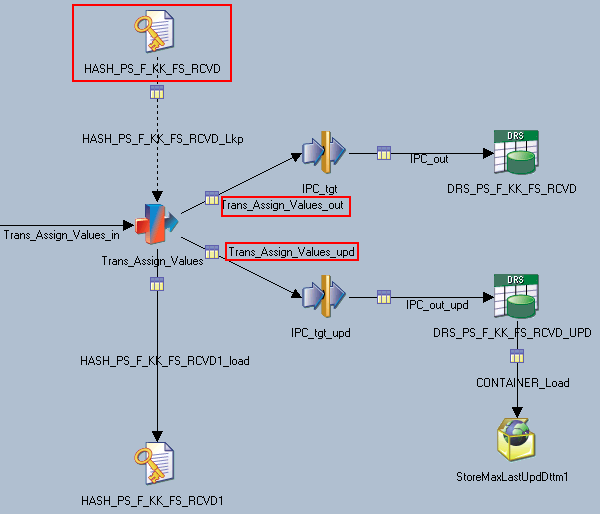
A closer look at the Trans_Assign_Values transformation shows that the Trans_Assign_Values_out and Trans_Assign_Values_update constraints are used to filter new or updated records:
Image: Trans_Assign_Values constraints
This example illustrates the Trans_Assign_Values constraints.
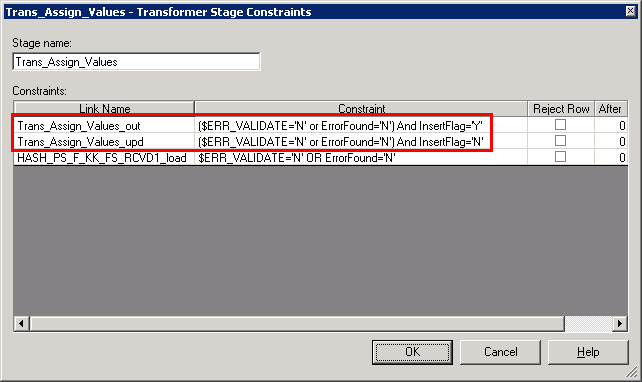
The Trans_Assign_Values_out constraint will insert a new record when the InsertFlag is set to 'Y' and the ErrorFound flag is set to 'N.'
The Trans_Assign_Values_upd constraint will update a record when the InsertFlag is set to 'N' and the ErrorFound flag is set to 'N.'
Looking at the stage variables in the same transformation, note that the InsertFlag value (Y or N) is set based on the HASH_PS_F_KK_FS_RCVD_LKP:
Image: Trans_Assign_Values transformation stage variables
This example illustrates the Trans_Assign_Values transformation stage variables.

The HASH_PS_F_KK_FS_RCVD_LKP uses incoming values for the source keys KK_FS_SID and SEQ_NBR to determine the SID value for each row of fact data. If the lookup returns a null SID value based on the source keys, the InsertFlag is set to 'Y' (insert a new record). If the lookup returns an existing SID value based on the source keys, the InsertFlag is set to 'N' (update existing record).
Also note that the ErrorFound flag value (Y or N) is set based on the ErrorFoundFundSource stage variable. However, the value of the ErrorFoundFundSource stage variable is determined in an earlier transformation, the Trans_SID_Lkp transformation:
Image: Trans_SID_Lkp transformation
This example illustrates the f Trans_SID_Lkp transformation.
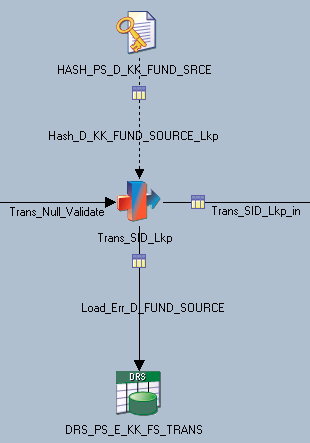
Looking at the ErrorFoundFundSource stage variable in the same transformation, note that its value is set based on the HASH_D_KK_FUND_SOURCE_LKP:
Image: ErrorFoundFundSource stage variable
This example illustrates the ErrorFoundFundSource stage variable.
