Understanding Jobstreams
This topic discusses:
Jobstreams.
Jobstream terminology
Jobstream processing.
Jobstream record suites.
Jobstream chunking.
Spawn process.
Resolver engine.
Resolver and chunking.
Process monitor.
Jobstreams
To help streamline your processing, PeopleSoft provide jobstreams which use temporary tables for intermediate processing. Jobstreams enable different users to run their own jobs using instances of the same processing engines at the same time. Jobstreams enhance performance by sharing temporary tables passed between jobs.
Instead of locking up the fact (primary input) tables, jobstreams use temporary tables for intermediate processing. A set of delivered temporary tables, referred to as a record suite, is assigned when the first job of a jobstream is run, and then the tables are released when the last job of a jobstream is completed. The use of record suites frees up the fact tables so that another user can access them and run a concurrent job. Each job then has its own record suite for a jobstream.
There are several steps involved in setting up a jobstream. PeopleSoft delivers predefined processing engines and engine metadata, jobs and job metadata, jobstreams, and record suites. If you use the predefined metadata, the only item that you have to specify before you run an engine is one or more record suites for each jobstream for a given SetID.
Image: Jobstream overview
This diagram illustrates the components that make up a jobstream:
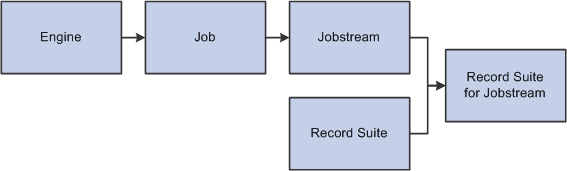
Jobstreams work by creating a copy of the processing engine. When you run a jobstream, you can:
Run multiple engines sequentially in one jobstream.
Run each individual engine in its own jobstream.
Run one sequential jobstream for multiple fiscal years or accounting periods.
Suppose you want to run the Activity-Based Management engine, Data Manager engine, and Merge engine at the end of the business day. You can select a jobstream that runs all three engines automatically. Each engine runs sequentially and populates specific temporary tables, with the Merge engine transferring the data from the temporary tables back to the fact tables. You only need to initiate the jobstream, no further action is required.
The Merge (PF_MERGE) engine merges the output temporary tables into the final tables for use as input for other processes. PF_MERGE is the last job in all jobstreams except when the POST job is run at the end of a jobstream.
Image: Jobstream setup
This diagram illustrates how jobstream setup works:
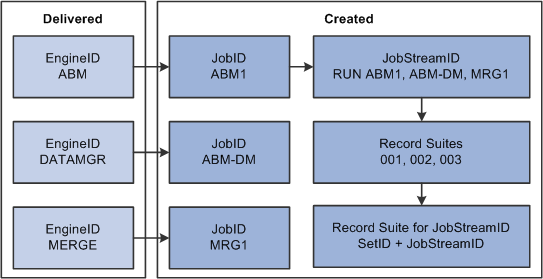
In the above diagram, note that the engine IDs on the left side of the illustration are delivered with PeopleSoft EPM. You create the job and jobstream IDs, and then assign record suites to the jobstream.
Image: Merge engine process
This diagram illustrates how the Merge engine moves output from the Activity-Based Management (ABM) engine to the into final fact tables:
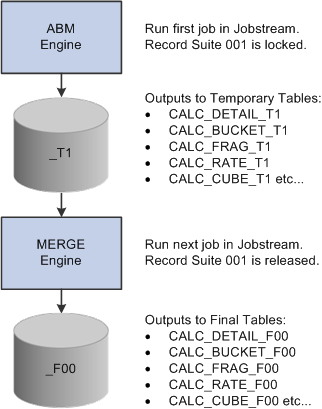
Jobstream Terminology
The following terms apply to jobstreams in PeopleSoft EPM applications:
Jobstream Processing
When you run a jobstream, the following occurs:
Record suite 001 is locked and the first engine runs placing its output into the appropriate temporary table in record suite 001.
The next engine runs getting its input from the temporary tables generated by the first job and putting its output into other temporary tables in record suite 001.
The last job in the jobstream (either PF_MERGE or PF_POST) reads the data in the temporary tables, merges it, and then writes the output to the final target tables. The system releases the record suite.
Note: Not all processes use jobstreams. For example, PF_SUMM does, but PF_MODIFICATION does not. Exceptions are noted in the documentation as appropriate.
