Using Hashed File Stages
Using hashed files improves job performance by enabling validation of incoming data rows without having to query a database each time a row is processed. These are called lookups. The hashed file can also be placed locally, eliminating time that would be spent accessing a remote server.
You can create hashed files to use as lookups in your jobs by running one of the delivered hash file jobs, or you can create a new job that creates a target hashed file. In many of the delivered PeopleSoft sequence jobs, the appropriate hashed file is refreshed as the last step following the load of the data table, which ensures synchronized updates to the data in the hashed file for use in future lookups.
Hashed file stages:
Represent hashed files, which use a specific algorithm for distributing records in one or more groups, typically to store data extracted from a database.
Can be used to extract or write data, or to act as an intermediate file in a job.
Are most commonly used as reference tables or lookups based on key fields.
Can have any number of inputs or outputs.
Can be static or dynamic.
Accessing Hashed File Stages
To access a hashed file stage, double-click the hashed file stage in a job.
Image: Hashed File Stage Properties Window
This example illustrates the Hashed File Stage Properties Window.
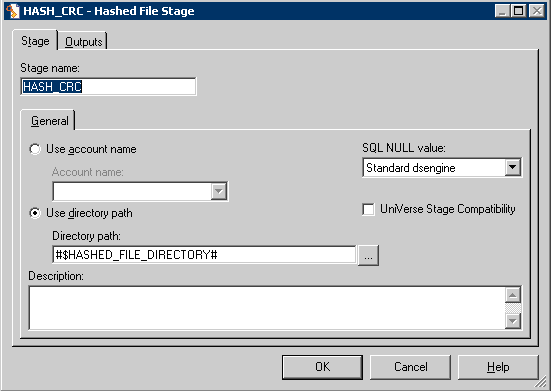
The Hashed File Stage window contains the following tabs:
|
Window Element |
Usage |
|---|---|
|
Stage tab |
Define whether an account name or a directory path accesses the hashed file. |
|
Inputs or Output tab |
If the stage has an input, the Input tab is available. If it has an output, the Output tab is available. |
|
Inputs - General tab |
Enter the hashed file name. Select whether to create a new file, if none exists. Select whether to clear the file before writing to it. |
|
Inputs - Columns tab |
Select which columns of data will be written to the file. |
Creating Hashed File Lookups
Lookups are references that enable you to compare each incoming row of data to a list of valid values, and then accept or reject that row based on the validation result.
DataStage job stages can have two types of input links:
A Stream link represents where the data flow will flow, and is displayed as a solid line.
A Reference link represents a table lookup, and is displayed as a dotted line.
Stream links, represented by solid lines, can connect either active or passive stages. Reference links, shown as dotted lines, are only used by active stages. Their purpose is to provide information that may affect how the data is changed, but they do not supply the actual data to be changed.
Typically, hashed files are used as lookups because they are much quicker to access than querying a database. Hashed files used as lookups usually contain only one or two key columns against which incoming data can be validated.
Before you can create the lookup, you must first create a hashed file containing the values to be used as a reference. To add a lookup stage to a job, you select the hashed file stage from the File palette, enter the directory path and file name of the hashed file, and link the hashed file stage to a transformer stage.
You use a DRS stage as a lookup when your lookup requires that use of relational operators, such as >= and <=.