Compiling and Running Jobs
Before running a job you must always:
Image: Compiling a Job
This graphic illustrates that you must save and compile jobs prior to running them.
To compile a job, click the Compile button on the DataStage Designer toolbar. After compiling the job, the result appears in the display area. If the result of the compilation is Job successfully compiled with no errors, you can schedule or run the job. If an error is displayed, you can click the Show Error button to highlight the stage where the problem occurs. Ensure that you have specified all the input and output column definitions, directory paths, file names, and table names correctly.
Criteria Checked when Compiling Jobs
The link to the source data stage is called the primary link. All other input links are called reference links.
During compilation, the following criteria in the job design are checked:
Primary Input: If you have more than one input link to a Transformer stage, the compiler checks that one is defined as the primary input link.
Reference Input: If you have reference inputs defined in a Transformer stage, the compiler checks that these are not from sequential files.
Key Expressions: If you have key fields specified in your column definitions, the compiler checks that there are key expressions joining the data tables.
Transforms: If you have specified a transform, the compiler checks that this is a suitable transform for the data element.
Specifying Job Run Options
After compiling jobs, they become executable. The executable version of the job is stored in your project along with your job design.
To run a job, click the Run button on the DataStage Designer toolbar. After clicking the Run button the Job Run Options window appears, where you can specify information on running a server job.
Image: Job Run Options Window
This example illustrates the Job Run Options Window.
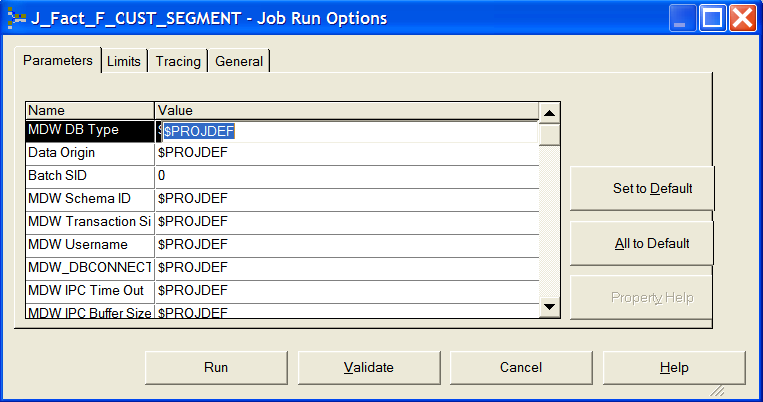
In the Parameters tab, you enter specific parameter values for the job. You specify job parameters in the job properties window. You can create job-specific parameters or use an environment variable defined in DataStage Administrator. When running jobs, the parameters required to run the job are displayed in the Parameters tab of the Job Run Options window. If you specified default values in your job properties, these are displayed in the Parameters tab.
When setting values for environment variables, you can specify either $PROJDEF,, $ENV, or $UNSET special values:
When you use $ENV, DataStage uses the current setting for the environment variable.
When you use $PROJDEF, the current setting for the environment variable is retrieved and set in the job environment. This allows the environment variable value to be used anywhere in the job. If the value of that environment variable is subsequently changed in DataStage Administrator, the job picks up the new value without the need for recompiling.
When you use $UNSET, DataStage explicitly unsets the environment variable.
In the Limits tab, you specify any run time limits.
Image: Job Run Options Limits Tab
This example illustrates the Job Run Options Limits Tab.
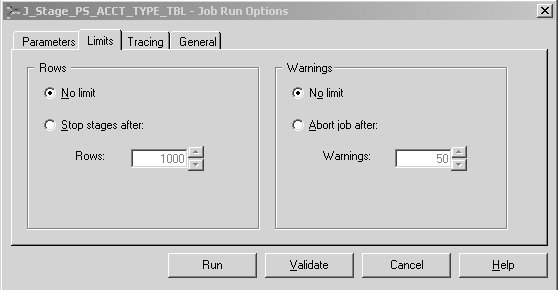
You can specify whether stages in the job should be limited in how many rows they process and whether runtime error warnings should be ignored.
You specify whether the job should generate operational metadata in the General tab.
Image: Job Run Options General Tab
This example illustrates the Job Run Options General Tab.
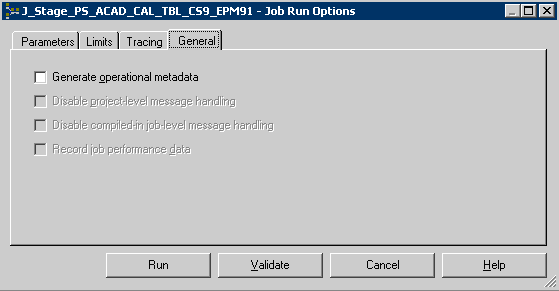
You can also disable any message handlers specified for the job run in the General tab.