Jobstream Record Suites
When you initially process a jobstream, the system checks which record suites are assigned to the specified SetID and jobstream ID.
This process enables you to reserve a set of record suites for a specific type of engine. For example, if record suites 001 and 002 are assigned to PeopleSoft Activity-Based Management (ABM) jobstreams, and 003 is authorized for PeopleSoft Asset Liability Management (ALM), then PeopleSoft ALM jobstreams never compete for record suite availability with ABM jobstreams.
Jobstream Chunking
Chunking is a mechanism that enables you to select a smaller chunk of data for further processing and to parallel process data in multiple chunks. It enables you to horizontally partition source data so that only a subset of data is processed by an engine. The enables users to run multiple engines with different criteria and to run them in parallel to reduce the processing time.
During a jobstream run, chunking occurs when technical scenario is associated with the run scenario based on the scenario selected on the Technical Scenarios page. After a jobstream identifies that chunking has been requested, the jobstream initiates the PF_CHUNK application engine program to process each chunking selection. The jobstream then invokes a parallel application engine PF_SPAWN to process each chunking selection. This program spawns a job for each chunking definition.
The number of jobs that can be spawned in parallel is restricted to the number of available record suites. You require one record suite for the jobstream process and one for each of the spawned processes.
Because all jobs that use the same technical scenario may not require chunking, the decision to chunk is based on the chunking selection in the engine metadata and chunking criteria specified on the Technical Scenarios page.
Spawn Process
The spawn application engine process (PF_SPAWN) provides greater control over jobstream processing by enabling jobs to be launched as needed.
Spawn Process Tables
PF_SPAWN creates the following tables to store data while the jobstream runs:
The PF_SPWN_JOB_TBL table stores all required information about spawned jobs.
Entries in this table are deleted once all spawned jobs are complete.
The PF_SPWN_CTL_T temporary table passes the run control parameters for each spawned job.
Use the sequence number field to control the order of the spawned jobs.
The PF_SPWN_CRIT_T table stores all of the required spawn criteria for each of the spawned jobs.
Resolver Engine
The Resolver engine further enhances and increases application performance by reducing the amount of data an engine needs to process. You do not invoke the Resolver (PF_ENG_PROC.RESOLVE) engine. The system invokes it automatically as part of startup processing to resolve all records and tablemaps specified in the engine metadata for an engine. An application needs to explicitly invoke the Resolver engine to resolve datamaps, filters, constraints, and data sets referenced in business rules.
Resolution occurs on the SetID, business unit, scenario ID, effective date, as of date, fiscal year, and accounting period. The resolution process only moves the data that matches the run control values from the table to the associated temporary table as defined in the record metadata. The engine works only on the data in the temporary table.
Individual engines call the Resolver engine as part of their run processes.
Note: The Resolver engine is limited to resolving tables for only one value at a time. For example, it cannot resolve for multiple business units.
Resolver and Chunking
As part of chunking, the Resolver engine applies chunk criteria to the record that is being chunked based on the criteria defined on the Technical Scenarios page. When the system invokes the Resolver engine, it checks all the records that it needs to resolve to see if the record requires chunking. If this is the case, the Resolver engine checks the record to see if the chunk field exists in the record. If the field exists, the system appends chunk criteria to the resolver query for this record.
Below is an example of chunk criteria:
(CUST_ID IN (SELECT CUST_ID FROM PS_CUSTiINTFC_F00 WHERE CUST_ID BETWEEN ('1000','10000'))
In this case the CUST_ID is the chunk field that exists in the record being resolved.
Process Monitor
During job processing, use Process Monitor to review the status of reports and processes. You can monitor process requests, server status, and the status of any job in the queue. If there are messages related to a process, you can view them from Process Monitor, as well. For example, if a process encounters an error, or if a server is down, you can find out almost immediately.
See PeopleSoft PeopleTools: PeopleSoft Process Scheduler
Failed Jobstreams and the Process Monitor
When a jobstream fails, one of the following status messages appear:
Error: Indicates that the program that is associated with the process request encountered an error while processing transactions within the program. In this case, delivered programs are coded to update the run status to Error before terminating.
No Success: Indicates that the program encountered an error within the transaction. No Success is different from Error because the process is marked as restartable.
Success With Application Error: Indicates that a jobstream has completed, but with an application error. For example, a jobstream may result in an application error due to unavailable record suites.