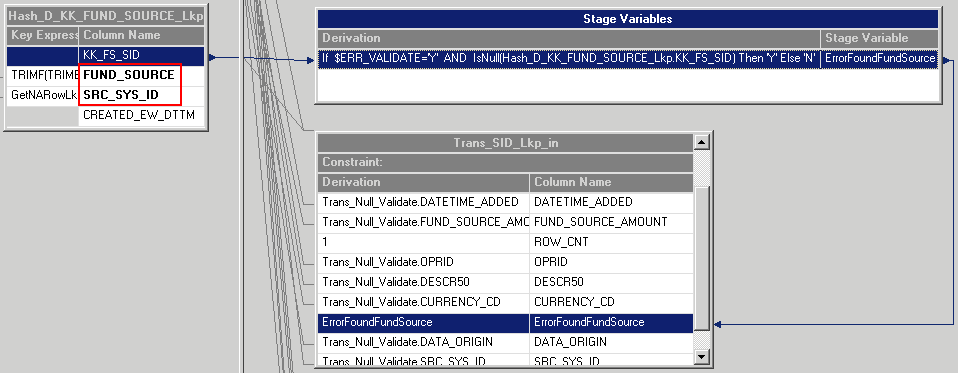
The HASH_D_KK_FUND_SOURCE_LKP uses incoming values for the source keys FUND_SOURCE and SRC_SYS_ID to determine the SID value for each row of fact data. If the lookup returns a null SID value based on the source keys, the ErrorFoundFundSource is set to 'Y' (error found). If the lookup returns an existing SID value based on the source keys, the ErrorFoundFundSource is set to 'N' (no error).
Note: Normally the $ERR_VALIDATE parameter is set to 'Y.' By default EPM is delivered with the value set to Y, which means that records failing validation are moved an error table.
Special Load Requirements
The complex process behind integrating and aggregating disparate source data can create some special load requirements in EPM. For example, subrecords are used extensively in EPM target tables to provide additional depth and breadth of processing.
Passing Default Values to EPM Target Tables
Due to data aggregation and other processing requirements, EPM target tables may contain columns that do not exist in your source transaction tables. Because of the differences between source and EPM columns, there are sometimes no source values to populate the EPM columns. Therefore, default values must be used to populate the EPM columns instead.
|
Warehouse Layer |
Data Type |
Default Value |
|---|---|---|
|
OWS |
Char |
'-' |
|
Num |
0 |
|
|
Date |
Null |
|
|
OWE |
Char |
' ' |
|
Num |
0 |
|
|
Date |
Null |
|
|
MDW |
Char |
'-' |
|
Num |
0 |
|
|
Date |
Null |
For MDW fact records, fact rows coming from the source normally contain a valid reference to an existing row in the dimension table, in the form of a foreign key using a business key field. However, occasionally a fact row does not contain the dimension key. To resolve this issue, each MDW dimension contains a row for Value Not Specified, with predefined key values of zero—for a missing numeric value—and a hyphen—for a missing character value.
PeopleSoft delivers several routines to pass default values to the EPM columns. For example, the routine GetNumDefault is used to pass numeric default values to a target warehouse table. A separate routine is delivered for each data type (such as varchar and numeric).
Target Table Subrecords
Subrecords are a collection of specific columns that repeat across multiple EPM target tables. Subrecords can perform a variety of functions, including tracking data to its original source and facilitating customizations that enable type 2 slowly changing dimensions. For example, the subrecord LOAD_OWS_SBR contains columns such as CREATED_EW_DTTM, LAST_UPD_DTTM, and BATCH_SID which help track target warehouse table load history.
It is important to populate subrecords with the appropriate data. Thus, it is important that you thoroughly familiarize yourself with the PeopleSoft delivered subrecords and their associated columns.